TACO: Trajectory Aligning Cross-view Optimisation
Pith reviewed 2026-05-08 01:30 UTC · model grok-4.3
The pith
TACO fuses IMU motion with triggered satellite-image matches to cut median trajectory error 5.9 times on KITTI while using only 5-10 percent camera time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
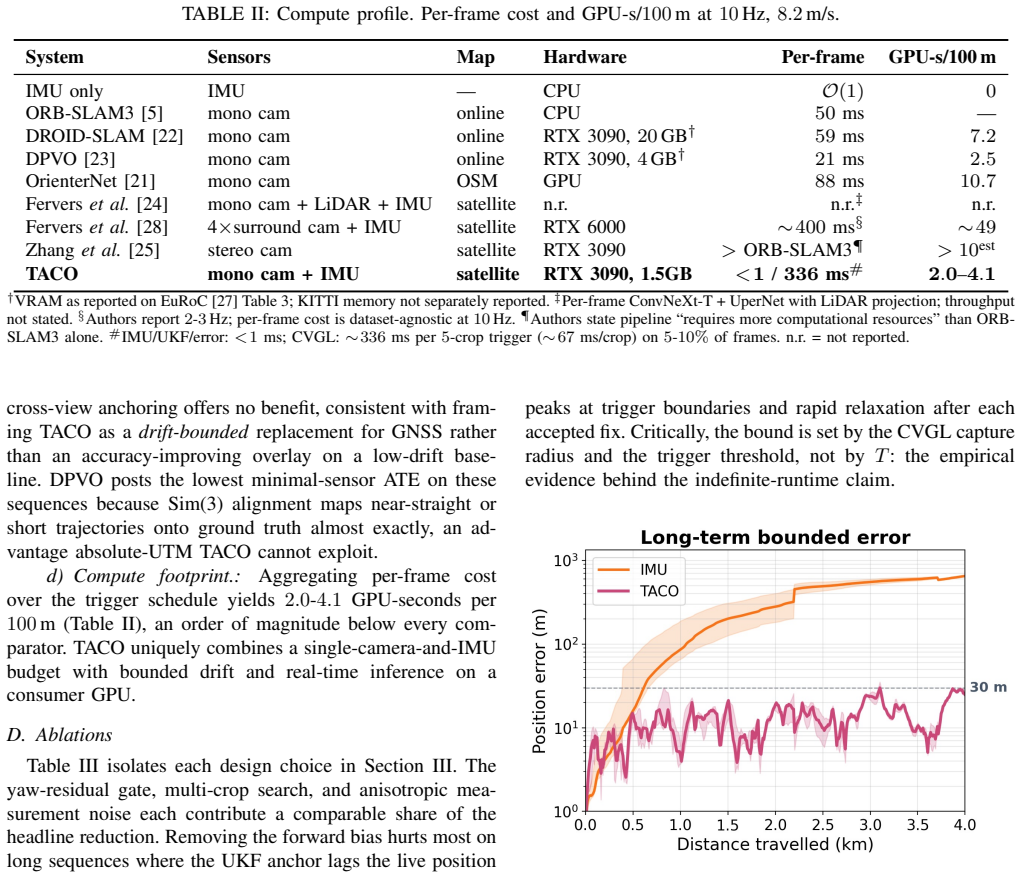
TACO is a tightly-coupled IMU plus fine-grained CVGL pipeline that consumes a single GNSS reading at start-up and thereafter operates on onboard sensing alone. A closed-form cross-track error model triggers CVGL before IMU drift exceeds the matcher's capture radius, and a forward-biased five-point multi-crop search keeps inference cost fixed at five forward passes per fix. A yaw-residual gate rejects fixes that disagree with the onboard compass, and an anisotropic body-frame noise model scales each Unscented Kalman Filter update by per-fix confidence. A factor graph with vetted loop closures provides an offline smoothed trajectory. On the KITTI raw dataset, TACO reduces median Absolute Traj
What carries the argument
the closed-form cross-track error model that predicts IMU drift to trigger CVGL fixes only when the position is about to exit the matcher's capture radius
If this is right
- Absolute positioning remains possible after a single GNSS start-up reading and with camera duty cycle limited to 5-10 percent.
