Distilling Bayesian Belief States into Language Models for Auditable Negotiation
Pith reviewed 2026-05-08 17:04 UTC · model grok-4.3
The pith
Bayesian distillation into an 8B model lets negotiation agents output explicit, calibrated opponent beliefs that support auditing and outperform a 70B baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
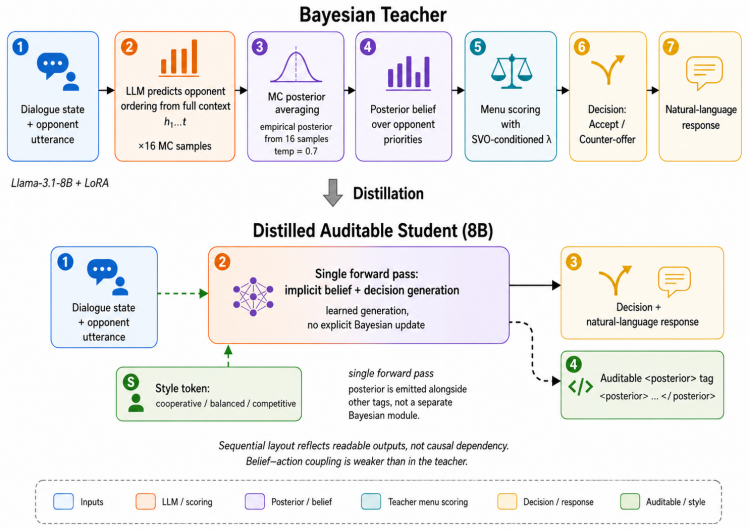
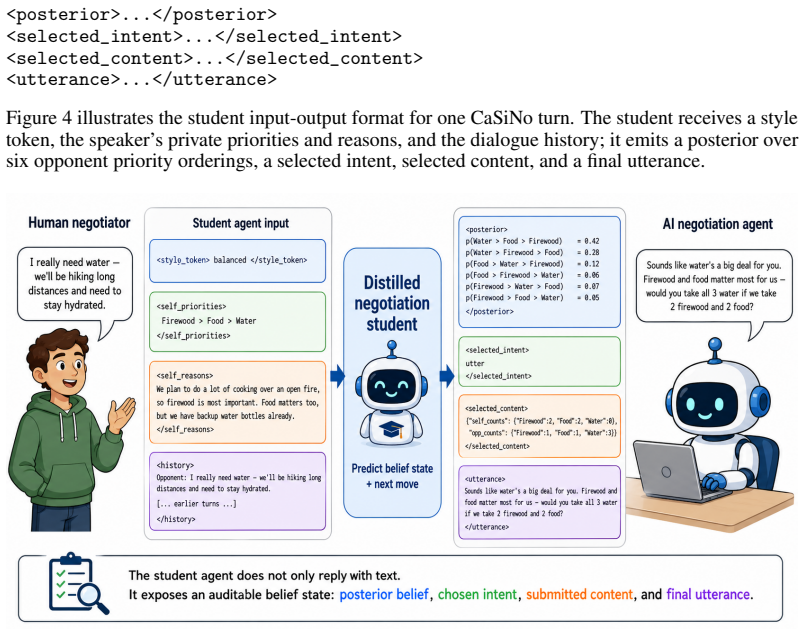
An LLM teacher that scores dialogue contexts against exactly six opponent priority orderings can produce accurate Bayesian posteriors for negotiation decisions, and these posteriors can be distilled into a compact 8B student language model that generates both actions and normalized belief reports as tagged text, yielding stronger posterior calibration than a much larger 70B baseline while exposing belief trajectories, belief-policy error splits, and the effects of belief interventions.
What carries the argument
The Bayesian teacher that updates a posterior over six discrete opponent priority orderings by scoring each context, together with the distillation that trains the student to emit those posteriors as normalized tagged text alongside its actions.
If this is right
- Explicit posteriors allow decomposition of negotiation errors into belief inaccuracy versus policy error.
- Posterior-prefix interventions make the causal link between reported beliefs and chosen actions directly testable.
- Posterior trajectories over dialogue turns become inspectable diagnostics rather than hidden internal states.
- Weak belief-action coupling is surfaced as a measurable phenomenon instead of remaining invisible inside end-to-end generation.
Where Pith is reading between the lines
- The same teacher-student structure could be tried in other interactive settings that require tracking a counterpart's private preferences, such as persuasion or multi-issue bargaining.
