3D Ultrasound-Derived Pseudo-CT Synthesis Using a Transformer-Augmented Residual Network for Real-Time Operator Guidance
Pith reviewed 2026-05-08 16:34 UTC · model grok-4.3
The pith
A transformer-augmented residual network generates CT-like volumes from 3D ultrasound to guide operators without radiation exposure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Bottleneck Transformer Residual U-Net3D (BT-ResUNet3D) produces pseudo-CT volumes from 3D ultrasound that achieve higher structural fidelity and perceptual quality than established baselines, as measured by PSNR and SSIM on paired kidney data from the TRUSTED dataset after landmark-based multimodal registration.
What carries the argument
The BT-ResUNet3D generator, a 3D residual U-Net encoder-decoder with a transformer inserted at the bottleneck to capture both local anatomy and long-range volumetric dependencies, trained adversarially against a 3D Conditional PatchGAN discriminator.
If this is right
- The synthesized volumes can supply real-time anatomical references during live ultrasound scanning.
- Operator variability in ultrasound acquisition may decrease when these references are available on-screen.
- Fewer follow-up CT examinations may be required once ultrasound operators have access to the pseudo-CT guidance.
- The pipeline depends on accurate prior spatial alignment of ultrasound and CT volumes via landmark-based registration.
Where Pith is reading between the lines
- The same registration-plus-synthesis pattern could be tested on other organs where paired 3D data exist.
- Embedding the model in clinical ultrasound workstations would let operators see the guidance immediately rather than after offline processing.
- If paired data remain scarce, future versions might explore unpaired or semi-supervised training to enlarge the effective training set.
Load-bearing premise
The small number of paired ultrasound-CT cases available in the TRUSTED dataset is sufficient for the trained model to produce usable results on new, unseen ultrasound scans.
What would settle it
Applying the trained model to an independent collection of paired 3D kidney ultrasound and CT volumes and observing whether PSNR and SSIM fall below the reported baseline levels.
Figures



read the original abstract
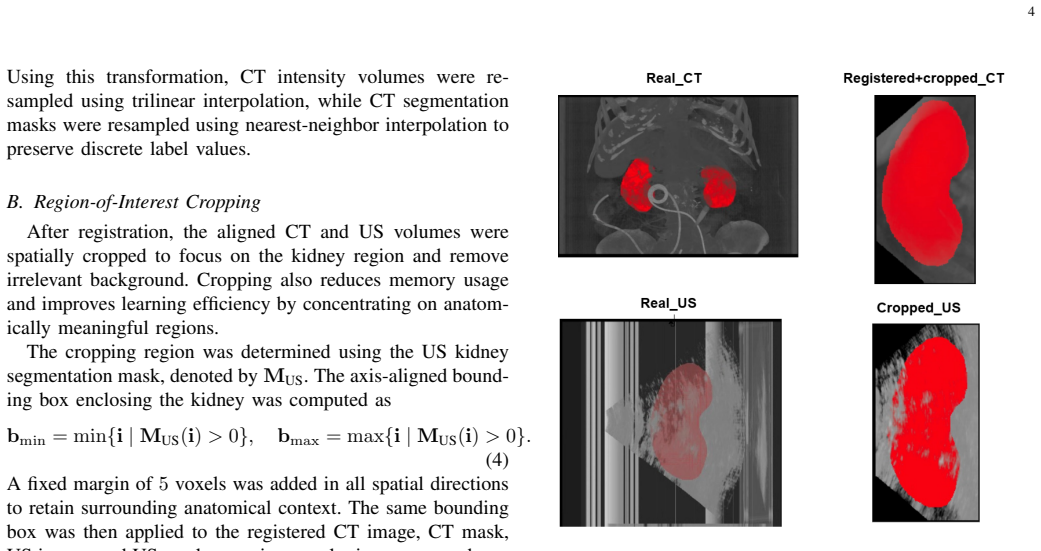
Computed tomography (CT) is indispensable for clinical diagnosis and image-guided interventions but exposes patients to ionizing radiation, motivating the development of safer imaging alternatives. Ultrasound (US) is non-ionizing and widely accessible; however, it is highly operator dependent and lacks quantitative tissue characterization, often leading to diagnostic uncertainty and unnecessary CT examinations. This work presents a 3D ultrasound-derived pseudo-CT (UD-pCT) framework that generates CT-like anatomical reference volumes inferred from US, without aiming to reproduce physically accurate Hounsfield Units. Paired 3D kidney US and CT volumes from the TRUSTED dataset are first spatially aligned using a landmark-based multimodal registration pipeline, creating high-quality paired inputs for supervised training of an adversarial framework. The proposed Bottleneck Transformer Residual U-Net3D (BT-ResUNet3D) model employs a 3D residual encoder-decoder generator augmented with a transformer bottleneck, enabling effective modeling of fine-grained local anatomical structures as well as long-range volumetric dependencies, while a 3D Conditional PatchGAN discriminator enforces local structural realism in the synthesized pseudo-CT volumes. Quantitative evaluation using PSNR and SSIM demonstrates that the proposed method outperforms established baselines in structural fidelity and perceptual image quality. The UD-pCT volumes provide real-time anatomical reference for operator guidance, potentially reducing acquisition variability and unnecessary CT use. A limitation of this study is the relatively small paired dataset, which may limit the generalizability of the proposed model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a 3D ultrasound-derived pseudo-CT (UD-pCT) synthesis framework using a Bottleneck Transformer Residual U-Net3D (BT-ResUNet3D) generator paired with a 3D Conditional PatchGAN discriminator. Trained on landmark-aligned paired kidney US-CT volumes from the TRUSTED dataset, the model is claimed to outperform established baselines in PSNR and SSIM, providing real-time anatomical references for operator guidance while noting the small paired dataset as a limitation on generalizability.
