Bayesian Optimization in Linear Time
Pith reviewed 2026-05-09 20:16 UTC · model grok-4.3
The pith
Recursive binary partitioning adapts Bayesian optimization to linear time and better performance on high-dimensional tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using flexible and recursive binary partitioning of the search space, both the modeling and acquisitive aspects of standard Bayesian optimization are adapted to work harmoniously with the partitioning scheme. This change removes the cubic computational bottleneck and aligns the search process more closely with the local character of minimization.
What carries the argument
Flexible recursive binary partitioning of the search space, which localizes both the Gaussian process surrogate and the acquisition function within each subregion.
If this is right
- The approach scales to optimization budgets far larger than those feasible with cubic methods.
- Better final objective values are obtained on high-dimensional black-box problems.
- Computational cost grows linearly rather than cubically with the number of observations collected.
- The local nature of minimization is respected while still using uncertainty to guide sampling.
Where Pith is reading between the lines
- Partitioning ideas of this kind could be applied to other surrogate-based sequential methods that currently face cubic scaling limits.
- Real engineering or hyperparameter tasks with costly evaluations might now support longer search runs without computational collapse.
- Adaptive rules for choosing split locations could further improve performance on functions with sharp local features.
Load-bearing premise
That recursive binary partitioning integrates with Gaussian process modeling and acquisition functions without introducing biases that degrade the quality of the uncertainty-aware search.
What would settle it
Runtime measurements showing super-linear growth as the number of evaluations increases, or the method returning higher final values than standard Bayesian optimization on new test functions with known optima.
