A Retraction-Free EXTRA Method for Decentralized Optimization on the Stiefel Manifold
Pith reviewed 2026-05-08 05:48 UTC · model grok-4.3
The pith
RF-EXTRA achieves an exact O(1/K) convergence rate to stationary points for decentralized optimization on the Stiefel manifold with constant step sizes and no retractions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RF-EXTRA is a distributed retraction-free primal-dual method that, by establishing a contractive recursion for the joint error (X_k - average X_k, s_k - average s_k), ensures that the joint error can be controlled using small yet constant step sizes, leading to an exact O(1/K) convergence rate to a stationary point on static undirected networks.
What carries the argument
The joint error vector consisting of deviations in local variables and local directions from their averages, whose contractive recursion is established under the approximate gradient mapping and EXTRA recursion.
Load-bearing premise
The joint-error recursion remains contractive when the approximate gradient mapping for the orthogonality constraints is paired with the EXTRA decentralized update on static undirected networks.
What would settle it
Observing that the joint error fails to contract or the convergence rate exceeds O(1/K) for some constant step size on a static undirected network with the given mapping would falsify the claim.
Figures

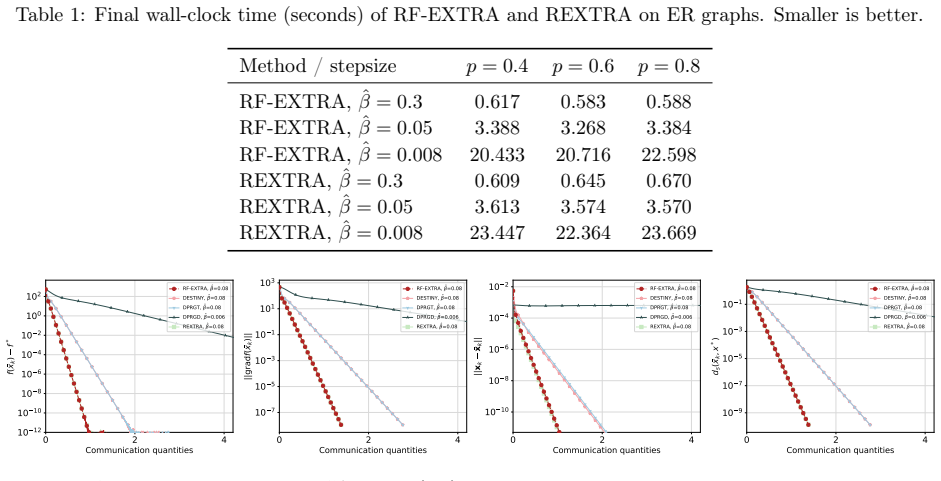



read the original abstract
Decentralized optimization provides a fundamental framework for large-scale learning and signal processing with distributed data. We study decentralized optimization with orthogonality constraints on the Stiefel manifold and propose RF-EXTRA, a distributed retraction-free primal-dual method on static undirected networks. The method combines an approximate gradient mapping for orthogonality-constrained optimization with an EXTRA-based decentralized recursion, thereby avoiding retractions while preserving a simple communication pattern. On the theoretical side, the analysis considers \revise{the joint error} $(\mathbf{X}_k-\overline{\mathbf X}_k,\mathbf{s}_k-\overline{\mathbf s}_k)$ in the local variables and local directions, and establishes a contractive recursion for the joint error. This contractivity ensures that the joint error can be controlled using small yet constant step sizes, thus leading to an exact $\mathcal{O}(1/K)$ convergence rate of RF-EXTRA to a stationary point. Experiments on PCA and low-rank matrix completion show that RF-EXTRA compares favorably with the reported decentralized baselines and exhibits strong communication efficiency on the tested tasks on the Stiefel manifold.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RF-EXTRA, a retraction-free primal-dual decentralized optimization algorithm for problems on the Stiefel manifold. It combines an approximate gradient mapping to handle orthogonality constraints without retractions and an EXTRA-based recursion for communication on static undirected networks. The central claim is that the joint error (X_k - average X_k, s_k - average s_k) satisfies a contractive recursion, which permits constant step sizes and yields an exact O(1/K) convergence rate to a stationary point. Experiments on PCA and low-rank matrix completion show competitive performance and communication efficiency relative to baselines.
