A Systematic Comparison of Prompting and Multi-Agent Methods for LLM-based Stance Detection
Pith reviewed 2026-05-07 13:14 UTC · model grok-4.3
The pith
Prompt-based methods outperform multi-agent debate for LLM stance detection while using 7 to 12 times fewer API calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
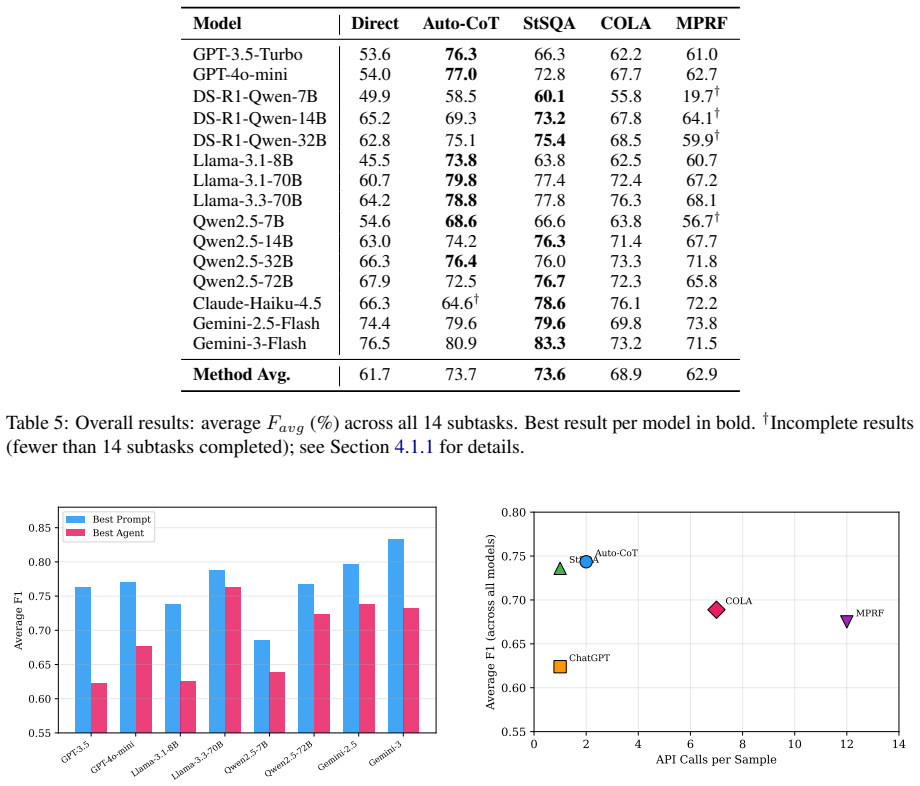
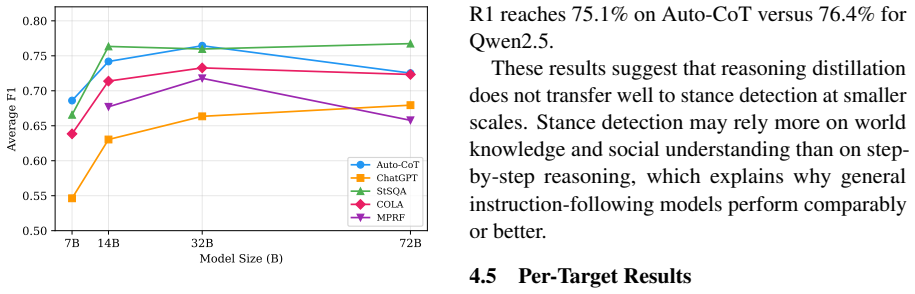
Through systematic experiments on 14 subtasks, the authors show that the best prompt-based methods (Direct Prompting, Auto-CoT, StSQA) achieve higher accuracy than the best agent-based methods (COLA, MPRF) on every model that produced complete results, while the agent methods require 7 to 12 times more API calls per sample.
What carries the argument
A standardized comparison of three prompt-based inference methods and two multi-agent debate methods applied to the same 15 LLMs on four stance-detection datasets with fixed evaluation protocols.
If this is right
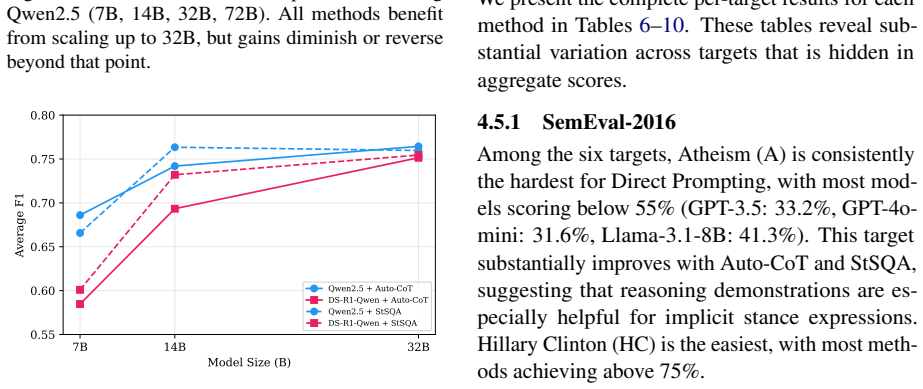
- Increasing model scale up to roughly 32B parameters produces larger accuracy gains than switching from prompt-based to agent-based methods.
