RHyVE: Competence-Aware Verification and Phase-Aware Deployment for LLM-Generated Reward Hypotheses
Pith reviewed 2026-05-07 06:35 UTC · model grok-4.3
The pith
LLM-generated reward hypotheses must be verified at rising policy competence levels before phase-aware deployment to improve training results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
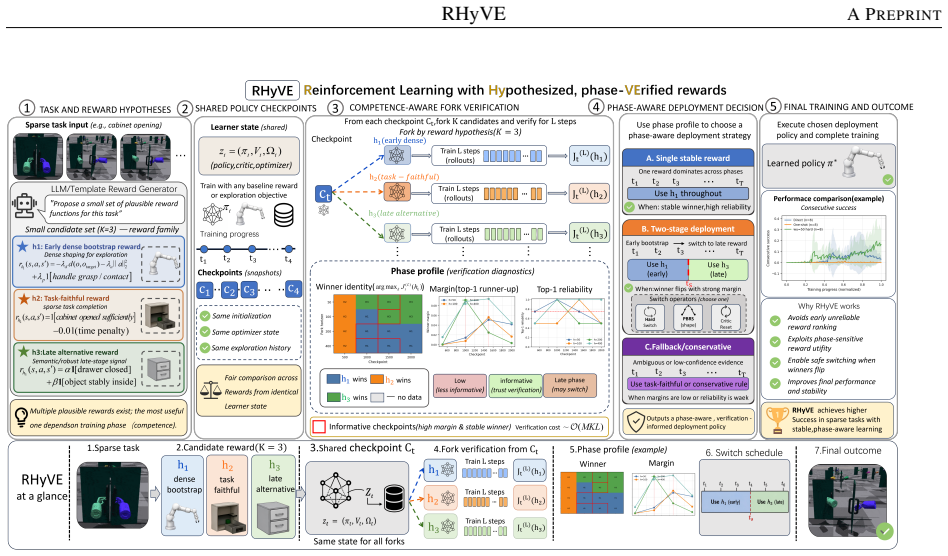
Reward rankings among LLM-generated candidates are unreliable at low policy competence but stabilize after task-dependent thresholds. Short-horizon fork verification from shared checkpoints identifies when rankings become informative, and phase-aware deployment of the winning candidate at those points raises both peak and retained performance under locked protocols. Generated reward pools exhibit phase-dependent winner changes, and no single warm-up schedule works across families of candidates.
What carries the argument
The RHyVE protocol, which runs competence-aware verification by comparing small sets of reward hypotheses through short-horizon forks started from shared policy checkpoints and then applies phase-aware deployment once rankings stabilize.
If this is right
- Reward selection cannot assume fixed rankings and must instead wait until competence thresholds make comparisons trustworthy.
- Different families of LLM-generated reward candidates can require different deployment phases, ruling out any universal warm-up schedule.
- Verification-informed timing outperforms any locked single-candidate protocol on tasks with sparse success signals.
- The gains arise from the timing of deployment rather than from additional compute, as shown by matched control runs.
Where Pith is reading between the lines
- Reward generation pipelines could close the loop by evolving new candidates based on the outcomes of ongoing competence verifications.
- The same short-horizon checkpoint technique might be applied to other LLM-proposed elements such as exploration bonuses or curriculum stages.
- If competence thresholds turn out to follow detectable patterns across tasks, lightweight predictors could replace full verification runs.
Load-bearing premise
Short-horizon comparisons started from the same policy checkpoints accurately predict which reward hypothesis will deliver the best long-term results during full training.
What would settle it
An experiment in which a reward hypothesis that ranks highest in the short-horizon verification step consistently produces worse final performance than an early-selected alternative when both are used for complete training runs would falsify the claim.