Significance. If the joint-error contractivity holds, the result is significant because it removes the need for retraction operations in distributed manifold optimization, which are often expensive or unstable. The exact O(1/K) rate with constant steps and simple communication pattern is a practical advantage for large-scale distributed tasks such as PCA. The approach of analyzing the combined primal-dual deviation vector is a clean way to obtain the rate, and the empirical results on standard tasks add value.
major comments (2)
- [Analysis section on joint-error recursion] The derivation of the contractive recursion for the joint error (X_k - average X_k, s_k - average s_k) is load-bearing for the O(1/K) claim. The bounding of cross terms arising from the decentralized EXTRA updates and the first-order approximation to the orthogonality constraint must be presented with explicit constants so that the spectral-radius condition (strictly less than one) and the allowable constant step-size range can be verified directly.
- [Section introducing the approximate gradient mapping] The contractivity relies on the approximate gradient mapping respecting the orthogonality constraint. The precise definition of this mapping, together with its Lipschitz constant or approximation-error bound, must be stated explicitly because these quantities enter the step-size restriction that guarantees the spectral radius is less than one.
minor comments (3)
- [Abstract] The abstract contains the LaTeX command 'revise{the joint error}'; replace this with clean text and ensure the term 'joint error' is defined consistently in the introduction and analysis.
- [Experiments] The experimental section should report the network size, topology, and exact communication metric (e.g., total scalar transmissions per iteration) to make the claimed communication efficiency quantitative.
- [Notation and preliminaries] Notation for the averages (overline{X}_k and overline{s}_k) should be introduced at the first use rather than assumed.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the precise comments on the analysis. We address the two major comments below and will revise the manuscript accordingly to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Analysis section on joint-error recursion] The derivation of the contractive recursion for the joint error (X_k - average X_k, s_k - average s_k) is load-bearing for the O(1/K) claim. The bounding of cross terms arising from the decentralized EXTRA updates and the first-order approximation to the orthogonality constraint must be presented with explicit constants so that the spectral-radius condition (strictly less than one) and the allowable constant step-size range can be verified directly.
Authors: We agree that the bounding steps for the cross terms must be expanded with explicit constants to allow direct verification of the spectral radius and step-size range. The manuscript derives the joint-error recursion in the analysis section, but the intermediate bounds are presented compactly. In the revision we will insert the full expansion of each cross-term bound, compute the resulting spectral-radius expression explicitly, and state the resulting restriction on the constant step size. revision: yes
-
Referee: [Section introducing the approximate gradient mapping] The contractivity relies on the approximate gradient mapping respecting the orthogonality constraint. The precise definition of this mapping, together with its Lipschitz constant or approximation-error bound, must be stated explicitly because these quantities enter the step-size restriction that guarantees the spectral radius is less than one.
Authors: We accept the point that the definition and quantitative properties of the approximate gradient mapping need to be stated more explicitly. The mapping is introduced as a first-order approximation that preserves the orthogonality constraint to first order; its Lipschitz constant and approximation-error bound appear in the subsequent analysis but are not highlighted at the definition stage. In the revised manuscript we will restate the precise definition at the beginning of the relevant section, list the Lipschitz and error constants, and show explicitly how they propagate into the step-size condition that ensures the spectral radius is strictly less than one. revision: yes
Circularity Check
No significant circularity; derivation self-contained via explicit joint-error bounds
full rationale
The paper's central result is the contractive recursion on the joint error vector (X_k - avg X_k, s_k - avg s_k) obtained by bounding the cross terms that arise from the EXTRA mixing matrices on static undirected graphs together with the first-order approximation to the orthogonality constraint. This produces a linear system whose spectral radius is strictly less than one for sufficiently small constant step sizes, directly yielding the O(1/K) rate to stationarity. No equation or claim reduces to a fitted parameter renamed as a prediction, a self-citation whose content is itself unverified, or a definitional equivalence; the analysis is presented as an independent derivation resting on standard Lipschitz and network assumptions rather than re-deriving prior constants by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The network is static and undirected.
- ad hoc to paper An approximate gradient mapping exists that respects the orthogonality constraint without retraction.
