Evaluating Strategic Reasoning in Forecasting Agents
Pith reviewed 2026-05-07 16:05 UTC · model grok-4.3
The pith
Frontier AI agents' main forecasting weaknesses lie in judging leaders' incentives, plan follow-through, and institutional dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
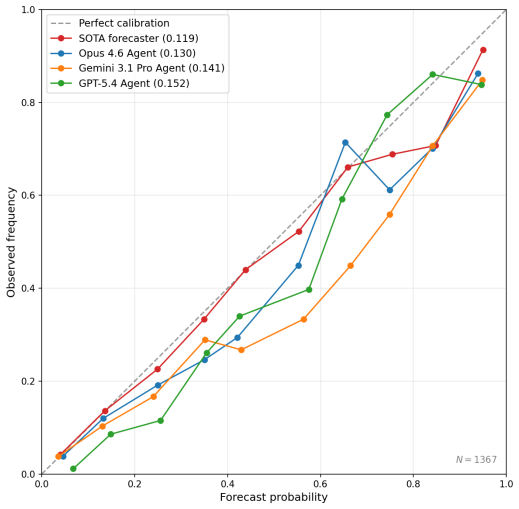
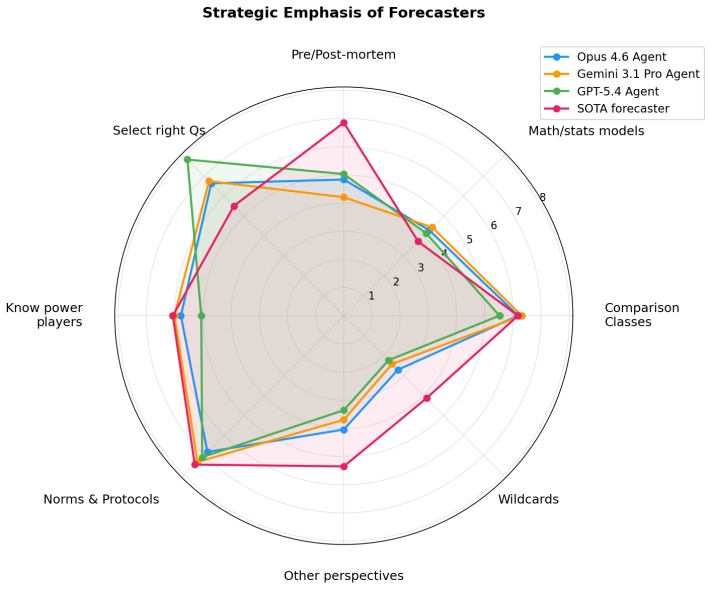
Using the BTF-2 benchmark of 1,417 pastcasting questions with a frozen research corpus, the authors show that a composite forecaster outperforms individual frontier agents by 0.011 in Brier score, primarily through better pre-mortem analysis of its own blind spots and explicit consideration of black swan events. Expert human forecasters reviewing the traces identify the dominant strategic reasoning failures as inadequate assessment of political and business leaders' incentives, underestimation of whether stated plans will be followed, and incomplete modeling of institutional processes.
What carries the argument
BTF-2 benchmark consisting of pastcasting questions and a frozen 15M-document corpus that enables reproducible, hindsight-free evaluation of agent reasoning traces.
Load-bearing premise
That the specific 1,417 pastcasting questions and the 15M-document frozen corpus provide an unbiased, generalizable test of strategic reasoning ability.
What would settle it
Running the same agents on a new set of pastcasting questions drawn from a different time period or topic distribution and finding that the same three failure modes no longer dominate expert judgments.
