Instance-Level Costs for Nuanced Classifier Evaluation
Pith reviewed 2026-05-08 19:00 UTC · model grok-4.3
The pith
A weighted error metric shows that most classifier mistakes happen on low-cost ambiguous cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
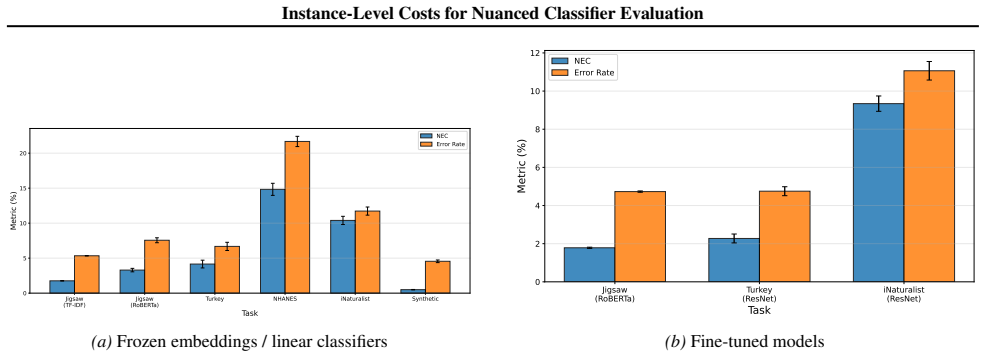
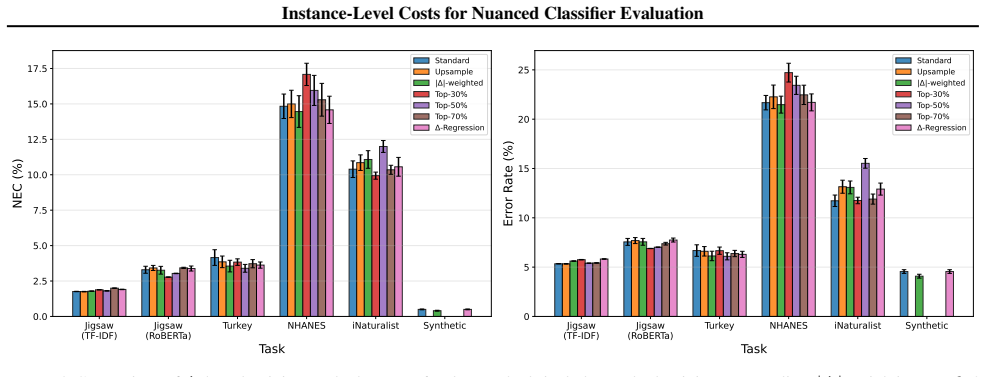
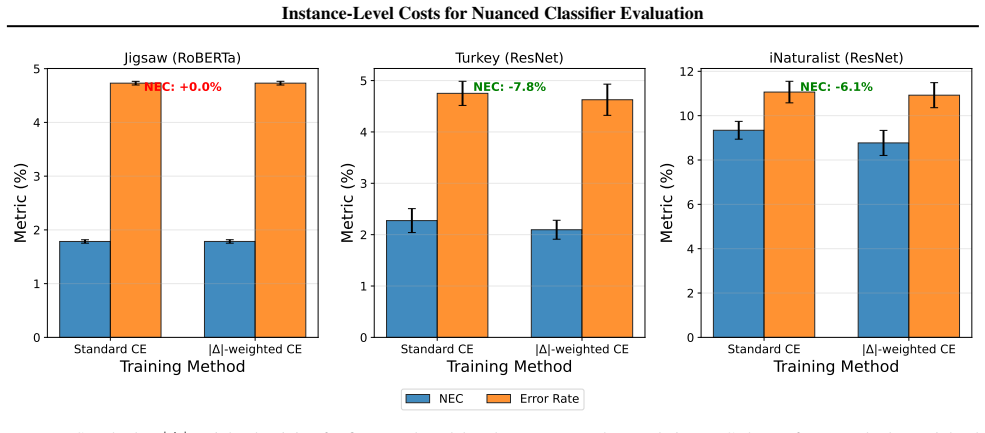
Normalized excess cost weights each misclassification by an instance-specific cost and normalizes so the measure equals ordinary error rate when costs are uniform. On standard benchmarks this quantity is typically much smaller than the unweighted error rate, because errors concentrate on ambiguous low-cost examples. Cost-sensitive training methods such as loss reweighting or sampling improve performance only when the instance costs are predictable from the input features, as demonstrated in a synthetic control; real datasets show mixed or no benefit.
What carries the argument
Normalized excess cost (NEC), a metric that multiplies each error by its per-example cost and normalizes the total to match standard error rate under uniform costs.
