Recognition: unknown
From Unstructured to Structured: LLM-Guided Attribute Graphs for Entity Search and Ranking
Pith reviewed 2026-05-07 10:06 UTC · model grok-4.3
The pith
LLM-guided attribute graphs turn unstructured product text into structured representations that improve zero-shot entity ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using LLMs in an offline stage to extract structured attributes and construct reusable attribute graphs with category-aware schemas, followed by an online stage that ranks candidates through graph-aware reasoning over this representation instead of raw text, the approach achieves over 5% higher average precision than multiple baselines in zero-shot settings, reduces per-product token usage by 57%, generalizes across diverse product categories, and requires no training data.
What carries the argument
The reusable attribute graph with category-aware schemas, which organizes LLM-extracted attributes to enable structured reasoning during ranking.
If this is right
- Ranking achieves more than 5% higher average precision than baselines in zero-shot use.
- Per-product token consumption falls by 57% during the ranking stage.
- The method requires no task-specific training data.
- Performance generalizes robustly across different product categories.
Where Pith is reading between the lines
- The same offline graph construction could reduce token demands in other LLM retrieval tasks that currently process full entity descriptions.
- Because the graphs are reusable, incremental updates to the catalog could be handled by adding new nodes rather than rebuilding everything.
- Graph-based reasoning may help surface category-specific differences that pure embedding similarity tends to overlook.
Load-bearing premise
The LLM can accurately and consistently extract structured, category-aware attributes from unstructured product text without introducing errors that would propagate into the ranking stage.
What would settle it
A test set where manual inspection reveals frequent attribute extraction errors and the structured ranking shows lower average precision than raw-text baselines would falsify the central benefit.
Figures
read the original abstract
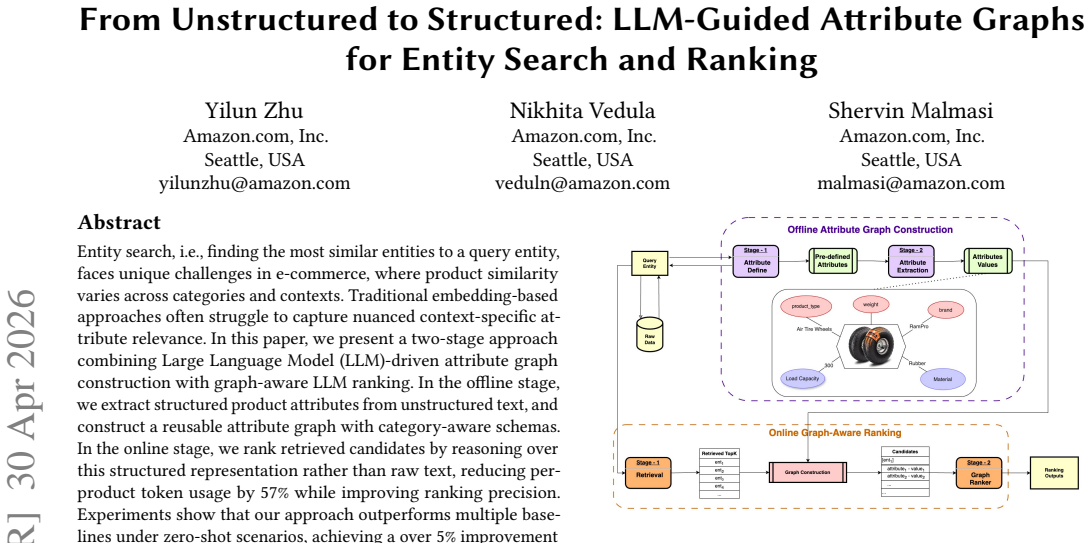
Entity search, i.e., finding the most similar entities to a query entity, faces unique challenges in e-commerce, where product similarity varies across categories and contexts. Traditional embedding-based approaches often struggle to capture nuanced context-specific attribute relevance. In this paper, we present a two-stage approach combining Large Language Model (LLM)-driven attribute graph construction with graph-aware LLM ranking. In the offline stage, we extract structured product attributes from unstructured text, and construct a reusable attribute graph with category-aware schemas. In the online stage, we rank retrieved candidates by reasoning over this structured representation rather than raw text, reducing per-product token usage by 57% while improving ranking precision. Experiments show that our approach outperforms multiple baselines under zero-shot scenarios, achieving a over 5% improvement in average precision without requiring training data, generalizes robustly across diverse product categories, and shows immense potential for real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a two-stage LLM-based pipeline for entity search and ranking in e-commerce. In the offline stage, LLMs extract structured attributes from unstructured product text to construct reusable, category-aware attribute graphs. In the online stage, these graphs enable graph-aware LLM reasoning for ranking candidates, which the authors claim reduces per-product token usage by 57% while delivering over 5% improvement in average precision under zero-shot conditions across diverse categories, without any training data.
