No Tile Left Behind: Multiprogramming for Surface-Code Architectures
Pith reviewed 2026-05-07 16:39 UTC · model grok-4.3
The pith
A scheduler for surface-code quantum architectures achieves 3.1 times speedup in multiprogramming by accounting for tiles, ancilla, and magic-state resources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper proposes a hierarchy-aware scheduling framework for FTQC multiprogramming that models the constraints of data tiles, ancilla tiles, and magic-state resources in surface-code architectures. It formulates the static allocation problem and extends it to online and cultivation-enabled settings, demonstrating through simulation on Clifford+T workloads a normalized system speedup of 3.1x over baselines while keeping mean slowdown low.
What carries the argument
Hierarchy-aware scheduling policies that handle limited resources, online admission decisions, and dynamic magic-state cultivation while respecting tile placement, connectivity, routing headroom, and shared support infrastructure.
If this is right
- Multiprogramming becomes feasible on structured FTQC floorplans without rapid fragmentation of remaining space.
- Overall system throughput rises as more programs execute concurrently on the same hardware.
- Individual programs experience only low mean slowdown, preserving acceptable quality of service.
- Dynamic magic-state generation integrates into the scheduler without major degradation in performance.
Where Pith is reading between the lines
- The same modeling of tile and ancilla constraints could extend to other error-correcting codes that also impose structured layouts.
- Hardware featuring extra ancilla pools or more flexible routing might show even larger gains than the simulated results.
- Coupling the scheduler with circuit compilers that optimize for tile adjacency could increase the observed speedups.
- Real application traces might expose contention patterns not present in the synthetic Clifford+T test cases.
Load-bearing premise
The synthetic Clifford+T workloads and the modeled tile, ancilla, and magic-state constraints accurately represent the behavior and resource demands of future real-world FTQC applications.
What would settle it
Running the proposed scheduler on physical surface-code hardware or with workloads drawn from practical algorithms such as Shor's factoring or variational quantum eigensolvers and measuring whether the 3.1x speedup and 29 percent improvement over baselines still appear.
Figures









read the original abstract
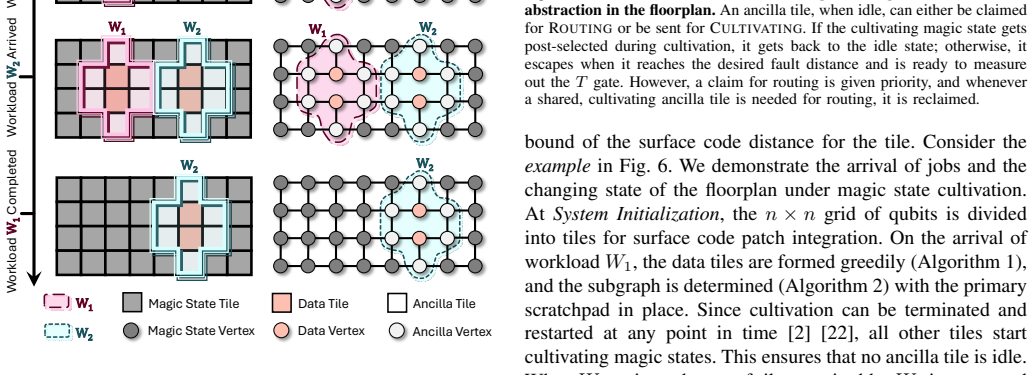
Fault-tolerant quantum computing (FTQC) is emerging as the architectural regime in which practical large-scale quantum workloads will execute. In this setting, however, multiprogramming is no longer a matter of partitioning a flat pool of qubits. Quantum error correction exposes a structured floorplan of data tiles, ancilla tiles, and magic-state service resources, so concurrent execution must account for compact placement, connectivity, routing headroom, and shared support infrastructure. This makes FTQC multiprogramming fundamentally harder than its NISQ counterpart: admission decisions can fragment the remaining floorplan, conservative reservations can waste ancilla, and dynamic contention across data, ancilla, and magic-state resources can degrade both throughput and quality of service. In this work, we develop a formal framework for FTQC multiprogramming that captures these structural constraints and their runtime implications. We formulate the baseline static allocation problem, extend it to limited-resource and online settings through hierarchy-aware scheduling policies, and further generalize it to cultivation-enabled architectures with dynamic magic-state generation. Through simulation on synthetic Clifford+T workloads, the proposed scheduler achieves a normalized system speedup of 3.1x, improving over prior FTQC multiprogramming baselines by ~29% while maintaining low mean slowdown.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a formal framework for multiprogramming in surface-code FTQC architectures that accounts for structured floorplans of data tiles, ancilla tiles, and magic-state resources. It formulates the static allocation problem, extends it to limited-resource and online settings via hierarchy-aware scheduling policies, and generalizes further to cultivation-enabled architectures with dynamic magic-state generation. Simulations on synthetic Clifford+T workloads are used to claim a 3.1x normalized system speedup with a ~29% improvement over prior FTQC multiprogramming baselines while maintaining low mean slowdown.
