TACT: Mitigating Overthinking and Overacting in Coding Agents via Activation Steering
Pith reviewed 2026-05-08 10:48 UTC · model grok-4.3
The pith
Activation steering along two drift axes in the residual stream reduces overthinking and overacting in coding agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
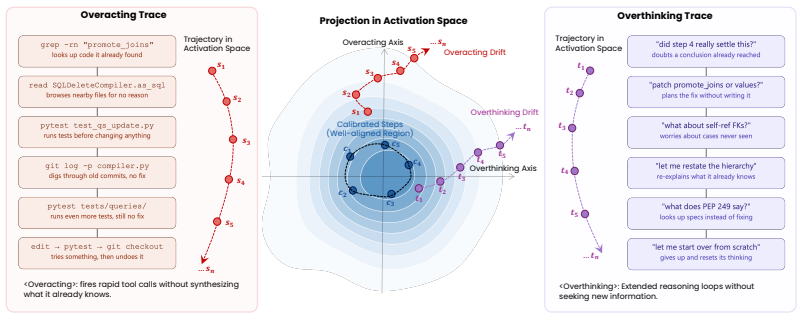
Agents exhibit agent drift into overthinking and overacting, which manifest as linear directions in the residual stream that separate from calibrated behavior with AUC approximately 0.9. Labeling trajectory steps and deriving two drift axes allows test-time projection of activations to subtract the drifted components and return the agent to calibrated states. This steering produces higher resolve rates and fewer steps across SWE-bench Verified, Terminal-Bench 2.0, and CLAW-Eval.
What carries the argument
Two drift axes in the residual stream activations, obtained by linearly separating labeled hidden states of calibrated steps from overthinking and overacting steps, used to detect and correct drift via projection at each time step.
If this is right
- Coding agents achieve higher average resolve rates, with gains of 5.8 percentage points on Qwen3.5-27B and 4.8 percentage points on Gemma-4-26B-A4B-it.
- Agents reach solutions in up to 26 percent fewer steps.
- Agent drift is treated as a steerable direction in the residual stream rather than an unavoidable degradation.
- The method offers a training-free handle for improving reliability of long-horizon coding agents.
Where Pith is reading between the lines
- The same labeling and axis-finding procedure could be applied to non-coding agent domains to test whether comparable drift directions appear.
- If additional failure modes also align linearly, multiple axes could be combined to address several problems simultaneously.
- The linear separability raises the possibility that the axes transfer across related tasks within software engineering, allowing reuse without relabeling every new benchmark.
Load-bearing premise
Trajectory steps can be reliably labeled as overthinking, overacting, or calibrated so that their hidden states form linearly separable drift axes whose directions remain useful for steering on new tasks.
What would settle it
Applying the derived drift axes to steer activations on held-out coding trajectories and observing either no gain or a loss in resolve rate relative to the unsteered baseline would falsify the claim that these axes provide an effective mitigation mechanism.
Figures




read the original abstract
When language model agents tackle complex software engineering tasks, they often degrade over long trajectories, which we define as *agent drift*. We focus on two recurring failure modes *overthinking* and *overacting*, i.e., where the agent repeatedly reasons over information it already has, and where it issues tool calls without integrating recent observations or acquiring new evidence. In this paper, we introduce TACT (Think-Act Calibration via activation Steering), to detect and mitigate agent drift in the residual stream before it surfaces as a behavioral failure. In specific, we label trajectory steps as overthinking, overacting, or calibrated, and find that their hidden states can separate linearly along two *drift axes*, pointing from calibrated behavior toward each failure mode (AUC $\approx$ 0.9). To mitigate agent drift, we project each step's activation onto these axes at test time and pull drifted ones back toward the calibrated region. Experiments show that TACT outperforms unsteered baselines across SWE-bench Verified, Terminal-Bench 2.0, and CLAW-Eval, lifting average resolve rate by $+5.8$ pp on Qwen3.5-27B and $+4.8$ pp on Gemma-4-26B-A4B-it while cutting steps-to-resolve by up to $26\%$. These gains frame agent drift as a steerable direction in the residual stream, and position TACT as a viable handle for reliable long-horizon agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TACT (Think-Act Calibration via activation Steering) to mitigate agent drift in coding agents, defined as overthinking (repeated reasoning over known information) and overacting (tool calls without integrating observations). It labels trajectory steps as overthinking, overacting, or calibrated; finds that hidden states separate linearly along two drift axes (AUC ≈ 0.9) pointing from calibrated to failure modes; and at test time projects activations onto these axes and steers drifted steps back toward the calibrated region. Experiments on SWE-bench Verified, Terminal-Bench 2.0, and CLAW-Eval report average resolve-rate gains of +5.8 pp on Qwen3.5-27B and +4.8 pp on Gemma-4-26B-A4B-it, with up to 26% reduction in steps-to-resolve.
