The Nonverbal Syntax Framework: An Evidence-Based Tiered System for Inferring Learner States from Observable Behavioral Cues
Pith reviewed 2026-05-07 16:10 UTC · model grok-4.3
The pith
The Nonverbal Syntax Framework provides an evidence-tiered system that identifies 480 replicated nonverbal cue-state relationships for inferring learner cognitive and affective states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
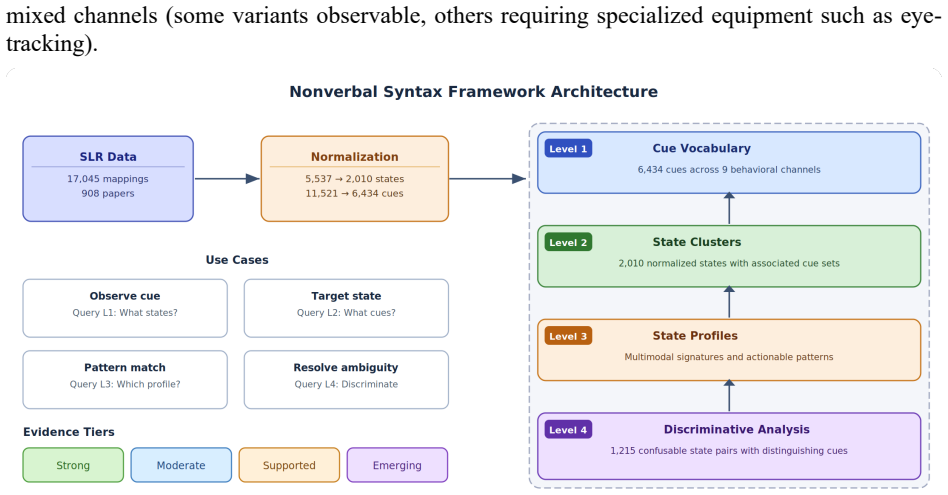
The Nonverbal Syntax Framework, drawn from a systematic review of 908 studies and 17,043 cue-state mappings, normalizes 5,537 state labels into 2,010 canonical states and 11,521 cues into 6,434 normalized cues, applies dual-evidence assessment to separate component coverage from relationship replication, and structures the results into four levels that highlight 480 actionable relationships supported by three or more papers as the replicated core across 47 key states.
What carries the argument
The dual-evidence assessment that evaluates Component Evidence for coverage of cues and states separately from Relationship Evidence counting independent studies per cue-state link.
If this is right
- Researchers can use the framework to spot which of the thousands of findings need replication to move from exploratory to actionable.
- Practitioners can apply the 480 replicated relationships and their multimodal signatures to infer learner states with calibrated confidence.
- Technologists can select the 111 distinct indicators from the replicated core as reliable features for multimodal AI detection systems.
- The structure prevents overconfident inferences from single-observation data by design.
- The discriminative analysis helps resolve ambiguities among 1,215 confusable state pairs.
Where Pith is reading between the lines
- This tiered approach could be applied in real-time educational software to adjust instruction based on detected states while reporting the evidence level to users.
- The normalization technique might transfer to other fields involving behavioral observation, such as human-computer interaction or clinical assessment, to create similar standardized vocabularies.
- Future work could test the framework by collecting new observational data and checking how well the 480 core relationships predict actual learner performance metrics.
Load-bearing premise
The systematic review comprehensively covers relevant literature without selection bias and the normalization of varied state and cue labels preserves their intended meanings without substantial distortion.
What would settle it
Observing in a new set of controlled studies that fewer than half of the 480 relationships backed by multiple papers show consistent cue-state associations would indicate the replicated core is less stable than presented.