Figures
read the original abstract
Forecasting benchmarks produce accuracy leaderboards but little insight into why some forecasters are more accurate than others. We introduce Bench to the Future 2 (BTF-2), 1,417 pastcasting questions with a frozen 15M-document research corpus in which agents reproducibly research and forecast offline, producing full reasoning traces. BTF-2 detects accuracy differences of 0.004 Brier score, and can distinguish differential agent strengths in research vs. judgment. We build a forecaster 0.011 Brier more accurate than any single frontier agent, and use it to evaluate agent strategic reasoning without hindsight bias. We find the better forecaster differs primarily in its pre-mortem analysis of its blind spots and consideration of black swans. Expert human forecasters found the dominant strategic reasoning failures of frontier agents are in assessing political and business leaders' incentives, judging their likelihood to follow through on stated plans, and modeling institutional processes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bench to the Future 2 (BTF-2), a benchmark of 1,417 pastcasting questions paired with a frozen 15M-document research corpus. Agents perform offline research and forecasting to produce full reasoning traces; the benchmark distinguishes accuracy differences of 0.004 Brier score and research vs. judgment strengths. A composite forecaster is constructed that outperforms any single frontier agent by 0.011 Brier score. Expert human analysis of the traces identifies the dominant strategic-reasoning failures of frontier agents as assessing political/business leaders' incentives, judging follow-through on stated plans, and modeling institutional processes.
Significance. If the results hold, the work supplies concrete diagnostic evidence on why current agents underperform in forecasting, moving beyond accuracy leaderboards to actionable failure modes. The frozen-corpus, hindsight-free design and the construction of a demonstrably superior forecaster are strengths that could guide targeted improvements in agent reasoning.
major comments (2)
- [Abstract] Abstract: the assertion that the three listed failure modes are 'dominant' in frontier agents rests on expert analysis of traces from the BTF-2 set. No validation is provided that the 1,417 questions constitute a representative sample of strategic forecasting problems (e.g., no stratification by domain, no out-of-distribution hold-out set, no check against over-representation of political/business events), so generalization of the 'dominant' claim is not yet secured.
- [Evaluation and data sections] Evaluation and data sections: the manuscript reports concrete Brier-score deltas and human-expert analysis but supplies insufficient detail on question-selection criteria, exact composition of the 15M-document corpus, and plans for public data release. Without these, independent verification of leakage controls and reproducibility of the reported accuracy differences cannot be performed.
minor comments (2)
- [Abstract] Abstract: the reported Brier-score improvements (0.004 and 0.011) are given without accompanying standard errors, number of questions per comparison, or baseline definition, making it hard to judge statistical and practical significance.
- Notation: the distinction between 'research' and 'judgment' components of agent performance is introduced but not formally defined or operationalized in a way that allows readers to replicate the differential-strength analysis.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the three listed failure modes are 'dominant' in frontier agents rests on expert analysis of traces from the BTF-2 set. No validation is provided that the 1,417 questions constitute a representative sample of strategic forecasting problems (e.g., no stratification by domain, no out-of-distribution hold-out set, no check against over-representation of political/business events), so generalization of the 'dominant' claim is not yet secured.
Authors: We appreciate the referee's observation on the scope of the 'dominant' claim. The BTF-2 questions were selected to emphasize strategic forecasting challenges across domains, and the expert trace analysis identified the three failure modes as the most frequent within this set. We did not include explicit stratification or an OOD hold-out in the reported experiments. To address the concern, we will revise the abstract and discussion to qualify that these are the dominant failures observed in expert analysis of BTF-2 traces, rather than asserting broader dominance without additional validation. This change preserves the empirical finding while limiting overgeneralization. revision: yes
-
Referee: [Evaluation and data sections] Evaluation and data sections: the manuscript reports concrete Brier-score deltas and human-expert analysis but supplies insufficient detail on question-selection criteria, exact composition of the 15M-document corpus, and plans for public data release. Without these, independent verification of leakage controls and reproducibility of the reported accuracy differences cannot be performed.
