Free Decompression with Algebraic Spectral Curves
Pith reviewed 2026-05-07 13:14 UTC · model grok-4.3
The pith
Algebraic spectral curves enable a general method for free decompression of spectral densities in machine learning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
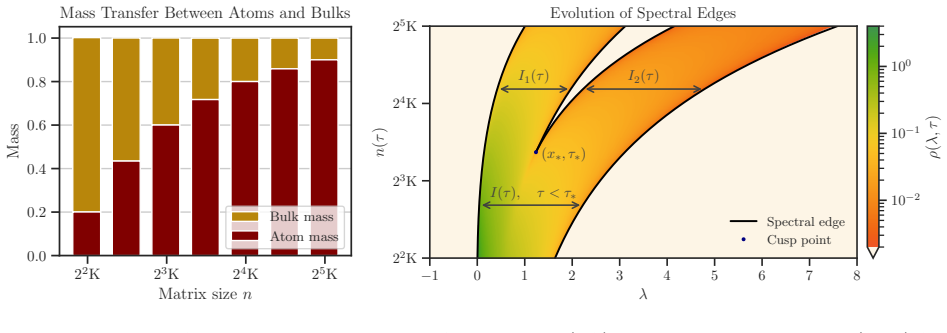
We use algebraic spectral curve theory to provide a general FD methodology for spectral densities whose Stieltjes transform satisfies an algebraic relation, a modeling assumption that is more likely to hold in practice. This recasts FD as an evolution along spectral curves which can be readily integrated. Our framework enables the expansion of spectral densities that have multiple or multi-modal bulks, that exist at multiple scales, and that contain atoms, all characteristic of real-world data and popular ML models.
What carries the argument
Algebraic spectral curves that recast free decompression as an integrable evolution for spectral densities with algebraic Stieltjes transforms.
If this is right
- Supports extrapolation for neural network Hessian and activation matrices with complex spectral features.
- Applies to large-scale diffusion models without requiring full matrix computations.
- Enables modeling of generalization and robustness in more realistic deep learning settings.
- Handles multi-scale and atomic components in spectral densities.
Where Pith is reading between the lines
- If the algebraic relation holds for more models, it could simplify analysis of scaling laws in neural networks.
- The approach might extend to predicting failure modes in large models from small prototypes.
- It suggests connections between algebraic structures in spectra and practical model behaviors across different architectures.
Load-bearing premise
The Stieltjes transform of the spectral density satisfies an algebraic relation.
What would settle it
Direct computation of the full spectrum for a large neural network Hessian and comparison against the prediction obtained by applying the method to a smaller version of the same model.
Figures





read the original abstract
Tools from random matrix theory have become central to deep learning theory, using spectral information to provide mechanisms for modeling generalization, robustness, scaling, and failure modes. While often capable of modeling empirical behavior, practical computations are limited by matrix size, often imposing a restriction to models that are too small to be realistic. This motivates the inference of properties of larger models from the behavior of smaller ones. Free decompression (FD) is a recently proposed method for extrapolating spectral information across matrix sizes, but its utility is currently limited by strong assumptions that preclude its implementation on more realistic machine learning (ML) models. We use algebraic spectral curve theory to provide a general FD methodology for spectral densities whose Stieltjes transform satisfies an algebraic relation, a modeling assumption that is more likely to hold in practice. This recasts FD as an evolution along spectral curves which can be readily integrated. Our framework enables the expansion of spectral densities that have multiple or multi-modal bulks, that exist at multiple scales, and that contain atoms, all characteristic of real-world data and popular ML models. We demonstrate the efficacy of our framework on models of interest in modern ML, including Hessian and activation matrices associated with neural networks and large-scale diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to generalize free decompression (FD) for spectral densities in ML models by recasting the problem as evolution along an algebraic spectral curve, applicable whenever the Stieltjes transform G(z) satisfies a polynomial equation P(z, G(z)) = 0. This is asserted to enable extrapolation of multi-bulk, multi-modal, multi-scale, and atomic spectra characteristic of neural-network Hessians, activations, and large diffusion models, overcoming limitations of prior FD methods that rely on stronger assumptions.
Significance. If the algebraic modeling assumption holds with sufficient accuracy for empirical spectra arising in realistic ML models, the framework would meaningfully extend random-matrix-theory tools to large-scale deep learning by permitting reliable inference of spectral properties across model sizes, directly supporting studies of generalization, robustness, and scaling.
major comments (2)
- [Abstract and Introduction] The load-bearing modeling assumption that empirical Stieltjes transforms of neural-network Hessians and diffusion-model spectra satisfy low-degree algebraic relations is stated in the abstract and introduction but is not accompanied by quantitative diagnostics (e.g., residual norms or degree-selection criteria) showing how closely the observed transforms adhere to any P(z, G(z)) = 0; without such evidence the claimed generality for “real-world data” remains unverified.