- If the six-ordering discretization proves adequate, similar low-cardinality discretizations might let explicit belief reporting scale to other uncertainty-heavy LLM tasks.
- The finding that a small model with structured output beats a larger unstructured model in calibration suggests that output format can sometimes substitute for raw scale when the goal is accurate uncertainty reporting.
- Hybrid agents that feed the student's explicit posteriors into conventional planners could combine language flexibility with formal verifiability.
Load-bearing premise
Opponent preferences can be represented by exactly six discrete priority orderings that an LLM teacher can score reliably enough from dialogue context to produce accurate Bayesian updates, and the student can emit those posteriors as normalized tagged text without substantial distortion.
What would settle it
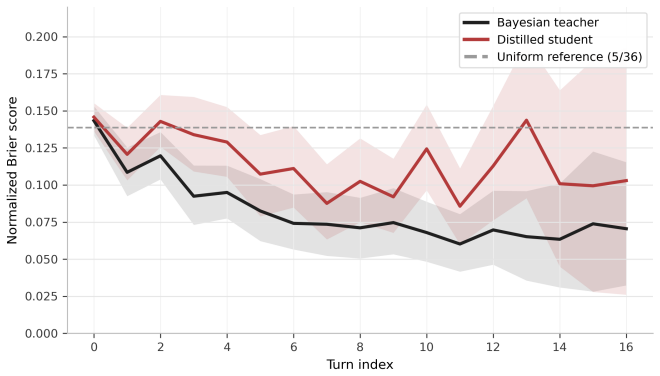
If the 8B student's elicited posteriors on held-out CaSiNo dialogues produce a mean Brier score above the uniform reference of approximately 0.139, or if posterior-prefix interventions fail to shift actions in the direction predicted by the reported beliefs, the claim that distillation preserves usable belief signal is falsified.
Figures

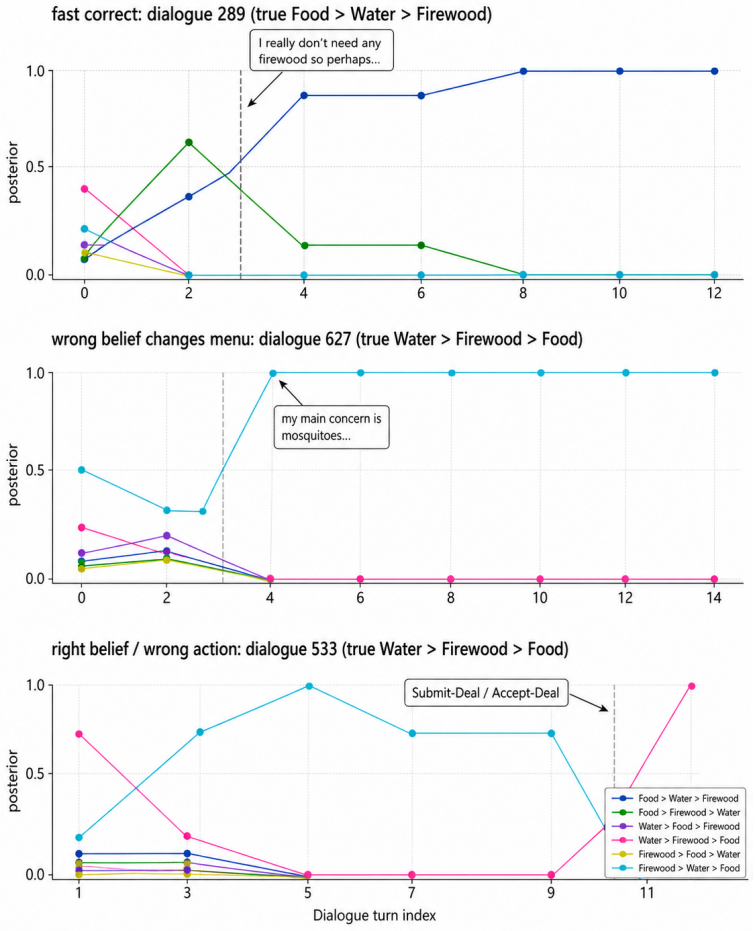
read the original abstract
Negotiation agents must infer what their counterpart values, update those beliefs over dialogue turns, and choose actions under uncertainty. End-to-end large language models (LLMs) can imitate negotiation dialogue, but their opponent beliefs are usually implicit and difficult to inspect. We propose BOND (Bayesian Opponent-belief Negotiation Distillation), a framework for auditable negotiation. BOND consists of an LLM-based Bayesian teacher that scores dialogue contexts against the six possible opponent priority orderings, updates a posterior over those orderings, and uses the posterior for menu-based decision making, as well as a smaller 8B student language model that emits both negotiation actions and normalized posterior beliefs as tagged text. In the CaSiNo negotiation dataset, BOND outperforms the state-of-the-art and achieves mean Brier score 0.085 over opponent-priority posteriors. The distilled student preserves much of this belief signal, achieving Brier 0.114, below the uniform six-ordering reference of 5/36, approximately 0.139. Compared with a 70B structured-CoT baseline, the significantly smaller 8B student model yields substantially better elicited posterior calibration. We further showcase auditability through posterior trajectories, belief-versus-policy error decomposition, and posterior-prefix interventions. These diagnostics reveal that distillation preserves a scoreable belief report more strongly than causal belief-conditioned control, making weak belief-action coupling visible, not hidden.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BOND, a teacher-student distillation framework for embedding explicit opponent-belief states into language models for negotiation. An LLM teacher scores dialogue contexts against six fixed priority orderings, computes posteriors over those orderings, and uses them for menu-based decisions; an 8B student model is trained to emit both negotiation actions and normalized posteriors as tagged text. On the CaSiNo dataset the teacher reports mean Brier score 0.085 over opponent-priority posteriors and the student 0.114 (below the uniform reference of ~0.139), outperforming a 70B structured-CoT baseline; additional diagnostics include posterior trajectories, belief-policy error decomposition, and prefix interventions.
