Cooperative Informative Sensing for Monitoring Dynamic Indoor Environments via Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-08 07:56 UTC · model grok-4.3
The pith
Multi-agent reinforcement learning lets robot teams optimize monitoring accuracy for moving humans in indoor spaces by directly targeting observation quality rather than coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a learning-based MARL approach for cooperative informative sensing enables decentralized robot teams to learn policies that optimize monitoring accuracy for dynamic human activity, outperforming classical coverage and persistent monitoring baselines in diverse simulated indoor settings while remaining robust to variations in the number of observed humans.
What carries the argument
A multi-agent reinforcement learning architecture that processes decentralized observations, handles variable numbers of humans, and captures temporal dependencies to produce cooperative motion policies for active observation.
If this is right
- Robot teams can achieve higher-quality observations of dynamic humans without centralized coordination or reliance on geometric coverage objectives.
- Policies remain effective when the number of humans changes during operation, supporting scalable deployment.
- Monitoring accuracy improves for applications such as facility management and safety assessment compared to visitation-based strategies.
- Decentralized learning reduces communication overhead while still enabling cooperative behavior in partially observable settings.
Where Pith is reading between the lines
- The approach could extend to hybrid human-robot teams if the observation model is augmented with additional modalities like audio or wearable data.
- Similar informative-sensing objectives might improve performance in other dynamic domains such as traffic monitoring or wildlife tracking.
- If sim-to-real transfer succeeds, the framework suggests a path toward autonomous systems that prioritize information utility over exhaustive coverage.
Load-bearing premise
Simulation environments and observation models sufficiently capture real-world sensor noise, human motion patterns, and partial observability so that learned policies will perform similarly on physical robots.
What would settle it
Real-robot experiments in physical indoor spaces with actual moving humans where the MARL policies fail to achieve higher monitoring accuracy than classical coverage or persistent monitoring methods under equivalent conditions.
Figures







read the original abstract
Monitoring human activity in indoor environments is important for applications such as facility management, safety assessment, and space utilization analysis. While mobile robot teams offer the potential to actively improve observation quality, existing multi-robot monitoring and active perception approaches typically rely on coverage or visitation based objectives that are weakly aligned with the accuracy requirements of human-centric monitoring tasks. In this work, we formulate cooperative active observation as a decentralized control problem in which multiple robots adjust their motion to directly optimize monitoring accuracy under partial observability. We propose a learning-based framework for cooperative policies from decentralized observations using multi-agent reinforcement learning (MARL), supported by an architecture that handles variable numbers of humans and temporal dependencies. Simulation results across diverse indoor environments and monitoring tasks show that the proposed approach consistently outperforms classical coverage, persistent monitoring, and learning-free multi-robot baselines, while remaining robust to changes in the number of observed humans.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates cooperative active observation of dynamic human activity in indoor environments as a decentralized partially observable Markov decision process and proposes a multi-agent reinforcement learning (MARL) framework to learn cooperative robot motion policies that directly optimize monitoring accuracy. The architecture incorporates mechanisms for variable numbers of humans and temporal dependencies. Simulation experiments across diverse indoor environments and monitoring tasks report that the MARL approach consistently outperforms classical coverage, persistent monitoring, and learning-free multi-robot baselines while remaining robust to changes in the number of observed humans.
Significance. If the reported simulation results hold under closer scrutiny, the work offers a concrete advance in multi-robot active perception by replacing proxy coverage objectives with direct optimization of human-monitoring accuracy. The decentralized MARL formulation and explicit handling of variable human counts are technically sound contributions that could inform future systems for facility management and safety monitoring. The simulation-only nature and absence of real-robot validation or detailed statistical reporting in the abstract limit immediate deployment impact, but the core empirical claim is within the scope of a robotics journal.
major comments (1)
- [Abstract] The abstract asserts consistent outperformance across environments and tasks but supplies no quantitative metrics (e.g., mean accuracy, standard deviation, or p-values), no description of how the classical baselines were implemented or tuned, and no statistical details on the number of trials. This omission prevents verification of the central empirical claim and must be addressed with concrete numbers and experimental protocol in the results section.
minor comments (2)
- [Problem Formulation] The problem formulation section should explicitly state the observation model and reward function used to quantify monitoring accuracy, including any assumptions about sensor noise or human motion predictability.