- Per-frame fusion cost stays below 0.1 ms while inference per fix is capped at five forward passes.
- Yaw-residual gating and anisotropic noise scaling prevent bad matches from corrupting the Unscented Kalman Filter.
- Offline factor-graph smoothing with loop closures produces a globally consistent trajectory from the same online fixes.
Where Pith is reading between the lines
- The same triggering logic could be ported to other expensive sensors such as lidar or radar by swapping the CVGL matcher for an equivalent absolute fix source.
- In power-constrained robots the method implies a tunable trade-off between camera duty cycle and acceptable drift bound by adjusting the model's safety margin.
- The yaw gate and anisotropic scaling components are modular and could be inserted into existing visual-inertial odometry pipelines without changing the core filter.
Load-bearing premise
The closed-form cross-track error model reliably predicts the exact moment when IMU drift will push the position outside the CVGL matcher's capture radius in real time.
What would settle it
A sequence of KITTI-style runs in which the actual cross-track error exceeds the CVGL capture radius before the model triggers a fix, causing the filter to lose lock with no subsequent recovery.
Figures




read the original abstract
Cross-View Geo-localisation (CVGL) matches ground imagery against satellite tiles to give absolute position fixes, an alternative to GNSS where signals are occluded, jammed, or spoofed. Recent fine-grained CVGL methods regress sub-tile metric pose, but have only been evaluated as one-shot localisers, never as the primary fix in a live pipeline. Inertial sensing provides high-rate relative motion, but accumulates unbounded drift without an absolute anchor. We propose TACO, a tightly-coupled IMU + fine-grained CVGL pipeline that consumes a single GNSS reading at start-up and thereafter operates on onboard sensing alone. A closed-form cross-track error model triggers CVGL before IMU drift exceeds the matcher's capture radius, and a forward-biased five-point multi-crop search keeps inference cost fixed at five forward passes per fix. A yaw-residual gate rejects fixes that disagree with the onboard compass, and an anisotropic body-frame noise model scales each Unscented Kalman Filter update by per-fix confidence. A factor graph with vetted loop closures provides an offline smoothed trajectory. On the KITTI raw dataset, TACO reduces median Absolute Trajectory Error (ATE) from 97.0m (IMU-only) to 16.3m, a 5.9 times reduction, at <0.1 ms per-frame fusion cost and a 5-10% camera duty cycle. Code is available: github.com/tavisshore/TACO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. TACO proposes a tightly-coupled IMU + fine-grained CVGL pipeline for GNSS-denied trajectory estimation. It uses a closed-form cross-track error model to trigger CVGL fixes before IMU drift exceeds the matcher's capture radius, a forward-biased five-point multi-crop search, a yaw-residual gate, and an anisotropic noise model within an Unscented Kalman Filter, followed by offline factor-graph smoothing with loop closures. On the KITTI raw dataset the method reports reducing median ATE from 97.0 m (IMU-only) to 16.3 m (5.9× improvement) at <0.1 ms per-frame fusion cost and 5–10 % camera duty cycle, with code released.
Significance. If the central empirical claim and triggering model hold under realistic IMU noise, the work demonstrates a practical, low-duty-cycle alternative to continuous GNSS by integrating recent fine-grained CVGL into a live filter pipeline. The released code and quantitative result on a standard benchmark are positive contributions that could support further research in GNSS-denied navigation.
major comments (3)
- [Section 3.2] The closed-form cross-track error model used to trigger CVGL (Section 3.2) is presented without quantitative validation against observed IMU drift on KITTI sequences (e.g., predicted vs. measured cross-track error curves or failure-rate statistics under the dataset's actual bias and motion profiles). This validation is load-bearing for the claimed timely triggering, 5.9× ATE reduction, and 5–10 % duty-cycle operating point.