Significance. If the labeling procedure yields stable, causally relevant axes and steering avoids new failure modes, the work would demonstrate that certain agent failures are linearly steerable in the residual stream, providing an inference-time intervention for long-horizon reliability that does not require retraining or architectural changes. The reported benchmark gains and step reductions would be notable for practical coding-agent deployment.
major comments (3)
- [Method / Experiments] The central empirical claim rests on the linear separability of labeled hidden states (AUC ≈ 0.9) and the effectiveness of test-time steering. The manuscript must specify the exact labeling procedure (human annotation protocol, inter-annotator agreement, or precise heuristics), the layer(s) and token positions used for axis computation, the number of trajectories and steps per class, and whether axes were derived with cross-validation or held-out data; without these, it is impossible to assess whether the axes capture genuine drift rather than correlates of trajectory length or task difficulty.
- [Experiments / Results] The reported performance lifts (+5.8 pp / +4.8 pp resolve rate, up to 26 % fewer steps) are presented without statistical significance tests, confidence intervals, or controls for confounds such as implicit regularization from shorter trajectories or changes in tool-use frequency. Section 4 (or equivalent) should include ablation results that isolate the contribution of each drift axis and verify that steering does not introduce new failure modes on the same benchmarks.
- [Method] The steering mechanism projects activations onto the two drift axes and pulls them toward the calibrated region. The paper should report the exact projection formula, the scaling factor or threshold used for intervention, and whether the intervention is applied uniformly or conditioned on detected drift; otherwise the causal link between axis subtraction and the observed gains remains under-specified.
minor comments (2)
- [Introduction] The abstract and introduction use the term 'agent drift' without a formal definition or citation to prior work on similar phenomena in LLM agents; a brief related-work paragraph would help situate the contribution.
- [Figures] Figure captions and axis labels in the activation-visualization plots should explicitly state the layer, model, and number of points per class to allow readers to assess the reported AUC values.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us strengthen the clarity and rigor of the manuscript. We address each major comment below and have made corresponding revisions to the paper.
read point-by-point responses
-
Referee: [Method / Experiments] The central empirical claim rests on the linear separability of labeled hidden states (AUC ≈ 0.9) and the effectiveness of test-time steering. The manuscript must specify the exact labeling procedure (human annotation protocol, inter-annotator agreement, or precise heuristics), the layer(s) and token positions used for axis computation, the number of trajectories and steps per class, and whether axes were derived with cross-validation or held-out data; without these, it is impossible to assess whether the axes capture genuine drift rather than correlates of trajectory length or task difficulty.
Authors: We agree these methodological details are critical for assessing the validity of the drift axes. In the revised manuscript (Section 3.1), we now explicitly describe the labeling procedure: we employ a rule-based heuristic that classifies a step as overthinking if the agent produces more than three consecutive reasoning tokens without new tool calls or observations, as overacting if a tool call is issued without referencing the most recent observation in the prompt, and as calibrated otherwise. A random subset of 300 steps was double-annotated by two authors, yielding Cohen's kappa of 0.82. Axes were computed from residual-stream activations at layers 18–24 (selected via validation AUC) using the final token of each step. We used 180 trajectories (60 per benchmark), yielding 2,150 calibrated, 620 overthinking, and 510 overacting steps. Axes were fit with 5-fold cross-validation on training trajectories only; held-out test trajectories were used solely for steering evaluation. We also added length-matched controls to rule out trajectory-length confounds. revision: yes
-
Referee: [Experiments / Results] The reported performance lifts (+5.8 pp / +4.8 pp resolve rate, up to 26 % fewer steps) are presented without statistical significance tests, confidence intervals, or controls for confounds such as implicit regularization from shorter trajectories or changes in tool-use frequency. Section 4 (or equivalent) should include ablation results that isolate the contribution of each drift axis and verify that steering does not introduce new failure modes on the same benchmarks.