- [Methodology (curve-evolution procedure)] The integration of the resulting ODEs along the algebraic curve presupposes that a well-defined curve can be extracted from the small-model spectrum; the manuscript provides no error analysis or stability bounds quantifying how finite-N fluctuations or training-induced correlations propagate into the extrapolated density, which directly affects the reliability of the decompression step.
minor comments (2)
- [Throughout] Notation for the polynomial P and the resulting ODE system should be introduced with a concrete low-degree example before the general case to improve readability.
- [Experimental results] Demonstration figures comparing extrapolated and reference spectra would benefit from quantitative metrics (e.g., Kolmogorov-Smirnov distance or integrated squared error) rather than visual inspection alone.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which point to areas where additional validation and analysis would enhance the manuscript. We respond to each major comment below, indicating planned revisions.
read point-by-point responses
-
Referee: [Abstract and Introduction] The load-bearing modeling assumption that empirical Stieltjes transforms of neural-network Hessians and diffusion-model spectra satisfy low-degree algebraic relations is stated in the abstract and introduction but is not accompanied by quantitative diagnostics (e.g., residual norms or degree-selection criteria) showing how closely the observed transforms adhere to any P(z, G(z)) = 0; without such evidence the claimed generality for “real-world data” remains unverified.
Authors: We concur that quantitative support for the algebraic assumption is important for substantiating the generality claim. In the revised version, we will incorporate residual norm calculations for the polynomial equations fitted to the Stieltjes transforms of the neural network Hessians, activations, and diffusion model spectra presented in the paper. Additionally, we will describe the degree selection process, such as using cross-validation or residual thresholds, to justify the chosen algebraic degrees. revision: yes
-
Referee: [Methodology (curve-evolution procedure)] The integration of the resulting ODEs along the algebraic curve presupposes that a well-defined curve can be extracted from the small-model spectrum; the manuscript provides no error analysis or stability bounds quantifying how finite-N fluctuations or training-induced correlations propagate into the extrapolated density, which directly affects the reliability of the decompression step.
Authors: This is a valid observation regarding the robustness of the method. The current manuscript focuses on the deterministic evolution along the curve once extracted, without explicit propagation of uncertainties. We will revise the methodology section to include a brief analysis of stability, for example by examining how small perturbations in the small-model spectrum affect the integrated density, and report numerical experiments demonstrating the sensitivity to finite-N effects in our examples. A comprehensive theoretical bound on error propagation is beyond the scope of this work but will be noted as a direction for future research. revision: partial
Circularity Check
Algebraic modeling assumption stated explicitly; derivation is mathematical recasting with no reduction to fitted inputs or self-citations
full rationale
The provided abstract and description present the algebraic relation P(z, G(z)) = 0 as an explicit modeling assumption chosen because it is 'more likely to hold in practice' for multi-bulk and atomic spectra. The central step is then a mathematical recasting of free decompression as evolution along the resulting spectral curve, which follows directly from algebraic curve theory once the assumption is granted. No equations or steps in the given text reduce a prediction to a fitted parameter by construction, import uniqueness via self-citation, or rename an empirical pattern as a first-principles result. The framework is therefore self-contained as a general method applicable to any spectra satisfying the stated algebraic condition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stieltjes transform of the spectral density satisfies an algebraic relation
Reference graph
Works this paper leans on
-
[1]
Ameli, S., van der Heide, C., Hodgkinson, L., & Mahoney, M. W. (2025a). Spectral estimation with free decompression. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[2]
Ameli, S., van der Heide, C., Hodgkinson, L., Roosta, F., & Mahoney, M. W. (2025b). Determinant estimation under memory constraints and neural scaling laws. InForty-second International Conference on Machine Learning
-
[3]