Reference graph
Works this paper leans on
-
[1]
John Tsitsiklis, Dimitri Bertsekas, and Michael Athans. Distributed asynchronous deterministic and stochastic gradient optimization algorithms.IEEE transactions on automatic control, 31(9):803–812, 1986
work page 1986
-
[2]
Distributed subgradient methods for multi-agent optimization
Angelia Nedic and Asuman Ozdaglar. Distributed subgradient methods for multi-agent optimization. IEEE Transactions on automatic control, 54(1):48–61, 2009
work page 2009
-
[3]
Kun Yuan, Qing Ling, and Wotao Yin. On the convergence of decentralized gradient descent.SIAM Journal on Optimization, 26(3):1835–1854, 2016
work page 2016
-
[4]
Sulaiman A. Alghunaim and Kun Yuan. A unified and refined convergence analysis for non-convex decentralized learning.IEEE Transactions on Signal Processing, 2022
work page 2022
-
[5]
Kun Yuan, Bicheng Ying, Xiaochuan Zhao, and Ali H. Sayed. Exact diffusion for distributed opti- mization and learning — part i: Algorithm development.IEEE Transactions on Signal Processing, 2018
work page 2018
-
[6]
Wei Shi, Qing Ling, Gang Wu, and Wotao Yin. EXTRA: An exact first-order algorithm for decentralized consensus optimization.SIAM Journal on Optimization, 25(2):944–966, 2015
work page 2015
-
[7]
Distributed constrained optimal consensus of multi- agent systems.Automatica, 68:209–215, 2016
Zhirong Qiu, Shuzhi Sam Ge Liu, and Lihua Xie. Distributed constrained optimal consensus of multi- agent systems.Automatica, 68:209–215, 2016. doi: 10.1016/j.automatica.2016.01.055
-
[8]
John Duchi, Alekh Agarwal, and Martin Wainwright. Dual averaging for distributed optimization: Convergence analysis and network scaling.IEEE Transactions on Automatic Control, 2011
work page 2011
-
[9]
Lei Huang, Xianglong Liu, Bo Lang, Adams Yu, Yongliang Wang, and Bo Li. Orthogonal weight nor- malization: Solution to optimization over multiple dependent Stiefel manifolds in deep neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[10]
Riemannian approach to batch normalization
Minhyung Cho and Jaehyung Lee. Riemannian approach to batch normalization. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[11]
Riemannian preconditioned lora for fine-tuning foundation mod- els.arXiv preprint arXiv:2402.02347,
Fangzhao Zhang and Mert Pilanci. Riemannian preconditioned LoRA for fine-tuning foundation models. arXiv preprint arXiv:2402.02347, 2024
-
[12]
Retraction-free optimization over the Stiefel manifold with application to the LoRA fine-tuning
Yuan Zhang, Jiang Hu, Jiaxi Cui, Lin Lin, Zaiwen Wen, and Quanzheng Li. Retraction-free optimization over the Stiefel manifold with application to the LoRA fine-tuning. 2024
work page 2024
-
[13]
Susan Blackford, Antoine Petitet, Roldan Pozo, Karin Remington, R
L. Susan Blackford, Antoine Petitet, Roldan Pozo, Karin Remington, R. Clint Whaley, James Demmel, Jack Dongarra, Iain Duff, Sven Hammarling, Greg Henry, and Michael Heroux. An updated set of basic linear algebra subprograms (BLAS).ACM Transactions on Mathematical Software, 28(2):135–151, 2002
work page 2002
-
[14]
Anastasia Koloskova, Tao Lin, and Sebastian U. Stich. An improved analysis of gradient tracking for decentralized machine learning. InAdvances in Neural Information Processing Systems, 2021
work page 2021
-
[15]
D2: Decentralized training over decen- tralized data
Hanlin Tang, Xiangru Lian, Ming Yan, Ce Zhang, and Ji Liu. D2: Decentralized training over decen- tralized data. InProceedings of the International Conference on Machine Learning, 2018. 21
work page 2018
-
[16]
Angelia Nedić, Alex Olshevsky, and Wei Shi. Achieving geometric convergence for distributed optimiza- tion over time-varying graphs.SIAM Journal on Optimization, 27(4):2597–2633, 2017
work page 2017
-
[17]
Guannan Qu and Na Li. Harnessing smoothness to accelerate distributed optimization.IEEE Trans- actions on Control of Network Systems, 5(3):1245–1260, 2017