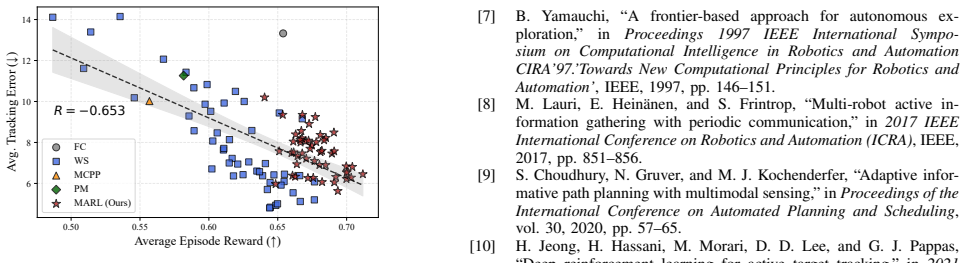
- [Experiments] Figure captions and axis labels in the experimental results should include units and the exact performance metric (e.g., average monitoring error or coverage ratio) to allow direct comparison with the baselines.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. We address the single major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts consistent outperformance across environments and tasks but supplies no quantitative metrics (e.g., mean accuracy, standard deviation, or p-values), no description of how the classical baselines were implemented or tuned, and no statistical details on the number of trials. This omission prevents verification of the central empirical claim and must be addressed with concrete numbers and experimental protocol in the results section.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised version we will update the abstract to report concrete performance figures drawn from our simulation experiments (mean monitoring accuracy, standard deviations, and relative improvements over baselines). We will also expand the results section to include: (i) explicit descriptions of how each classical baseline (coverage, persistent monitoring, and learning-free multi-robot methods) was implemented and tuned, (ii) the exact number of independent trials per environment and task, and (iii) any statistical comparisons (e.g., p-values) that were performed. These additions will make the empirical protocol fully verifiable while preserving the original technical contributions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper formulates a decentralized MARL problem for multi-robot monitoring and evaluates it via simulation against external classical coverage, persistent monitoring, and learning-free baselines. No equations, derivations, or self-citations appear in the abstract or described content that reduce the claimed outperformance to a quantity defined by the method itself. The simulation results and robustness claims rest on independent experimental comparisons rather than self-referential fitting or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The environment can be modeled as a partially observable Markov decision process suitable for decentralized MARL training.
Reference graph
Works this paper leans on
-
[1]
Analysis of factors influencing office workplace planning and design in corporate facilities,
M. A. Hassanain, “Analysis of factors influencing office workplace planning and design in corporate facilities,” Journal of Building Appraisal, vol. 6, no. 4, pp. 183–197, 2010
2010
-
[2]
Human motion trajectory prediction: A survey,
A. Rudenko, L. Palmieri, M. Herman, K. M. Kitani, D. M. Gavrila, and K. O. Arras, “Human motion trajectory prediction: A survey,” The International Journal of Robotics Research , vol. 39, no. 8, pp. 895–935, 2020
2020
-
[3]
Active perception,
R. Bajcsy, “Active perception,” Proceedings of the IEEE , vol. 76, no. 8, pp. 966–1005, 1988
1988
-
[4]
Information based adaptive robotic explo- ration,
F. Bourgault, A. A. Makarenko, S. B. Williams, B. Grocholsky, and H. F. Durrant-Whyte, “Information based adaptive robotic explo- ration,” in IEEE/RSJ International Conference on Intelligent Robots and Systems , IEEE, vol. 1, 2002, pp. 540–545
2002
-
[5]
Marvel: Multi-agent reinforcement learning for constrained field-of-view multi-robot exploration in large-scale environments,
J. Chiun, S. Zhang, Y . Wang, Y . Cao, and G. Sartoretti, “Marvel: Multi-agent reinforcement learning for constrained field-of-view multi-robot exploration in large-scale environments,” in 2025 IEEE International Conference on Robotics and Automation (ICRA) , IEEE, 2025, pp. 11 392–11 398
2025
-
[6]
Persistent robotic tasks: Monitoring and sweeping in changing environments,
S. L. Smith, M. Schwager, and D. Rus, “Persistent robotic tasks: Monitoring and sweeping in changing environments,” IEEE Trans- actions on Robotics , vol. 28, no. 2, pp. 410–426, 2011
2011
-
[7]
A frontier-based approach for autonomous ex- ploration,
B. Y amauchi, “A frontier-based approach for autonomous ex- ploration,” in Proceedings 1997 IEEE International Sympo- sium on Computational Intelligence in Robotics and Automation CIRA’97. ’Towards New Computational Principles for Robotics and Automation’, IEEE, 1997, pp. 146–151
1997
-
[8]
Multi-robot active in- formation gathering with periodic communication,
M. Lauri, E. Heinänen, and S. Frintrop, “Multi-robot active in- formation gathering with periodic communication,” in 2017 IEEE International Conference on Robotics and Automation (ICRA) , IEEE, 2017, pp. 851–856
2017
-
[9]
Adaptive infor- mative path planning with multimodal sensing,
S. Choudhury, N. Gruver, and M. J. Kochenderfer, “Adaptive infor- mative path planning with multimodal sensing,” in Proceedings of the International Conference on Automated Planning and Scheduling , vol. 30, 2020, pp. 57–65