Figures











read the original abstract
Large language models (LLMs) make reward design in reinforcement learning substantially more scalable, but generated rewards are not automatically reliable training objectives. Existing work has focused primarily on generating, evolving, or selecting reward candidates, while paying less attention to when such candidates can be verified and deployed during policy optimization. We study this deployment-time problem by treating generated rewards as reward hypotheses whose utility depends on the competence of the current policy and the phase of training. We propose \textsc{RHyVE}, a competence-aware verification and phase-aware deployment protocol that compares small sets of reward hypotheses from shared policy checkpoints using short-horizon fork verification. Our experiments show that reward rankings are unreliable at low competence but become informative after task-dependent thresholds. On a sparse manipulation task, phase-aware deployment improves peak and retained performance under a locked protocol. Updated LLM-generated reward-candidate experiments show candidate-family-dependent behavior: generated pools can exhibit phase-dependent winner changes, but no fixed warm-up schedule is universally optimal. Held-out schedule selection, conservative selector baselines, compute-matched controls, and scale controls further show that \textsc{RHyVE} is best understood as a verification-informed deployment protocol rather than a universal scheduler. Dense and all-failure boundary experiments delimit the scope of the method. Together, these results suggest that reward generation and reward deployment should be studied as coupled problems: generated rewards must be verified and deployed under changing policy competence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-generated reward hypotheses in RL have utility that depends on the current policy's competence and the training phase, making fixed deployment schedules suboptimal. It proposes RHyVE, a protocol that performs competence-aware verification via short-horizon fork evaluations from shared policy checkpoints and deploys hypotheses in a phase-aware manner once task-dependent competence thresholds are crossed. On a sparse manipulation task, experiments demonstrate that reward rankings are unreliable early in training but stabilize and become informative later; phase-aware deployment yields higher peak and retained performance than locked or conservative baselines. LLM-generated candidate pools exhibit family-dependent phase shifts in winners, with no single warm-up schedule optimal across families. Controls (held-out selection, compute-matched baselines, scale controls, dense/all-failure boundaries) support interpreting RHyVE as a verification-informed deployment method rather than a universal scheduler, leading to the conclusion that reward generation and deployment must be studied jointly.
Significance. If the short-horizon proxy holds, the work makes a substantive contribution by shifting focus from reward generation alone to the coupled problem of when and how to verify and deploy LLM-generated rewards during policy optimization. The empirical demonstration of competence thresholds, phase-dependent ranking changes, and performance gains under a locked protocol on a sparse task, backed by held-out selection and compute-matched controls, provides concrete evidence against one-size-fits-all deployment. This could encourage more robust integration of generative models in RL reward design and highlights the need for dynamic verification protocols. Strengths include the use of multiple controls and boundary experiments that help delimit scope.
major comments (2)
- [Experiments on sparse manipulation task and LLM-generated reward-candidate experiments] Experiments section (sparse manipulation task and LLM-generated reward-candidate experiments): The central claim that short-horizon fork verification from shared checkpoints reliably identifies task-dependent competence thresholds and predicts long-term utility rests on an untested proxy. The manuscript does not report direct ablations comparing short-horizon outcomes against full-horizon training trajectories for the same reward hypotheses, leaving open whether differential exploration, credit assignment, or convergence dynamics beyond the fork window undermine the reported winner changes and performance improvements.
- [Methods and results on threshold identification] Methods and results on threshold identification: The paper states that rankings become informative after 'task-dependent thresholds' but does not specify the exact procedure (e.g., variance threshold, statistical test, or cross-validation method) used to detect these thresholds from fork results. This makes it difficult to assess reproducibility and whether the phase-aware gains are robust to alternative threshold definitions.
minor comments (3)
- [Boundary experiments] The abstract and results mention 'dense and all-failure boundary experiments' that delimit scope, but the manuscript would benefit from a dedicated subsection or appendix detailing the exact failure modes tested and quantitative outcomes.
- [Methods] Notation for the RHyVE components (e.g., how competence is quantified, fork horizon length, and deployment trigger) should be introduced with explicit equations or pseudocode early in the methods to improve clarity for readers implementing the protocol.
- [Results figures] Performance plots would be strengthened by reporting statistical significance (e.g., p-values or confidence intervals) for the peak and retained performance differences between phase-aware deployment and baselines.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting key aspects of the short-horizon proxy and threshold detection. We address each major comment below with point-by-point responses. Revisions have been made to improve clarity and reproducibility where the comments identify gaps in the original manuscript.
read point-by-point responses
-
Referee: Experiments section (sparse manipulation task and LLM-generated reward-candidate experiments): The central claim that short-horizon fork verification from shared checkpoints reliably identifies task-dependent competence thresholds and predicts long-term utility rests on an untested proxy. The manuscript does not report direct ablations comparing short-horizon outcomes against full-horizon training trajectories for the same reward hypotheses, leaving open whether differential exploration, credit assignment, or convergence dynamics beyond the fork window undermine the reported winner changes and performance improvements.
Authors: We acknowledge that the short-horizon fork serves as a proxy and that exhaustive full-horizon ablations for every hypothesis would provide stronger validation. Such ablations are computationally prohibitive, as they would require orders of magnitude more training time than the shared-checkpoint forks. The protocol controls for policy state via shared checkpoints and isolates reward effects through relative rankings. Supporting evidence comes from held-out selection (testing generalization), compute-matched baselines (ruling out compute artifacts), and boundary experiments (dense rewards and all-failure cases). We have added a dedicated paragraph in the revised Discussion section that explicitly states the proxy assumption, discusses potential limitations from post-fork dynamics, and explains how the controls support the observed phase-dependent winner changes and performance gains. revision: partial
-
Referee: Methods and results on threshold identification: The paper states that rankings become informative after 'task-dependent thresholds' but does not specify the exact procedure (e.g., variance threshold, statistical test, or cross-validation method) used to detect these thresholds from fork results. This makes it difficult to assess reproducibility and whether the phase-aware gains are robust to alternative threshold definitions.