Significance. If the performance claims prove robust, the work would be significant for FTQC systems by providing the first structured treatment of tile fragmentation, routing headroom, and cross-resource contention that distinguish FTQC multiprogramming from NISQ approaches. The hierarchy-aware and cultivation-enabled policies represent a concrete advance over flat allocation models.
major comments (1)
- [Evaluation / Simulation Results] The central performance claims (3.1x normalized speedup and ~29% gain over baselines) rest entirely on simulation results for synthetic Clifford+T workloads under a modeled tile/ancilla/magic-state floorplan. No details are provided on workload generation, circuit-shape distributions, statistical error bars, or independent validation against mapped real algorithms (e.g., Shor or chemistry circuits). Because synthetic generation can understate irregular fragmentation or overstate magic-state reuse, the external validity of the reported advantage is not yet established and directly affects the load-bearing speedup claim.
minor comments (1)
- [Abstract] The abstract refers to 'prior FTQC multiprogramming baselines' without naming the specific prior schedulers or policies used for the 29% comparison; adding one sentence of identification would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of our framework for FTQC multiprogramming. We address the evaluation concerns point by point below and commit to targeted revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: The central performance claims (3.1x normalized speedup and ~29% gain over baselines) rest entirely on simulation results for synthetic Clifford+T workloads under a modeled tile/ancilla/magic-state floorplan. No details are provided on workload generation, circuit-shape distributions, statistical error bars, or independent validation against mapped real algorithms (e.g., Shor or chemistry circuits). Because synthetic generation can understate irregular fragmentation or overstate magic-state reuse, the external validity of the reported advantage is not yet established and directly affects the load-bearing speedup claim.
Authors: We agree that greater transparency on the synthetic workload methodology is needed. In the revised manuscript we will add a dedicated subsection describing the workload generator: the parameterization of circuit shapes (gate-count and depth distributions drawn from Clifford+T ensembles), the sampling procedure used to produce varied fragmentation and contention scenarios, and the inclusion of 95% confidence intervals on all speedup and slowdown figures. These additions directly address the missing details on generation and error bars. On independent validation, our study deliberately employs synthetic workloads to enable systematic sweeps over parameters such as tile fragmentation and cross-resource contention that are hard to isolate when mapping specific real circuits. While we acknowledge that evaluating mapped instances of Shor’s algorithm or quantum-chemistry circuits would provide complementary evidence, performing those mappings and full simulations lies outside the scope of the present framework paper. We will therefore add an explicit limitations paragraph and a future-work statement rather than claim such validation is already present. revision: partial
- Independent validation on mapped real algorithms (e.g., Shor or chemistry circuits) cannot be supplied in the current revision without substantial new simulation work.