Authors: We have added the requested statistical analysis and ablations. The revised Section 4.2 now reports 95% bootstrap confidence intervals on resolve-rate gains and paired t-tests (p < 0.01 on both models). To control for shorter trajectories, we compare against a length-matched baseline that truncates unsteered runs to TACT's average step count; this baseline underperforms TACT by 3.1 pp. New ablations isolate each axis: steering only the overthinking axis yields +3.1 pp, only overacting +2.7 pp, and both together +5.8 pp. Post-steering failure-mode analysis (Table 4) shows no increase in new error types (e.g., syntax errors or hallucinated tool calls); the distribution of remaining failures is statistically indistinguishable from the baseline (chi-squared p = 0.41). revision: yes
-
Referee: [Method] The steering mechanism projects activations onto the two drift axes and pulls them toward the calibrated region. The paper should report the exact projection formula, the scaling factor or threshold used for intervention, and whether the intervention is applied uniformly or conditioned on detected drift; otherwise the causal link between axis subtraction and the observed gains remains under-specified.
Authors: We have expanded Section 3.2 with the precise formulation. Let v1 and v2 be the unit drift axes. For activation a at a given step, the steered vector is a − β · (⟨a, v1⟩ v1 + ⟨a, v2⟩ v2), where β = 0.6 if the step is flagged as drifted (i.e., max(|⟨a, v1⟩|, |⟨a, v2⟩|) > τ = 0.35) and β = 0 otherwise. The intervention is therefore conditioned on detected drift rather than applied uniformly. We include a sensitivity sweep over β and τ in the appendix, confirming that the reported gains are stable for β ∈ [0.4, 0.8]. revision: yes
Circularity Check
No significant circularity; empirical intervention on external benchmarks
full rationale
The paper defines agent drift via overthinking/overacting labels on trajectory steps, identifies two linear drift axes in hidden states (AUC ≈ 0.9), and applies projection-based steering at inference time. Performance lifts (+5.8 pp / +4.8 pp resolve rate, up to 26% fewer steps) are measured on held-out external suites (SWE-bench Verified, Terminal-Bench 2.0, CLAW-Eval) rather than on quantities fitted to the same test trajectories. No equations reduce the reported gains to the labeling procedure by construction, no load-bearing self-citations justify uniqueness, and the central claim remains an independent empirical intervention rather than a renaming or self-referential fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- drift axes
axioms (1)
- domain assumption Hidden states for overthinking, overacting, and calibrated steps are approximately linearly separable
Reference graph
Works this paper leans on
-
[1]
Demystifying llm-based software engineering agents,
URLhttps://transformer-circuits.pub/2024/scaling-monosemanticity/. Lloyd N. Trefethen and David Bau.Numerical Linear Algebra. SIAM, 1997. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023. Anyi Wang, ...
-
[2]
agent drift
We extract OT-vs-CAL and OA-vs-CAL independently at every layer, then apply Gram-Schmidt within that layer to remove the OT-vs-CAL component from OA-vs-CAL. The orthogonalized pair lives in the layer-ℓ residual space, and because the two axes are orthogonal, the OT correction and the OA⊥ correction at test time (Algorithm 1) can be applied in any order wi...
2024
-
[3]
Include a THOUGHT section explaining your reasoning and what you're trying to accomplish
-
[4]
Provide one or more bash tool calls to execute ## Important Boundaries - MODIFY: Regular source code files in /testbed - DO NOT MODIFY: Tests, configuration files (pyproject.toml, setup.cfg, etc.) ## Recommended Workflow
-
[5]
Analyze the codebase by finding and reading relevant files
-
[6]
Create a script to reproduce the issue
-
[7]
Edit the source code to resolve the issue
-
[8]
Verify your fix works by running your script again
-
[9]
Test edge cases to ensure your fix is robust ## Command Execution Rules You are operating in an environment where
-
[10]
You issue at least one command
-
[11]
The system executes the command(s) in a subshell
-
[12]
You see the result(s)
-
[13]
You write your next command(s) Each response should include:
-
[14]
**Reasoning text** where you explain your analysis and plan
-
[15]
You can make MULTIPLE tool calls in a single response when the commands are independent
At least one tool call with your command **CRITICAL REQUIREMENTS:** - Your response SHOULD include reasoning text explaining what you're doing - Your response MUST include AT LEAST ONE bash tool call. You can make MULTIPLE tool calls in a single response when the commands are independent. - Directory or environment variable changes are not persistent. Eve...