Significance. If the teacher's scoring produces coherent posteriors and the distillation preserves calibration, the work supplies a concrete route to smaller, auditable negotiation agents whose internal beliefs can be inspected and intervened upon. The explicit tagged-text output format and the suite of belief-action diagnostics are genuine strengths that could be adopted more broadly in interpretable agent research.
major comments (2)
- [framework description / teacher model] Teacher model (framework description): the paper states that the LLM 'scores dialogue contexts against the six possible opponent priority orderings, updates a posterior' and treats the result as a Bayesian belief state. No explicit likelihood function P(context | ordering) or likelihood-ratio derivation is supplied; scores appear to be obtained via ad-hoc prompting (e.g., compatibility ratings) followed by normalization. Consequently the reported teacher Brier of 0.085 demonstrates concentration on the ground-truth ordering but does not establish that the distribution satisfies Bayesian updating. This directly affects the central claim that the student distills 'Bayesian Belief States'.
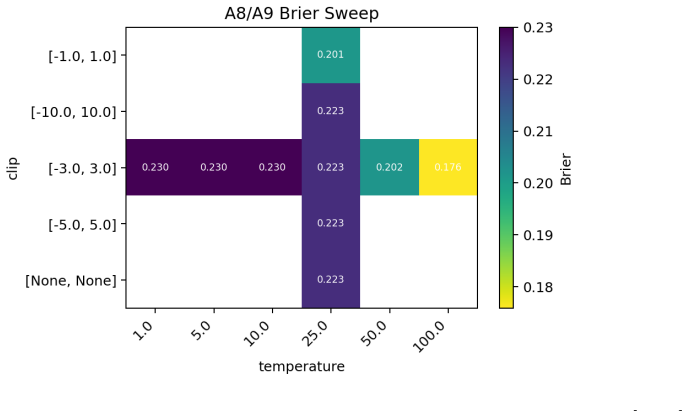
- [results / Brier score table] Experimental results (results section / Table reporting Brier scores): mean Brier scores are given without error bars, standard errors, or details of dialogue-level variance, data exclusion criteria, or statistical tests against the 70B baseline. With the modest size of the CaSiNo negotiation corpus, it is impossible to determine whether the student's 0.114 is reliably superior to the baseline or merely reflects imitation of the same heuristic scoring procedure.
minor comments (2)
- [abstract] Abstract: the uniform six-ordering Brier reference is stated as '5/36, approximately 0.139'. Provide the exact multi-class Brier formula used so readers can replicate the baseline value.
- [methods / appendix] Reproducibility: the exact prompts used for teacher scoring and for eliciting tagged posteriors from the student should be included in an appendix.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with specific plans for revision where appropriate, while defending the core contributions of the work.
read point-by-point responses
-
Referee: Teacher model (framework description): the paper states that the LLM 'scores dialogue contexts against the six possible opponent priority orderings, updates a posterior' and treats the result as a Bayesian belief state. No explicit likelihood function P(context | ordering) or likelihood-ratio derivation is supplied; scores appear to be obtained via ad-hoc prompting (e.g., compatibility ratings) followed by normalization. Consequently the reported teacher Brier of 0.085 demonstrates concentration on the ground-truth ordering but does not establish that the distribution satisfies Bayesian updating. This directly affects the central claim that the student distills 'Bayesian Belief States'.