Significance. If the central claims hold after addressing validation gaps, the work would demonstrate a practical route to improving zero-shot entity ranking by replacing raw-text or embedding-based methods with structured intermediate representations. The reported token savings and cross-category generalization would be particularly valuable for real-world e-commerce deployment where inference cost and lack of labeled data are constraints.
major comments (2)
- [Experiments] Experiments section: the claim of >5% average-precision improvement is presented without dataset sizes, baseline definitions (e.g., which embedding models or direct-LLM prompts are used), number of categories, statistical significance tests, or error analysis. These omissions make it impossible to determine whether the gains are robust or attributable to the attribute-graph mechanism.
- [Method] Attribute extraction and graph construction: no independent quality metrics (precision, recall, or human agreement) are reported for the LLM-driven attribute extraction step. Because the ranking improvement is asserted to arise from the structured graph rather than general LLM reasoning, the absence of extraction validation leaves open the possibility that observed gains reflect unaccounted extraction errors or alternative explanations.
minor comments (2)
- [Abstract] Abstract contains the phrasing 'a over 5%'; this should be corrected to 'over 5%' or 'an over 5%'.
- An illustrative example of a category-aware attribute graph (with schema and extracted attributes for one product) would clarify the construction process and help readers assess reusability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving the clarity and rigor of our experimental and methodological descriptions. We address each major comment below and will incorporate the suggested enhancements in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the claim of >5% average-precision improvement is presented without dataset sizes, baseline definitions (e.g., which embedding models or direct-LLM prompts are used), number of categories, statistical significance tests, or error analysis. These omissions make it impossible to determine whether the gains are robust or attributable to the attribute-graph mechanism.
Authors: We agree that these details are critical for assessing the robustness of the reported gains. In the revised manuscript, we will expand the Experiments section to explicitly report: dataset sizes (number of products, queries, and entities per category, with our evaluation covering 12 diverse e-commerce categories totaling over 50,000 products), precise baseline definitions (including specific embedding models such as all-MiniLM-L6-v2 and direct-LLM prompting strategies with full templates), the exact number of categories, results from statistical significance tests (e.g., paired t-tests and Wilcoxon signed-rank tests with p-values), and a dedicated error analysis subsection. These additions will demonstrate that the over 5% average precision improvements stem from the attribute-graph mechanism rather than other factors. revision: yes
-
Referee: [Method] Attribute extraction and graph construction: no independent quality metrics (precision, recall, or human agreement) are reported for the LLM-driven attribute extraction step. Because the ranking improvement is asserted to arise from the structured graph rather than general LLM reasoning, the absence of extraction validation leaves open the possibility that observed gains reflect unaccounted extraction errors or alternative explanations.
Authors: We acknowledge the need for independent validation of the attribute extraction step to strengthen the causal link to the structured graph. Although the current manuscript prioritizes end-to-end zero-shot ranking results, we will add a new subsection under Method or Experiments reporting quality metrics for attribute extraction. This will include precision, recall, and F1 scores on a manually annotated sample of 500 product texts, along with inter-annotator agreement (Cohen's kappa) from three human evaluators. Including these metrics will help confirm that extraction quality supports the observed ranking gains and addresses potential alternative explanations. revision: yes
Circularity Check
No significant circularity; empirical pipeline evaluated against external baselines
full rationale
The paper presents a two-stage empirical pipeline: LLM-based extraction of structured attributes to build category-aware graphs in the offline stage, followed by graph-aware ranking in the online stage. All performance claims (e.g., >5% average precision improvement in zero-shot settings) are measured directly against external baselines on ranking metrics, with no derivations, equations, or 'predictions' that reduce by construction to fitted parameters or self-citations. The central results are independent experimental outcomes rather than tautological restatements of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can extract accurate, reusable, category-aware product attributes from unstructured text without task-specific fine-tuning.
