Object-Level Explanations for Image Geolocation Models: a GeoGuessr use-case
Pith reviewed 2026-05-09 20:41 UTC · model grok-4.3
The pith
Attribution maps from geolocation models break down into specific object regions that carry more predictive information than random areas of similar size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
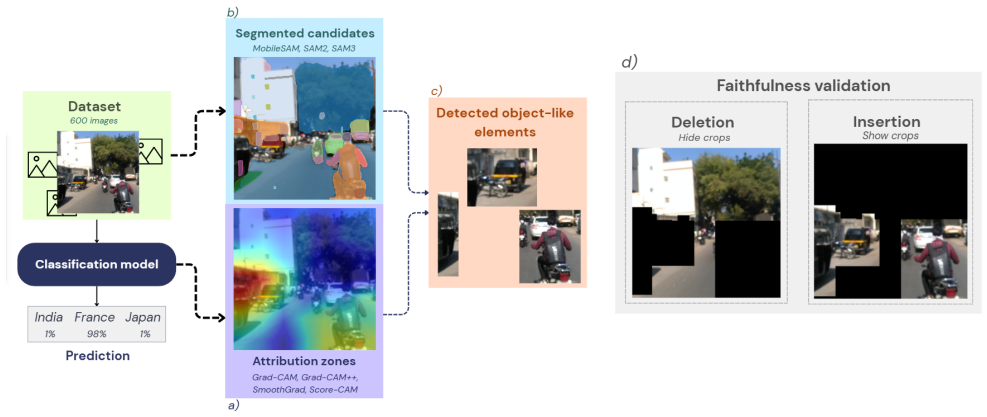
Starting from attribution maps, the authors extract salient regions and segment them into object-like elements; deletion and insertion tests on a three-country benchmark then show that these attribution-guided crops retain more information for the model's geolocation prediction than randomly selected regions with similar coverage.
What carries the argument
Object-centric analysis pipeline that extracts salient regions from attribution maps, segments them into object-like elements, and evaluates their predictive relevance through deletion and insertion tests.
If this is right
- Attribution maps can be decomposed into interpretable object-level evidence instead of remaining diffuse regions.
- Geolocation models appear to base predictions on perceptible patterns such as architectural details or vegetation.
- This pipeline supplies a concrete route from heatmap explanations to analysis of individual visual entities.
Where Pith is reading between the lines
- The same segmentation-plus-test approach could be applied to other vision tasks to check whether models use coherent objects rather than textures.
- If the object elements prove stable across models, they could serve as a basis for targeted data augmentation focused on key scene parts.
- The method invites direct comparison between the objects identified by the pipeline and the cues human geolocation experts report using.
Load-bearing premise
The segmentation step produces object-like elements that match the actual visual cues the model uses rather than artifacts created by the segmenter or the attribution method.
What would settle it
If attribution-guided crops failed to retain more predictive information than random crops of equal size across repeated tests on the three-country benchmark, the central claim would not hold.
Figures


read the original abstract
When humans play geolocation games such as GeoGuessr, they rely on concrete visual cues, such as road markings, vegetation, or architectural details, to infer where an image was captured. Whether image geolocation models rely on similar object-level evidence remains difficult to determine, as attribution methods like Grad-CAM typically highlight diffuse regions rather than coherent visual entities, making it difficult to link model predictions to specific objects or perceptible patterns. In this work, we propose an object-centric analysis pipeline to investigate the visual evidence used by geolocation models. Starting from attribution maps, we extract salient regions and segment them into object-like elements. We evaluate their predictive relevance through deletion and insertion tests, comparing attributionguided crops to randomly selected regions with similar coverage. Experiments on a three-country benchmark show that attribution-guided crops consistently retain more information for the model's prediction than random crops. These results suggest that attribution maps can be decomposed into interpretable, perceptible elements, providing a step toward object-level analysis of geolocation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an object-centric pipeline to interpret image geolocation models (e.g., for GeoGuessr). Attribution maps (such as Grad-CAM) are used to extract salient regions, which are segmented into object-like elements; these are then assessed for predictive relevance via deletion and insertion tests that compare attribution-guided crops against random crops of similar coverage. Experiments on a three-country benchmark are reported to show that the guided crops consistently retain more information for the model's prediction than random crops, suggesting that attribution maps can be decomposed into interpretable, perceptible elements.