- [Section 4] Results (Section 4): the headline median ATE figures lack reported variance, error bars, number of sequences evaluated, or ablations isolating the contribution of the cross-track trigger, yaw-residual gate, and anisotropic noise model. Without these, the robustness of the 5.9× improvement cannot be fully assessed.
- [Section 3.3] The five-point multi-crop search and forward-bias strategy (Section 3.3) are described at a high level; the manuscript does not quantify how often the search actually succeeds in recovering the true pose when the trigger fires, which directly affects the reported duty cycle and ATE.
minor comments (3)
- [Abstract] Abstract and Section 2: a brief reference to the specific fine-grained CVGL regressor used (architecture, training data) would clarify the capture-radius assumption.
- [Section 3.4] Notation: the anisotropic noise scaling factors are introduced without an explicit equation linking them to the per-fix CVGL confidence score.
- [Figure 3] Figure 3 (trajectory plots): axis scales and sequence identifiers should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We have carefully considered each major comment and revised the manuscript accordingly to address the concerns about validation, statistical reporting, and quantification of key components. Our point-by-point responses are provided below.
read point-by-point responses
-
Referee: [Section 3.2] The closed-form cross-track error model used to trigger CVGL (Section 3.2) is presented without quantitative validation against observed IMU drift on KITTI sequences (e.g., predicted vs. measured cross-track error curves or failure-rate statistics under the dataset's actual bias and motion profiles). This validation is load-bearing for the claimed timely triggering, 5.9× ATE reduction, and 5–10 % duty-cycle operating point.
Authors: We agree that explicit quantitative validation of the closed-form cross-track error model is important to support the triggering mechanism. In the revised manuscript, we have included new analysis in Section 3.2 with predicted versus measured cross-track error curves on KITTI sequences, demonstrating close agreement under the dataset's IMU bias and motion profiles. We also report failure-rate statistics showing that the model triggers CVGL in a timely manner before exceeding the matcher's capture radius, thereby justifying the 5–10% duty cycle and the observed ATE reduction. revision: yes
-
Referee: [Section 4] Results (Section 4): the headline median ATE figures lack reported variance, error bars, number of sequences evaluated, or ablations isolating the contribution of the cross-track trigger, yaw-residual gate, and anisotropic noise model. Without these, the robustness of the 5.9× improvement cannot be fully assessed.
Authors: We acknowledge the need for more comprehensive statistical reporting. The revised Section 4 now includes the number of sequences evaluated, per-sequence ATE values with standard deviations and error bars in the updated tables, and ablations that isolate the individual contributions of the cross-track trigger, yaw-residual gate, and anisotropic noise model. These additions confirm the robustness of the 5.9× median ATE improvement. revision: yes
-
Referee: [Section 3.3] The five-point multi-crop search and forward-bias strategy (Section 3.3) are described at a high level; the manuscript does not quantify how often the search actually succeeds in recovering the true pose when the trigger fires, which directly affects the reported duty cycle and ATE.
