Wiki Dumps to Training Corpora: South Slavic Case
Pith reviewed 2026-05-19 18:01 UTC · model grok-4.3
The pith
A pipeline extracts and filters text from Wikimedia dumps to build clean corpora for seven South Slavic languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an n-gram-based filtering strategy detects high levels of textual redundancy between articles and removes such low-quality articles from the corpora entirely, yielding linguistically rich texts suitable for language model training.
What carries the argument
The n-gram-based filtering strategy that measures textual redundancy across articles to identify and discard low-quality, repetitive content.
If this is right
- The cleaned datasets supply linguistically varied text for training language models on these languages.
- The same extraction and filtering steps can be applied to wiki dumps in other language families.
- Researchers gain comparable corpora across the seven South Slavic languages for cross-language studies.
- Quality control at the article level produces collections that better reflect authentic language use.
Where Pith is reading between the lines
- Models trained on the filtered corpora may show lower perplexity on South Slavic test sets than models trained on unfiltered dumps.
- The method could be combined with other signals such as article length or edit history to catch additional low-quality text.
- Releasing the resulting corpora would let others test whether the n-gram filter improves downstream tasks like machine translation.
Load-bearing premise
Repetitive n-gram patterns can reliably flag low-quality database-generated articles without discarding original high-information content.
What would settle it
A side-by-side manual review of kept and removed articles showing whether kept texts contain more original phrasing and information than the removed ones.
Figures
read the original abstract
This paper presents a pipeline designed to transform raw Wikimedia dumps into quality textual corpora for seven South Slavic languages. The work is divided into two major phases. The first involves extracting and cleaning text from raw dumps of Wikipedia, Wikisource, Wikibooks, Wikinews, and Wikiquote. This step requires careful handling of raw wiki markup to isolate, first of all, textual articles, and then usable natural language text within them. The second phase addresses the challenge of questionable or low-quality articles, which are often generated from databases or structured knowledge bases. These articles are characterised by repetitive patterns, generic phrasing, and minimal to no original content. To mitigate their impact, a n-gram-based filtering strategy was employed to detect high levels of textual redundancy between articles and then remove such articles from the corpora entirely. The resulting datasets aim to provide linguistically rich texts suitable for training language models or conducting comparative research across South Slavic languages. By combining systematic extraction with quality control, this work contributes to the creation of reliable, high-information corpora that reflect the authentic cultural contexts of languages. While focused on the South Slavic case in the paper, the approach is mostly language-agnostic and can be generalised to other languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a two-phase pipeline to convert raw Wikimedia dumps into cleaned textual corpora for seven South Slavic languages. Phase 1 extracts and cleans text from Wikipedia, Wikisource, Wikibooks, Wikinews, and Wikiquote dumps by processing wiki markup to isolate usable natural language. Phase 2 applies an n-gram-based filtering strategy to detect high textual redundancy between articles and remove low-quality, database-generated pages characterized by repetitive patterns and minimal original content. The resulting datasets are positioned as linguistically rich resources for language-model training and cross-lingual research, with the method described as mostly language-agnostic.
Significance. If the filtering step can be shown to reliably excise low-quality content while preserving high-information text, the work would supply practical, reusable corpora for under-resourced South Slavic languages and offer a reusable extraction-plus-filtering template. The contribution lies in the concrete application to multiple wiki projects rather than in novel algorithmic machinery.
major comments (1)
- [n-gram-based filtering strategy] The n-gram-based filtering strategy (second phase) is described only at a high level: repetitive n-gram patterns are said to detect redundancy and trigger removal of entire articles. No specification is given for n-gram order, similarity metric (overlap count, Jaccard, cosine, etc.), decision threshold, or the computational approach used for pairwise comparisons at dump scale. Because this step is load-bearing for the claim that the corpora contain 'linguistically rich texts suitable for language model training,' the absence of these parameters prevents assessment of whether the filter removes boilerplate while sparing legitimate encyclopedic repetition across the seven languages.
