Safe and Sharp Honest Inference for Nonparametric Estimation via Empirical Bernstein Calibration
Pith reviewed 2026-07-01 00:08 UTC · model grok-4.3
The pith
Empirical Bernstein calibration produces nonparametric confidence intervals that maintain nominal coverage uniformly over smooth functions while shrinking at the minimax rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
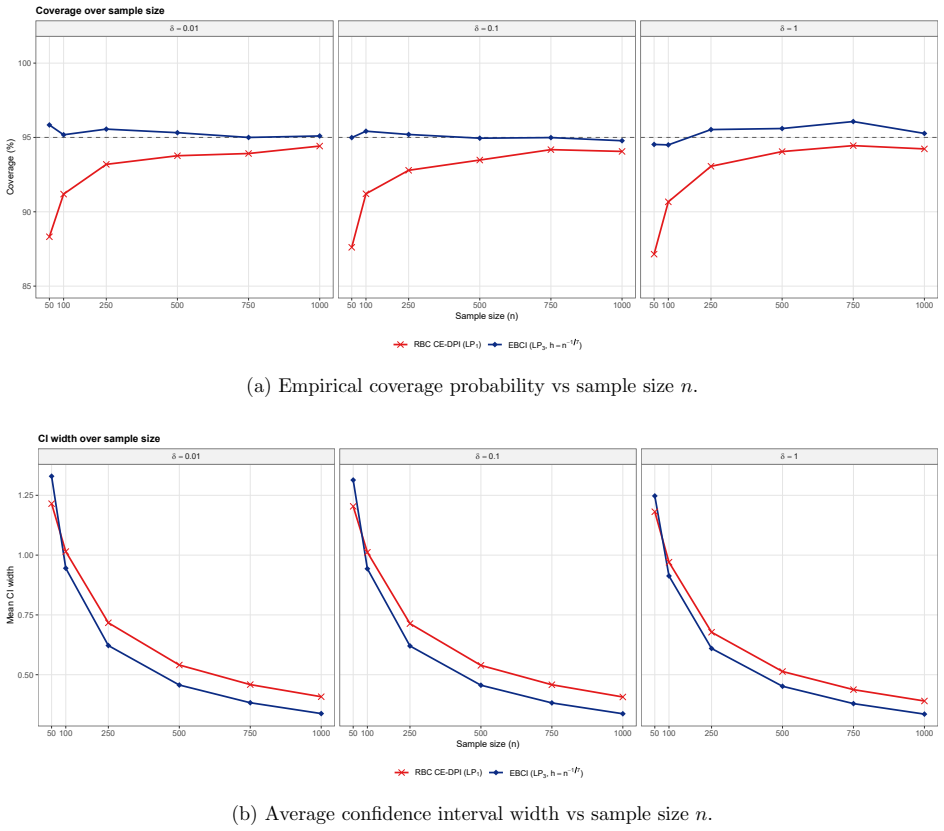
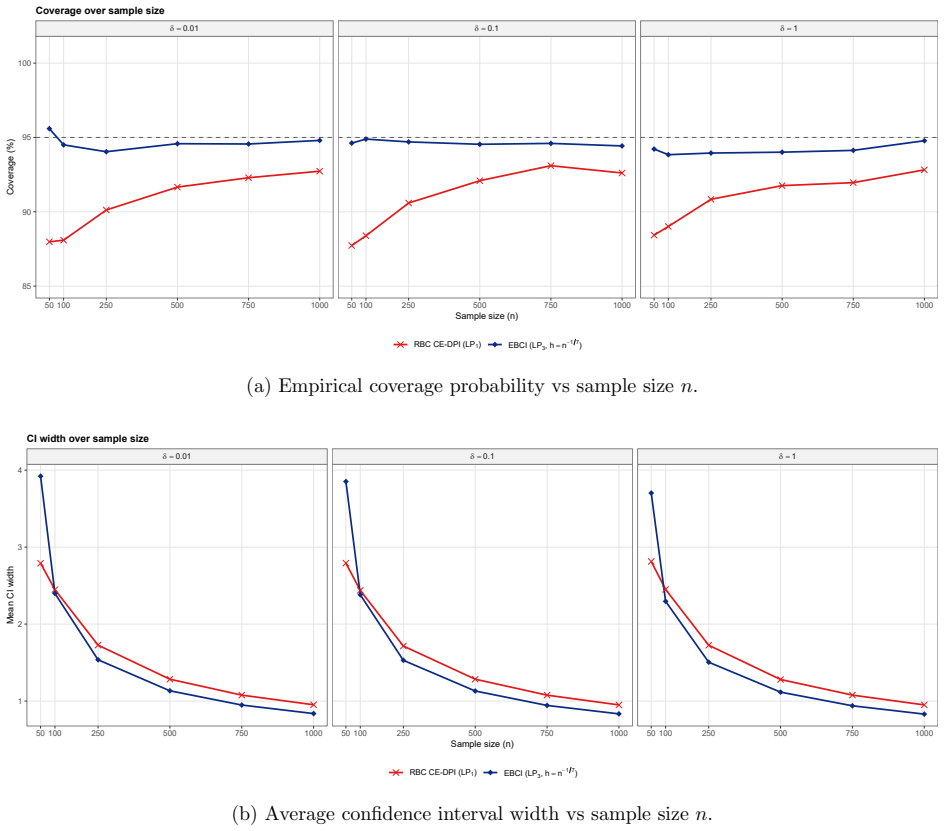
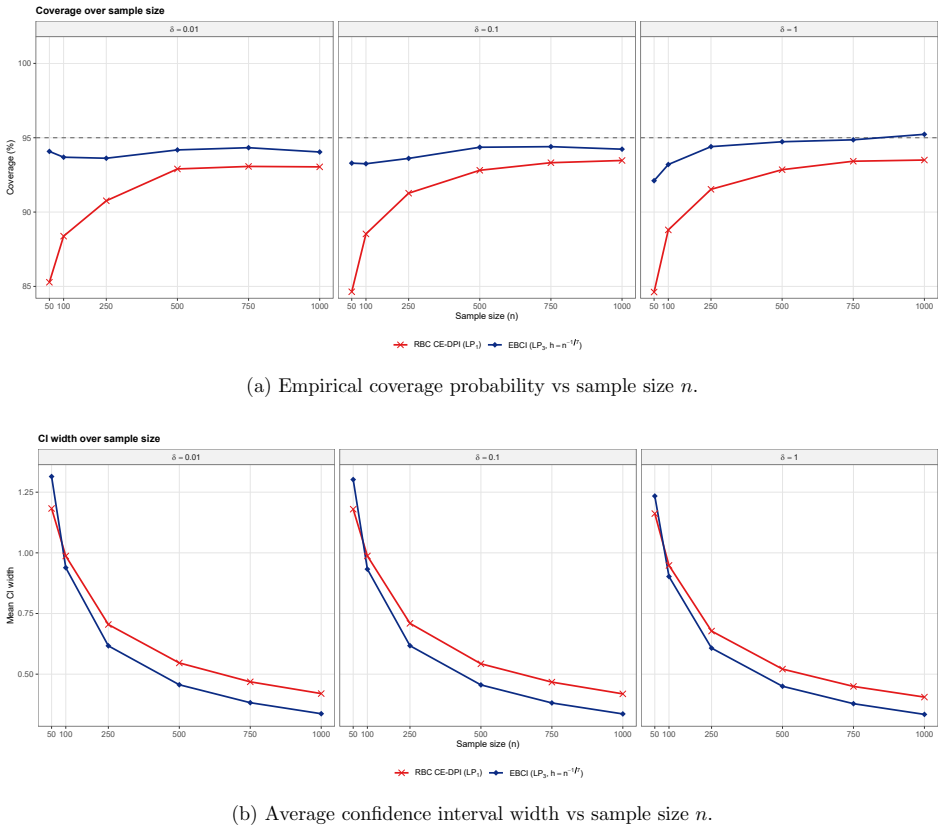