Figures










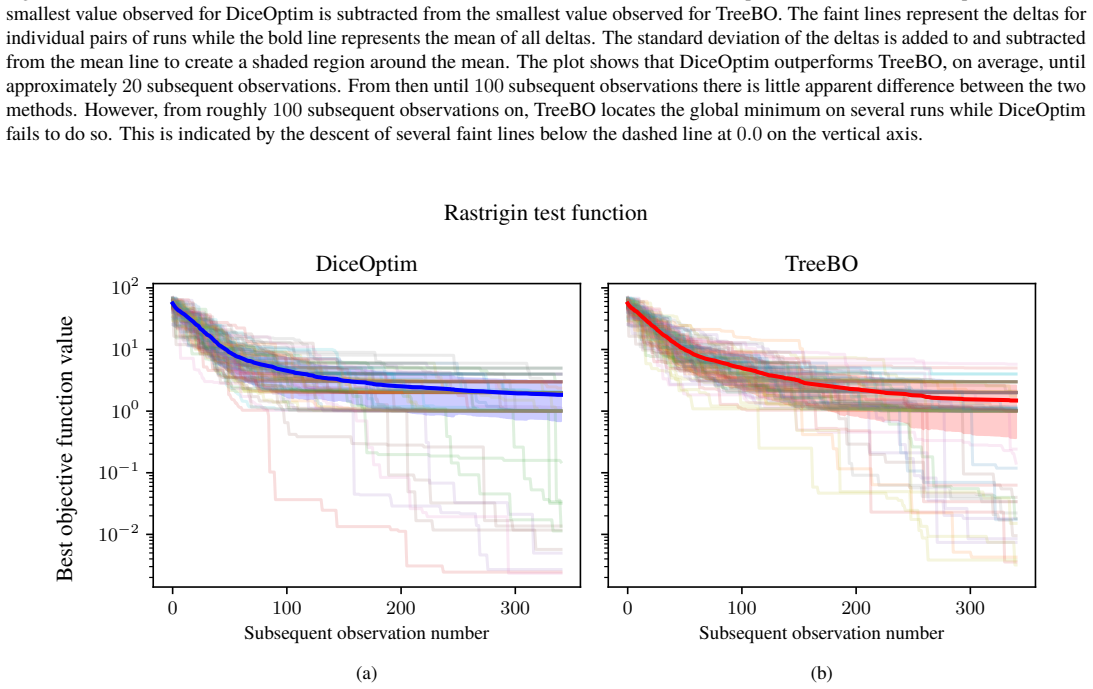






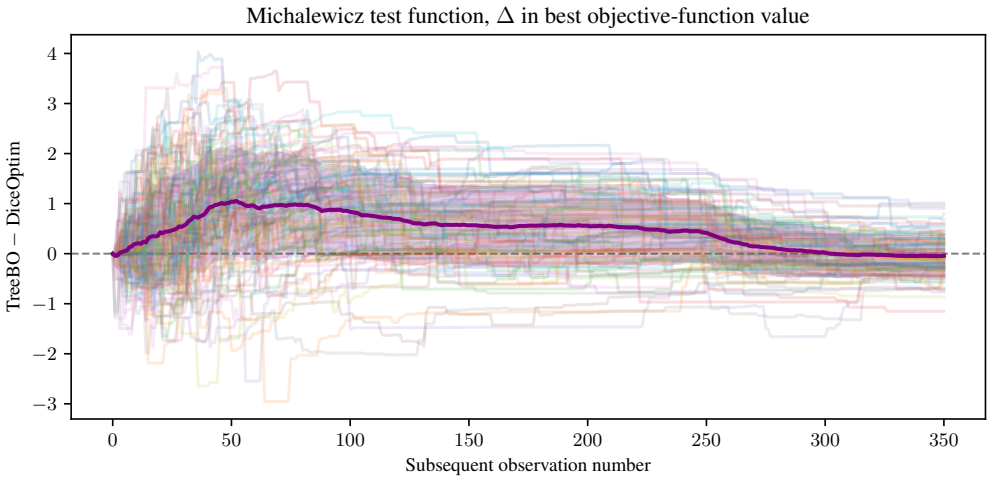

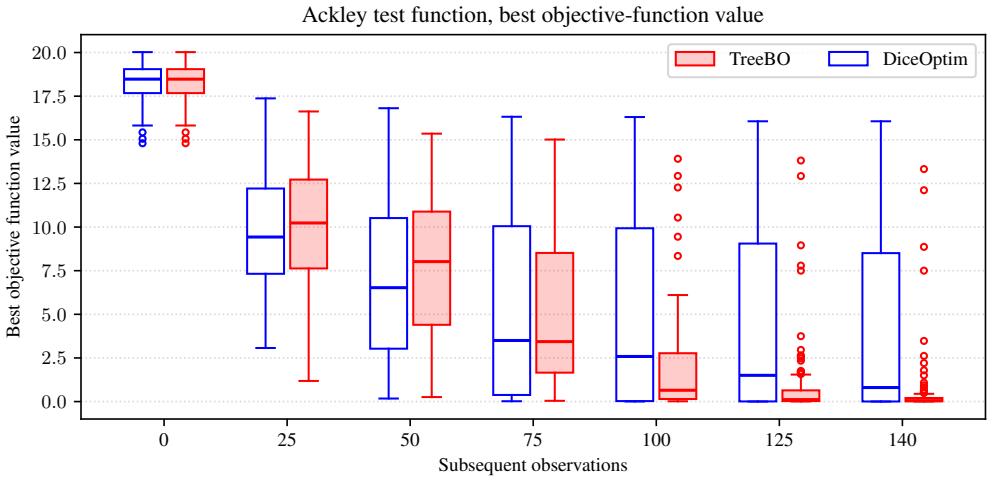





read the original abstract
Bayesian optimization is a sequential method for minimizing objective functions that are expensive to evaluate and about which few assumptions can be made. By using all gathered data to train a Gaussian process model for the function and adaptively employing a mixture of global exploration and local exploitation, this method has been used for optimization in many fields including machine learning, automotive engineering and reinforcement learning. However, the standard method suffers from two problems: 1) with cubic computational complexity in the training-set size it eventually becomes computationally infeasible to train the model, and 2) globally modeling the objective function is not necessarily optimal given the local nature of minimization. Using flexible and recursive binary partitioning of the search space, we adapt both the modeling and acquisitive aspects of standard Bayesian optimization to work harmoniously with the partitioning scheme, thereby ameliorating both standard shortcomings. We compare our method against a commonly used Bayesian optimization library on seven challenging test functions, ranging in dimensionality from $6$ to $124$, and show that our method achieves superior optimization performance in all tests. In addition our method has linear computational complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Bayesian optimization algorithm that uses flexible recursive binary partitioning of the search space to adapt both Gaussian process modeling and acquisition functions. This is claimed to resolve the cubic complexity of standard BO and the mismatch between global modeling and local minimization, yielding linear computational complexity and superior empirical performance against a standard library on seven test functions with input dimensions ranging from 6 to 124.
