Adapt or Forget: Provable Tradeoffs Between Adam and SGD in Nonstationary Optimization
Pith reviewed 2026-05-08 17:16 UTC · model grok-4.3
The pith
Adam and SGD exhibit a noise-drift tradeoff in nonstationary optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
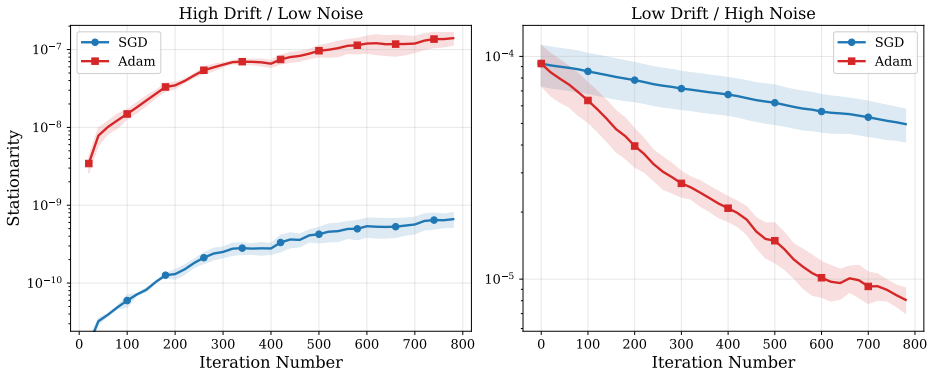
We derive finite-time expected and high-probability bounds for Adam that decompose sharply into four components: initialization, objective drift, a first-moment tracking error governed by β1, and a preconditioner perturbation governed by β2. These bounds characterize the burn-in time to reach Adam's irreducible tracking floor under constant and step-decay schedules. Across both the tracking analysis under adaptive strong monotonicity and the high-probability stationarity analysis under L-smoothness, the bounds reveal a noise-drift tradeoff: in noise-dominated regimes first-moment averaging and adaptive preconditioning can improve the high-probability error, whereas in drift-dominated regimes
What carries the argument
The four-component decomposition of tracking error into initialization, objective drift, β1-governed first-moment error, and β2-governed preconditioner perturbation, which exposes when Adam's adaptivity reduces or increases error relative to SGD.
Load-bearing premise
The derived bounds and tradeoff require that the problem satisfies either adaptive strong monotonicity of the Adam-preconditioned mean-gradient operator or general L-smoothness.
What would settle it
An experiment in which the relative tracking error between Adam and SGD fails to reverse as predicted when the ratio of noise variance to drift rate is varied across the threshold set by β1 and β2.
Figures










read the original abstract
We provide a theoretical analysis of Adam under non-stationary stochastic objectives, separating two regimes: Euclidean tracking under adaptive strong monotonicity of the Adam-preconditioned mean-gradient operator, and high-probability projected stationarity guarantees under general $L$-smooth objectives. In the tracking regime, we derive finite-time expected and high-probability bounds that decompose sharply into four components: initialization, objective drift, a first-moment tracking error governed by $\beta_1$, and a preconditioner perturbation governed by $\beta_2$. We characterize the burn-in time to reach Adam's irreducible tracking floor under constant and step-decay schedules. We also prove a high-probability bound on the average projected stationarity gap for Adam under distribution shift. Across both analyses, our bounds reveal a noise--drift tradeoff: in noise-dominated regimes, first-moment averaging and adaptive preconditioning can improve the high-probability error, whereas in drift-dominated regimes, stale first-moment information and preconditioner perturbations can compound the cost of nonstationarity, allowing vanilla SGD to achieve a smaller tracking floor. Our explicit $(\beta_1,\beta_2,\epsilon)$-dependent bounds delineate when adaptive step-sizing is beneficial versus harmful, and provide a theoretical mechanism for Adam's empirical instability and stabilization under distribution shift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides a theoretical analysis of the Adam optimizer for non-stationary stochastic objectives. It separates the analysis into an Euclidean tracking regime under adaptive strong monotonicity of the Adam-preconditioned mean-gradient operator and a high-probability projected stationarity regime under general L-smoothness. Finite-time expected and high-probability bounds are derived that decompose the tracking error into initialization, objective drift, a β1-governed first-moment tracking error, and a β2-governed preconditioner perturbation. The work characterizes burn-in times under constant and step-decay schedules and identifies a noise-drift tradeoff: Adam can improve high-probability error in noise-dominated regimes while SGD can achieve a smaller tracking floor in drift-dominated regimes due to stale moments and preconditioner perturbations. Explicit (β1, β2, ε)-dependent bounds are used to delineate when adaptive step-sizing is beneficial.