Circularity Check
No circularity: performance claims rest on external simulation runs
full rationale
The paper defines a scheduling framework for surface-code multiprogramming and evaluates it via simulation on explicitly described synthetic Clifford+T workloads. The reported 3.1x normalized speedup and 29% improvement are measured outcomes of running the proposed policies against those workloads under modeled tile/ancilla/magic-state constraints; they are not obtained by fitting parameters to the target metric or by renaming inputs as predictions. No self-definitional equations, load-bearing self-citations, or ansatz smuggling appear in the derivation of the scheduler or its reported results. The evaluation chain remains independent of the claims it supports.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
High-threshold and low-overhead fault-tolerant quantum memory,
S. Bravyi, A. W. Cross, J. M. Gambetta, D. Maslov, P. Rall, and T. J. Yoder, “High-threshold and low-overhead fault-tolerant quantum memory,”Nature, vol. 627, p. 778–782, Mar. 2024
work page 2024
-
[2]
Magic state cultivation: growing t states as cheap as cnot gates,
C. Gidney, N. Shutty, and C. Jones, “Magic state cultivation: growing t states as cheap as cnot gates,” 2024
work page 2024
-
[3]
Atom Computing product page for the AC1000 system; accessed April 7, 2026
Atom Computing, “Ac1000,” 2026. Atom Computing product page for the AC1000 system; accessed April 7, 2026
work page 2026
-
[4]
2026 in quantum: A strategic preview from atom computing and partners,
Atom Computing, “2026 in quantum: A strategic preview from atom computing and partners,” Jan. 2026. Atom Computing Tech Perspectives, published January 7, 2026; accessed April 7, 2026
work page 2026
-
[5]
How ibm will build the world’s first large-scale, fault- tolerant quantum computer,
R. Mandelbaum, J. Gambetta, J. Chow, T. Mittal, T. J. Yoder, A. Cross, and M. Steffen, “How ibm will build the world’s first large-scale, fault- tolerant quantum computer,” June 2025. IBM Quantum Blog, published June 10, 2025; accessed April 7, 2026
work page 2025
-
[6]
Surface codes: Towards practical large-scale quantum computation,
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, “Surface codes: Towards practical large-scale quantum computation,”Physical Review A, vol. 86, Sept. 2012
work page 2012
-
[7]
Surface code quantum computing by lattice surgery,
D. Horsman, A. G. Fowler, S. Devitt, and R. V . Meter, “Surface code quantum computing by lattice surgery,”New Journal of Physics, vol. 14, p. 123011, Dec. 2012
work page 2012
-
[8]
Lattice surgery with a twist: Simplifying clifford gates of surface codes,
D. Litinski and F. v. Oppen, “Lattice surgery with a twist: Simplifying clifford gates of surface codes,”Quantum, vol. 2, p. 62, May 2018
work page 2018
-
[9]
A game of surface codes: Large-scale quantum computing with lattice surgery,
D. Litinski, “A game of surface codes: Large-scale quantum computing with lattice surgery,”Quantum, vol. 3, p. 128, Mar. 2019
work page 2019
-
[10]
Design automation in quantum error correction,
A. Ghosh, A. Chatterjee, and S. Ghosh, “Design automation in quantum error correction,” 2025
work page 2025
-
[11]
T. Kobori, Y . Suzuki, Y . Ueno, T. Tanimoto, S. Todo, and Y . Tokunaga, “Lsqca: Resource-efficient load/store architecture for limited-scale fault- tolerant quantum computing,” in2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), p. 304–320, IEEE, Mar. 2025
work page 2025
-
[12]
Surface code compila- tion via edge-disjoint paths,
M. Beverland, V . Kliuchnikov, and E. Schoute, “Surface code compila- tion via edge-disjoint paths,”PRX Quantum, vol. 3, May 2022
work page 2022
-
[13]
Toward designing workload- aware surface code architectures,
A. Ghosh, A. Chatterjee, and S. Ghosh, “Toward designing workload- aware surface code architectures,” 2026
work page 2026
-
[14]
A. Chatterjee, S. Das, and S. Ghosh, “Lattice surgery for dummies,” Sensors, vol. 25, p. 1854, Mar. 2025
work page 2025
-
[15]
Dependency- aware compilation for surface code quantum architectures,
A. Molavi, A. Xu, S. Tannu, and A. Albarghouthi, “Dependency- aware compilation for surface code quantum architectures,”Proc. ACM Program. Lang., vol. 9, Apr. 2025
work page 2025
-
[16]
Magic state distillation: Not as costly as you think,
D. Litinski, “Magic state distillation: Not as costly as you think,” Quantum, vol. 3, p. 205, Dec. 2019
work page 2019
-
[17]