Significance. If the integration of partitioning with GPs and acquisition functions is shown to preserve uncertainty quantification without introducing bias, the work would be significant for scaling Bayesian optimization to larger problems and higher dimensions where standard methods become infeasible. The reported empirical results across a range of dimensions provide a starting point for assessing practical utility, though the absence of explicit complexity derivations or theoretical guarantees in the provided text limits assessment of the core contribution.
major comments (2)
- [Abstract / Methods] The abstract asserts linear computational complexity and harmonious adaptation of modeling and acquisition to the partitioning scheme, but no derivation, complexity analysis, or pseudocode detailing the integration with Gaussian processes is supplied. A dedicated methods section with explicit complexity bounds (e.g., showing O(n) scaling in training-set size) is required to substantiate the central claim.
- [Experiments] The empirical comparison reports superior performance on all seven test functions, but without details on the specific acquisition function adaptation, partitioning recursion depth, or how local vs. global search is balanced within partitions, it is impossible to verify that the method avoids new biases while retaining the benefits of uncertainty-aware optimization. Include the exact experimental protocol, hyperparameter settings, and any ablation studies in §4 or §5.
minor comments (2)
- [Abstract] The abstract mentions 'a commonly used Bayesian optimization library' without naming it or providing version/citation; add the specific reference (e.g., GPyOpt or BoTorch) for reproducibility.
- [Experiments] Test function dimensions are given as a range (6 to 124) but individual dimensions and function names are not listed; include a table in the experiments section enumerating each function, its dimension, and the number of evaluations used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / Methods] The abstract asserts linear computational complexity and harmonious adaptation of modeling and acquisition to the partitioning scheme, but no derivation, complexity analysis, or pseudocode detailing the integration with Gaussian processes is supplied. A dedicated methods section with explicit complexity bounds (e.g., showing O(n) scaling in training-set size) is required to substantiate the central claim.
Authors: We agree that the current version does not provide a self-contained derivation or pseudocode. In the revised manuscript we will insert a new dedicated Methods section that formally describes the recursive binary partitioning procedure, its integration with the Gaussian process posterior and the adapted acquisition function, the full algorithm in pseudocode, and a complexity analysis establishing O(n) scaling in the number of observations (training-set size). This will directly substantiate the linear-complexity claim. revision: yes
-
Referee: [Experiments] The empirical comparison reports superior performance on all seven test functions, but without details on the specific acquisition function adaptation, partitioning recursion depth, or how local vs. global search is balanced within partitions, it is impossible to verify that the method avoids new biases while retaining the benefits of uncertainty-aware optimization. Include the exact experimental protocol, hyperparameter settings, and any ablation studies in §4 or §5.
