Reinforcement Learning Trained Observer Control for Bearings-Only Tracking
Pith reviewed 2026-05-09 16:49 UTC · model grok-4.3
The pith
Reinforcement learning can train an observer control policy that achieves the same average tracking accuracy as information-theoretic methods but reduces worst-case errors by a factor of nearly ten in bearings-only scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
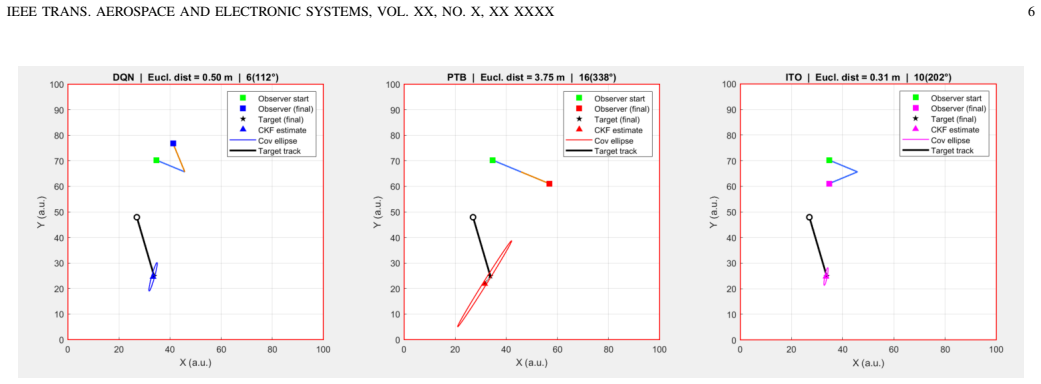
The central claim is that the DQN policy trained at β = 0.7 on the geometric interpolation reward achieves matching mean tracking accuracy to the D-optimal criterion while reducing the worst-case error by nearly a factor of ten over 5000 Monte Carlo episodes, because the Mahalanobis term implicitly regularizes for filter consistency.
What carries the argument
The key machinery is the belief Markov decision process with the cubature Kalman filter posterior serving as the belief state and a geometrically interpolated reward between Euclidean position error and Mahalanobis consistency distance controlled by parameter β.
If this is right
- The DQN policy at β = 0.7 matches the information-theoretic baseline on mean tracking accuracy.
- It reduces the worst-case error by nearly a factor of ten.
- The improvement stems from implicit filter-consistency regularisation via the Mahalanobis term.
- Performance was demonstrated over 50,000 training episodes and 5,000 evaluation episodes against heuristic and information baselines.
Where Pith is reading between the lines
- Similar reward designs could improve robustness in other estimation and control problems where filter consistency matters.
- Testing the policy on trajectories with maneuvers outside the training distribution would reveal its generalization limits.
- The results imply that pure information maximization may leave some error distributions vulnerable to large outliers.
Load-bearing premise
The load-bearing premise is that the cubature Kalman filter posterior provides a sufficient belief state for the decision process and that the chosen beta value generalizes to unseen target paths and noise settings.
What would settle it
Evaluating the DQN policy on Monte Carlo trials with target trajectories that include sudden turns or altered measurement noise not present during training, to see if the factor-of-ten worst-case improvement persists.
Figures

read the original abstract
This paper develops a deep reinforcement learning based observer control policy for autonomous bearings-only tracking of a moving target. The observer manoeuvre problem is formulated as a belief Markov decision process, where the belief state is represented by the posterior of a cubature Kalman filter (CKF). The reward function is designed to address two conflicting objectives: minimising the absolute target position estimation error (Euclidean distance) and maintaining CKF estimation consistency (Mahalanobis distance). The reward is formulated as a geometric interpolation between the two objectives on the Pareto front, parametrised by a weighting factor $\beta \in [0,1]$. The policy is implemented as a deep Q-network (DQN) trained over 50,000 episodes. Performance is evaluated over 5,000 Monte Carlo episodes and compared against two baselines: the perpendicular-to-bearing heuristic and the D-optimal Fisher information maximisation criterion. The results show that the DQN policy at $\beta = 0.7$ achieves the best trade-off between accuracy and robustness: it matches the information-theoretic baseline on mean tracking accuracy while reducing the worst-case error by nearly a factor of ten, owing to the implicit filter-consistency regularisation provided by the Mahalanobis term in the reward.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates observer control for bearings-only tracking of a moving target as a belief MDP whose state is the posterior of a cubature Kalman filter (CKF). A DQN policy is trained for 50,000 episodes with a reward that geometrically interpolates (via tunable β) between Euclidean position error and Mahalanobis consistency. Monte-Carlo evaluation over 5,000 episodes shows that the policy at β = 0.7 matches the mean accuracy of the D-optimal Fisher-information baseline while reducing worst-case position error by nearly a factor of ten, which the authors attribute to implicit filter-consistency regularization.