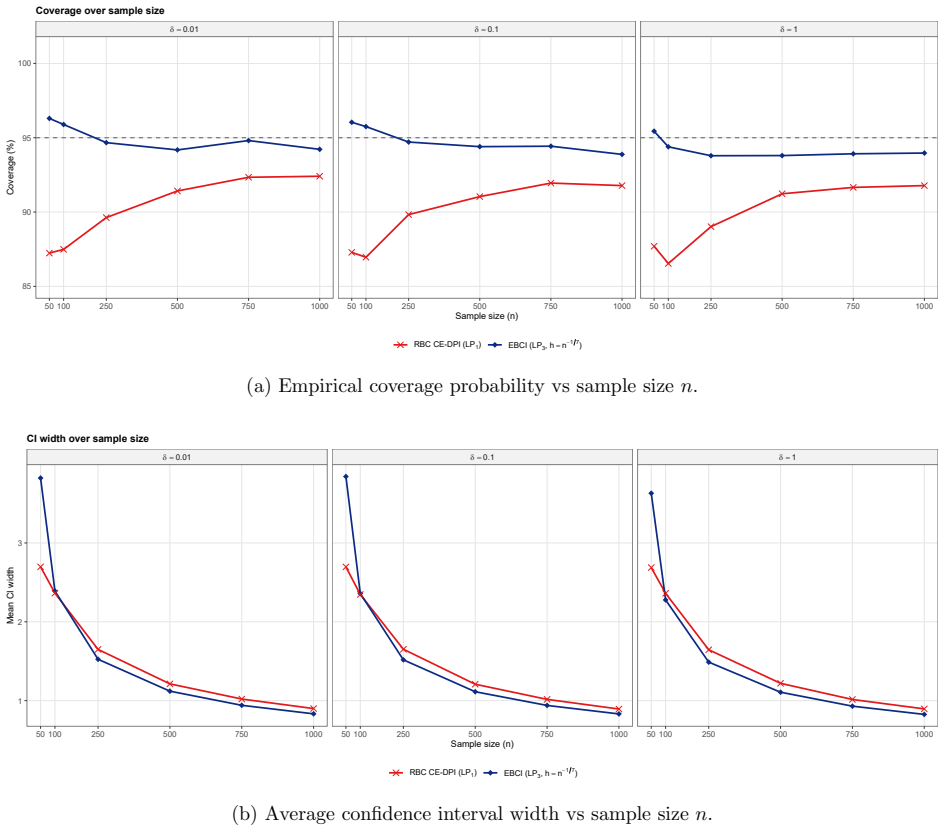
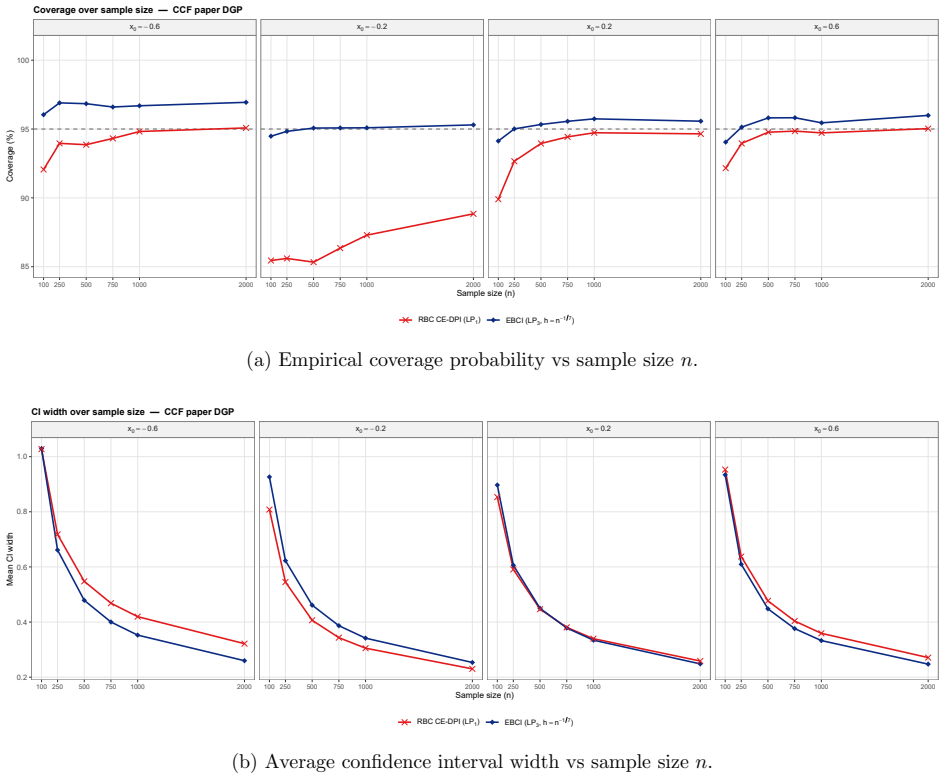
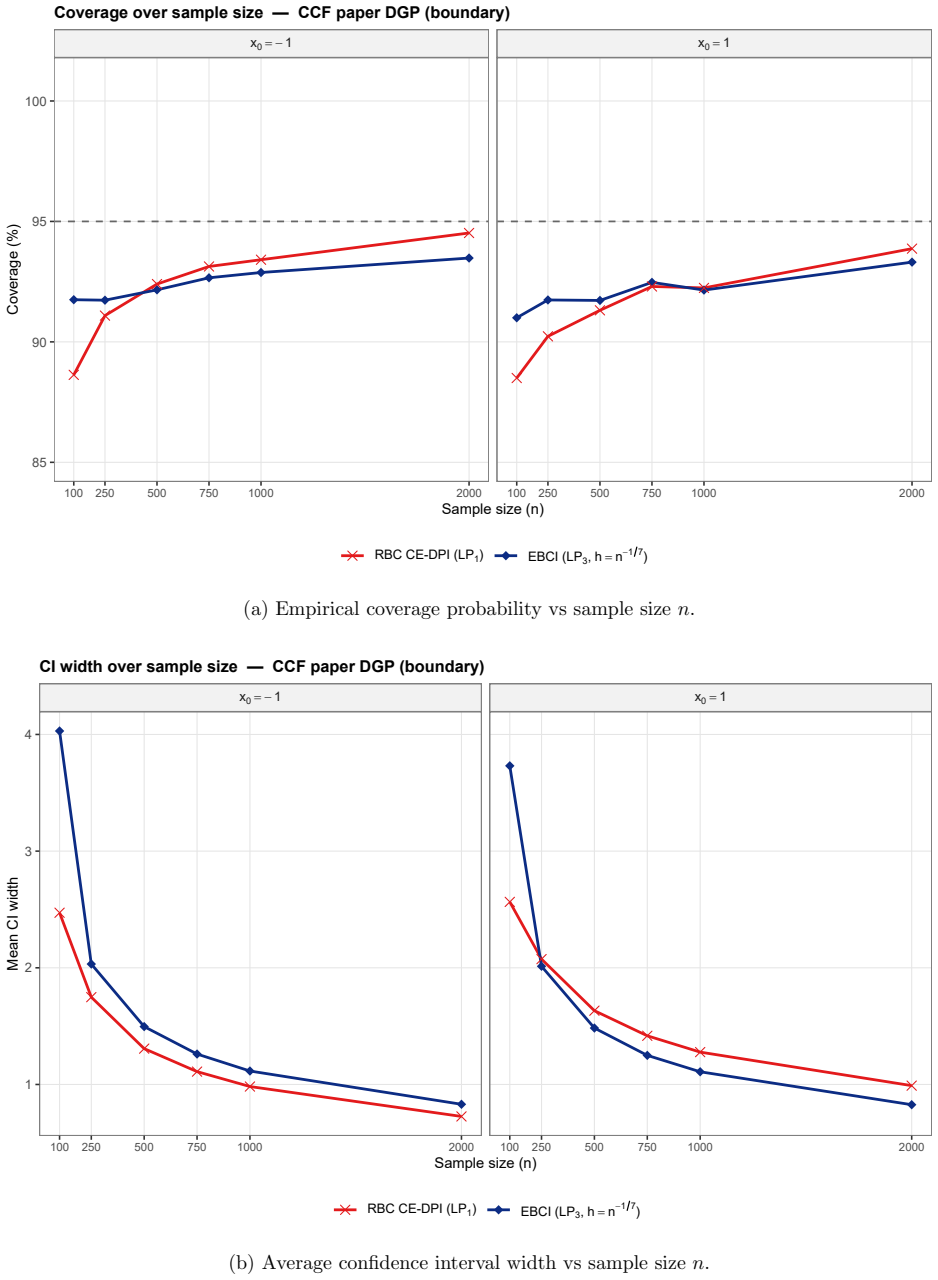
The resulting empirical Bernstein confidence intervals (EBCIs) are safe and sharp: uniformly over functions with some S-th order local smoothness, both one-sided and two-sided intervals attain the nominal coverage level up to a remainder o(n^{-2S/(2S+1)}), or an exponential remainder in bounded or sub-Gaussian settings, while interval widths shrink at the minimax rate n^{-S/(2S+1)}.