Significance. If the experimental outcome is robust, the work offers a concrete step toward object-level rather than pixel-level explanations for geolocation models, potentially aligning model behavior with the concrete visual cues (road markings, vegetation, architecture) that humans use. This could be useful for debugging, trust, and domain-specific interpretability in computer vision tasks where location inference depends on localized, perceptible patterns.
major comments (2)
- [Experiments] The central experimental claim (attribution-guided crops retain more predictive information than random crops) rests on deletion/insertion tests whose quantitative outcomes, error bars, dataset sizes, model architectures, and statistical significance are not reported in the abstract and are not accompanied by ablations that isolate the contribution of the segmentation step from possible artifacts of the attribution concentration or the segmenter itself.
- [Method] The pipeline (attribution map → salient region extraction → segmentation) could produce non-random regions due to method-specific biases in region size, texture, or position without those regions corresponding to the actual visual cues the geolocation model relies on; no validation (e.g., human annotation of segmented objects or comparison across multiple segmenters) is described to rule out this alternative explanation for the three-country benchmark result.
minor comments (2)
- [Abstract] The abstract states that guided crops 'consistently retain more information' without defining the precise metric (e.g., change in log-probability or top-1 accuracy) or the coverage-matching procedure for random crops; this should be clarified with a precise definition and pseudocode.
- [Related Work] No references are provided for the specific attribution method, segmentation algorithm, or the deletion/insertion evaluation protocol; adding these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, providing clarifications on the reported experiments and methodological controls while outlining targeted revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Experiments] The central experimental claim (attribution-guided crops retain more predictive information than random crops) rests on deletion/insertion tests whose quantitative outcomes, error bars, dataset sizes, model architectures, and statistical significance are not reported in the abstract and are not accompanied by ablations that isolate the contribution of the segmentation step from possible artifacts of the attribution concentration or the segmenter itself.
Authors: We agree that the abstract is intentionally high-level and does not contain the detailed metrics. The full manuscript reports the deletion/insertion test outcomes on the three-country benchmark, including dataset sizes, the geolocation model architectures, comparative retention scores, and associated statistical tests. To improve accessibility, we will revise the abstract to include key quantitative summaries (e.g., mean predictive retention differences with standard errors). We also acknowledge the absence of explicit ablations isolating segmentation; in the revision we will add these, including comparisons of segmented vs. unsegmented attribution regions and alternative segmenters to quantify their individual contributions. revision: yes
-
Referee: [Method] The pipeline (attribution map → salient region extraction → segmentation) could produce non-random regions due to method-specific biases in region size, texture, or position without those regions corresponding to the actual visual cues the geolocation model relies on; no validation (e.g., human annotation of segmented objects or comparison across multiple segmenters) is described to rule out this alternative explanation for the three-country benchmark result.
Authors: The random-crop baseline with matched area coverage is intended to control for size and demonstrate that guided regions carry more predictive signal than arbitrary selections of equivalent extent. We recognize, however, that residual biases in texture or spatial distribution from the attribution or segmenter could remain. To address this directly, the revised manuscript will include cross-segmenter comparisons and a qualitative breakdown of extracted objects with examples tied to perceptible cues (e.g., road markings, architecture). We will also add a limited human validation step to assess whether the segmented regions align with human-interpretable location cues. revision: yes
Circularity Check
No circularity: empirical pipeline is self-contained
full rationale
The paper describes an object-centric pipeline starting from standard attribution maps (Grad-CAM), extracting salient regions, segmenting them, and evaluating predictive relevance via deletion/insertion tests against random crops of similar coverage. These tests are independent of the geolocation model's training objective and do not involve fitted parameters, self-definitions, or load-bearing self-citations. The reported result is a direct empirical comparison on a three-country benchmark; no derivation reduces to its own inputs by construction. The evaluation procedure stands on its own without requiring external uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Attribution maps (e.g., Grad-CAM) highlight regions that are causally relevant to the model's output.
- domain assumption Deletion and insertion tests measure the predictive relevance of image regions.
Reference graph
Works this paper leans on
-
[1]
OpenStreetView-5M: The Many Roads to Global Visual Ge- olocation
Guillaume Astruc, Nicolas Dufour, Ioannis Siglidis, Con- stantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vincent, Lintao Xu, Hongyu Zhou, and Loic Landrieu. OpenStreetView-5M: The Many Roads to Global Visual Ge- olocation. In2024 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR),...