Anshelevich, M. (2008). Orthogonal polynomials with a resolvent-type generating function.Transactions of the American Mathematical Society, 360(8), 4125–4143
work page 2008
-
[4]
Benaych-Georges, F. (2005). Classical and free infinitely divisible distributions and random matrices. The Annals of Probability, 33(3), 1134 – 1170
work page 2005
-
[5]
Bercovici, H. & Voiculescu, D. (1993). Free convolution of measures with unbounded support.Indiana University Mathematics Journal, 42(3), 733–773
work page 1993
-
[6]
Biroli, G., Bonnaire, T., de Bortoli, V., & Mézard, M. (2024). Dynamical regimes of diffusion models. Nature Communications, 15(1), 9957
work page 2024
-
[7]
Blaizot, J.-P., Grela, J., Nowak, M., & Warchoł, P. (2015). Diffusion in the space of complex Hermi- tian matrices: microscopic properties of the averaged characteristic polynomial and the averaged inverse characteristic polynomial.Acta Physica Polonica. B, 46(9), 1801–1823
work page 2015
-
[8]
Blaizot, J.-P. & Nowak, M. A. (2010). Universal shocks in random matrix theory.Phys. Rev. E, 82, 051115
work page 2010
-
[9]
Blaizot, J.-P., Nowak, M. A., & Warchoł, P. (2013). Universal shocks in the Wishart random-matrix ensemble.Phys. Rev. E, 87, 052134
work page 2013
-
[10]
Bonnaire, T., Urfin, R., Biroli, G., & Mezard, M. (2025). Why diffusion models don’t memorize: The role of implicit dynamical regularization in training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
work page 2025
-
[11]
Burda, Z., Janik, R. A., Jurkiewicz, J., Nowak, M. A., Papp, G., & Zahed, I. (2002). Free random Lévy matrices.Phys. Rev. E, 65, 021106
work page 2002
-
[12]
Chen, J. & Olver, S. (2026). Computing inverses of Stieltjes transforms of probability measures. Mathematics of Computation
work page 2026
- [13]
-
[14]
El Karoui, N. (2010). The spectrum of kernel random matrices.The Annals of Statistics, 38(1), 1 – 50
work page 2010
-
[15]
Erdős, L., Krüger, T., & Schröder, D. (2020). Cusp universality for random matrices I: Local law and the complex Hermitian case.Communications in Mathematical Physics, 378(2), 1203–1278
work page 2020
-
[16]
George, A. J., Veiga, R., & Macris, N. (2025). Denoising score matching with random features: Insights on diffusion models from precise learning curves
work page 2025
-
[17]
Gibbs, A. L. & Su, F. E. (2002). On choosing and bounding probability metrics.International statistical review, 70(3), 419–435
work page 2002
-
[18]
Guionnet, A. (2009). Large random matrices: lectures on macroscopic asymptotics
work page 2009
-
[19]
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition(pp. 770–778). 11
work page 2016
-
[20]
Hodgkinson, L., Wang, Z., & Mahoney, M. W. (2025). Models of heavy-tailed mechanistic universality. In A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, & J. Zhu (Eds.),Proceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research(pp. 23290–23329).: PMLR
work page 2025
-
[21]
(2013).An introduction to statistical learning: with applications in R, volume 103
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013).An introduction to statistical learning: with applications in R, volume 103. Springer
work page 2013
-
[22]
Kesten, H. (1959). Symmetric random walks on groups.Transactions of the American Mathematical Society, 92(2), 336–354
work page 1959
-
[23]
(2009).Learning Multiple Layers of Features from Tiny Images
Krizhevsky, A. (2009).Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto
work page 2009
-
[24]
Liao, Z., Couillet, R., & Mahoney, M. W. (2021). A random matrix analysis of random Fourier features: beyond the Gaussian kernel, a precise phase transition, and the corresponding double descent.Journal of Statistical Mechanics: Theory and Experiment, 2021(12), 124006
work page 2021
-
[25]
Martin, C. H. & Mahoney, M. W. (2021). Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165), 1–73
work page 2021
-
[26]
Marčenko, V. A. & Pastur, L. A. (1967). Distribution of eigenvalues for some sets of random matrices. Mathematics of the USSR-Sbornik, 1(4), 457
work page 1967
-
[27]
McKay, B. D. (1981). The expected eigenvalue distribution of a large regular graph.Linear Algebra and its Applications, 40, 203–216
work page 1981
-
[28]
Meixner, J. (1934). Orthogonale polynomsysteme mit einer besonderen gestalt der erzeugenden funktion. Journal of The London Mathematical Society-second Series, (pp. 6–13)
work page 1934
-
[29]
Muskhelishvili, N. (1992).Singular Integral Equations: Boundary Problems of Function Theory and Their Application to Mathematical Physics. Dover Books on Mathematics Series. Dover Publications
work page 1992
-
[30]
Nica, A. & Speicher, R. (1996). On the multiplication of free N-tuples of noncommutative random variables.Amer. J. Math., 118(4), 799––837
work page 1996
-
[31]