Figures





read the original abstract
Understanding learners' cognitive and affective states underpins adaptive educational systems and effective teaching. Although research links nonverbal cues to internal states, no framework calibrates them to evidence. We present the Nonverbal Syntax Framework, drawn from a systematic review of 908 studies and 17,043 cue-state mappings (Turaev et al., 2026). The framework addresses three challenges: terminological fragmentation (behaviors described inconsistently), evidence heterogeneity (single observations to replicated findings), and state ambiguity (similar patterns indicating multiple states). Normalization consolidated 5,537 state labels into 2,010 canonical states (63.7%) and 11,521 cues into 6,434 normalized cues (44.2%) across nine behavioral channels. Dual-evidence assessment separately evaluates Component Evidence (coverage of cues and states) and Relationship Evidence (independent studies per cue-state link). 52% of "Very High" relationships rest on one paper, so separation enables calibrated rather than overconfident inference from preliminary findings. The framework's four levels comprise a Cue Vocabulary of 6,434 indicators classified as observable/instrumental; State Clusters linking 2,010 states to indicative cues; State Profiles with multimodal behavioral signatures and actionable specifications; and Discriminative Analysis distinguishing 1,215 confusable state pairs. We identify 480 actionable R1-R4 relationships (three or more independent papers), the replicated core of six decades of research, covering 35.5% of mappings across 47 key learning states and 111 distinct indicators. The remaining 91.5% (9,653 single-paper findings) form exploratory hypotheses for replication. The framework gives researchers an empirical foundation for identifying gaps, practitioners evidence-based tools for state inference, and technologists validated features for multimodal detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Nonverbal Syntax Framework, constructed from a systematic review of 908 studies encompassing 17,043 cue-state mappings. It normalizes 5,537 state labels into 2,010 canonical states and 11,521 cues into 6,434 normalized cues across nine behavioral channels. The framework employs a dual-evidence assessment for component coverage and relationship replication, organizing findings into four tiers: Cue Vocabulary, State Clusters, State Profiles, and Discriminative Analysis. It identifies 480 replicated R1-R4 relationships (supported by three or more independent papers) as the actionable core, while classifying the remaining 91.5% as exploratory hypotheses.
Significance. If the normalization preserves original meanings without distortion and the evidence grading is shown to be reliable, the framework would constitute a significant synthesis of research on nonverbal cues in educational contexts. It would supply researchers with a structured basis for identifying replication gaps, practitioners with calibrated inference tools differentiated by evidence strength, and technologists with a validated set of multimodal features drawn from the replicated core of 480 relationships.
major comments (2)
- [Abstract and framework construction] The normalization step that reduces 5,537 state labels to 2,010 canonical states (63.7% reduction) and 11,521 cues to 6,434 normalized cues (44.2% reduction) is described in the abstract but provides no details on inter-rater reliability, explicit merging decision rules, or quantitative checks for semantic preservation and information loss. Because the Cue Vocabulary, State Clusters, State Profiles, and Discriminative Analysis all depend on these canonical entities, and the dual-evidence assessment (Component vs. Relationship) is applied post-normalization, this gap is load-bearing for the claim that the framework supplies an evidence-based tiered system.
- [Evidence assessment and results] The manuscript acknowledges that 52% of Very High relationships rest on single papers yet does not report inter-rater reliability metrics or validation procedures for the extraction of the 17,043 original cue-state mappings from the 908 studies. Without such metrics, the separation into 480 R1-R4 replicated relationships and 9,653 exploratory hypotheses cannot be fully evaluated for robustness.
minor comments (1)
- [Abstract] Clarify the publication status and authorship overlap of the cited systematic review (Turaev et al., 2026) to distinguish the contributions of the present framework paper from the source review.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments identify important areas where additional methodological transparency will strengthen the presentation of the Nonverbal Syntax Framework. We address each major comment point by point below and indicate the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract and framework construction] The normalization step that reduces 5,537 state labels to 2,010 canonical states (63.7% reduction) and 11,521 cues to 6,434 normalized cues (44.2% reduction) is described in the abstract but provides no details on inter-rater reliability, explicit merging decision rules, or quantitative checks for semantic preservation and information loss. Because the Cue Vocabulary, State Clusters, State Profiles, and Discriminative Analysis all depend on these canonical entities, and the dual-evidence assessment (Component vs. Relationship) is applied post-normalization, this gap is load-bearing for the claim that the framework supplies an evidence-based tiered system.