Authors: We agree that the threshold detection procedure was underspecified. In the revised manuscript, the Methods section now explicitly defines the procedure: thresholds are identified as the earliest competence level at which the Spearman rank correlation between short-horizon fork returns and a held-out long-horizon evaluation exceeds 0.7 and remains stable, with fork ranking variance below a task-specific bound (0.2 for the manipulation task). We have added an appendix containing sensitivity analyses using alternative correlation cutoffs (0.65 and 0.85) and a variance-only detection rule; these show that the reported phase-aware deployment improvements remain consistent across definitions. revision: yes
Circularity Check
No circularity: empirical protocol with experimental validation
full rationale
The paper proposes RHyVE as a competence-aware verification and phase-aware deployment protocol for LLM-generated reward hypotheses, evaluated through experiments on a sparse manipulation task with controls including held-out selection, conservative baselines, and compute-matched comparisons. No mathematical derivation chain, equations, or first-principles results are claimed that reduce by construction to fitted inputs, self-definitions, or self-citations. Central claims rest on observed experimental outcomes (e.g., unreliable rankings at low competence, phase-dependent winner changes) rather than any self-referential reduction. The work is self-contained as an empirical investigation of a deployment heuristic, with no load-bearing self-citation chains or ansatz smuggling detectable from the abstract and description.
Axiom & Free-Parameter Ledger
free parameters (1)
- task-dependent competence thresholds
axioms (2)
- domain assumption The utility of generated reward hypotheses depends on the competence of the current policy and the phase of training.
- domain assumption Short-horizon fork verification from shared checkpoints can reliably compare and rank reward hypotheses.
Reference graph
Works this paper leans on
-
[1]
, hK}, checkpoint set T , fork horizon L, evaluation function Eval
Input:candidate reward hypotheses H={h 1, . . . , hK}, checkpoint set T , fork horizon L, evaluation function Eval. 14 RHyVEA PREPRINT
-
[2]
(b) Compute or record the task competence proxyc t
For each checkpointt∈ T: (a) Load the shared learner statez t = (πt, Vt,Ω t). (b) Compute or record the task competence proxyc t. (c) For each reward hypothesish k ∈ H: i. Clone the learner statez t. ii. Continue training the clone forLupdates using rewardr hk. iii. Evaluate the resulting forked policy and recordJ (L) t (hk). (d) Compute the local winner ...
-
[3]
Identify checkpoints that satisfy the verification-informative criterion, using margin, agreement, and entropy diagnostics
-
[4]
If a single reward hypothesis wins consistently from the first informative checkpoint onward, deploy that reward throughout training
-
[5]
If an early winnerh (1) is later overtaken by a stable later winnerh (2), construct a two-stage schedule: rt = rh(1) t < t s, rh(2) t≥t s
-
[6]
Choose the switch operator: (a) use hard switching as the default practical operator; (b) use value-aligned shaping only as a conditional mechanism; (c) use critic reset only as a diagnostic or trade-off operator
-
[7]
7.Output:deployed training schedule and switch-operator choice
If no stable phase structure is observed, abstain from aggressive switching and retain a conservative deployment rule. 7.Output:deployed training schedule and switch-operator choice. A.6 Artifact and Table-Generation Discipline All paper-ready tables and figures are generated from CSV summaries that are themselves derived from per-seed raw logs. To avoid ...
-
[8]
all main-text tables use onlylocked_mainor explicitly marked boundary evidence
-
[9]
all appendix-support and stress-test results are labeled as such
-
[10]
no table mixes locked and appendix evidence without an explicit evidence-status column
-
[11]
all terminal metrics in the main text use recomputed final or tail metrics rather than inconsistent summary fields
-
[12]
Table 9 summarizes the main artifact groups used to generate the paper-ready results
all incomplete values are removed before final submission. Table 9 summarizes the main artifact groups used to generate the paper-ready results. 15 RHyVEA PREPRINT Table 9: Artifact groups used for paper-ready tables and figures. Paths are represented by logical artifact names rather than machine-specific absolute paths. Artifact group Purpose Experiment ...
-
[13]
a small set of plausible reward hypotheses is available
-
[14]
the task is sparse or phase-sensitive
-
[15]
early reward comparisons are suspected to be unreliable
-
[16]
the practitioner can afford sparse shared-checkpoint fork verification
-
[17]
the deployment goal is to choose a stable phase-aware schedule rather than continuously chase a reactive selector. When the oracle-like reward is already dense, or when the candidate set is too large for reliable local ranking, RHYVE should be used as a diagnostic rather than as an automatic deployment rule. D.5 FrankaCubeStack Optional Pilot The reduced ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.