Significance. If the empirical claims hold, the work is significant for demonstrating that reinforcement learning can produce observer policies that improve robustness over both heuristic and information-theoretic baselines in a classic nonlinear estimation setting. The geometric reward construction and the scale of the Monte-Carlo evaluation (5,000 episodes) are concrete strengths that make the reported trade-off between mean accuracy and tail performance falsifiable and potentially useful for autonomous navigation applications.
major comments (2)
- [§3 (Belief MDP formulation)] §3 (Belief MDP formulation): The central attribution of the ~10× worst-case error reduction to the Mahalanobis term in the reward presupposes that the CKF Gaussian posterior is a sufficient statistic for the MDP. Bearings-only measurements are known to induce range ambiguity and potentially multi-modal or non-Gaussian uncertainty; no diagnostic is provided showing that the filter remains consistent precisely on the trajectories where the worst-case improvement appears. This leaves open the possibility that the reported robustness is an artifact of the training distribution rather than a general property of the reward interpolation.
- [§4 (Experimental Evaluation)] §4 (Experimental Evaluation): The claim that the β = 0.7 policy generalizes to unseen target trajectories and noise conditions rests on a single Monte-Carlo test set whose distribution relative to training is not characterized. Without an explicit out-of-distribution test (e.g., different target speeds, sensor noise levels, or initial range ambiguities), the robustness advantage cannot be separated from possible overfitting to the training ensemble.
minor comments (2)
- The DQN architecture, layer sizes, replay-buffer size, and exact hyper-parameter schedule for β during training are not reported, which limits reproducibility of the claimed policy.
- Figure 3 (or equivalent) showing error histograms would benefit from explicit annotation of the 95th-percentile and maximum errors to make the factor-of-ten claim immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below and indicate the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [§3 (Belief MDP formulation)] §3 (Belief MDP formulation): The central attribution of the ~10× worst-case error reduction to the Mahalanobis term in the reward presupposes that the CKF Gaussian posterior is a sufficient statistic for the MDP. Bearings-only measurements are known to induce range ambiguity and potentially multi-modal or non-Gaussian uncertainty; no diagnostic is provided showing that the filter remains consistent precisely on the trajectories where the worst-case improvement appears. This leaves open the possibility that the reported robustness is an artifact of the training distribution rather than a general property of the reward interpolation.
Authors: We agree that bearings-only measurements can produce range ambiguities leading to non-Gaussian or multi-modal posteriors, and that the CKF provides only a Gaussian approximation. Our belief MDP is deliberately formulated with the CKF posterior as the state representation, which is a standard and computationally tractable choice for this class of problems. The geometric reward is constructed precisely to penalize deviations from consistency within that Gaussian model. While the original submission did not include trajectory-specific consistency diagnostics focused on the worst-case episodes, we have revised the manuscript to add NEES statistics and consistency plots for the 100 highest-error trajectories under the β = 0.7 policy (new Figure 7 and accompanying text in §4.2). These diagnostics indicate that the policy maintains lower NEES values than the baselines on those trajectories, supporting that the observed robustness is tied to the consistency term in the reward rather than an artifact of the training distribution alone. revision: yes
-
Referee: [§4 (Experimental Evaluation)] §4 (Experimental Evaluation): The claim that the β = 0.7 policy generalizes to unseen target trajectories and noise conditions rests on a single Monte-Carlo test set whose distribution relative to training is not characterized. Without an explicit out-of-distribution test (e.g., different target speeds, sensor noise levels, or initial range ambiguities), the robustness advantage cannot be separated from possible overfitting to the training ensemble.
Authors: The 5,000-episode test set is generated from the same parametric distributions as the training episodes (initial range, bearing, target velocity, and measurement noise) but with independent random seeds, yielding distinct trajectories. We have revised §4.1 to include an explicit statistical comparison (new Table 2) of means and variances for key parameters between the training and test ensembles. To address the request for out-of-distribution evaluation, we have added §4.3 containing results on two modified regimes: target speeds increased by 50 % and sensor noise variance doubled. In both cases the β = 0.7 policy retains its worst-case error reduction relative to the baselines, providing evidence that the robustness is not limited to the original training distribution. revision: yes
Circularity Check
No significant circularity; empirical RL training pipeline is self-contained
full rationale
The paper formulates observer control as a belief MDP with CKF posterior as state and trains a DQN policy to maximize a tunable geometric reward interpolating Euclidean position error against Mahalanobis consistency. All reported performance numbers (mean accuracy, worst-case error) are obtained directly from Monte Carlo rollouts of the trained policy on held-out episodes; no closed-form derivation, fitted parameter renamed as prediction, or self-citation chain reduces the headline result to its inputs by construction. The choice of beta is presented as an empirical trade-off parameter, not a derived quantity.