Authors: We agree that the normalization methodology requires fuller documentation to support the framework's downstream components. The full manuscript (Methods, Section 3) outlines the process as a multi-stage procedure using lexical standardization followed by semantic clustering guided by established taxonomies in educational psychology and nonverbal behavior research, with disagreements resolved by consensus. However, explicit inter-rater reliability coefficients and quantitative semantic-preservation metrics are not reported. We will revise the manuscript to add a dedicated subsection detailing the merging decision rules (including equivalence criteria and tie-breaking procedures) and any available quantitative checks from the original coding process. If formal inter-rater statistics were not computed in the source review, we will state this limitation transparently while describing the safeguards used. revision: yes
-
Referee: [Evidence assessment and results] The manuscript acknowledges that 52% of Very High relationships rest on single papers yet does not report inter-rater reliability metrics or validation procedures for the extraction of the 17,043 original cue-state mappings from the 908 studies. Without such metrics, the separation into 480 R1-R4 replicated relationships and 9,653 exploratory hypotheses cannot be fully evaluated for robustness.
Authors: We accept that the extraction validation procedures should be summarized in the present manuscript rather than relying solely on the cited source review. The 17,043 mappings originate from the systematic review (Turaev et al., 2026), which applied PRISMA-compliant double screening with third-party adjudication for disagreements. We will add an explicit paragraph in the Methods section summarizing the extraction validation steps and clarifying that the R1–R4 replication tiers are computed from independent study counts rather than single-paper quality. The 52% figure is retained precisely to signal that many high-evidence relationships still require further replication; the tiered structure is intended to permit calibrated inference rather than to claim uniform robustness across all entries. revision: yes
Circularity Check
No significant circularity; framework organizes data from cited systematic review
full rationale
The paper presents the Nonverbal Syntax Framework as drawn from an external systematic review (Turaev et al., 2026) that compiles 908 studies and 17,043 mappings. This review serves as the input data source, which the current work then normalizes, clusters, profiles, and grades via dual-evidence assessment. Although the citation shares lead authorship, the review itself aggregates independently published literature and remains externally falsifiable through replication of the search and extraction process. No claimed result, count of relationships, or tiered structure reduces by construction to a redefinition or refit of the paper's own outputs; the 480 R1-R4 relationships and 91.5% exploratory hypotheses are direct tallies from the compiled mappings after normalization. The derivation chain is therefore self-contained against the external literature benchmark rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Systematic reviews can reliably aggregate cue-state mappings across studies despite variations in methodology
invented entities (1)
-
Nonverbal Syntax Framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Channel distribution profiles for key learning states. Each line represents one state (engagement, confusion, frustration, boredom, attention, happiness) and traces the proportion of that state’s total mappings across the seven major behavioral channels (facial expressions, eye movements, body posture, head movements, voice/paralinguistic, hand/arm gestur...
work page 2014
-
[2]
Confusion Multimodal Signature Channel Top Cues Evidence Facial AU4 brow lowerer (35), AU7 lid tightener (14), AU12 lip corner puller (11), frown (8) R1–R3 Eye Repeated fixation on same elements (6), gaze toward material (5), increased blink rate (4) R3–R4 Head Head tilt (questioning) (4), head shake (3) R4 Body Leaning toward screen (3), stillness/pause ...
work page 2007
-
[3]
Frustration Multimodal Signature Channel Top Cues Evidence Facial AU4 brow lowerer (15), frown (12), tightened jaw (8), AU23 lip tightener (6) R2–R3 Eye Gaze away from task (7), eye rolling (3) R3–R4 Head Head shake (negative) (4), head drop (3) R4 Body Tense posture (5), restlessness (4), leaning back (3) R3–R4 Gesture Banging on keyboard (5), pulling ha...