Significance. If the quantitative superiority holds under rigorous validation, the approach could meaningfully support radiation-free guidance in interventions by supplying CT-like structural context from accessible ultrasound, with the transformer bottleneck offering a plausible way to capture long-range 3D dependencies beyond standard residual U-Nets.
major comments (2)
- [Abstract] Abstract: The central claim of outperformance on PSNR and SSIM is presented without any description of training protocol, baseline implementations, statistical testing, variance across runs, or cross-validation strategy. Given the explicit limitation of the relatively small paired TRUSTED dataset, this omission directly weakens the ability to attribute reported gains to the BT-ResUNet3D architecture rather than split-specific effects or overfitting.
- [Abstract] Abstract: No evidence is provided (e.g., k-fold results or external cohort testing) that the quantitative improvements survive scrutiny on independent data, despite the acknowledged small dataset size; standard U-Net baselines are known to produce inflated metrics on tiny medical volumes due to memorization, making the superiority claim load-bearing on unreported evaluation details.
minor comments (1)
- [Abstract] The abstract could usefully report the exact number of paired volumes and the train/validation/test split sizes to allow immediate assessment of the dataset scale.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying details present in the full manuscript while proposing targeted revisions to the abstract and discussion to improve transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of outperformance on PSNR and SSIM is presented without any description of training protocol, baseline implementations, statistical testing, variance across runs, or cross-validation strategy. Given the explicit limitation of the relatively small paired TRUSTED dataset, this omission directly weakens the ability to attribute reported gains to the BT-ResUNet3D architecture rather than split-specific effects or overfitting.
Authors: We agree the abstract is concise and omits key methodological details. The full manuscript describes the training protocol (Section 3.2, including optimizer, loss weights, and augmentation), baseline implementations (Section 4.1, with standard 3D U-Net and ResUNet3D variants), and reports mean PSNR/SSIM with standard deviations across five independent runs using different random seeds. No p-value statistical testing was performed, but variance is explicitly shown in Table 2. A fixed 70/15/15 split was used rather than cross-validation due to the small paired dataset size. We will revise the abstract to briefly note the evaluation protocol, variance reporting, and fixed split to strengthen attribution of gains to the architecture. revision: partial
-
Referee: [Abstract] Abstract: No evidence is provided (e.g., k-fold results or external cohort testing) that the quantitative improvements survive scrutiny on independent data, despite the acknowledged small dataset size; standard U-Net baselines are known to produce inflated metrics on tiny medical volumes due to memorization, making the superiority claim load-bearing on unreported evaluation details.
Authors: We acknowledge this valid concern regarding generalizability. The study is limited to the single TRUSTED paired dataset with no external cohort available; evaluation used a held-out test set after landmark alignment, with consistent outperformance over baselines. Data augmentation and the transformer bottleneck were employed to reduce memorization risk. We will expand the discussion section to explicitly address overfitting risks on small medical volumes and call for future multi-center validation. We cannot provide k-fold results without new experiments. revision: partial
- Providing k-fold cross-validation results or external independent cohort testing, as these were not performed in the original study due to the constraints of the small paired TRUSTED dataset.