Authors: We have expanded Section 3.3 to include quantitative metrics on the success rate of the five-point multi-crop search. Specifically, we now report the percentage of cases where the search recovers the true pose upon triggering, along with the improvement due to the forward-bias strategy. This quantification supports the claimed duty cycle and overall trajectory accuracy. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper derives a closed-form cross-track error model from IMU dynamics to trigger CVGL fixes, then integrates it with standard UKF updates, anisotropic noise scaling, yaw gating, and offline factor-graph smoothing. All performance numbers (e.g., 5.9× ATE reduction on KITTI) are obtained by running the pipeline on an external public benchmark rather than by fitting parameters inside the same equations and then re-predicting those quantities. No self-definitional steps, fitted-input-called-prediction patterns, or load-bearing self-citations appear in the abstract or described machinery. The derivation therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (3)
- cross-track error trigger threshold
- yaw-residual gate threshold
- anisotropic noise scaling factors
axioms (3)
- domain assumption IMU provides high-rate relative motion whose error grows unbounded without absolute corrections
- domain assumption Fine-grained CVGL can return metric pose when the query lies inside the matcher's capture radius
- standard math Unscented Kalman Filter fusion and factor-graph smoothing behave as standard textbook methods
Reference graph
Works this paper leans on
-
[1]
Convolutional cross-view pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3813–3831, 2023
Zimin Xia, Olaf Booij, and Julian FP Kooij. Convolutional cross-view pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3813–3831, 2023
2023
-
[2]
Slice- match: Geometry-guided aggregation for cross-view pose estimation
Ted Lentsch, Zimin Xia, Holger Caesar, and Julian FP Kooij. Slice- match: Geometry-guided aggregation for cross-view pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17225–17234, 2023
2023
-
[3]
Fgˆ 2: Fine-grained cross-view localization by fine-grained feature matching
Zimin Xia and Alexandre Alahi. Fgˆ 2: Fine-grained cross-view localization by fine-grained feature matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6362–6372, 2025
2025
-
[4]
Vins-mono: A robust and versatile monocular visual-inertial state estimator.IEEE transactions on robotics, 34(4):1004–1020, 2018
Tong Qin, Peiliang Li, and Shaojie Shen. Vins-mono: A robust and versatile monocular visual-inertial state estimator.IEEE transactions on robotics, 34(4):1004–1020, 2018
2018
-
[5]
Orb-slam3: An accurate open-source li- brary for visual, visual–inertial, and multimap slam.IEEE transactions on robotics, 37(6):1874–1890, 2021
Carlos Campos, Richard Elvira, Juan J G ´omez Rodr´ıguez, Jos´e MM Montiel, and Juan D Tard ´os. Orb-slam3: An accurate open-source li- brary for visual, visual–inertial, and multimap slam.IEEE transactions on robotics, 37(6):1874–1890, 2021
2021
-
[6]
Keyframe-based visual–inertial odometry using non- linear optimization.The International Journal of Robotics Research, 34(3):314–334, 2015
Stefan Leutenegger, Simon Lynen, Michael Bosse, Roland Siegwart, and Paul Furgale. Keyframe-based visual–inertial odometry using non- linear optimization.The International Journal of Robotics Research, 34(3):314–334, 2015
2015
-
[7]
Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping
Tixiao Shan, Brendan Englot, Drew Meyers, Wei Wang, Carlo Ratti, and Daniela Rus. Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping. In2020 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 5135–5142. IEEE, 2020
2020
-
[8]
Fast-lio2: Fast direct lidar-inertial odometry.IEEE Transactions on Robotics, 38(4):2053–2073, 2022
Wei Xu, Yixi Cai, Dongjiao He, Jiarong Lin, and Fu Zhang. Fast-lio2: Fast direct lidar-inertial odometry.IEEE Transactions on Robotics, 38(4):2053–2073, 2022
2053
-
[9]
Visual localization within lidar maps for automated urban driving
Ryan W Wolcott and Ryan M Eustice. Visual localization within lidar maps for automated urban driving. In2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 176–183. IEEE, 2014
2014
-
[10]
Cvm-net: Cross-view matching network for image-based ground-to- aerial geo-localization
Sixing Hu, Mengdan Feng, Rang MH Nguyen, and Gim Hee Lee. Cvm-net: Cross-view matching network for image-based ground-to- aerial geo-localization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7258–7267, 2018
2018
-
[11]
Spatial-aware feature aggregation for image based cross-view geo-localization