Authors: We acknowledge that the teacher employs an approximate rather than fully specified Bayesian procedure. The LLM is prompted to produce compatibility ratings that serve as a proxy for the likelihood P(context | ordering); these ratings are then normalized across the six discrete hypotheses to yield a proper posterior. This approach is common in LLM-based inference where an explicit generative likelihood is intractable, and the resulting posteriors are validated by their low Brier score (0.085) against ground-truth orderings. The student then distills these normalized posteriors, preserving the auditable belief format. To address the concern directly, we will revise the framework section to explicitly label the update as 'approximate Bayesian' with the prompting procedure described as the likelihood proxy, and we will add a short discussion of its relation to standard Bayesian updating. This clarification strengthens rather than weakens the central claim of distilling inspectable belief states. revision: partial
-
Referee: Experimental results (results section / Table reporting Brier scores): mean Brier scores are given without error bars, standard errors, or details of dialogue-level variance, data exclusion criteria, or statistical tests against the 70B baseline. With the modest size of the CaSiNo negotiation corpus, it is impossible to determine whether the student's 0.114 is reliably superior to the baseline or merely reflects imitation of the same heuristic scoring procedure.
Authors: We agree that uncertainty quantification and statistical comparison are necessary given the finite size of CaSiNo. In the revised manuscript we will report per-dialogue standard errors and bootstrap 95% confidence intervals for all Brier scores. We will also add a paired non-parametric test (Wilcoxon signed-rank) comparing the 8B student posteriors against the 70B baseline on the same dialogues, together with the exact data-processing pipeline (no dialogues were excluded beyond the published CaSiNo train/test splits). These additions will allow readers to evaluate whether the observed improvement is reliable and not merely heuristic imitation. revision: yes
Circularity Check
No significant circularity in BOND derivation or evaluation chain
full rationale
The paper presents an empirical teacher-student distillation pipeline on the CaSiNo dataset. The LLM teacher produces posteriors over six fixed orderings via context scoring, the student is trained to emit matching normalized posteriors as text, and performance is measured by Brier score against ground-truth orderings. These steps follow standard supervised learning and calibration evaluation; no reported metric reduces by construction to a fitted parameter, no self-citation supplies a load-bearing uniqueness theorem or ansatz, and no equation equates a claimed prediction to its own input. The framework is therefore self-contained against external dataset benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The six possible opponent priority orderings form a sufficient discrete hypothesis space for Bayesian updating in negotiation dialogues
- domain assumption LLM-based scoring of dialogue contexts against orderings produces calibrated likelihoods for Bayesian inference
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages=
Deal or no deal? end-to-end learning of negotiation dialogues , author=. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2017
-
[2]
Advances in Neural Information Processing Systems , volume=
Cooperation, competition, and maliciousness: Llm-stakeholders interactive negotiation , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Casino: A corpus of campsite negotiation dialogues for automatic negotiation systems , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
work page 2021
-
[4]
Exploring the strategy space of negotiating agents: A framework for bidding, learning and accepting in automated negotiation , author=. 2016 , publisher=
work page 2016
- [5]
-
[6]
Findings of the Association for Computational Linguistics: NAACL 2022 , pages=
Opponent modeling in negotiation dialogues by related data adaptation , author=. Findings of the Association for Computational Linguistics: NAACL 2022 , pages=
work page 2022
-
[7]
arXiv preprint arXiv:2512.24885 , year=
BEDA: Belief Estimation as Probabilistic Constraints for Performing Strategic Dialogue Acts , author=. arXiv preprint arXiv:2512.24885 , year=
-
[8]
Judgment and Decision making , volume=
Measuring social value orientation , author=. Judgment and Decision making , volume=. 2011 , publisher=
work page 2011
-
[9]
Multi-issue bargaining with deep reinforcement learning.arXiv preprint arXiv:2002.07788,
Multi-issue bargaining with deep reinforcement learning , author=. arXiv preprint arXiv:2002.07788 , year=
-
[10]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
ACE: A LLM-based negotiation coaching system , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
work page 2024
- [11]
- [12]
-
[13]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.