-
[2]
SAM 3: Segment Anything with Concepts, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R¨adle, Triantafyllos Afouras, Effrosyni Mavroudi, Kather- ine Xu, Tsung-Han Wu, Yu Zhou, Lil...
work page 2025
-
[3]
Grad-CAM++: General- ized Gradient-Based Visual Explanations for Deep Convolu- tional Networks
Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad-CAM++: General- ized Gradient-Based Visual Explanations for Deep Convolu- tional Networks. In2018 IEEE Winter Conference on Appli- cations of Computer Vision (WACV), pages 839–847, 2018. 3
work page 2018
-
[4]
ImageNet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical im- age database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 3
work page 2009
-
[5]
Towards Automatic Concept-based Explanations
Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards Automatic Concept-based Explanations. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2019. 2
work page 2019
-
[6]
PIGEON: Predicting Image Geolocations
Lukas Haas, Michal Skreta, Silas Alberti, and Chelsea Finn. PIGEON: Predicting Image Geolocations. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12893–12902, 2024. 2
work page 2024
-
[7]
James Hays and Alexei A. Efros. IM2GPS: Estimating geo- graphic information from a single image. In2008 IEEE Con- ference on Computer Vision and Pattern Recognition, pages 1–8, 2008. 1
work page 2008
-
[8]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 3
work page 2016
-
[9]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept Bottleneck Models. InProceedings of the 37th In- ternational Conference on Machine Learning, pages 5338–
-
[10]
Yehui Liu, Yuliang Zhao, Xinyue Zhang, Xiaoai Wang, Chao Lian, Jian Li, Peng Shan, Changzeng Fu, Xiaoyong Lyu, Lianjiang Li, Qiang Fu, and Wen Jung Li. MobileSAM- Track: Lightweight One-Shot Tracking and Segmentation of Small Objects on Edge Devices.Remote Sensing, 15(24),
-
[11]
RISE: Random- ized Input Sampling for Explanation of Black-box Models,
Vitali Petsiuk, Abir Das, and Kate Saenko. RISE: Random- ized Input Sampling for Explanation of Black-box Models,
-
[12]
SAM 2: Segment Anything in Images and Videos,
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. SAM 2: Segment Anything in Images and Videos,
-
[13]
Marco Ribeiro, Sameer Singh, and Carlos Guestrin. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. InProceedings of the 2016 Conference of the North American Chapter of the Association for Compu- tational Linguistics: Demonstrations, pages 97–101, San Diego, California, 2016. Association for Computational Lin- guistics. 2
work page 2016
-
[14]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In2017 IEEE Interna- tional Conference on Computer Vision (ICCV), pages 618– 626, 2017. 1, 2, 3
work page 2017
-
[15]
Deep Visual City Recognition Visualization, 2019
Xiangwei Shi, Seyran Khademi, and Jan van Gemert. Deep Visual City Recognition Visualization, 2019. 2
work page 2019
-
[16]
SmoothGrad: Removing noise by adding noise, 2017
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Vi ´egas, and Martin Wattenberg. SmoothGrad: Removing noise by adding noise, 2017. 3
work page 2017
-
[17]
Ax- iomatic Attribution for Deep Networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Ax- iomatic Attribution for Deep Networks. InProceedings of the 34th International Conference on Machine Learning, pages 3319–3328. PMLR, 2017. 2
work page 2017
-
[18]
Revisiting IM2GPS in the Deep Learning Era
Nam V o, Nathan Jacobs, and James Hays. Revisiting IM2GPS in the Deep Learning Era. In2017 IEEE Interna- tional Conference on Computer Vision (ICCV), pages 2640– 2649, 2017. 2
work page 2017
-
[19]
Score-CAM: Score-Weighted Visual Explanations for Convolutional Neu- ral Networks
Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-CAM: Score-Weighted Visual Explanations for Convolutional Neu- ral Networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 24–25, 2020. 3
work page 2020
-
[20]
PlaNet - Photo Geolocation with Convolutional Neural Networks
Tobias Weyand, Ilya Kostrikov, and James Philbin. PlaNet - Photo Geolocation with Convolutional Neural Networks. In Computer Vision – ECCV 2016, pages 37–55, Cham, 2016. Springer International Publishing. 1, 2
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.