Circularity Check
No significant circularity in claimed results
full rationale
The paper describes an empirical supervised learning pipeline: paired 3D US-CT volumes from the TRUSTED dataset are registered, a BT-ResUNet3D generator plus PatchGAN discriminator is trained, and performance is measured with standard PSNR/SSIM on held-out pairs. No derivation chain, first-principles equations, or uniqueness theorems are presented that reduce the reported outperformance to fitted parameters, self-definitions, or self-citations by construction. The abstract explicitly flags the small paired dataset as a limitation without invoking prior author work to justify generalizability. Evaluation on independent test data with conventional image metrics remains falsifiable and does not collapse into the training inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- network weights and hyperparameters
Reference graph
Works this paper leans on
-
[1]
Current global utilization of computed tomography: Trends and implications,
R. Smith-Bindman and J. Boone, “Current global utilization of computed tomography: Trends and implications,”Radiology, 2025. [In press], doi: 10.1148/radiol.202525XXXX
-
[2]
Global trends in computed tomogra- phy usage and dose: Implications for future cancer risk,
M. K. Kalra, J. G. Amaral, et al., “Global trends in computed tomogra- phy usage and dose: Implications for future cancer risk,”Eur. J. Radiol., vol. 141, p. 109791, 2021, doi: 10.1016/j.ejrad.2021.109791
-
[3]
Global cancer statis- tics 2022: GLOBOCAN estimates of incidence and mortality world- wide,
F. Bray, J. Ferlay, I. Soerjomataram, A. Jemal, “Global cancer statis- tics 2022: GLOBOCAN estimates of incidence and mortality world- wide,”CA Cancer J. Clin., vol. 74, no. 2, pp. 118–145, 2024, doi: 10.3322/caac.21823
-
[4]
Global cancer burden rising, expected to reach 35 million new cases by 2050,
World Health Organization, “Global cancer burden rising, expected to reach 35 million new cases by 2050,” 2024. Available: https://www. who.int/news/item/01-02-2024-global-cancer-burden-rising. [Accessed: 2025-10-07]
work page 2050
-
[5]
Projected cancer risks from computed tomographic scans performed in the United States in 2007,
A. B. de Gonz ´alez, M. Mahesh, K. K. Kim, C. R. McCollough, D. J. Brenner, “Projected cancer risks from computed tomographic scans performed in the United States in 2007,”Arch. Intern. Med., vol. 169, no. 22, pp. 2071–2077, 2009, doi: 10.1001/archinternmed.2009.440
-
[6]
Projected lifetime cancer risks from current 9 computed tomographic practices,
R. Smith-Bindman, et al., “Projected lifetime cancer risks from current 9 computed tomographic practices,”JAMA Intern. Med., 2025. [Online], doi: 10.1001/jamainternmed.2025.XXXX
-
[7]
T. L. Szabo,Diagnostic Ultrasound Imaging: Inside Out, Academic Press, 2014
work page 2014
-
[8]
S. Xing, D. W. Cool, D. Tessier, E. C. S. Chen, T. M. Peters, and A. Fenster, “Deep regression 2D–3D ultrasound registration for liver motion correction in focal tumour thermal ablation,”Healthcare Technology Letters, vol. 12, no. 1, p. e12117, 2025
work page 2025
-
[9]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
work page 1998
-
[10]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y . Bengio, “Generative adversarial nets,”Advances in Neural Information Processing Systems, vol. 27, 2014
work page 2014
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[12]
Physics-informed machine learning,
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, L. Yang, “Physics-informed machine learning,”Nature Reviews Physics, vol. 3, pp. 422–440, 2021
work page 2021
-
[13]
Medical image synthesis with deep learning: Progress and challenges,
D. Nie, R. Trullo, J. Lian, C. Petitjean, S. Ruan, Q. Wang, D. Shen, “Medical image synthesis with deep learning: Progress and challenges,” Journal of Magnetic Resonance Imaging, vol. 51, pp. 1067–1088, 2020
work page 2020
-
[14]
S. Ossaba, ´A. Diez, M. Marti, M. L. Parra-Gordo, R. Alonso-Gonzalez, R. Tenajas, G. Garz´on, “Validation of a deep-learning modular prototype to guide novices to acquire diagnostic ultrasound images from urinary system,”WFUMB Ultrasound Open, vol. 2, no. 2, p. 100049, 2024
work page 2024
-
[15]
Artificial intelligence–guided lung ultrasound by nonexperts,
C. Baloescu, J. Bailitz, B. Cheema, et al., “Artificial intelligence–guided lung ultrasound by nonexperts,”JAMA Cardiology, vol. 10, no. 3, pp. 245–253, 2025
work page 2025
-
[16]
Recent advances in AI-assisted ultrasound scanning,
R. Tenajas, et al., “Recent advances in AI-assisted ultrasound scanning,” Applied Sciences, 2023
work page 2023
-
[17]