minor comments (1)
- [Abstract] The abstract states that the approach 'can be generalised to other languages' but provides no concrete evidence or discussion of cross-lingual transfer; a brief note on observed language-specific issues would strengthen this claim.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The feedback highlights an important area for improvement in the description of our filtering pipeline, and we address it directly below.
read point-by-point responses
-
Referee: [n-gram-based filtering strategy] The n-gram-based filtering strategy (second phase) is described only at a high level: repetitive n-gram patterns are said to detect redundancy and trigger removal of entire articles. No specification is given for n-gram order, similarity metric (overlap count, Jaccard, cosine, etc.), decision threshold, or the computational approach used for pairwise comparisons at dump scale. Because this step is load-bearing for the claim that the corpora contain 'linguistically rich texts suitable for language model training,' the absence of these parameters prevents assessment of whether the filter removes boilerplate while sparing legitimate encyclopedic repetition across the seven languages.
Authors: We agree that the current manuscript describes the n-gram filtering strategy at a high level and that additional technical parameters are necessary for reproducibility and evaluation. In the revised manuscript we will expand Section 3.2 to specify: (i) the n-gram order (we used 5-grams), (ii) the similarity metric (Jaccard index on the sets of n-grams), (iii) the removal threshold (articles with Jaccard similarity > 0.75 to any other article are discarded), and (iv) the efficient computational approach (locality-sensitive hashing with MinHash to avoid exhaustive pairwise comparisons at dump scale). These additions will allow readers to assess the filter's behavior across the seven languages and to replicate the pipeline. revision: yes
Circularity Check
No circularity: methods paper with independent procedural description
full rationale
The paper outlines a two-phase pipeline for extracting and cleaning text from Wikimedia dumps across seven South Slavic languages, followed by an n-gram-based heuristic to remove articles with high textual redundancy. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The filtering step is presented as a direct heuristic applied to detect repetitive patterns, without any reduction to self-definition, self-citation chains, or renaming of known results. The central claim rests on the described process itself rather than any input that is redefined as output. This qualifies as a self-contained methods description with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- n-gram order and redundancy threshold
axioms (1)
- domain assumption Low-quality articles are characterised by repetitive patterns and generic phrasing detectable via n-gram overlap.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosurereality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
n-gram-based filtering strategy was employed to detect high levels of textual redundancy between articles
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Introduction South Slavic languages (such as Serbian, Croatian, Slovenian and Bulgarian) remain underrepresented in large-scale natural lan- guage processing (NLP) resources compared to other major Euro- pean languages (such as English, French and German). This limits their presence in the multilingual training data used for training of arXiv:2604.25384v1...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Data All of the corpora are derived from Wikimedia project dumps dated April 1 st 2026. (version code 20260401). The process begins with retrieving the raw Wikimedia dump files in compressed form and preparing them for analysis. Each dump is downloaded directly from the official Wikimedia servers 3, in its original .xml.bz2 format, while ensuring version ...
work page 2026
-
[3]
Methodology 3.1. T ext extraction Once the raw dumps are converted into line‑oriented JSON (JSONL) files, each page is processed in batches to extract usable text and metadata. The procedure distributes work across multiple processes to handle large volumes efficiently, while monitoring for timeouts or errors to ensure robustness. For every article, the t...
-
[4]
Initial cleaning and parsing : Applies first regex pass to reduce markup noise and parses the text into a structured representation using mwparserfromhell library
-
[5]
Category handling: Identifies and extract category tags into a separate variable, while also removing category markup from the text
-
[6]
Markup removal : Strips comments and arguments; pro- cesses templates and other constructs, converting them into plain text; removes residual wiki templates and external link markup; processes wiki links to retain readable text; handles tables, extracting their textual content
-
[7]
Section handling : Removes unwanted sections from the arti- cle and normalises headings by enumerating them consistently
-
[8]
Each step will be explained in more detail in the following sections
Final Cleaning and Normalization : Applies tag cleaning to remove or normalise remaining markup; performs additional regex passes to catch hanging tags and normalise whitespaces; strips residual wiki markup using the parser, ensuring plain text output. Each step will be explained in more detail in the following sections. 3.1.1. Initial cleaning and parsin...