Load-bearing premise
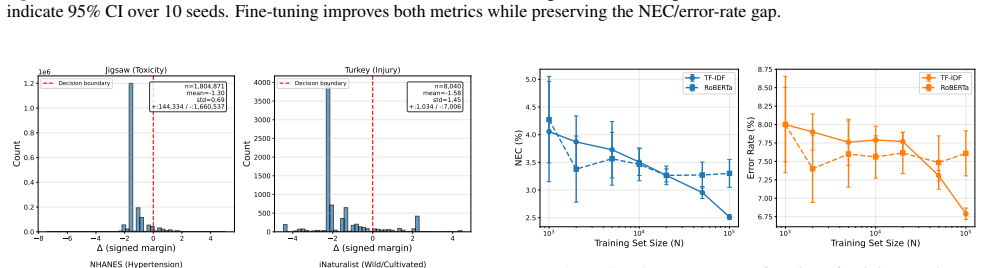
The costs estimated from annotator vote margins, distance to thresholds, or scores actually match the real deployment costs of misclassifying each instance.
What would settle it
Measure actual harms or operational costs from misclassifications in a deployed system and check whether they correlate with the costs derived from annotator margins or model confidence on the same examples.
Figures

read the original abstract
Standard classification treats all errors equally, but in content moderation, medical screening, and safety-critical applications, mistakes on clear-cut cases are far more costly than errors on ambiguous ones. We propose normalized excess cost (NEC), a metric that weights classification errors by per-example costs and reduces to standard error rate when costs are uniform. Costs can derive from annotator vote margins, distance from decision thresholds, or confidence ratings. Across text, image, and tabular benchmarks, we find that NEC is often substantially lower than error rate -- models with 5\% error rate can achieve 1.8\% NEC -- revealing that most mistakes concentrate on ambiguous, low-cost examples. However, incorporating costs into training via loss weighting, sampling strategies, or regression yields inconsistent benefits: improvements appear only when costs are predictable from input features, as in our synthetic control, while real-world datasets show mixed or negligible gains. Our framework provides a practical methodology for deriving and evaluating instance-level misclassification costs, even when cost-sensitive training offers limited benefit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Normalized Excess Cost (NEC), a metric that weights per-instance classification errors by costs derived from proxies such as annotator vote margins, distance to decision thresholds, or model confidence scores. NEC reduces to standard error rate under uniform costs. Across text, image, and tabular benchmarks, the authors report that NEC is often substantially lower than error rate (e.g., 5% error yielding 1.8% NEC), indicating errors concentrate on ambiguous low-cost instances. Experiments on cost-sensitive training (loss weighting, sampling, regression) show inconsistent benefits, appearing mainly in synthetic settings where costs are predictable from features, with mixed or negligible gains on real data. The work also provides a methodology for deriving and using instance-level costs.
Significance. If the cost proxies are shown to align with external deployment consequences, NEC would enable more nuanced classifier evaluation in domains like content moderation and medical screening, where uniform error rates may overstate risk by treating all mistakes equally. The synthetic-versus-real distinction and the negative result on training benefits are valuable contributions. The practical methodology for cost derivation is a strength, though its broader impact hinges on validation of the proxies.
major comments (2)
- [Abstract and empirical results] Abstract and empirical results section: the quantitative headline that 'models with 5% error rate can achieve 1.8% NEC' and that NEC is 'often substantially lower' is stated without identifying the specific benchmarks, number of runs, variance, or statistical tests used to support the claim. This detail is load-bearing for the central assertion that mistakes concentrate on low-cost examples.
- [Cost derivation and interpretation] Cost derivation and interpretation (methods and discussion): the claim that the NEC reduction 'reveals' errors on ambiguous low-cost examples assumes the proxies (vote margins, confidence, threshold distance) meaningfully track true deployment misclassification costs. No external validation against real-world cost measures is described, so the reduction is also consistent with reweighting by any internal ambiguity signal; this directly affects the interpretation of the main finding.
minor comments (2)
- [Methods] The formal definition of NEC (including normalization) should be presented as an equation in the early methods section rather than described only in prose.
- Notation for per-example cost c_i and the exact normalization factor in NEC should be made consistent across text, equations, and figures to avoid ambiguity.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments below, agreeing with the need for greater specificity in the abstract and for clearer discussion of the cost proxies' limitations. We propose revisions accordingly.
read point-by-point responses
-
Referee: [Abstract and empirical results] Abstract and empirical results section: the quantitative headline that 'models with 5% error rate can achieve 1.8% NEC' and that NEC is 'often substantially lower' is stated without identifying the specific benchmarks, number of runs, variance, or statistical tests used to support the claim. This detail is load-bearing for the central assertion that mistakes concentrate on low-cost examples.