Significance. If the finite-time bounds hold under the stated assumptions, the paper supplies a concrete mechanism explaining Adam's empirical instability and stabilization under distribution shift. The sharp decomposition and regime-dependent tradeoff offer practical guidance for choosing between Adam and SGD based on noise versus drift dominance, which is valuable for non-stationary ML settings such as online learning and continual training. The combination of expected and high-probability guarantees, together with explicit hyperparameter dependence, strengthens the result relative to prior qualitative discussions of adaptive methods in drifting environments.
major comments (2)
- [§3] §3 (Tracking regime): The central noise-drift tradeoff rests on the decomposition of the tracking error into four additive terms (initialization, drift, β1 first-moment error, β2 preconditioner). The high-probability bound requires that the adaptive strong monotonicity constant remains positive and uniform; if the preconditioner perturbation term can make the effective monotonicity constant arbitrarily small for certain β2 and ε choices, the contraction argument would fail to yield the claimed floor independent of initialization after burn-in.
- [§4] §4 (Stationarity regime): The high-probability projected stationarity gap bound under L-smoothness and distribution shift is stated to hold for Adam; however, the proof sketch must explicitly control the additional variance introduced by the adaptive preconditioner relative to SGD, because any looseness here would undermine the claim that the tradeoff is visible in the stationarity gap as well as the tracking floor.
minor comments (3)
- Notation for the adaptive strong monotonicity constant should be introduced once with a clear definition before its repeated use in the tracking bounds.
- The burn-in time expressions under step-decay schedules would benefit from an explicit comparison table against the constant-step case to highlight the improvement.
- A short remark on how the ε-stabilization term interacts with the drift term in the high-probability bound would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments on the proof structure in both regimes are helpful, and we address them point by point below with clarifications and planned revisions to improve transparency without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Tracking regime): The central noise-drift tradeoff rests on the decomposition of the tracking error into four additive terms (initialization, drift, β1 first-moment error, β2 preconditioner). The high-probability bound requires that the adaptive strong monotonicity constant remains positive and uniform; if the preconditioner perturbation term can make the effective monotonicity constant arbitrarily small for certain β2 and ε choices, the contraction argument would fail to yield the claimed floor independent of initialization after burn-in.
Authors: The adaptive strong monotonicity assumption is imposed directly on the preconditioned mean-gradient operator (Definition 3.1), so the contraction rate μ is taken as given and uniform by hypothesis; the β2-governed preconditioner perturbation enters only as an additive error in the tracking-error decomposition (Theorem 3.2 and its high-probability counterpart). Under the stated bounded-gradient and bounded-preconditioner assumptions, the perturbation cannot drive the effective monotonicity constant below μ/2 for the β2, ε ranges considered in the noise-drift tradeoff (see the auxiliary Lemma B.3 in the appendix). Nevertheless, to make this explicit, we will insert a short remark after Theorem 3.1 stating the sufficient condition on ε relative to μ and β2 that keeps the effective constant bounded away from zero, together with a one-paragraph sketch of the perturbation control. This is a partial revision. revision: partial
-
Referee: [§4] §4 (Stationarity regime): The high-probability projected stationarity gap bound under L-smoothness and distribution shift is stated to hold for Adam; however, the proof sketch must explicitly control the additional variance introduced by the adaptive preconditioner relative to SGD, because any looseness here would undermine the claim that the tradeoff is visible in the stationarity gap as well as the tracking floor.
