Bayesian policy gradient and actor-critic algorithms
Pith reviewed 2026-05-07 09:31 UTC · model grok-4.3
The pith
Modeling policy gradients as Gaussian processes yields accurate estimates from fewer trajectory samples in reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that treating the policy gradient itself as a Gaussian process produces low-variance posterior estimates of the gradient, the natural gradient, and its covariance from far fewer full-trajectory samples than Monte Carlo policy gradients. Supplementing the framework with a Bayesian non-parametric critic—itself a Gaussian process over action values trained by temporal difference learning—recovers the Markov property when the underlying system is Markovian and supplies exact posterior expressions for the policy gradient under compatible policy parameterizations and kernels.
What carries the argument
The Gaussian process prior placed directly on the policy gradient vector (and, in the actor-critic case, on the action-value function), which performs Bayesian updating over observed return trajectories.
If this is right
- Accurate gradient estimates become available after observing substantially fewer trajectories than Monte Carlo baselines require.
- Natural-gradient directions are obtained directly from the same posterior without separate computation.
- The covariance of the gradient estimate supplies a built-in uncertainty measure for each policy update.
- The framework applies unchanged to partially observable and non-Markovian environments.
- Closed-form posterior gradients are available once an appropriate kernel and policy parameterization are chosen for the actor-critic variant.
Where Pith is reading between the lines
- The uncertainty measure could be used to modulate step sizes or to prioritize exploration along directions of high gradient variance.
- Sparse or inducing-point approximations to the Gaussian process would be a direct route to scaling the method to longer trajectories or larger policy spaces.
- The same trajectory-based Bayesian update could be applied to other policy-search objectives such as entropy-regularized returns.
Load-bearing premise
The true gradient surface over policy parameters must be adequately described by the chosen Gaussian process prior, and entire trajectories must remain the indivisible units of observation.
What would settle it
A controlled comparison on a low-dimensional Markov decision process in which the Bayesian method requires at least as many trajectories as standard REINFORCE to reach a fixed performance threshold would falsify the claimed sample-efficiency gain.
Figures








read the original abstract
Policy gradient methods are reinforcement learning algorithms that adapt a parameterized policy by following a performance gradient estimate. Conventional policy gradient methods use Monte-Carlo techniques to estimate the gradient, which tend to have high variance, requiring many samples and resulting in slow convergence. We first propose a Bayesian framework for policy gradient, based on modeling the policy gradient as a Gaussian process. This reduces the number of samples needed to obtain accurate gradient estimates. Moreover, estimates of the natural gradient and a measure of the uncertainty in the gradient estimates, namely, the gradient covariance, are provided at little extra cost. Since the proposed framework considers system trajectories as its basic observable unit, it does not require the dynamics within trajectories to be of any particular form, and can be extended to partially observable problems. On the downside, it cannot exploit the Markov property when the system is Markovian. To address this, we supplement our Bayesian policy gradient framework with a new actor-critic learning model in which a Bayesian class of non-parametric critics, based on Gaussian process temporal difference learning, is used. Such critics model the action-value function as a Gaussian process, allowing Bayes rule to be used to compute the posterior distribution over action-value functions, conditioned on the observed data. Appropriate choices of the policy parameterization and of the prior covariance (kernel) between action-values yield closed-form expressions for the posterior of the gradient of the expected return with respect to the policy parameters. We perform detailed experimental comparisons of the proposed Bayesian policy gradient and actor-critic algorithms with classic Monte-Carlo based policy gradient methods, on a number of reinforcement learning problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Bayesian policy gradient framework that models the policy gradient as a Gaussian process over trajectories to obtain lower-variance estimates, natural gradients, and gradient covariance at low additional cost. It then introduces a Bayesian actor-critic extension that employs Gaussian-process temporal-difference learning for the critic; under suitable policy parameterizations and kernels this yields closed-form posterior expressions for the gradient of expected return. The approach is evaluated experimentally against standard Monte-Carlo policy-gradient baselines on several reinforcement-learning problems.
Significance. If the GP prior on gradients is well-matched to the true surface and the closed-form results hold under the stated kernel choices, the framework could materially improve sample efficiency while supplying built-in uncertainty quantification and natural-gradient estimates. The trajectory-centric formulation is a genuine strength for non-Markovian or partially observable domains; the actor-critic extension addresses the Markov limitation noted in the abstract. Reproducible experimental comparisons and the explicit provision of covariance estimates are positive features.
major comments (3)
- [§3.1–3.2] §3.1–3.2: The central claim that modeling the gradient as a GP reduces the number of samples required rests on the prior being a reasonable model of the true gradient surface, yet no quantitative analysis (e.g., posterior contraction rate or sample-complexity bound) is supplied that relates kernel hyperparameters to the achieved variance reduction; without this the headline efficiency gain remains unquantified.
- [§4.3] §4.3: The closed-form posterior gradient expressions are stated to follow from “appropriate choices” of policy parameterization and kernel between action-values, but the manuscript does not exhibit the explicit kernel matrix or the algebraic steps that produce the closed form; this derivation is load-bearing for the actor-critic contribution and must be shown in full.
- [Table 2 / §5.2] Table 2 / §5.2: The reported variance-reduction figures are obtained only against plain Monte-Carlo baselines; no comparison is made to existing low-variance estimators (e.g., baselines, control variates, or other GP-based methods), so the incremental benefit of the Bayesian construction cannot be isolated.
minor comments (3)
- [§3] Notation for the trajectory kernel and the policy-parameter gradient is introduced without a consolidated table; readers must hunt across §3 and §4 for definitions.