- Reasoning-enhanced models such as DeepSeek-R1 do not deliver reliable improvements over standard models of comparable size on stance detection.
- For this task, the extra computation spent on multi-agent debate yields lower returns than simply using a larger base model with direct prompting.
Where Pith is reading between the lines
- Practical systems for stance detection may achieve better cost-performance by scaling model size rather than adding agent layers.
- Tasks with short, opinion-laden text may not require the multi-step reasoning that agent debate supplies, unlike longer reasoning problems.
- A follow-up study could test whether a lightweight hybrid that adds one verification step to prompting recovers some accuracy without the full agent cost.
Load-bearing premise
Differences in data splits, prompt wording, and agent implementation details do not introduce hidden biases that favor prompting over agent approaches.
What would settle it
Re-running the identical methods on the same datasets but with fully harmonized data splits, prompt templates, and agent code would show the agent methods achieving higher accuracy than the prompt methods.
Figures
read the original abstract
Stance detection identifies the attitude of a text author toward a given target. Recent studies have explored various LLM-based strategies for this task, from zero-shot prompting to multi-agent debate. However, existing works differ in data splits, base models, and evaluation protocols, making fair comparison difficult. We conduct a systematic comparison that evaluates five methods across two categories -- prompt-based inference (Direct Prompting, Auto-CoT, StSQA) and agent-based debate (COLA, MPRF) -- on four datasets with 14 subtasks, using 15 LLMs from six model families with parameter sizes from 7B to 72B+. Our experiments yield several findings. First, on all models with complete results, the best prompt-based method outperforms the best agent-based method, while agent methods require 7 to 12 times more API calls per sample. Second, model scale has a larger impact on performance than method choice, with gains plateauing around 32B. Third, reasoning-enhanced models (DeepSeek-R1) do not consistently outperform general models of the same size on this task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs a large-scale empirical comparison of five LLM-based stance detection methods—three prompt-based (Direct Prompting, Auto-CoT, StSQA) and two agent-based debate methods (COLA, MPRF)—across four datasets with 14 subtasks and 15 models ranging from 7B to 72B+ parameters. It reports that the best prompt-based method outperforms the best agent-based method on all models with complete results, that agent methods consume 7–12× more API calls, that model scale dominates method choice with performance plateauing near 32B, and that reasoning-enhanced models do not consistently beat general models of comparable size.
Significance. If the comparison protocol is shown to be equitable, the work supplies actionable guidance for practitioners choosing between simple prompting and multi-agent setups for stance detection, while quantifying the efficiency penalty of agent methods. The breadth of models and datasets strengthens the empirical contribution relative to prior fragmented studies.
major comments (2)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): The headline claim that prompt-based methods outperform agent-based methods rests on selecting the single best configuration from each category. However, the protocol does not demonstrate that the additional degrees of freedom in COLA and MPRF (debate rounds, agent roles, communication topology, stopping criteria) received search budgets comparable to the prompt-template and few-shot variations explored for Direct Prompting, Auto-CoT, and StSQA. Without an explicit ablation or grid search over these agent hyperparameters, the observed gap may reflect unequal optimization effort rather than intrinsic category differences.
- [§5.2 and Table 2] §5.2 and Table 2: No per-run variance, standard deviations, or statistical significance tests (e.g., McNemar or paired t-tests across seeds) are reported for the accuracy differences between best prompt and best agent methods. Given that LLM outputs are stochastic and that 14 subtasks are evaluated, the directional superiority claim lacks a quantitative assessment of reliability.
minor comments (3)
- [Abstract and §3] The abstract and §3 omit the exact prompt templates and agent system prompts used; these should be released in an appendix or repository to enable reproduction.
- [Figure 1 and §5.3] Figure 1 and §5.3: The plateau at 32B is visually clear but would benefit from an explicit statement of whether the same trend holds when controlling for total inference tokens rather than parameter count alone.
- [§4.3] §4.3: The description of data splits should clarify whether the same train/test partitions were used for all methods or whether any method-specific preprocessing altered the evaluation sets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our systematic comparison of prompting and multi-agent methods for LLM-based stance detection. We address each major comment below and outline the revisions we will make to improve the rigor and transparency of the empirical protocol.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): The headline claim that prompt-based methods outperform agent-based methods rests on selecting the single best configuration from each category. However, the protocol does not demonstrate that the additional degrees of freedom in COLA and MPRF (debate rounds, agent roles, communication topology, stopping criteria) received search budgets comparable to the prompt-template and few-shot variations explored for Direct Prompting, Auto-CoT, and StSQA. Without an explicit ablation or grid search over these agent hyperparameters, the observed gap may reflect unequal optimization effort rather than intrinsic category differences.