Magic-state distillation with low overhead,
S. Bravyi and J. Haah, “Magic-state distillation with low overhead,” Physical Review A, vol. 86, Nov. 2012
work page 2012
-
[18]
Multi-qubit lattice surgery scheduling,
A. Silva, X. Zhang, Z. Webb, M. Kramer, C.-W. Yang, X. Liu, J. Lemieux, K.-W. Chen, A. Scherer, and P. Ronagh, “Multi-qubit lattice surgery scheduling,” vol. 310, pp. 1:1–1:22, Schloss Dagstuhl – Leibniz- Zentrum f ¨ur Informatik, 2024
work page 2024
-
[19]
Synchronization for fault-tolerant quantum computers,
S. Maurya and S. Tannu, “Synchronization for fault-tolerant quantum computers,” inProceedings of the 52nd Annual International Sympo- sium on Computer Architecture, ISCA ’25, (New York, NY , USA), p. 1370–1385, Association for Computing Machinery, 2025
work page 2025
-
[20]
Swiper: Minimizing fault-tolerant quantum program latency via speculative window decoding,
J. Viszlai, J. D. Chadwick, S. Joshi, G. S. Ravi, Y . Li, and F. T. Chong, “Swiper: Minimizing fault-tolerant quantum program latency via speculative window decoding,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, ISCA ’25, (New York, NY , USA), p. 1386–1401, Association for Computing Machinery, 2025
work page 2025
-
[21]
Better than worst-case decoding for quantum error correction,
G. S. Ravi, J. M. Baker, A. Fayyazi, S. F. Lin, A. Javadi-Abhari, M. Pedram, and F. T. Chong, “Better than worst-case decoding for quantum error correction,” 2022
work page 2022
-
[22]
Scheduling lattice surgery with magic state cultivation,
S. Hofmeyr, M. Weiden, J. Kalloor, J. Kubiatowicz, and C. Iancu, “Scheduling lattice surgery with magic state cultivation,” 2026
work page 2026
-
[23]
An approximate solution for steiner problem in graphs,
H. Takahashi, “An approximate solution for steiner problem in graphs,” Math. Japonica, vol. 24, no. 6, pp. 573–577, 1980
work page 1980
-
[24]
Magic state cultivation on a superconducting quantum processor,
E. Rosenfeld, C. Gidney, G. Roberts, A. Morvan, N. Lacroix, D. Kafri, J. Marshall, M. Li, V . Sivak, D. Abanin, A. Abbas, R. Acharya, L. A. Beni, G. Aigeldinger, R. Alcaraz, S. Alcaraz, T. I. Andersen, M. Ansmann, F. Arute, K. Arya, W. Askew, N. Astrakhantsev, J. Atalaya, R. Babbush, B. Ballard, J. C. Bardin, H. Bates, A. Bengtsson, M. B. Karimi, A. Bilme...
work page 2025
-
[25]
Online job scheduler for fault-tolerant quantum multiprogramming,
R. Wakizaka, S. Nishio, D. Sakuma, Y . Ueno, and Y . Suzuki, “Online job scheduler for fault-tolerant quantum multiprogramming,” in2025 IEEE International Conference on Quantum Computing and Engineering (QCE), p. 779–790, IEEE, Aug. 2025
work page 2025
-
[26]
Y . Ueno, T. Saito, T. Tanimoto, Y . Suzuki, Y . Tabuchi, S. Tamate, and H. Nakamura, “High-performance and scalable fault-tolerant quantum computation with lattice surgery on a 2.5d architecture,” 2024
work page 2024
-
[27]
A case for multi- programming quantum computers,
P. Das, S. S. Tannu, P. J. Nair, and M. Qureshi, “A case for multi- programming quantum computers,” inProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, MICRO- 52, (New York, NY , USA), p. 291–303, Association for Computing Machinery, 2019
work page 2019
-
[28]
A new qubits mapping mechanism for multi- programming quantum computing,
X. Dou and L. Liu, “A new qubits mapping mechanism for multi- programming quantum computing,” inProceedings of the ACM Inter- national Conference on Parallel Architectures and Compilation Tech- niques, PACT ’20, (New York, NY , USA), p. 349–350, Association for Computing Machinery, 2020
work page 2020
-
[29]
Simultaneous execution of quantum circuits on current and near-future nisq systems,
Y . Ohkura, T. Satoh, and R. Van Meter, “Simultaneous execution of quantum circuits on current and near-future nisq systems,”IEEE Transactions on Quantum Engineering, vol. 3, p. 1–10, 2022
work page 2022
-
[30]
Adaptive job and resource management for the growing quantum cloud,
G. S. Ravi, K. N. Smith, P. Murali, and F. T. Chong, “Adaptive job and resource management for the growing quantum cloud,” 2022
work page 2022
-
[31]
Enabling multi-programming mechanism for quantum computing in the nisq era,
S. Niu and A. Todri-Sanial, “Enabling multi-programming mechanism for quantum computing in the nisq era,”Quantum, vol. 7, p. 925, Feb. 2023
work page 2023
-
[32]
Qos: A quantum operating system,
E. Giortamis, F. Rom ˜ao, N. Tornow, and P. Bhatotia, “Qos: A quantum operating system,” 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.