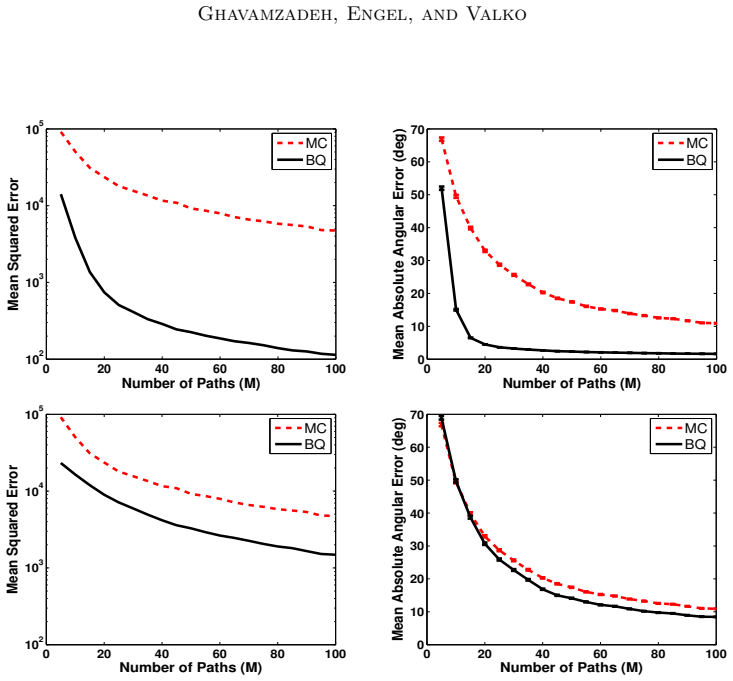
- [Figure 3] Figure 3 caption does not state the number of independent runs or the precise kernel hyperparameters used, making reproduction difficult.
- [§5] The abstract states that experiments were performed, yet the experimental section omits any discussion of computational overhead of the GP inversion step relative to the sample savings.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the framework's potential. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§3.1–3.2] The central claim that modeling the gradient as a GP reduces the number of samples required rests on the prior being a reasonable model of the true gradient surface, yet no quantitative analysis (e.g., posterior contraction rate or sample-complexity bound) is supplied that relates kernel hyperparameters to the achieved variance reduction; without this the headline efficiency gain remains unquantified.
Authors: We acknowledge that a general sample-complexity bound or posterior contraction analysis would provide stronger theoretical grounding for the efficiency claims. Such bounds depend heavily on the specific kernel, MDP, and policy parameterization, and deriving them is non-trivial. The manuscript instead demonstrates variance reduction empirically across multiple RL problems. In the revision we will add a discussion paragraph in §3.1–3.2 explaining how the GP prior induces variance reduction under reasonable kernel choices and the practical conditions under which gains are observed, while noting the absence of a general theoretical bound. revision: partial
-
Referee: [§4.3] The closed-form posterior gradient expressions are stated to follow from “appropriate choices” of policy parameterization and kernel between action-values, but the manuscript does not exhibit the explicit kernel matrix or the algebraic steps that produce the closed form; this derivation is load-bearing for the actor-critic contribution and must be shown in full.
Authors: We agree that the explicit derivation is essential. In the revised manuscript we will add the complete algebraic steps, including the explicit kernel matrix under the chosen policy parameterization and the application of Bayes' rule, either as an expanded subsection in §4.3 or as a dedicated appendix. revision: yes
-
Referee: [Table 2 / §5.2] The reported variance-reduction figures are obtained only against plain Monte-Carlo baselines; no comparison is made to existing low-variance estimators (e.g., baselines, control variates, or other GP-based methods), so the incremental benefit of the Bayesian construction cannot be isolated.
Authors: The experiments compare against standard Monte-Carlo policy-gradient baselines to isolate the effect of the Bayesian GP modeling. While broader comparisons to control variates or other GP methods would further isolate incremental gains, a comprehensive set of additional baselines would require substantial new experiments. In the revision we will expand the discussion in §5.2 to relate our results to common low-variance techniques and highlight the unique benefits of uncertainty quantification and natural-gradient estimates provided at low cost. revision: partial
Circularity Check
No circularity: GP prior and kernel choices are modeling assumptions, not self-referential reductions
full rationale
The derivation introduces a Gaussian process prior over policy gradients as an explicit modeling choice to enable Bayesian updates that lower variance in gradient estimates. Closed-form posterior expressions for the actor-critic variant are obtained only after selecting specific policy parameterizations and kernels, which the paper states as enabling assumptions rather than deriving them from the target result. No equation reduces a claimed prediction (e.g., sample efficiency or natural gradient) to a fitted constant or prior output by construction, and no load-bearing step relies on a self-citation that itself collapses to the current claim. The framework remains self-contained against external benchmarks such as Monte-Carlo policy gradients, with the reasonableness of the GP prior treated as an assumption rather than proven internally.
Axiom & Free-Parameter Ledger
free parameters (1)
- kernel hyperparameters
axioms (1)
- domain assumption Trajectories are the fundamental observable unit and the gradient surface admits a Gaussian-process representation.
Reference graph
Works this paper leans on
-
[1]
J. Choi and K. Kim. Map inference for Bayesian inverse reinforcement learning. InPro- ceedings of the Advances in Neural Information Processing Systems, pages 1989–1997,
work page 1989
- [2]
-
[3]
D. Russo and B. Van Roy. An information-theoretic analysis of Thompson sampling.CoRR, abs/1403.5341,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.