Axiom & Free-Parameter Ledger
free parameters (1)
- beta =
0.7
Reference graph
Works this paper leans on
- [1]
-
[2]
Position and velocity estimation via bearing observations,
A. G. Lingren and K. F. Gong, “Position and velocity estimation via bearing observations,”IEEE Trans. on Aerospace and Electronic Systems, no. 4, pp. 564–577, 1978
work page 1978
-
[3]
A Gaussian-sum based cubature Kalman filter for bearings-only track- ing,
P. H. Leong, S. Arulampalam, T. A. Lamahewa, and T. D. Abhayapala, “A Gaussian-sum based cubature Kalman filter for bearings-only track- ing,”IEEE Trans. on Aerospace and Electronic Systems, vol. 49, no. 2, pp. 1161–1176, 2013
work page 2013
-
[4]
Observability criteria for bearings-only target motion analysis,
S. C. Nardone and V . J. Aidala, “Observability criteria for bearings-only target motion analysis,”IEEE Trans. Aerospace and Electronic Systems, vol. 17, no. 2, pp. 162–166, 1981
work page 1981
-
[5]
Observability metrics for single-target tracking with bearings-only measurements,
H. Jiang, Y . Cai, and Z. Yu, “Observability metrics for single-target tracking with bearings-only measurements,”IEEE Trans. on Systems, Man, and Cybernetics: Systems, vol. 52, no. 2, pp. 1065–1077, 2022
work page 2022
-
[6]
Nonlinear data observability and informa- tion,
R. Mohler and C. Hwang, “Nonlinear data observability and informa- tion,”Journal of the Franklin Institute, vol. 325, no. 4, pp. 443–464, 1988
work page 1988
-
[7]
Optimal obsever maneuver for bearings-only tracking,
J. M. Passerieux and D. V . Cappel, “Optimal obsever maneuver for bearings-only tracking,”IEEE Trans. Aerospace and Electronic Systems, vol. 34, no. 3, pp. 777–788, 1998
work page 1998
-
[8]
Optimization of observer trajectories for bearings only target localization,
Y . Oshman and P. Davidson, “Optimization of observer trajectories for bearings only target localization,”IEEE Trans Aerospace and Electronic Systems, vol. 35, no. 3, pp. 892–902, 1999
work page 1999
-
[9]
An information theoretic approach to observer path design for bearings-only tracking,
A. Logothetis, A. Isaksson, and R. Evans, “An information theoretic approach to observer path design for bearings-only tracking,” inProc. of 36th IEEE Conference on Decision and Control, vol. 4, 1997, pp. 3132–3137
work page 1997
-
[10]
Bernoulli particle filter with observer control for bearings only tracking in clutter,
B. Ristic and S. Arulampalam, “Bernoulli particle filter with observer control for bearings only tracking in clutter,”IEEE Trans Aerospace and Electronic Systems, vol. 48, no. 3, July 2012
work page 2012
-
[11]
Optimal sensor trajectories in bearings-only track- ing,
M. L. Hernandez, “Optimal sensor trajectories in bearings-only track- ing,” inProc. of the 7th Intern. Conference on Information Fusion, vol. 2, 2004, pp. 893–900
work page 2004
-
[12]
Double Q-learning for radiation source detection,
Z. Liu and S. Abbaszadeh, “Double Q-learning for radiation source detection,”Sensors, vol. 19, no. 4, p. 960, 2019
work page 2019
-
[13]
X. Chen, C. Fu, and J. Huang, “A deep Q-network for robotic odor/gas source localization: Modeling, measurement and comparative study,” Measurement, vol. 183, p. 109725, 2021
work page 2021
-
[14]
Enhanced reward function design for source term estimation based on deep reinforcement learning,
J. Lee, H. Jang, M. Park, and H. Oh, “Enhanced reward function design for source term estimation based on deep reinforcement learning,”IEEE Access, 2025
work page 2025
-
[15]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction, 2nd ed. MIT press, Cambridge, 2018
work page 2018
-
[16]
Prediction- guided multi-objective reinforcement learning for continuous robot control,
J. Xu, Y . Tian, P. Ma, D. Rus, S. Sueda, and W. Matusik, “Prediction- guided multi-objective reinforcement learning for continuous robot control,” inInternational conference on machine learning, 2020, pp. 10 607–10 616
work page 2020
-
[17]
Y . Bar-Shalom, X. R. Li, and T. Kirubarajan,Estimation with Applica- tions to Tracking and Navigation. John Wiley & Sons, 2001
work page 2001
-
[18]
I. Arasaratnam and S. Haykin, “Cubature kalman filters,”IEEE Trans. on automatic control, vol. 54, no. 6, pp. 1254–1269, 2009
work page 2009
-
[19]
A Gaussian-sum based cubature Kalman filter for bearings-only tracking,
P. H. Leong, S. Arulampalam, T. Lamahewa, and T. D. Abhayapala, “A Gaussian-sum based cubature Kalman filter for bearings-only tracking,” IEEE Trans. Aerospace and Electronic Systems, vol. 49, no. 2, pp. 1161– 1176, 2013
work page 2013
-
[20]
Human- level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjelandet al., “Human- level control through deep reinforcement learning,”Nature, vol. 518, no. 7540, pp. 529–533, 2015
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.