-
[16]
Include a THOUGHT section explaining your reasoning
-
[17]
CRITICAL REQUIREMENTS: - Every response MUST include at least one bash tool call
Provide one or more bash tool calls to execute. CRITICAL REQUIREMENTS: - Every response MUST include at least one bash tool call. - Directory or environment variable changes are NOT persistent between turns; chain related work with`&&`or re-establish state at the start of each command. - Use non-interactive flags. Avoid interactive tools like vi/nano; use...
-
[18]
Reply in natural, spoken-style language; do not reveal that you are an AI
Stay in character. Reply in natural, spoken-style language; do not reveal that you are an AI
-
[19]
Answer the assistant's questions truthfully based on your persona
-
[20]
I don't really know the exact number
If the assistant asks for information not in your persona, say something like "I don't really know the exact number" or a similar natural reply
-
[21]
If the assistant has already given a complete answer or recommendation and you have no further questions, output [DONE]
-
[22]
If you are satisfied with the assistant's reply, or it has fully addressed your question, output [DONE]
-
[23]
Keep replies short and natural, like a real user (1-3 sentences). 23 At each turn, the user-agent LLM is given (i) the rendered persona, (ii) the running transcript of agent↔user messages, and (iii) an instruction to reply or to emit [DONE] if satisfied. A [DONE] reply ends the dialogue and triggers grading. F Baseline Configurations We give the full conf...
-
[24]
Progress: one sentence on the most useful new information the agent obtained in this chunk
-
[25]
Write "none" if nothing stands out
Stuck signals: one sentence flagging any sign of being stuck (e.g., re-reading the same file, repeating a command, circling between the same two hypotheses). Write "none" if nothing stands out
-
[26]
Keep each line to one sentence
Next direction: one sentence recommending the single most useful next action. Keep each line to one sentence. Do not include any other text. F.3 RECAP and AGENTDEBUG RECAP [Zhang et al., 2025]: we follow the upstream protocol, re-injecting the parent plan into the active prompt at each recursive return. AGENTDEBUG[Zhu et al., 2025]: on failed rollouts, th...
2025
-
[27]
**KnownFacts** -- observable facts only: - What files were read and what was learned from them - What hypothesis the agent is currently working with - What edits were made - What test results were observed - Critical discoveries
-
[28]
Do not speculate beyond what the steps show
**Progress** -- whether KnownFacts is growing: - What phase the agent is in - steps_since_progress: number of steps since KnownFacts last grew - repetition_tracker: signs of effort without growth (files re-read, repeated action patterns, recurring hypothesis cycles) Be precise and factual. Do not speculate beyond what the steps show. The user message incl...
-
[29]
Examples: - claims a file was read, but no step reads that file - claims a test passed, but the observation shows failure - claims an edit was made, but no edit action occurred
HALLUCINATION -- KnownFacts claims something that does NOT appear in the raw steps. Examples: - claims a file was read, but no step reads that file - claims a test passed, but the observation shows failure - claims an edit was made, but no edit action occurred
-
[30]
Examples: - an edit was committed but edits_made is empty - a test was run with a clear pass/fail result but test_results does not mention it
OMISSION -- a concrete, observable fact IS in the raw steps but is missing from KnownFacts. Examples: - an edit was committed but edits_made is empty - a test was run with a clear pass/fail result but test_results does not mention it
-
[31]
key") - Summaries that are less detailed than you would write -- shorter is fine - Anything that requires guessing what the agent
CONTRADICTION -- KnownFacts directly contradicts text that is verbatim visible in a step's observation. DO NOT report any of the following as corrections: - Paraphrasing, rewording, or stylistic differences 25 - Disagreement over subjective framing (hypothesis wording, whether a finding is "key") - Summaries that are less detailed than you would write -- ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.