work page 2017
-
[18]
Huaqing Li, Lifeng Zheng, Zheng Wang, Yu Yan, Liping Feng, and Jing Guo. S-diging: A stochastic gradient tracking algorithm for distributed optimization.IEEE Transactions on Emerging Topics in Computational Intelligence, 2020
work page 2020
-
[19]
Distributed stochastic gradient tracking methods.Mathematical Program- ming, 2021
Shi Pu and Angelia Nedić. Distributed stochastic gradient tracking methods.Mathematical Program- ming, 2021
work page 2021
-
[20]
Yue Liu, Tao Lin, Anastasia Koloskova, and Sebastian U. Stich. Decentralized gradient tracking with local steps.Optimization Methods and Software, 2025
work page 2025
-
[21]
Zhi Li, Wei Shi, and Ming Yan. A decentralized proximal-gradient method with network independent step-sizes and separated convergence rates.IEEE Transactions on Signal Processing, 67(17):4494–4506, 2019
work page 2019
-
[22]
MingyiHong, DavoodHajinezhad, andMing-MinZhao. Prox-PDA:Theproximalprimal-dualalgorithm for fast distributed nonconvex optimization and learning over networks. InInternational Conference on Machine Learning, pages 1529–1538. PMLR, 2017
work page 2017
-
[23]
Kun Yuan, Sulaiman A. Alghunaim, and Xinmeng Huang. Removing data heterogeneity influence enhances network topology dependence of decentralized SGD.Journal of Machine Learning Research, 2023
work page 2023
-
[24]
Paolo Di Lorenzo and Gesualdo Scutari. Next: In-network nonconvex optimization.IEEE Transactions on Signal and Information Processing over Networks, 2016
work page 2016
-
[25]
Anastasia Koloskova, Sebastian U. Stich, and Martin Jaggi. Decentralized stochastic optimization and gossip algorithms with compressed communication. InProceedings of the International Conference on Machine Learning, 2019
work page 2019
-
[26]
Yutong He, Xinmeng Huang, and Kun Yuan. Unbiased compression saves communication in distributed optimization: When and how much? InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[27]
Chuyan Chen, Yutong He, Pengrui Li, Weichen Jia, and Kun Yuan. Greedy low-rank gradient com- pression for distributed learning with convergence guarantees.IEEE Transactions on Signal Processing, 2026
work page 2026
-
[28]
On biased compression for distributed learning.Journal of Machine Learning Research, 2023
Aleksandr Beznosikov, Samuel Horváth, Peter Richtárik, and Mher Safaryan. On biased compression for distributed learning.Journal of Machine Learning Research, 2023
work page 2023
-
[29]
Error compensated distributed SGD can be accelerated
Xun Qian, Peter Richtárik, and Tong Zhang. Error compensated distributed SGD can be accelerated. InAdvances in Neural Information Processing Systems, 2021
work page 2021
-
[30]
Liyuan Liang, Xinmeng Huang, Ran Xin, and Kun Yuan. Understanding the influence of digraphs on decentralized optimization: Effective metrics, lower bound, and optimal algorithm.SIAM Journal on Optimization, 2025
work page 2025
- [31]
-
[32]
Exponential graph is provably efficient for decentralized deep training
Bicheng Ying, Kun Yuan, Yiming Chen, Hanbin Hu, Pan Pan, and Wotao Yin. Exponential graph is provably efficient for decentralized deep training. InAdvances in Neural Information Processing Systems, 2021. 22
work page 2021
-
[33]
Decentralized Riemannian gradient descent on the Stiefel manifold
Shixiang Chen, Alfredo Garcia, Mingyi Hong, and Shahin Shahrampour. Decentralized Riemannian gradient descent on the Stiefel manifold. InInternational Conference on Machine Learning, pages 1594–1605. PMLR, 2021
work page 2021
-
[34]
Kangkang Deng and Jiang Hu. Decentralized projected Riemannian gradient method for smooth opti- mization on compact submanifolds embedded in the euclidean space.Numerische Mathematik, 2025
work page 2025
-
[35]
Lei Wang, Le Bao, and Xin Liu. A decentralized proximal gradient tracking algorithm for composite optimization on Riemannian manifolds.Journal of Machine Learning Research, 2025
work page 2025