Authors: We agree that an explicit variance comparison strengthens the presentation. In the proof of the high-probability stationarity bound (Theorem 4.1, Appendix C), the adaptive gradient is decomposed as the SGD term plus a multiplicative perturbation whose second-moment contribution is bounded using the L-smoothness assumption and the uniform upper bound on the second-moment estimator; a separate martingale concentration step then absorbs the extra variance into an additive O(ε + (1-β2)) term that appears in the final gap. This term is precisely what produces the noise-drift tradeoff in the stationarity regime. To address the request, we will expand the proof sketch in §4 to display this decomposition side-by-side with the corresponding SGD variance bound, making the additional control fully explicit. This will be incorporated as a revision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central results consist of finite-time expected and high-probability bounds for Adam under non-stationary objectives, derived from standard external assumptions (adaptive strong monotonicity of the preconditioned mean-gradient operator for the tracking regime; L-smoothness for stationarity). These bounds explicitly decompose into initialization, drift, β1-governed first-moment tracking error, and β2-governed preconditioner perturbation terms without any reduction to quantities defined via the paper's own fitted parameters, self-citations, or ansatzes. The noise-drift tradeoff is obtained directly from the (β1, β2, ε) dependence in the stated bounds rather than by construction from inputs. No load-bearing self-citation chains, uniqueness theorems imported from prior author work, or renaming of known results appear in the derivation structure.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Adaptive strong monotonicity of the Adam-preconditioned mean-gradient operator
- domain assumption L-smoothness of the objective
Reference graph
Works this paper leans on
-
[1]
Polyak, B. T. , title =. USSR Computational Mathematics and Mathematical Physics , volume =. 1964 , doi =
1964
-
[2]
Bernoulli , volume=
Asymptotic breakdown point analysis for a general class of minimum divergence estimators , author=. Bernoulli , volume=. 2026 , publisher=
2026
-
[3]
The Marginal Value of Momentum for Small Learning Rate
Runzhe Wang and Sadhika Malladi and Tianhao Wang and Kaifeng Lyu and Zhiyuan Li , booktitle=. The Marginal Value of Momentum for Small Learning Rate. 2024 , url=
2024
-
[4]
2025 , note=
Adaptive Memory Momentum via a Model-Based Framework for Deep Learning Optimization , author=. 2025 , note=
2025
-
[5]
YellowFin and the Art of Momentum Tuning , url =
Zhang, Jian and Mitliagkas, Ioannis , booktitle =. YellowFin and the Art of Momentum Tuning , url =
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
KOALA: A. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2022 , month=. doi:10.1609/aaai.v36i6.20599 , abstractNote=
-
[7]
2018 , note=
Kalman Gradient Descent: Adaptive Variance Reduction in Stochastic Optimization , author=. 2018 , note=
2018
-
[8]
The Extended
Yann Ollivier , year=. The Extended
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i12.17275 , abstractNote=
-
[10]
International Conference on Learning Representations , year=
Sharpness-aware Minimization for Efficiently Improving Generalization , author=. International Conference on Learning Representations , year=
-
[11]
Proceedings of the 35th International Conference on Machine Learning , pages =
Shampoo: Preconditioned Stochastic Tensor Optimization , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[12]
Kovachki and Andrew M
Nikola B. Kovachki and Andrew M. Stuart , title =. Journal of Machine Learning Research , year =
-
[13]
Demon: Improved Neural Network Training With Momentum Decay , year=
Chen, John and Wolfe, Cameron and Li, Zhao and Kyrillidis, Anastasios , booktitle=. Demon: Improved Neural Network Training With Momentum Decay , year=
-
[14]
2025 , url=