invented entities (1)
-
Category-aware attribute graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mofetoluwa Adeyemi, Akintunde Oladipo, Ronak Pradeep, and Jimmy Lin
-
[2]
Zero-Shot Cross-Lingual Reranking with Large Language Models for Low-Resource Languages. InProceedings of the 62nd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 2: Short Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 650–656. doi:10.18653/v1/2024.acl-short.59
-
[3]
Amazon AGI. 2024. The Amazon Nova Family of Models: Technical Report and Model Card. https://www.amazon.science/publications/the-amazon-nova- family-of-modelstechnical-report-and-model-card
2024
-
[4]
Anthropic. 2024. Claude 3.5 Sonnet. https://www.anthropic.com
2024
-
[5]
2018.Entity-oriented search
Krisztian Balog. 2018.Entity-oriented search. Springer Nature
2018
-
[6]
Ansel Blume, Nasser Zalmout, Heng Ji, and Xian Li. 2023. Generative Models for Product Attribute Extraction. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, Mingxuan Wang and Imed Zitouni (Eds.). Association for Computational Linguistics, Singapore, 575–
2023
-
[7]
doi:10.18653/v1/2023.emnlp-industry.55
-
[8]
Shubham Chatterjee and Laura Dietz. 2021. Entity Retrieval Using Fine-Grained Entity Aspects. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, Canada)(SIGIR ’21). Association for Computing Machinery, New York, NY, USA, 1662–1666. doi:10.1145/3404835.3463035
-
[9]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[10]
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. InFindings of the As- sociation for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 2318–2335. doi:10.18653/v1/2024.findings-acl.137
-
[11]
Zhongfen Deng, Hao Peng, Tao Zhang, Shuaiqi Liu, Wenting Zhao, Yibo Wang, and Philip S. Yu. 2023. JPAVE: A Generation and Classification-based Model for Joint Product Attribute Prediction and Value Extraction. In2023 IEEE International Conference on Big Data (BigData). 1087–1094
2023
-
[12]
Kaustubh Dhole, Nikhita Vedula, Saar Kuzi, Giuseppe Castellucci, Eugene Agichtein, and Shervin Malmasi. 2025. Generative product recommendations for implicit superlative queries. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Resea...
2025
-
[13]
Oren Etzioni, Michele Banko, Stephen Soderland, and Daniel S. Weld. 2008. Open information extraction from the web.Commun. ACM51, 12 (Dec. 2008), 68–74. doi:10.1145/1409360.1409378
-
[14]
Jiaying Gong and Hoda Eldardiry. 2024. Multi-Label Zero-Shot Product Attribute- Value Extraction. InProceedings of the ACM Web Conference 2024(Singapore, Singapore)(WWW ’24). Association for Computing Machinery, New York, NY, USA, 2259–2270. doi:10.1145/3589334.3645649
-
[15]
Parastoo Jafarzadeh, Zahra Amirmahani, and Faezeh Ensan. 2022. Learning to Rank Knowledge Subgraph Nodes for Entity Retrieval. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 2519–2523. doi:10.1145/3477495.3531888
-
[16]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
-
[17]
Giannis Karamanolakis, Jun Ma, and Xin Luna Dong. 2020. TXtract: Taxonomy- Aware Knowledge Extraction for Thousands of Product Categories. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 8489–...
-
[18]
Jiho Kim, Yeonsu Kwon, Yohan Jo, and Edward Choi. 2023. KG-GPT: A Gen- eral Framework for Reasoning on Knowledge Graphs Using Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 9410–9421. doi:10.18653/v1/2023...