Authors: We acknowledge that the experimental section currently lacks sufficient implementation detail for full reproducibility and bias assessment. We will expand Sections 4 and 5 to report the precise experimental protocol, all hyperparameter values, the exact form of acquisition-function adaptation inside each partition, the recursion-depth schedule, the mechanism used to balance local versus global search, and ablation studies that isolate the contribution of the partitioning scheme. These additions will allow readers to verify that uncertainty quantification is preserved. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an algorithmic adaptation of Bayesian optimization via recursive binary partitioning of the search space to achieve linear complexity and address global-vs-local modeling issues. No equations, fitted parameters, or derivation steps are presented in the abstract or claims that reduce any result to a self-referential definition, a renamed fit, or a load-bearing self-citation chain. Empirical superiority is asserted via direct comparison on seven test functions (dimensions 6-124), which constitutes independent validation rather than a constructed prediction. The central claims remain self-contained algorithmic descriptions without the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jiang, Samuel Daulton, Benjamin Letham, Andrew Gordon Wilson, and Ey- tan Bakshy
Maximilian Balandat, Brian Karrer, Daniel R. Jiang, Samuel Daulton, Benjamin Letham, Andrew Gordon Wilson, and Ey- tan Bakshy. BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization. InAdvances in Neural Information Processing Systems 33, 2020. 7
work page 2020
-
[2]
Claus Bendtsen.pso: Particle Swarm Optimization, 2022. R package version 1.0.4. 7, 11
work page 2022
-
[3]
Rob Carnell.lhs: Latin Hypercube Samples, 2024. 6, 8
work page 2024
-
[4]
Standard particle swarm optimisation.HAL preprint hal-00764996, 2012
Maurice Clerc. Standard particle swarm optimisation.HAL preprint hal-00764996, 2012. 11
work page 2012
-
[5]
Scalable global optimization via local Bayesian optimization
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local Bayesian optimization. InAdvances in Neural Infor- mation Processing Systems, 2019. 9, 10
work page 2019
-
[6]
CambridgeUniversity Press, 2023
RomanGarnett.BayesianOptimization. CambridgeUniversity Press, 2023. 1, 2, 3
work page 2023
-
[7]
Daniel Golovin, Benjamin Solnik, Subhodeep Moitra, Greg Kochanski, John Karro, and D. Sculley. Google Vizier: A service for black-box optimization. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017. 1
work page 2017
-
[8]
Scalable Bayesian opti- mization using Vecchia approximations of Gaussian processes
Felix Jimenez and Matthias Katzfuss. Scalable Bayesian opti- mization using Vecchia approximations of Gaussian processes. InProceedings of The 26th International Conference on Artifi- cial Intelligence and Statistics, 2023. 9
work page 2023
- [9]
-
[10]
Benchmark problems for constrained global optimizationwithhigh-dimensionalblack-boxfunctions, 2025
Donald R Jones. Benchmark problems for constrained global optimizationwithhigh-dimensionalblack-boxfunctions, 2025. 7, 14
work page 2025
-
[11]
Efficient global optimization of expensive black-box functions
Donald R Jones, Matthias Schonlau, and William J Welch. Efficient global optimization of expensive black-box functions. Journal of Global optimization, 1998. 3
work page 1998
-
[12]
Welch.EGO: Efficient Global Optimization, 2023
Xiaomeng Ju and William J. Welch.EGO: Efficient Global Optimization, 2023. 8
work page 2023
-
[13]
Rousseeuw.Finding Groups in Data: An Introduction to Cluster Analysis
Leonard Kaufman and Peter J. Rousseeuw.Finding Groups in Data: An Introduction to Cluster Analysis. John Wiley & Sons, Inc., 1990. 5, 9, 13 11