Yujiao Shi, Liu Liu, Xin Yu, and Hongdong Li. Spatial-aware feature aggregation for image based cross-view geo-localization. volume 32, 2019
2019
-
[12]
Transgeo: Transformer is all you need for cross-view image geo-localization
Sijie Zhu, Mubarak Shah, and Chen Chen. Transgeo: Transformer is all you need for cross-view image geo-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1162–1171, 2022
2022
-
[13]
Bev-cv: Birds-eye- view transform for cross-view geo-localisation
Tavis Shore, Simon Hadfield, and Oscar Mendez. Bev-cv: Birds-eye- view transform for cross-view geo-localisation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11048–11055. IEEE, 2024
2024
-
[14]
Wide-area image geolocalization with aerial reference imagery
Scott Workman, Richard Souvenir, and Nathan Jacobs. Wide-area image geolocalization with aerial reference imagery. InIEEE Inter- national Conference on Computer Vision (ICCV), pages 1–9, 2015. Acceptance rate: 30.3%
2015
-
[15]
Vigor: Cross-view image geo-localization beyond one-to-one retrieval
Sijie Zhu, Taojiannan Yang, and Chen Chen. Vigor: Cross-view image geo-localization beyond one-to-one retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3640–3649, 2021
2021
-
[16]
Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformer
Yujiao Shi, Fei Wu, Akhil Perincherry, Ankit V ora, and Hongdong Li. Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21516–21526, 2023
2023
-
[17]
Peng: Pose-enhanced geo-localisation.IEEE Robotics and Automation Letters, 10(4):3835– 3842, 2025
Tavis Shore, Oscar Mendez, and Simon Hadfield. Peng: Pose-enhanced geo-localisation.IEEE Robotics and Automation Letters, 10(4):3835– 3842, 2025
2025
-
[18]
Uav pose estimation using cross-view geolocalization with satellite imagery
Akshay Shetty and Grace Xingxin Gao. Uav pose estimation using cross-view geolocalization with satellite imagery. In2019 Interna- tional Conference on Robotics and Automation (ICRA), pages 1827–
-
[19]
Evaluation of cross-view matching to improve ground vehicle localization with aerial perception, 2020
Deeksha Dixit, Surabhi Verma, and Pratap Tokekar. Evaluation of cross-view matching to improve ground vehicle localization with aerial perception, 2020
2020
-
[20]
Bevren- der: Vision-based cross-view vehicle registration in off-road gnss- denied environment
Lihong Jin, Wei Dong, Wenshan Wang, and Michael Kaess. Bevren- der: Vision-based cross-view vehicle registration in off-road gnss- denied environment. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11032–11039. IEEE, 2024
2024
-
[21]
Orienternet: Visual localization in 2d public maps with neural matching
Paul-Edouard Sarlin, Daniel DeTone, Tsun-Yi Yang, Armen Avetisyan, Julian Straub, Tomasz Malisiewicz, Samuel Rota Bulo, Richard New- combe, Peter Kontschieder, and Vasileios Balntas. Orienternet: Visual localization in 2d public maps with neural matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 21632–21...
2023
-
[22]
DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras
Zachary Teed and Jia Deng. DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[23]
Deep patch visual odometry.Advances in Neural Information Processing Systems, 36:39033–39051, 2023
Zachary Teed, Lahav Lipson, and Jia Deng. Deep patch visual odometry.Advances in Neural Information Processing Systems, 36:39033–39051, 2023
2023
-
[24]
Continuous self-localization on aerial images using visual and lidar sensors
Florian Fervers, Sebastian Bullinger, Christoph Bodensteiner, Michael Arens, and Rainer Stiefelhagen. Continuous self-localization on aerial images using visual and lidar sensors. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7028– 7035, 2022
2022
-
[25]
Increasing slam pose accuracy by ground-to-satellite image registration
Yanhao Zhang, Yujiao Shi, Shan Wang, Ankit V ora, Akhil Perincherry, Yongbo Chen, and Hongdong Li. Increasing slam pose accuracy by ground-to-satellite image registration. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 8522–8528. IEEE, 2024
2024
-
[26]
Vision meets robotics: The kitti dataset.International Journal of Robotics Research (IJRR), 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.International Journal of Robotics Research (IJRR), 2013
2013
-
[27]
Deep patch visual slam
Lahav Lipson, Zachary Teed, and Jia Deng. Deep patch visual slam. In European Conference on Computer Vision, pages 424–440. Springer, 2024
2024
-
[28]
Uncertainty-aware vision-based metric cross-view geolocalization
Florian Fervers, Sebastian Bullinger, Christoph Bodensteiner, Michael Arens, and Rainer Stiefelhagen. Uncertainty-aware vision-based metric cross-view geolocalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21621–21631, June 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.