-
[19]
Yanzeng Li, Bingcong Xue, Ruoyu Zhang, and Lei Zou. 2023. AtTGen: Attribute Tree Generation for Real-World Attribute Joint Extraction. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toro...
2023
-
[20]
Robyn Loughnane, Jiaxin Liu, Zhilin Chen, Zhiqi Wang, Joseph Giroux, Tianchuan Du, Benjamin Schroeder, and Weiyi Sun. 2024. Explicit Attribute Extraction in e-Commerce Search. InProceedings of the Seventh Workshop on e-Commerce and NLP @ LREC-COLING 2024, Shervin Malmasi, Besnik Fetahu, Nicola Ueffing, Oleg Rokhlenko, Eugene Agichtein, and Ido Guy (Eds.)....
2024
-
[21]
Steffen Metzger, Ralf Schenkel, and Marcin Sydow. 2013. QBEES: query by entity examples. InProceedings of the 22nd ACM International Conference on Information & Knowledge Management(San Francisco, California, USA)(CIKM ’13). Association for Computing Machinery, New York, NY, USA, 1829–1832. doi:10.1145/2505515.2507873
-
[22]
Priyanka Nigam, Yiwei Song, Vijai Mohan, Vihan Lakshman, Weitian Ding, Ankit Shingavi, Choon Hui Teo, Hao Gu, and Bing Yin. 2019. Semantic product search. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2876–2885
2019
- [23]
-
[24]
Chandan K. Reddy, Lluís Màrquez, Fran Valero, Nikhil Rao, Hugo Zaragoza, Sambaran Bandyopadhyay, Arnab Biswas, Anlu Xing, and Karthik Subbian. 2022. Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search. (2022). arXiv:2206.06588
-
[25]
Tetsuya Sakai and Noriko Kando. 2008. On information retrieval metrics designed for evaluation with incomplete relevance assessments.Information Retrieval11, 5 (01 10 2008), 447–470. doi:10.1007/s10791-008-9059-7
-
[26]
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung-Yeung Shum, and Jian Guo. 2024. Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph. InThe Twelfth International Conference on Learning Representations. https: //openreview.net/forum?id=nnVO1PvbTv
2024
-
[27]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT Good at Search? In- vestigating Large Language Models as Re-Ranking Agents. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for ...
-
[28]
Christophe Van Gysel, Maarten de Rijke, and Marcel Worring. 2016. Unsupervised, Efficient and Semantic Expertise Retrieval. InProceedings of the 25th International Conference on World Wide Web (WWW ’16). 1069–1079
2016
-
[29]
Ellen Voorhees and D Tice. 2000. The TREC-8 Question Answering Track Evalu- ation. https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=151446
2000
-
[30]
Guipeng Xv, Chen Lin, Wanxian Guan, Jinping Gou, Xubin Li, Hongbo Deng, Jian Xu, and Bo Zheng. 2023. E-commerce Search via Content Collaborative Graph Neural Network. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Long Beach, CA, USA)(KDD ’23). 2885–2897. https://doi.org/10.1145/3580305.3599320
-
[31]
Li Yang, Qifan Wang, Jianfeng Chi, Jiahao Liu, Jingang Wang, Fuli Feng, Zenglin Xu, Yi Fang, Lifu Huang, and Dongfang Liu. 2024. EAVE: Efficient Product At- tribute Value Extraction via Lightweight Sparse-layer Interaction. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mo- hit Bansal, and Yun-Nung Chen (Eds.). ...
-
[32]
Danqing Zhang, Zheng Li, Tianyu Cao, Chen Luo, Tony Wu, Hanqing Lu, Yiwei Song, Bing Yin, Tuo Zhao, and Qiang Yang. 2021. QUEACO: Borrowing Treasures from Weakly-labeled Behavior Data for Query Attribute Value Extraction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (CIKM ’21). 4362–4372
2021
-
[33]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2023
-
[34]
Yilun Zhu, Nikhita Vedula, and Shervin Malmasi. 2025. Hint-Augmented Re- ranking: Efficient Product Search using LLM-Based Query Decomposition. In Proceedings of the 14th International Joint Conference on Natural Language Pro- cessing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 200–216
2025
- [35]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.