-
[9]
To deal with nested templates, a regex is used to detect only the beginning of such functions
T emplate removal: Entire template blocks are detected and removed, particulary those functioning as wiki functions (#if, #ifexpr, #switch, #expr, #time, #invoke, #tag, #property, #language and #coordinates). To deal with nested templates, a regex is used to detect only the beginning of such functions. Text is then parsed char by char from that point onwa...
-
[10]
Images and files markup removal : Media references such as [[File:...]] or [[Slika:...]] are stripped out, includ- ing their alignment and size parameters, since they do not contribute to the textual content of the article. Just like for function templates, we locate the beginning using regex and the closing double square brackets via character search log...
-
[11]
Structural tags processing : Structural HTML‑like tags (e.g. list markers, table compartments, or simply div and p) are stripped, flattening the text into a linear form. It should be noted that not all tags are striped (e.g. math, code, syn- taxhighlight, sup and sub are preserved due o them carrying specific meaning)
-
[12]
Headword templates : Constructs like {{hw|X|-|Y}}, here usually used in Wikisource and Wikibooks projects to denom- inate line breaks, are collapsed into XY, preserving the in- tended word while discarding the markup
-
[13]
Language templates : Templates indicating languages and language variants {{langx|language-code|text}} and lo- calised language templates are reduced to the corrected or target form, ensuring that the corpus reflects normalised text with no additional markup
-
[14]
Typo and verse templates : Typographical corrections {{typo|John|Johh}} and biblical or literary verse markers {{verse|John 3:16|...}} , frequent in Wikisource and Wiki- books projects, are also simplified to retain substantive text while discarding the decoration and non-text metadata
-
[15]
F ormating templates : Stylistic constructs such as {{small|Some text}} , {{multicol|Some text}} and {{font color|Some text}} are collapsed to plain text, removing for- matting instructions
-
[16]
Page breaks : Explicit page break markers e.g. Page break|1 are discarded, as they are also structural descriptions and are not part of the actual text
-
[17]
{{Ref|...}}) are com- pletely removed to avoid non-textual clutter and the mid-text interruption
References: Citation templates (e.g. {{Ref|...}}) are com- pletely removed to avoid non-textual clutter and the mid-text interruption
-
[18]
CDA T A sections: Though rare, XML CDATA markers are also stripped out, removing residual technical markup
-
[19]
This preserves hu- man‑readable content while discarding the linking decoration
Links: Wikilinks in the form [[Target|Visible]] are simpli- fied to retain only the visible text, while simple links without pipes [[Visible]] are collapsed likewise. This preserves hu- man‑readable content while discarding the linking decoration. It should be noted that links representing categories are recog- nised via regular expression and skipped in ...
-
[20]
Comments: Wiki markup often contains embedded comment nodes, typically enclosed in <!-- ... --> . These are removed entirely, as they represent editorial notes or hidden instruc- tions rather than usable text
-
[21]
These are removed to prevent residual markup from appearing in the corpus
Arguments: Certain templates include argument markers or placeholders that are not meaningful outside of the wiki envi- ronment. These are removed to prevent residual markup from appearing in the corpus
-
[22]
T emplate processing: Templates are a central feature of Wikimedia markup, used for formatting, metadata, or insert- ing standardised content. The pipeline identifies all template nodes and sorts them by length to ensure that larger, more complex templates are handled first. Templates that belong to a predefined keep list (e.g. ppoem and cquote) are prese...
-
[23]
Secondary template removal : In addition to selective pro- cessing, a broader sweep removes any remaining template structures enclosed in double braces ( {{ ... }} ). This is achieved by scanning for opening braces and matching them with their corresponding closing braces, even in cases of nested templates. The result is a clean removal of markup ranges, ...