Nica, A. & Speicher, R. (2006).Lectures on the Combinatorics of Free Probability. London Mathemat- ical Society Lecture Note Series. Cambridge University Press
work page 2006
-
[32]
Olver, F. W. J., Olde Daalhuis, A. B., Lozier, D. W., Schneider, B. I., Boisvert, R. F., Clark, C. W., Miller, B. R., Saunders, B. V., Cohl, H. S., & McClain, M. A. (Accessed 3 May 2026). NIST Digital Library of Mathematical Functions.https://dlmf.nist.gov/
work page 2026
-
[33]
Olver, S. & Nadakuditi, R. R. (2012). Numerical computation of convolutions in free probability theory. arXiv preprint arXiv:1203.1958
work page internal anchor Pith review arXiv 2012
-
[34]
Panaretos, V. M. & Zemel, Y. (2019). Statistical aspects of Wasserstein distances.Annual Review of Statistics and its Application, 6(1), 405–431
work page 2019
-
[35]
Pastur, L. & Shcherbina, M. (2011).Eigenvalue Distribution of Large Random Matrices. Mathematical surveys and monographs. American Mathematical Society
work page 2011
-
[36]
Pennington, J. & Bahri, Y. (2017). Geometry of neural network loss surfaces via random matrix theory. In D. Precup & Y. W. Teh (Eds.),Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research(pp. 2798–2806).: PMLR
work page 2017
-
[37]
Pennington, J., Schoenholz, S., & Ganguli, S. (2018). The emergence of spectral universality in deep networks. In A. Storkey & F. Perez-Cruz (Eds.),Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 ofProceedings of Machine Learning Research (pp. 1924–1932).: PMLR. 12
work page 2018
-
[38]
Pennington, J. & Worah, P. (2017). Nonlinear random matrix theory for deep learning. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.),Advances in Neural Information Processing Systems, volume 30: Curran Associates, Inc
work page 2017
-
[39]
Rao, N. R. & Edelman, A. (2008). The polynomial method for random matrices.Foundations of Computational Mathematics, 8(6), 649–702
work page 2008
-
[40]
Rudelson, M. & Vershynin, R. (2009). Smallest singular value of a random rectangular matrix.Com- munications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 62(12), 1707–1739
work page 2009
-
[41]
Saitoh, N. & Yoshida, H. (2001). The infinite divisibility and orthogonal polynomials with a constant recursion formula in free probability theory.Probab. Math. Statist., 21, 159–170
work page 2001
-
[42]
Senouf, D., Caflisch, R., & Ercolani, N. (1996). Pole dynamics and oscillations for the complex Burgers equation in the small-dispersion limit.Nonlinearity, 9(6), 1671
work page 1996
- [43]
-
[44]
Speicher, R. (2015). Free probability theory. InThe Oxford Handbook of Random Matrix Theory. Oxford University Press
work page 2015
-
[45]
Stein, E. M. & Shakarchi, R. (2003).Fourier Analysis: An Introduction, volume 1 ofPrinceton Lectures in Analysis. Princeton, NJ: Princeton University Press
work page 2003
-
[46]
(2002).Solving Systems of Polynomial Equations
Sturmfels, B. (2002).Solving Systems of Polynomial Equations. Conference Board of the Mathematical Sciences Regional Confe. Conference Board of the Mathematical Sciences
work page 2002
-
[47]
Trefethen, L. N. (2019).Approximation Theory and Approximation Practice. Philadelphia, PA: Society for Industrial and Applied Mathematics, extended edition edition
work page 2019
-
[48]
Trefethen, L. N. (2023). Numerical analytic continuation.Japan Journal of Industrial and Applied Mathematics, 40(3), 1587–1636
work page 2023
-
[49]
Ventura, E., Achilli, B., Silvestri, G., Lucibello, C., & Ambrogioni, L. (2025). Manifolds, random matrices and spectral gaps: The geometric phases of generative diffusion. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[50]
Voiculescu, D. (1991). Limit laws for random matrices and free products.Inventiones mathematicae, 104(1), 201–220
work page 1991
-
[51]
Wachter, K. W. (1978). The strong limits of random matrix spectra for sample matrices of independent elements.The Annals of Probability, 6(1), 1–18
work page 1978
-
[52]
(2012).Visual Complex Functions: An Introduction with Phase Portraits
Wegert, E. (2012).Visual Complex Functions: An Introduction with Phase Portraits. Mathematics and Statistics. Springer Basel
work page 2012
-
[53]
Wei, A., Hu, W., & Steinhardt, J. (2022). More than a toy: Random matrix models predict how real-world neural representations generalize. InInternational Conference on Machine Learning(pp. 23549–23588).: PMLR
work page 2022
-
[54]
Wigner, E. P. (1955). Characteristic vectors of bordered matrices with infinite dimensions.Annals of Mathematics, 62(3), 548–564. 13 Appendices Contents A Notation and Conventions 14 B Background 16 B.1 Stieltjes Transform and Boundary Values . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 B.2 Analytic Continuation Beyond the Physical Branch ...
work page 1955
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.