Tianjin Huang and Ziquan Zhu and Gaojie Jin and Lu Liu and Zhangyang Wang and Shiwei Liu , booktitle=. 2025 , url=
2025
-
[15]
2025 , note=
Muon is Scalable for LLM Training , author=. 2025 , note=
2025
-
[16]
Kakade , booktitle=
Nikhil Vyas and Depen Morwani and Rosie Zhao and Itai Shapira and David Brandfonbrener and Lucas Janson and Sham M. Kakade , booktitle=. 2025 , url=
2025
-
[17]
International Conference on Learning Representations , year=
AdaShift: Decorrelation and Convergence of Adaptive Learning Rate Methods , author=. International Conference on Learning Representations , year=
-
[18]
Bernstein, Jeremy and Wang, Yu-Xiang and Azizzadenesheli, Kamyar and Anandkumar, Animashree , booktitle =. sign. 2018 , editor =
2018
-
[19]
Sayed , title =
Kun Yuan and Bicheng Ying and Ali H. Sayed , title =. Journal of Machine Learning Research , year =
-
[20]
Proceedings of The 35th International Conference on Algorithmic Learning Theory , pages =
Provable Accelerated Convergence of Nesterov’s Momentum for Deep ReLU Neural Networks , author =. Proceedings of The 35th International Conference on Algorithmic Learning Theory , pages =. 2024 , editor =
2024
-
[21]
On the momentum term in gradient descent learning algorithms , journal =
Ning Qian , keywords =. On the momentum term in gradient descent learning algorithms , journal =. 1999 , issn =. doi:https://doi.org/10.1016/S0893-6080(98)00116-6 , url =
-
[22]
2023 , url=
Towards Stochastic Gradient Variance Reduction by Solving a Filtering Problem , author=. 2023 , url=
2023
-
[23]
2022 , url=
Towards understanding how momentum improves generalization in deep learning , author=. 2022 , url=
2022
-
[24]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Non-Stationary Learning of Neural Networks with Automatic Soft Parameter Reset , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[25]
Amortized
Zhou, Kaiwen and Jin, Yanghua and Ding, Qinghua and Cheng, James , booktitle =. Amortized. 2020 , editor =
2020
-
[26]
International Conference on Learning Representations , year=
Aggregated Momentum: Stability Through Passive Damping , author=. International Conference on Learning Representations , year=
-
[27]
Yinan Shen and Yichen Zhang and Wen-Xin Zhou , year=
-
[28]
Computational Intelligence and Neuroscience , year =
Yang, Haimin and Pan, Zhisong and Tao, Qing , title =. Computational Intelligence and Neuroscience , year =. doi:10.1155/2017/9478952 , url =
-
[29]
Journal of Machine Learning Research , year =
Joshua Cutler and Dmitriy Drusvyatskiy and Zaid Harchaoui , title =. Journal of Machine Learning Research , year =
-
[30]
Journal of Machine Learning Research , year =
Peng Zhao and Yu-Jie Zhang and Lijun Zhang and Zhi-Hua Zhou , title =. Journal of Machine Learning Research , year =
-
[31]
Vincent , booktitle=
Cao, Xuanyu and Zhang, Junshan and Poor, H. Vincent , booktitle=. On the Time-Varying Distributions of Online Stochastic Optimization , year=
-
[32]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
Exploring the Inefficiency of Heavy Ball as Momentum Parameter Approaches 1 , author =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,. 2024 , month =. doi:10.24963/ijcai.2024/431 , url =
-
[33]
Momentum Centering and Asynchronous Update for Adaptive Gradient Methods , url =
Zhuang, Juntang and Ding, Yifan and Tang, Tommy and Dvornek, Nicha and Tatikonda, Sekhar C and Duncan, James , booktitle =. Momentum Centering and Asynchronous Update for Adaptive Gradient Methods , url =
-
[34]
International Conference on Learning Representations , year=
Adaptive Gradient Methods with Dynamic Bound of Learning Rate , author=. International Conference on Learning Representations , year=
-
[35]
Wang and Masahito Ueda , year=
Liu Ziyin and Zhikang T. Wang and Masahito Ueda , year=. LaProp: Separating Momentum and Adaptivity in
-
[36]
Arnulf Jentzen and Julian Kranz and Adrian Riekert , year=
-
[37]
Adaptive Methods for Nonconvex Optimization , url =