-
[24]
Links that point to images or files are removed entirely, as they do not contribute textual content
Wikilinks: All remaining link nodes are inspected and pro- cessed. Links that point to images or files are removed entirely, as they do not contribute textual content. For the remainder, the visible text is preserved, just like in the previous pass: if a link is of the form [[Target|Visible]], only the Visible part is retained; if no alternate text is pro...
-
[25]
T ables: Tables are a frequent source of markup complexity, of- ten containing nested structures and irregular formatting. To handle them, the pipeline first balances unclosed table tags by adding missing delimiters where necessary (which is rare but it does happen, especially if the article ends with a table). Each table is then parsed row by row, with r...
-
[26]
Section removal: For most Wikimedia projects (all but Wik- iquote), only the main textual sections are retained. Sections whose headings match a predefined list of unwanted titles (such as References, Gallery and External links including ap- propriate localization variants) are discarded. The procedure ensures that empty sections or those consisting solel...
-
[27]
All other sections are removed
Section filtering (Wikiquote) : In the case of Wikiquote, the logic is reversed: only sections explicitly marked as con- taining quotations (such as quotes, sourced and attributed in- cluding appropriate localization variants) are retained. All other sections are removed. This guarantees that the result- ing corpus consists exclusively of the intended con...
-
[28]
Each head- ing level is tracked with counters, producing a numbering scheme (e.g
Heading processing : Headings are normalised and enumer- ated to provide a consistent hierarchical structure. Each head- ing level is tracked with counters, producing a numbering scheme (e.g. 1, 1.1, 1.2) that reflects the document’s outline. The heading text itself is stripped of markup and reinserted into the text with the corresponding enumeration. Thi...
-
[29]
T ag cleaning: All remaining HTML‑like tags are detected via regular expression and inspected. Tags belonging to a pre- defined destroy list (noinclude, ref, gallery and timeline) are removed entirely, while the remaining, if not in the preserve list (math, code, syntaxhighlight, b, sup, sub), are stripped of their markup but retain their inner content. T...
-
[30]
[[fr:Page]]) are removed, as they point to external projects rather than contributing text
Interwiki links and hanging templates : Cross‑language links (e.g. [[fr:Page]]) are removed, as they point to external projects rather than contributing text. Incomplete or hanging template fragments (e.g. {{something|) are collapsed to pre- vent malformed markup from appearing in the corpus
-
[31]
This step guarantees that the text is free of syntactic artifacts
Markup stripping : A secondary parsing pass is applied to strip any remaining wiki markup nodes, ensuring that head- ings, links, and other constructs are reduced to plain text. This step guarantees that the text is free of syntactic artifacts
-
[32]
Regular expression final clean‑up : A final regular ex- pression sweep removes special magic words (e.g. __TOC__) meaning table of contents , stray closing tags not in the pre- served list, and leftover template attributes such as key–value pairs. Additional replacements handle dangling link markers and language‑specific constructs. Whitespace is normalis...
-
[33]
T oken extraction: Each article is normalised and trans- formed into a sequence of tokens. Normalization includes low- ercasing, replacing digits with placeholders, and splitting text into words and symbols. The resulting tokens are counted to capture word frequencies
-
[34]
Tokens that occur fewer three times are discarded to reduce the noise
V ocabulary building: A single vocabulary is constructed by aggregating token counts across the single dataset. Tokens that occur fewer three times are discarded to reduce the noise. The remaining tokens are sorted by frequency, and each is assigned a unique index. This vocabulary serves as the basis for the encoding, as well as insight into token frequen...
-
[35]
V ector encoding: Articles exceeding 2000 words are at this point excluded from checkup to avoid skew from excessively long or anomalous texts, which also speeds up the compar- isons further down the pipeline (all under the assumption that longer texts are less likely to be template generated). Each article shorter than 2000 words is converted into a vect...
work page 2000
-
[36]
This dataset can be reloaded efficiently without repeating the encoding process
Dataset creation : The encoded vectors are written to a line‑oriented JSON file, forming a structured dataset of ar- ticles represented numerically. This dataset can be reloaded efficiently without repeating the encoding process. By encoding text into vectors, the corpus is transformed into a format that enables quantitative comparison. Vectors can now be...