What carries the argument
Empirical Bernstein calibration, which converts empirical Bernstein tail bounds into interval radii via fixed-length optimization drawn from bias-aware inference.
If this is right
- EBCIs can be layered on top of existing bias-aware or robust bias-correction procedures without altering their bias-handling steps.
- In the small-alpha regime the EBCI radius matches the first-order behavior of bias-aware fixed-length intervals.
- The method sidesteps the inferential bias that standard-normal calibration introduces when a small estimation bias is normalized.
- Coverage accuracy and length efficiency are obtained simultaneously once local smoothness order is correctly specified.
Where Pith is reading between the lines
- The same calibration principle could be tested in multivariate or functional data settings where similar smoothness assumptions apply.
- Practitioners using local-polynomial smoothers might replace default normal-based intervals with EBCIs to reduce under-coverage in moderate samples.
- Extensions to other tail bounds or to adaptive smoothness selection remain open but would follow the same radius-optimization logic.
Load-bearing premise
The formal coverage and rate results are proved only for scalar-covariate regression and density estimation using local-polynomial or weighted-average estimators under S-th order local smoothness and bounded or sub-Gaussian tails.
What would settle it
A Monte Carlo experiment in which, for a sequence of sample sizes and a fixed smooth target function, the empirical coverage of the proposed intervals falls short of the nominal level by an amount larger than the stated remainder term.
Figures
read the original abstract
Calibration of an honest confidence interval means choosing, for each $\alpha\in(0,1)$, how the corresponding $\alpha$-critical value is converted into a radius yielding coverage probability at least $1-\alpha$. Standard-normal critical-value calibration (SNC) is the default route for many confidence intervals based on nonparametric smoothers in nonparametric econometrics. However, this calibration method creates a structural difficulty: the normalization yielding a limiting distribution also makes a small estimation bias become a non-negligible inferential bias. We take a different calibration route by combining the tail control of empirical Bernstein inequalities with a fixed-length-radius optimization from bias-aware inference. We establish the formal theory in canonical scalar-covariate regression and density settings, with the regression theory ranging from local-polynomial to weighted-average estimators. The resulting empirical Bernstein confidence intervals (EBCIs) are "safe" and "sharp". Safety means that, uniformly over functions with some $S$-th order local smoothness, both one-sided and two-sided intervals attain the nominal coverage level up to a remainder $o(n^{-\frac{2S}{2S+1}})$, or an exponential remainder in bounded or sub-Gaussian settings. Sharpness means that interval widths shrink at the minimax rate $n^{-\frac{S}{2S+1}}$. Moreover, in the small-$\alpha$ regime, the EBCI radius is first-order aligned with the radii of bias-aware fixed-length confidence intervals. Thus, EBCI safely converts correctly specified smoothness into both coverage accuracy and interval-length efficiency. The contribution is not a new bias-control approach, but a new calibration principle for the radius of a confidence interval. The method can be combined with existing ideas such as bias-aware inference (BA) and robust bias correction (RBC), while avoiding the bias inflation induced by SNC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes empirical Bernstein confidence intervals (EBCIs) obtained by combining empirical Bernstein tail inequalities with fixed-length-radius optimization. In canonical scalar-covariate regression (local-polynomial and weighted-average estimators) and density estimation, the resulting one- and two-sided intervals are claimed to be safe (uniform coverage over S-smooth functions up to remainder o(n^{-2S/(2S+1)}) or exponential under bounded/sub-Gaussian tails) and sharp (widths attaining the minimax rate n^{-S/(2S+1)}). The method is positioned as an alternative calibration principle to standard-normal calibration (SNC), avoiding bias inflation while remaining compatible with bias-aware (BA) and robust bias-correction (RBC) approaches; first-order alignment with BA radii is asserted in the small-α regime.