Zaheer, Manzil and Reddi, Sashank and Sachan, Devendra and Kale, Satyen and Kumar, Sanjiv , booktitle =. Adaptive Methods for Nonconvex Optimization , url =
-
[38]
2023 , note=
Gradient Norm Aware Minimization Seeks First-Order Flatness and Improves Generalization , author=. 2023 , note=
2023
-
[39]
International Conference on Learning Representations , year=
On the Variance of the Adaptive Learning Rate and Beyond , author=. International Conference on Learning Representations , year=
-
[40]
Robust Stochastic Gradient Descent With
Ilboudo, Wendyam Eric Lionel and Kobayashi, Taisuke and Sugimoto, Kenji , journal=. Robust Stochastic Gradient Descent With. 2022 , volume=
2022
-
[41]
Proceedings of the 30th International Conference on Machine Learning , pages =
On the importance of initialization and momentum in deep learning , author =. Proceedings of the 30th International Conference on Machine Learning , pages =. 2013 , editor =
2013
-
[42]
Revisiting Distributed Synchronous
Jianmin Chen* and Xinghao Pan* and Rajat Monga and Samy Bengio and Rafal Jozefowicz , year=. Revisiting Distributed Synchronous
-
[43]
ICLR 2016 Workshop Track , year =
Dozat, Timothy , title =. ICLR 2016 Workshop Track , year =
2016
-
[44]
Journal of Machine Learning Research , year =
John Duchi and Elad Hazan and Yoram Singer , title =. Journal of Machine Learning Research , year =
-
[45]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[46]
2012 , note=
ADADELTA: An Adaptive Learning Rate Method , author=. 2012 , note=
2012
-
[47]
Signal Processing Meets
Zhipeng Yao and Rui Yu and Guisong Chang and Ying Li and Yu Zhang and Dazhou Li , year=. Signal Processing Meets
-
[48]
High-dimensional limit theorems for
Aukosh Jagannath and Taj Jones-McCormick and Varnan Sarangian , year=. High-dimensional limit theorems for
-
[49]
2025 , note=
Convergence of Momentum-Based Optimization Algorithms with Time-Varying Parameters , author=. 2025 , note=
2025
-
[50]
When and Why Momentum Accelerates
Jingwen Fu and Bohan Wang and Huishuai Zhang and Zhizheng Zhang and Wei Chen and Nanning Zheng , year=. When and Why Momentum Accelerates
-
[51]
2022 , note=
Adaptive Inertia: Disentangling the Effects of Adaptive Learning Rate and Momentum , author=. 2022 , note=
2022
-
[52]
Proceedings of Machine Learning and Systems (MLSys) , volume =
YellowFin and the Art of Momentum Tuning , author =. Proceedings of Machine Learning and Systems (MLSys) , volume =
-
[53]
2025 , note =
Adaptive Memory Momentum via a Model-Based Framework for Deep Learning Optimization , author =. 2025 , note =
2025
-
[54]
A Reliable Effective Terascale Linear Learning System , journal =
Alekh Agarwal and Oliveier Chapelle and Miroslav Dud. A Reliable Effective Terascale Linear Learning System , journal =. 2014 , volume =
2014
-
[55]
Non-Asymptotic Analysis of Stochastic Approximation Algorithms for Machine Learning , url =
Moulines, Eric and Bach, Francis , booktitle =. Non-Asymptotic Analysis of Stochastic Approximation Algorithms for Machine Learning , url =
-
[56]
The Tradeoffs of Large Scale Learning , url =
Bottou, L\'. The Tradeoffs of Large Scale Learning , url =. Advances in Neural Information Processing Systems , editor =
-
[57]
Using Statistics to Automate Stochastic Optimization , url =
Lang, Hunter and Xiao, Lin and Zhang, Pengchuan , booktitle =. Using Statistics to Automate Stochastic Optimization , url =
-
[58]
Warren B. Powell , keywords =. A unified framework for stochastic optimization , journal =. 2019 , issn =. doi:https://doi.org/10.1016/j.ejor.2018.07.014 , url =
-
[59]
Robust stochastic approximation approach to stochastic programming,
Nemirovski, A. and Juditsky, A. and Lan, G. and Shapiro, A. , title =. SIAM Journal on Optimization , volume =. 2009 , doi =. https://doi.org/10.1137/070704277 , abstract =
-
[60]
Journal of the American Statistical Association , author =
Xi Chen and Zehua Lai and He Li and Yichen Zhang , title =. Journal of the American Statistical Association , volume =. 2024 , publisher =. doi:10.1080/01621459.2023.2296703 , URL =