Authors: We agree that equitable hyperparameter exploration is important for a fair category-level comparison. For prompt-based methods we systematically varied templates and few-shot counts as described in §4. For COLA and MPRF we followed the exact configurations, debate rounds, agent roles, and stopping criteria published in the original papers to ensure reproducibility with prior work. While an exhaustive grid search over all agent hyperparameters was not feasible given the 7–12× higher API cost per sample, the consistent superiority of the best prompt method across 15 models, 14 subtasks, and all model scales suggests the gap is unlikely to be explained solely by optimization disparity. In the revision we will add an explicit subsection in §4 detailing the hyperparameter choices for each method, include a limited ablation on the most impactful agent parameters (e.g., debate rounds) on a representative subset of subtasks, and qualify the headline claim to reflect the use of published configurations. revision: partial
-
Referee: [§5.2 and Table 2] §5.2 and Table 2: No per-run variance, standard deviations, or statistical significance tests (e.g., McNemar or paired t-tests across seeds) are reported for the accuracy differences between best prompt and best agent methods. Given that LLM outputs are stochastic and that 14 subtasks are evaluated, the directional superiority claim lacks a quantitative assessment of reliability.
Authors: We acknowledge that reporting variance and statistical tests would strengthen confidence in the directional claims. Our primary experiments used single runs per configuration due to the prohibitive cost of repeating all 15 models × 5 methods × 14 subtasks. Nevertheless, the observed accuracy gaps between the best prompt and best agent methods are large (typically 4–12 points) and the ranking is stable across every model size and dataset. In the revised manuscript we will (1) rerun the best prompt and best agent configurations on three random seeds for a representative subset of subtasks and report means and standard deviations in an updated Table 2, and (2) apply McNemar’s test on the per-instance predictions to assess statistical significance of the differences. These additions will be included in the next version. revision: yes
Circularity Check
No circularity: purely empirical comparison of existing methods on external benchmarks
full rationale
The paper performs a head-to-head experimental evaluation of five published methods (Direct Prompting, Auto-CoT, StSQA, COLA, MPRF) across four public datasets, 14 subtasks, and 15 LLMs. All reported results are obtained by running the methods on these fixed external resources; there are no equations, fitted parameters, first-principles derivations, or predictions that reduce to the paper's own inputs. Self-citations, if present, serve only as references to prior method definitions and do not carry the central empirical claims. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stance detection can be reliably measured by accuracy or F1 on the chosen datasets and subtasks
Reference graph
Works this paper leans on
-
[1]
Zero- shot stance detection: A dataset and model using generalized topic representations. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8913–
work page 2020
-
[2]
Saif Mohammad, Svetlana Kiritchenko, Parinaz Sob- hani, Xiaodan Zhu, and Colin Cherry
Abstract, align, predict: Zero-shot stance detection via cognitive inductive reasoning.arXiv preprint arXiv:2506.13470. Saif Mohammad, Svetlana Kiritchenko, Parinaz Sob- hani, Xiaodan Zhu, and Colin Cherry
-
[3]
Semeval- 2016 task 6: Detecting stance in tweets. InProceed- ings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pages 31–41. Quang Minh Nguyen and Taegyoon Kim
work page 2016
-
[4]
Fuqiang Niu, Yi Yang, Xianghua Fu, Genan Dai, and Bowen Zhang
Is ex- ternal information useful for stance detection with LLMs? InFindings of the Association for Computa- tional Linguistics: ACL 2025, pages 14798–14807. Fuqiang Niu, Yi Yang, Xianghua Fu, Genan Dai, and Bowen Zhang
work page 2025
-
[5]
InarXiv preprint arXiv:2504.09958
C-MTCSD: A chinese multi- turn conversational stance detection dataset. InarXiv preprint arXiv:2504.09958. Lida Shi, Fausto Giunchiglia, Ran Luo, Daqian Shi, Rui Song, Xiaolei Diao, and Hao Xu
-
[6]
Bowen Zhang, Daijun Ding, Liwen Jing, Genan Dai, and Nan Yin
A survey of stance detection on social media: New directions and perspectives.arXiv preprint arXiv:2409.15690. Bowen Zhang, Daijun Ding, Liwen Jing, Genan Dai, and Nan Yin. 2022a. How would stance detec- tion techniques evolve after the launch of ChatGPT? arXiv preprint arXiv:2212.14548. Bowen Zhang, Daijun Ding, Guangning Xu, Jinjin Guo, Zhichao Huang, a...
-
[7]
Enhancing cross- target stance detection with transferable semantic- emotion knowledge. InProceedings of the 58th An- nual Meeting of the Association for Computational Linguistics, pages 3188–3197. Zhaodan Zhang, Jin Zhang, Hui Xu, Jiafeng Guo, and Xueqi Cheng. 2025b. MPRF: Interpretable stance detection through multi-path reasoning framework. InProceedin...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.