Significance. If the stated uniform coverage and rate results hold, the work supplies a calibration route that converts correctly specified local smoothness into both honest coverage and minimax-optimal length without introducing new bias-control machinery. The explicit scoping to local-polynomial/weighted-average estimators under S-th order smoothness and the compatibility statements with existing methods are useful for nonparametric econometrics applications.
minor comments (3)
- [Abstract] The abstract states the coverage remainder as o(n^{-2S/(2S+1)}) but does not indicate whether the o(·) is uniform in the function class or depends on additional constants; a clarifying sentence in §1 or the statement of the main theorem would help.
- [§2] Notation for the local-polynomial order and the precise definition of the weighted-average estimator should be introduced once in §2 before being used in the coverage theorems.
- [§4] The paper claims first-order alignment with bias-aware radii in the small-α regime; an explicit asymptotic expansion (perhaps in an appendix) would make this comparison sharper.
Simulated Author's Rebuttal
We thank the referee for the careful summary of the manuscript, the positive assessment of its significance, and the recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper's central contribution is a new calibration principle that combines empirical Bernstein tail bounds with fixed-length-radius optimization drawn from existing bias-aware inference. The safety and sharpness claims are derived from this combination under explicitly scoped assumptions (scalar covariate, local-polynomial or weighted-average estimators, S-th order smoothness, bounded/sub-Gaussian tails). No step reduces the coverage or rate result to a fitted parameter or to a self-citation chain; the derivation remains independent of the target quantities and does not rename or smuggle in prior results by construction. Minor self-citation of bias-aware methods is present but not load-bearing for the calibration novelty.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The target function has S-th order local smoothness
- domain assumption Observations are bounded or sub-Gaussian
Reference graph
Works this paper leans on
-
[1]
(High Dimensional Problems in Econometrics) doi: https://doi.org/10.1016/j.jeconom .2015.02.014 Calonico, S., Cattaneo, M. D., & Farrell, M. H. (2018). On the effect of bias estimation on coverage accuracy in nonparametric inference.Journal of the American Statistical Association, 113(522), 767–779. Calonico, S., Cattaneo, M. D., & Farrell, M. H. (2019). ...
-
[2]
Moreover, by letting l′ S(u) =K(u)e ⊤ 0 (Γ′ 1)−1r(u), for allϵ >0such thatϵ+L f(S+ 1)h≤ 1 2 fX(0)λmin(Γ′ 1), we have P max 1≤i≤n Wih(0)− 1 nhfX(0) l′ S( Xi h ) ≤ 2 √ S+ 1 nhf 2 X(0)λmin(Γ′ 1)(Lf h+ϵ) ≥1−2(S+ 1) exp − nhϵ2 3fX(0)(S+ 1) 2 + 8 3(S+ 1)ϵ ! .(A.45) Lemma A.5Based on the conditions and notations introduced in Lemma A.3 and the assumption thatΓ 1...
-
[3]
Moreover, according to theE ′ min andE ′ max defined in Corollary A.2, we further have moment inequality E h nX i=1 W 2 ih(0)1[E ′ min ∩ E ′ max] i ≤ 6λmax(Γ′ 2) nhfX(0)λ2 min(Γ′
-
[4]
Lemma A.8Suppose Assumptions 1-3 hold
(A.49) Lemma A.6Based on the conditions and notations introduced in Lemma A.4, there exists con- stantsc 5, c6, c7 >0independent ofnandhsuch that the following inequality holds for alln≥1, 41 h < H 0, and0< ϵ < ϵ 0, whereϵ 0 := min n 1−h, 1 2 fX(0)λmin(Γ1)−L f(S+ 1)h o , P nh nX i=1 W 2 ih(0)V(X i)− V(0) fX(0) Z 1 −1 l2 S(u)du > c5h+ϵ ≤exp − f 2 X(0)nh 8 ...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.