work page 2010
-
[4]
Boredom Multimodal Signature Channel Top Cues Evidence Facial Neutral/flat expression (12), yawning (8), drooping eyelids (5) R2–R3 Eye Gaze wandering away (9), looking at clock/door (4), reduced fixation (4) R3–R4 Head Head resting on hand/palm (4), head propping (3) R4 Body Slouching (10), slumped posture (6), resting chin on palm (4) R2–R4 Gesture Fidg...
work page 2004
-
[5]
A student shows reduced activity and occasional yawning. Both boredom and fatigue include these cues. Discriminative analysis suggests: if slouching and resting chin on palm are also present, the most likely state is boredom; if eye rubbing and stretching are present, the most likely state is fatigue. 3.6 Framework Integration The four levels work togethe...
work page 2012
-
[6]
Relationship Evidence Tier Distribution Tier Criterion Count Interpretation R1: Strong ≥20 papers 47 Extensively replicated link R2: Substantial 10–19 papers 63 Well-documented relationship R3: Moderate 5–9 papers 137 Solid replication R4: Supported 3–4 papers 233 Reasonable evidence R5: Emerging 2 papers 420 Preliminary, needs validation R6: Exploratory ...
work page 2009
-
[7]
What might this behavior indicate?
Power-law fit to the distribution of papers per cue-state relationship. (a) Complementary cumulative distribution function on log-log axes, with the empirical CCDF (solid blue) and the maximum-likelihood power-law fit (dashed red). (b) Probability density function on log-log axes, with empirical points (blue) and fitted power-law (dashed red). The data-dr...
work page 2022
-
[8]
Second, the empirical evidence base itself is heavily weighted toward recent research: 56.8% of the 908 studies underlying the framework were published between 2020 and 2025, ensuring that contemporary learning contexts, including remote and hybrid settings, are well represented in the actionable relationships. Third, however, certain context-bound cues a...
work page 2020
-
[9]
2014, PLOS ONE, 9, 1, doi: 10.1371/journal.pone.0085777 Andr´ e, P
CONCLUSION This paper introduced the Nonverbal Syntax Framework, a systematic approach to organizing empirical knowledge about the behavioral manifestations of cognitive and affective states in learning contexts. Built on a comprehensive systematic literature review of 908 empirical studies yielding 17,043 cue-state mappings (Turaev et al., 2026), the fra...
-
[10]
https://doi.org/10.1186/s40561-018-0080-z D’Mello, S., & Graesser, A. (2012). Dynamics of affective states during complex learning. Learning and Instruction, 22(2), 145–157. https://doi.org/10.1016/j.learninstruc.2011.10.001 D’Mello, S., & Graesser, A. (2014). Confusion. In R. Pekrun & L. Linnenbrink-Garcia (Eds.), International handbook of emotions in ed...
-
[11]
https://doi.org/10.1186/s40561-020-00122-x Sharma, P., & Hannafin, M. J. (2007). Scaffolding in technology-enhanced learning environments. Interactive Learning Environments, 15(1), 27–46. https://doi.org/10.1080/10494820600996972 Turaev, S., John, M. J., Rustamov, Z., Rustamov, J., Al-Dabet, S., Zaki, N., & Shuaib, K. (2026). Nonverbal indicators of learn...
-
[12]
https://doi.org/10.3389/fpsyg.2017.01454 Whitehill, J., Serpell, Z., Lin, Y.-C., Foster, A., & Movellan, J. R. (2014). The faces of engagement: Automatic recognition of student engagement from facial expressions. IEEE Transactions on Affective Computing, 5(1), 86–98. https://doi.org/10.1109/TAFFC.2014.2316163 Woolf, B., Burleson, W., Arroyo, I., Dragon, T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.