2020
-
[10]
Deep reinforcement learning for active target tracking,
H. Jeong, H. Hassani, M. Morari, D. D. Lee, and G. J. Pappas, “Deep reinforcement learning for active target tracking,” in 2021 IEEE International Conference on Robotics and Automation (ICRA) , IEEE, 2021, pp. 1825–1831
2021
-
[11]
Adaptive informative path plan- ning using deep reinforcement learning for uav-based active sens- ing,
J. Rückin, L. Jin, and M. Popovi, “Adaptive informative path plan- ning using deep reinforcement learning for uav-based active sens- ing,” in 2022 International Conference on Robotics and Automation (ICRA), IEEE, 2022, pp. 4473–4479
2022
-
[12]
Mstc*: Multi-robot coverage path planning under physical constrain,
J. Tang, C. Sun, and X. Zhang, “Mstc*: Multi-robot coverage path planning under physical constrain,” in 2021 IEEE Interna- tional Conference on Robotics and Automation (ICRA) , IEEE, 2021, pp. 2518–2524
2021
-
[13]
Priority-aware multi-robot coverage path planning,
K. Lee, H. Kim, J. Li, and J. Park, “Priority-aware multi-robot coverage path planning,” IEEE Robotics and Automation Letters , vol. 11, no. 3, pp. 3534–3541, 2026
2026
-
[14]
Turn-minimizing multirobot coverage,
I. V andermeulen, R. GroSS, and A. Kolling, “Turn-minimizing multirobot coverage,” in 2019 International Conference on Robotics and Automation (ICRA) , IEEE, 2019, pp. 1014–1020
2019
-
[15]
Planning periodic persistent monitoring trajectories for sensing robots in gaussian random fields,
X. Lan and M. Schwager, “Planning periodic persistent monitoring trajectories for sensing robots in gaussian random fields,” in 2013 IEEE International Conference on Robotics and Automation (ICRA) , IEEE, 2013, pp. 2415–2420
2013
-
[16]
An autonomous coverage path planning algorithm for maritime search and rescue of persons- in-water based on deep reinforcement learning,
J. Wu, L. Cheng, S. Chu, and Y . Song, “An autonomous coverage path planning algorithm for maritime search and rescue of persons- in-water based on deep reinforcement learning,” Ocean Engineering, vol. 291, p. 116 403, 2024
2024
-
[17]
Human implicit preference-based policy fine-tuning for multi-agent reinforcement learning in usv swarm,
H. Kim, K. Lee, J. Park, J. Li, and J. Park, “Human implicit preference-based policy fine-tuning for multi-agent reinforcement learning in usv swarm,” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 2025, pp. 18 653–18 659
2025
-
[18]
A decentralized mul- tirobot spatiotemporal multitask assignment approach for perimeter defense,
S. V elhal, S. Sundaram, and N. Sundararajan, “A decentralized mul- tirobot spatiotemporal multitask assignment approach for perimeter defense,” IEEE Transactions on Robotics , vol. 38, no. 5, pp. 3085– 3096, 2022
2022
-
[19]
A policy-guided reinforce- ment learning method for encirclement control in multiobstacle environment,
F. Gou, H. Du, C. Zhao, and Y . Cai, “A policy-guided reinforce- ment learning method for encirclement control in multiobstacle environment,” IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[20]
The complexity of decentralized control of markov decision processes,
D. S. Bernstein, R. Givan, N. Immerman, and S. Zilberstein, “The complexity of decentralized control of markov decision processes,” Mathematics of Operations Research , vol. 27, no. 4, pp. 819–840, 2002
2002
-
[21]
The surprising effectiveness of ppo in cooperative multi-agent games,
C. Y u, A. V elu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,”Advances in Neural Information Processing Systems , vol. 35, pp. 24 611–24 624, 2022
2022
-
[22]
Set transformer: A framework for attention-based permutation- invariant neural networks,
J. Lee, Y . Lee, J. Kim, A. Kosiorek, S. Choi, and Y . W. Teh, “Set transformer: A framework for attention-based permutation- invariant neural networks,” in Proceedings of the 36th International Conference on Machine Learning , 2019, pp. 3744–3753
2019
-
[23]
Computer-generated res- idential building layouts,
P . Merrell, E. Schkufza, and V . Koltun, “Computer-generated res- idential building layouts,” in ACM SIGGRAPH Asia 2010 papers , 2010, pp. 1–12
2010
-
[24]
Limits of pre- dictability in human mobility,
C. Song, Z. Qu, N. Blumm, and A.-L. Barabási, “Limits of pre- dictability in human mobility,” Science, vol. 327, no. 5968, pp. 1018– 1021, 2010
2010
-
[25]
Using gps to learn significant locations and predict movement across multiple users,
D. Ashbrook and T. Starner, “Using gps to learn significant locations and predict movement across multiple users,” Personal and Ubiqui- tous Computing , vol. 7, no. 5, pp. 275–286, 2003
2003
-
[26]
A formal basis for the heuristic determination of minimum cost paths,
P . E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,” IEEE Transactions on Systems Science and Cybernetics , vol. 4, no. 2, pp. 100–107, 1968
1968
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.