work page 1990
-
[14]
Wenxuan Li, Taiyi Wang, and Eiko Yoneki. Navigating in high-dimensional search space: A hierarchical Bayesian opti- mization approach.arXiv preprint arXiv:2410.23148, 2024. 9, 10
-
[15]
Haitao Liu, Yew-Soon Ong, Xiaobo Shen, and Jianfei Cai. When Gaussian process meets big data: A review of scalable gps.IEEE transactions on neural networks and learning sys- tems, 2020. 9
work page 2020
-
[16]
Choos- ing the sample size of a computer experiment: A practical guide.Technometrics, 2009
Jason L Loeppky, Jerome Sacks, and William J Welch. Choos- ing the sample size of a computer experiment: A practical guide.Technometrics, 2009. 8
work page 2009
-
[17]
WalterR.Mebane,Jr.andJasjeetS.Sekhon. Geneticoptimiza- tion using derivatives: The rgenoud package for R.Journal of Statistical Software, 2011. 7, 10
work page 2011
-
[18]
Foundations of Machine Learning
Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of Machine Learning. MIT Press, 2 edition, 2018. 7
work page 2018
-
[19]
Number153inAppliedMathematical Sciences
Stanley Osher and Ronald Fedkiw.Level Set Methods and Dy- namicImplicitSurfaces. Number153inAppliedMathematical Sciences. Springer, 2003. 10
work page 2003
-
[20]
DiceOptim: Kriging-Based Optimization for Computer Ex- periments, 2025
Victor Picheny, David Ginsbourger, and Olivier Roustant. DiceOptim: Kriging-Based Optimization for Computer Ex- periments, 2025. 1, 3, 7, 10
work page 2025
-
[21]
R Foundation for Statistical Computing, 2024
R Core Team.R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, 2024. 3, 7, 8
work page 2024
-
[22]
OlivierRoustant,DavidGinsbourger,andYvesDeville. DiceK- riging, DiceOptim: Two R packages for the analysis of com- puter experiments by kriging-based metamodeling and opti- mization.Journal of Statistical Software, 2012. 3, 10
work page 2012
-
[23]
Virtual library of sim- ulation experiments: Test functions and datasets, 2013
Sonja Surjanovic and Derek Bingham. Virtual library of sim- ulation experiments: Test functions and datasets, 2013. 7, 14
work page 2013
-
[24]
The MathWorks Inc.MATLAB, 2024. 8
work page 2024
- [25]
-
[26]
Ryan Turner, David Eriksson, Michael McCourt, Juha Kiili, Eero Laaksonen, Zhen Xu, and Isabelle Guyon. Bayesian op- timization is superior to random search for machine learning hyperparameter tuning: Analysis of the black-box optimiza- tion challenge 2020. InProceedings of the NeurIPS 2020 Competition and Demonstration Track, 2021. 1
work page 2020
-
[27]
LinnanWang,RodrigoFonseca,andYuandongTian. Learning search space partition for black-box optimization using Monte Carlo tree search.Advances in Neural Information Processing Systems, 2020. 9, 10
work page 2020
-
[28]
Ziyu Wang, Frank Hutter, Masrour Zoghi, David Matheson, andNandoDeFeitas. Bayesianoptimizationinabilliondimen- sionsviarandomembeddings.JournalofArtificialIntelligence Research, 2016. 9
work page 2016
-
[29]
ScalableBayesianoptimizationviafocalizedsparse Gaussian processes
Yunyue Wei, Vincent Zhuang, Saraswati Soedarmadji, and YananSui. ScalableBayesianoptimizationviafocalizedsparse Gaussian processes. InAdvances in Neural Information Pro- cessing Systems, 2024. 9
work page 2024
-
[30]
Aaron Wilson, Alan Fern, and Prasad Tadepalli. Using trajec- tory data to improve Bayesian optimization for reinforcement learning.Journal of Machine Learning Research, 2014. 1
work page 2014
-
[31]
Juliusz Krzysztof Ziomek and Haitham Bou Ammar. Are ran- domdecompositionsallweneedinhighdimensionalBayesian optimisation? InInternational Conference on Machine Learn- ing, 2023. 9 Jesse Schneiderreceived the B.Sc. in Data Science and Business Analytics from the University of London in 2021, and the M.Sc. in Statistics from Simon Fraser University in 2023...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.