Authors: We agree that the current level of detail is insufficient for full reproducibility. In the revised manuscript we will expand the Evaluation and Data sections to specify the question-selection criteria (including domain balance and strategic-reasoning focus), provide a more granular description of the 15M-document corpus (sources, temporal coverage, and freezing protocol), and state our plans for public release of the questions, corpus metadata, and evaluation code. These additions will support independent verification of leakage controls and the reported Brier-score differences. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs BTF-2 as an external benchmark with a frozen 15M-document corpus and 1,417 pastcasting questions, then elicits full reasoning traces from agents and has independent expert human forecasters label the dominant failure modes in those traces. This evaluation step does not reduce any claim to a fitted parameter on the same test set, a self-definition, or a self-citation chain; the human analysis is performed outside the model's own outputs and the question set is treated as given input rather than derived from the results. No equations or steps in the abstract or described methodology exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Brier score is a proper scoring rule suitable for comparing probabilistic forecasts
- domain assumption Human expert review of reasoning traces can reliably identify strategic reasoning failures
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.21558 , year=
Preprint, September 2024. Philip E. Tetlock and Dan Gardner.Superforecasting: The Art and Science of Prediction. Crown, 2015. Jack Wildman, Nikos I. Bosse, Daniel Hnyk, Peter Mühlbacher, Finn Hambly, Jon Evans, Dan Schwarz, and Lawrence Phillips. Bench to the future: A pastcasting benchmark for forecasting agents.arXiv preprint arXiv:2506.21558, 2025. Zel...
-
[2]
will be total and there will be no going back
ASUU’s planned escalation sequence was explicitly: 14-day ultimatum → 2-week warning strike → indefinite strike. ASUU National President Prof. Chris Piwuna stated the next phase of action “will be total and there will be no going back.”
-
[3]
As of October 21, ASUU is holding a strategic NEC meeting to evaluate the strike, with many branches voting to continue/escalate. Officials from several universities indicated the matter is “far from being over.”
-
[4]
The NLC has issued a 4-week ultimatum threatening solidarity action if ASUU’s demands aren’t met. 13
-
[5]
The FG has implemented a “no work, no pay” policy, which could harden both sides’ positions. Evidence that could prevent escalation:
-
[6]
ASUU reports progress in negotiations with FG’s Renegotiation Team on 5 of 7 demands
-
[7]
The Senate has intervened to mediate
-
[8]
Historical precedent shows some warning strikes end with partial concessions. However, ASUU’s demands are structural and longstanding (dating to 2009), making full resolution within weeks unlikely. The resolution window extends through December 31, 2025, a very long period that provides multiple opportunities for escalation. Even if the current round of n...
work page 2009
-
[9]
Identify the then-currentproposição principalfor the package including PL 1.874/2022 by checking itsficha de tramitação
work page 2022
- [10]
-
[11]
If PL 1.874/2022 itself is voted as principal in the Plenary during the window, check itsfichafor the Plenary approval event
work page 2022
-
[12]
If theficha(s)explicitly show such a Plenary approval event within the observation window, resolve YES. Otherwise, resolve NO. Key context:PL 1.874/2022 was presented in the Câmara on 2024-03-21 and is currentlyapensadaunder PL 3.899/2012. The lead proposition’sfichashows a relator designation (Dep. Luciano Vieira, 2025-03-20), urgency regime metadata, an...
work page 2022
-
[13]
The bill has urgency status since November 2024
work page 2024
-
[14]
Finance Minister Haddad cited it as a government priority
- [15]
-
[16]
However, significant obstacles remain:
End-of-year legislative sessions typically see more bills cleared. However, significant obstacles remain:
-
[17]
The de-appending has NOT yet been effectuated—requests REQ 3873/2025 and REQ 4116/2025 are still pending. 16
work page 2025
-
[18]
The productive sector called the current substitute text a “legislative monster” with over 100 articles and unrealistic obligations
-
[19]
The bill has failed to reach a vote in every Plenary session it was scheduled for in 2025
work page 2025
-
[20]
The procedural path forward remains uncertain due to pending de-appending requests. While there is political will and approximately 2.5 months remain in the observation window, the repeated failure to vote despite being on the agenda, ongoing procedural uncertainty about de-appending, and substantial industry opposition make approval uncertain but possibl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.