-
[37]
If the article length is insufficient, its category labels are extracted
Category indexing : Each record is examined for its associ- ated category subject field. If the article length is insufficient, its category labels are extracted. Articles may belong to a single or multiple categories, so all are indexed accordingly
-
[38]
This creates initial clusters of texts that are topically related
Cluster formation : Articles sharing the same category are grouped together into buckets. This creates initial clusters of texts that are topically related
-
[39]
Pruning oversised clusters : To prevent distortion (and higher computation) that comes with pairwise comparison in overly large clusters, buckets exceeding a maximum size (3000) are split into smaller chunks (up to 3000 articles each). By clustering articles according to their categories and chunk- ing over-sized groups, this step establishes a structured...
-
[40]
MinHashing: Traditional Jaccard similarity ( Jaccard, 1901) measures the overlap between two sets of n-grams, defined as: J(A, B) = |A ∩ B| |A ∪ B| where A and B are the sets of n-grams extracted from two se- quences. While exact Jaccard computations are accurate, they are computationally expensive when applied to large clusters of documents such as this ...
work page 1901
-
[41]
Similarity Scoring To measure similarity between articles in this case, MinHash signatures built on trigram representations are deployed. Each sequence is first decomposed into contiguous trigrams, which are then hashed under multiple permutations, and the mini- mum hash values are recorded to form a compact, fixed-length signature. Within a cluster of re...
-
[42]
Cutoff For each article we calculate a single score as the av- erage of previously saved top three scores. If there are fewer than three scores for an article, zero-padding is performed be- fore calculating the average. Once there is a score for each article, the scores are compiled into a single sorted list and evaluated using the KneeLocator algorithm (...
work page 2011
-
[43]
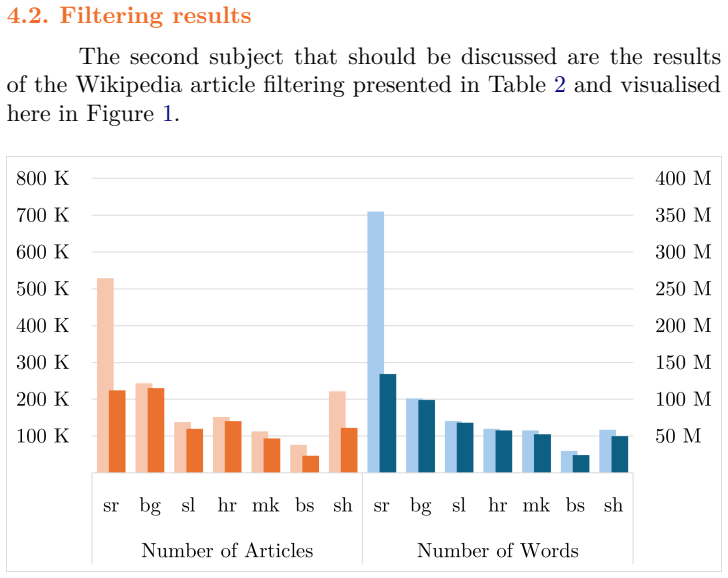
Discussion This paper had been focused on the extraction, cleaning, and filtering of textual data from Wikimedia projects in seven South Slavic languages. The methodology combined markup stripping and similarity analysis to improve the probability that the resulting cor- pora consist of authentic, naturally written texts. 4.1. Extraction results The resul...
work page 2026
-
[44]
In 31st International Conference on Distributed Computing Systems Workshops , pages 166–171
Finding a ”kneedle” in a haystack: Detecting knee points in system behavior. In 31st International Conference on Distributed Computing Systems Workshops , pages 166–171. Mengting Song, Hang Zheng, Zhen Tao, Jia Jiang, and Bin Pan. 2021. Research on methods of parsing and classification of internet super large-scale texts. In Journal of Physics: Conference...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.