Authors: We agree that the abstract would benefit from additional context to support the headline claims. In the revised manuscript, we will update the abstract to reference the specific benchmarks used in the experiments and indicate that the reported figures are averages over multiple runs, with variance and statistical details provided in the main text and supplementary material. This will strengthen the presentation without altering the findings. revision: yes
-
Referee: [Cost derivation and interpretation] Cost derivation and interpretation (methods and discussion): the claim that the NEC reduction 'reveals' errors on ambiguous low-cost examples assumes the proxies (vote margins, confidence, threshold distance) meaningfully track true deployment misclassification costs. No external validation against real-world cost measures is described, so the reduction is also consistent with reweighting by any internal ambiguity signal; this directly affects the interpretation of the main finding.
Authors: We acknowledge that our cost proxies are derived from internal model or annotation signals and have not been validated against external real-world cost measures, which is a limitation of the current study. The reduction in NEC demonstrates that errors tend to occur on instances with high ambiguity according to these proxies, providing a more nuanced evaluation than uniform error rates. We will revise the discussion section to explicitly state the assumptions underlying the proxies and suggest directions for future external validation, such as through user studies or deployment logs. This does not change the core methodology but clarifies the scope of the interpretation. revision: partial
Circularity Check
No circularity in NEC definition or empirical findings
full rationale
The paper defines normalized excess cost (NEC) explicitly as a weighted sum of per-example misclassification errors, normalized such that it equals the standard error rate when all costs are uniform. This is a direct, non-reductive definition with no fitted parameters or self-referential quantities. The reported results (NEC often substantially below error rate on benchmarks) are straightforward empirical computations on public datasets using costs derived from observable properties like vote margins or model confidence; these are inputs to the metric rather than outputs that loop back. No equations reduce the findings to the inputs by construction, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatzes or renamings of known results are smuggled in. The framework is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Instance-level costs can be derived from annotator vote margins, distance to decision thresholds, or model confidence scores
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (J(x) = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose normalized excess cost (NEC), a metric that weights classification errors by per-example costs and reduces to standard error rate when costs are uniform.
-
IndisputableMonolith/Cost/FunctionalEquationJcost_pos_of_ne_one unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Δ_i = log((n_{i,yes}+1)/(n_{i,no}+1)) ... Log-odds is the natural scale for binary outcomes: it is symmetric around zero, unbounded, and |Δ| is monotonically related to distance from maximum uncertainty.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
C. Elkan. The Foundations of Cost-Sensitive Learning. Proceedings of the 17th International Joint Conference on Artificial Intelligence (IJCAI 2001). 2001
work page 2001
-
[2]
B. Zadrozny and J. Langford and N. Abe. Cost-Sensitive Learning by Cost-Proportionate Example Weighting. Proceedings of the 3rd IEEE International Conference on Data Mining (ICDM 2003). 2003
work page 2003
-
[3]
J. Langford and A. Beygelzimer. Sensitive Error Correcting Output Codes. Proceedings of the 18th Annual Conference on Learning Theory (COLT 2005). 2005
work page 2005
-
[4]
A. C. Bahnsen and D. Aouada and B. Ottersten. Example-Dependent Cost-Sensitive Decision Trees. Expert Systems with Applications. 2015
work page 2015
-
[5]
A. P. Dawid and A. M. Skene. Maximum Likelihood Estimation of Observer Error-Rates Using the EM Algorithm. Journal of the Royal Statistical Society: Series C (Applied Statistics). 1979
work page 1979
-
[6]
B. Plank and D. Hovy and A. S gaard. Linguistically Debatable or Just Plain Wrong?. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL 2014). 2014
work page 2014
-
[7]
E. Pavlick and T. Kwiatkowski. Inherent Disagreements in Human Textual Inferences. Transactions of the Association for Computational Linguistics. 2019
work page 2019
-
[8]
J. C. Peterson and R. M. Battleday and T. L. Griffiths and O. Russakovsky. Human Uncertainty Makes Classification More Robust. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2019). 2019
work page 2019
- [9]
- [10]
-
[11]
B. Plank. The ``Problem'' of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022). 2022
work page 2022
-
[12]
K. Kurniawan and M. Mistica and T. Baldwin and J. H. Lau. Training and Evaluating with Human Label Variation: An Empirical Study. 2025
work page 2025
-
[13]
M. Raghu and K. Blumer and R. Sayres and Z. Obermeyer and B. Kleinberg and S. Mullainathan and J. Kleinberg. Direct Uncertainty Prediction for Medical Second Opinions. Proceedings of the 36th International Conference on Machine Learning (ICML 2019). 2019
work page 2019
-
[14]
J. Byrd and Z. C. Lipton. What is the Effect of Importance Weighting in Deep Learning?. Proceedings of the 36th International Conference on Machine Learning (ICML 2019). 2019
work page 2019
-
[15]
European Journal of Operational Research , volume=
Instance-dependent cost-sensitive learning for detecting transfer fraud , author=. European Journal of Operational Research , volume=. 2022 , publisher=
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.