-
[61]
Advances in Neural Information Processing Systems , editor=
An Even More Optimal Stochastic Optimization Algorithm: Minibatching and Interpolation Learning , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[62]
Stochastic Optimization for Large-scale Optimal Transport , url =
Genevay, Aude and Cuturi, Marco and Peyr\'. Stochastic Optimization for Large-scale Optimal Transport , url =. Advances in Neural Information Processing Systems , editor =
-
[63]
Kushner, Harold J. and Yin, G. George. Applications: Proofs of Convergence. Stochastic Approximation Algorithms and Applications. 1997. doi:10.1007/978-1-4899-2696-8\_9
-
[64]
2003 , publisher=
Fundamentals of Adaptive Filtering , author=. 2003 , publisher=
2003
-
[65]
Hazan, Elad , title =. Foundations and Trends in Optimization , volume =. 2016 , month =. doi:10.1561/2400000013 , url =
-
[66]
Stochastic optimization under time drift: iterate averaging, step-decay schedules, and high probability guarantees , url =
Cutler, Joshua and Drusvyatskiy, Dmitriy and Harchaoui, Zaid , booktitle =. Stochastic optimization under time drift: iterate averaging, step-decay schedules, and high probability guarantees , url =
-
[67]
The Annals of Mathematical Statistics , number =
Herbert Robbins and Sutton Monro , title =. The Annals of Mathematical Statistics , number =. 1951 , doi =
1951
-
[68]
Proceedings of the Twenty-First International Conference on Machine Learning , pages =
Zhang, Tong , title =. Proceedings of the Twenty-First International Conference on Machine Learning , pages =. 2004 , isbn =. doi:10.1145/1015330.1015332 , abstract =
-
[69]
Convex Optimization for Big Data: Scalable, randomized, and parallel algorithms for big data analytics , year=
Cevher, Volkan and Becker, Stephen and Schmidt, Mark , journal=. Convex Optimization for Big Data: Scalable, randomized, and parallel algorithms for big data analytics , year=
-
[70]
Going deeper with convolutions , year=
Szegedy, Christian and Wei Liu and Yangqing Jia and Sermanet, Pierre and Reed, Scott and Anguelov, Dragomir and Erhan, Dumitru and Vanhoucke, Vincent and Rabinovich, Andrew , booktitle=. Going deeper with convolutions , year=
-
[71]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
2015
-
[72]
Gradient methods for the minimisation of functionals
B.T. Polyak , abstract =. Gradient methods for the minimisation of functionals , journal =. 1963 , issn =. doi:https://doi.org/10.1016/0041-5553(63)90382-3 , url =
-
[73]
A method for solving the convex programming problem with convergence rate o(1/k^2)
Nesterov, Y. A method for solving the convex programming problem with convergence rate o(1/k^2). Dokl Akad Nauk SSSR. 1983
1983
-
[74]
Applied Optimization , year=
Introductory Lectures on Convex Optimization - A Basic Course , author=. Applied Optimization , year=
-
[75]
2024 , url=
Role of Momentum in Smoothing Objective Function and Generalizability of Deep Neural Networks , author=. 2024 , url=
2024
-
[76]
Ramezani-Kebrya, Ali and Antonakopoulos, Kimon and Cevher, Volkan and Khisti, Ashish and Liang, Ben , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2024 , issue_date =
2024
-
[77]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Liu, Yanli and Gao, Yuan and Yin, Wotao , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[78]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Cutkosky, Ashok and Mehta, Harsh , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
2020
-
[79]
Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =
Aydore, Sergul and Zhu, Tianhao and Foster, Dean , title =. Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =. 2019 , publisher =
2019
-
[80]
Yulai Zhang and Yuchao Wang and Guiming Luo , keywords =. A new optimization algorithm for non-stationary time series prediction based on recurrent neural networks , journal =. 2020 , issn =. doi:https://doi.org/10.1016/j.future.2019.09.018 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.