B. He, et al., “A robust and automatic CT-3D US registration method based on segmentation, context, and edge hybrid metric,”Medical Physics, 2023
work page 2023
-
[18]
Automatic landmark-based registration of 3D ultrasound and CT images for kidney intervention,
Y . Xie, H. Chen, J. Wang, “Automatic landmark-based registration of 3D ultrasound and CT images for kidney intervention,”IEEE Trans. Med. Imaging, vol. 41, no. 8, pp. 1990–2002, 2022, doi: 10.1109/TMI.2022.3173456
-
[19]
B. He, L. Zhang, Y . Li, “A robust and automatic CT-3D US registration method based on segmentation, context, and edge hybrid metric,”Medi- cal Physics, vol. 50, no. 4, pp. 1234–1247, 2023, doi: 10.1002/mp.16000
-
[20]
J. Ma, K. Liu, P. Gao, “Intensity-based multimodal registration of ultra- sound and CT using normalized cross-correlation and correlation ratio,” Phys. Med. Biol., vol. 66, no. 12, p. 125012, 2021, doi: 10.1088/1361- 6560/ac1234
-
[21]
In-silico simulation study to generate CT images from ultrasound data using pix2pix,
“In-silico simulation study to generate CT images from ultrasound data using pix2pix,”BJR—Artificial Intelligence, 2025
work page 2025
-
[22]
Double U-Net CycleGAN for 3D MR to CT image synthesis,
S. Sun, et al., “Double U-Net CycleGAN for 3D MR to CT image synthesis,”Int J Comput Assist Radiol Surg, 2023
work page 2023
-
[23]
Supervised versus unsupervised GAN for pseudo-CT synthesis in brain MR-guided radiotherapy,
“Supervised versus unsupervised GAN for pseudo-CT synthesis in brain MR-guided radiotherapy,”PubMed, 2025
work page 2025
-
[24]
Denoising diffusion probabilistic models for 3D medical image gener- ation,
“Denoising diffusion probabilistic models for 3D medical image gener- ation,”Scientific Reports, 2023
work page 2023
-
[25]
cWDM: Conditional Wavelet Diffusion Models for Cross-Modality 3D Medical Image Synthesis,
P. Friedrich, et al., “cWDM: Conditional Wavelet Diffusion Models for Cross-Modality 3D Medical Image Synthesis,”arXiv, 2024
work page 2024
-
[26]
3D U-Net: Learning Dense V olumetric Segmentation from Sparse Annotation,
O. C ¸ ic ¸ek, A. Abdulkadir, S. S. Lienkamp, T. Brox, and O. Ronneberger, “3D U-Net: Learning Dense V olumetric Segmentation from Sparse Annotation,” inMedical Image Computing and Computer-Assisted In- tervention (MICCAI), 2016, pp. 424–432
work page 2016
-
[27]
Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
K. Hara, H. Karpagam, and Y . Satoh, “Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6546–6555
work page 2018
-
[28]
ResViT: Residual Vision Transformers for Multimodal Medical Image Synthesis,
S. Mahmood, H. Chen, D. Ronneberger, and L. P. K. Wahid, “ResViT: Residual Vision Transformers for Multimodal Medical Image Synthesis,” IEEE Transactions on Medical Imaging, vol. 41, no. 10, pp. 2598–2614, 2022
work page 2022
-
[29]
Denoising Diffusion Probabilistic Models,
J. Ho, A. J. Chapman, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” inAdvances in Neural Information Processing Systems, 2020, vol. 33
work page 2020
-
[30]
High-Resolution Image Synthesis with Latent Diffusion Models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-Resolution Image Synthesis with Latent Diffusion Models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10684–10695
work page 2022
-
[31]
Conditional Wavelet Diffusion Models for Cross-Modality 3D Medical Image Synthesis,
P. Friedrich, et al., “Conditional Wavelet Diffusion Models for Cross-Modality 3D Medical Image Synthesis,”arXiv preprint arXiv:2401.XXXXX, 2024
work page 2024
-
[32]
Cross-Conditioned Diffusion Models for Robust Medical Image Translation,
R. Zhang, J. Lu, and S. Li, “Cross-Conditioned Diffusion Models for Robust Medical Image Translation,” inMedical Image Computing and Computer-Assisted Intervention (MICCAI), 2024
work page 2024
-
[33]
H. Wang, et al., “3D MedDiffusion: A 3D Medical Diffusion Model for Controllable and High-quality Medical Image Generation,”arXiv, 2024
work page 2024
-
[34]
Cross-conditioned Diffusion Model for Medical Image to Image Trans- lation,
“Cross-conditioned Diffusion Model for Medical Image to Image Trans- lation,”MICCAI 2024, 2024
work page 2024
-
[35]
Semantic CycleGAN for unpaired image-to-image translation,
M. Gong, Y . Zhang, T. Li, J. Huang, and J. Zhao, “Semantic CycleGAN for unpaired image-to-image translation,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 5144– 5153
work page 2017
-
[36]
W. Ndzimbong, et al., “TRUSTED: The Paired 3D Transabdominal Ul- trasound and CT Human Data for Kidney Segmentation and Registration Research.”Scientific Data, 2025 12(1), 615
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.