-
[36]
Jiayuan Wu, Zhanwang Deng, Jiang Hu, Weijie Su, and Zaiwen Wen. Riemannian EXTRA: Communication-efficient decentralized optimization over compact submanifolds with data heterogeneity. arXiv preprint arXiv:2505.15537, 2025
-
[37]
JunChen, LinaLiu, TianyiZhu, YongLiu, GuangDai, YunliangJiang, andIvorWTsang. Decentralized optimization on compact submanifolds by quantized Riemannian gradient tracking.IEEE Transactions on Signal Processing, 2025
work page 2025
-
[38]
Jiang Hu and Kangkang Deng. Improving the communication in decentralized manifold optimization through single-step consensus and compression.arXiv preprint arXiv:2407.08904, 2024
-
[39]
Decentralized projected Riemannian stochastic recursive momentum method for nonconvex optimization
Kangkang Deng and Jiang Hu. Decentralized projected Riemannian stochastic recursive momentum method for nonconvex optimization. InProceedings of the AAAI Conference on Artificial Intelligence, 2025
work page 2025
-
[40]
Jun Chen, Haishan Ye, Mengmeng Wang, Tianxin Huang, Guang Dai, Ivor W. Tsang, and Yong Liu. Decentralized Riemannian conjugate gradient method on the Stiefel manifold.arXiv preprint arXiv:2308.10547, 2023
-
[41]
Jiang Hu, Kangkang Deng, and Quanzheng Li. Decentralized Riemannian natural gradient methods with Kronecker product approximations.Journal of the Operations Research Society of China, 2025
work page 2025
-
[42]
Shixiang Chen, Alfredo Garcia, Mingyi Hong, and Shahin Shahrampour. On the local linear rate of consensus on the Stiefel manifold.IEEE Transactions on Automatic Control, 2023
work page 2023
-
[43]
Roberto Tron, Bijan Afsari, and René Vidal. Riemannian consensus for manifolds with bounded curva- ture.IEEE Transactions on Automatic Control, 2012
work page 2012
-
[44]
Consensus optimization on manifolds.SIAM Journal on Control and Optimization, 2009
Alain Sarlette and Rodolphe Sepulchre. Consensus optimization on manifolds.SIAM Journal on Control and Optimization, 2009
work page 2009
-
[45]
Achieving local consensus over compact submanifolds
Jiang Hu, Jiaojiao Zhang, and Kangkang Deng. Achieving local consensus over compact submanifolds. IEEE Transactions on Automatic Control, 70(9):5750–5763, 2025. doi: 10.1109/TAC.2025.3545711
-
[46]
Youbang Sun, Shixiang Chen, Alfredo Garcia, and Shahin Shahrampour. Retraction-free decentralized non-convex optimization with orthogonal constraints.arXiv preprint arXiv:2405.11590, 2024. doi: 10.48550/arXiv.2405.11590
-
[47]
Lei Wang and Xin Liu. Decentralized optimization over the Stiefel manifold by an approximate aug- mented Lagrangian function.IEEE Transactions on Signal Processing, 2022
work page 2022
-
[48]
Fast and accurate optimization on the orthogonal manifold without retraction
Pierre Ablin and Gabriel Peyré. Fast and accurate optimization on the orthogonal manifold without retraction. InProceedings of The 25th International Conference on Artificial Intelligence and Statistics, pages 5636–5657. PMLR, 2022
work page 2022
-
[49]
Bin Gao, Xin Liu, and Ya-xiang Yuan. Parallelizable algorithms for optimization problems with orthog- onality constraints.SIAM Journal on Scientific Computing, 41(3):A1949–A1983, 2019
work page 2019
-
[50]
Dissolving constraints for Riemannian optimization
Nachuan Xiao, Xin Liu, and Kim-Chuan Toh. Dissolving constraints for Riemannian optimization. Mathematics of Operations Research, 2024. 23
work page 2024
-
[51]
Roger A. Horn and Charles R. Johnson.Matrix Analysis. Cambridge University Press, 2012
work page 2012
-
[52]
Lei Qin and Ye Pu. Convergence analysis of EXTRA in non-convex distributed optimization.IEEE Control Systems Letters, 2025
work page 2025
-
[53]
ReasFlow Team. Reasflow: Assisting reasoning-centric scientific discovery in applied mathematics via a knowledge-based multi-agent system, 2026. URLhttps://blog.reaslab.io/blog/reasflow-intro/. 24
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.