Performance guaranteed MPC Policy Approximation via Cost Guided Learning
Pith reviewed 2026-05-08 08:13 UTC · model grok-4.3
The pith
Cost-guided learning for MPC policy approximation yields tighter optimality loss bounds than error-guided fitting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
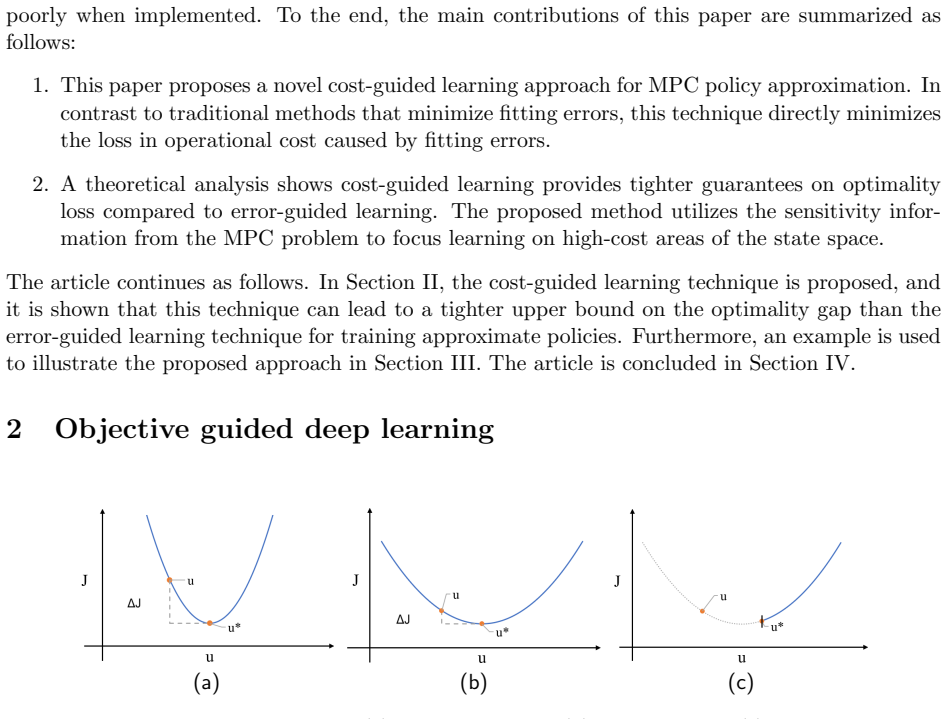
By replacing the conventional error-guided training objective with a cost-guided objective that incorporates sensitivity information from the MPC problem, the learned approximate policy incurs a provably smaller loss in closed-loop optimality while achieving substantially lower operating cost on the CSTR benchmark.
What carries the argument
Cost-guided learning that uses cost sensitivity extracted from the MPC optimization to minimize closed-loop performance loss rather than action fitting error.
If this is right
- Cost-guided learning supplies a strictly tighter upper bound on optimality loss than error-guided learning.
- Approximate MPC policies obtained this way produce lower closed-loop operating cost on the continuous stirred tank reactor.
- The method directly links training error to the operational objective of the controller.
- The same sensitivity-guided idea is claimed to be applicable to other data-driven control settings.
Where Pith is reading between the lines
- The technique could lower the computational resources needed to deploy MPC on embedded hardware by allowing simpler approximators to reach acceptable performance.
- Similar sensitivity weighting might improve policy approximation in other receding-horizon or optimization-based control methods.
- Efficient on-line or batch computation of the required cost sensitivities would be a practical prerequisite for scaling the method.
Load-bearing premise
Cost sensitivity information can be extracted from the MPC problem and incorporated into learning without introducing new approximation errors or prohibitive extra computation.
What would settle it
An experiment on the CSTR benchmark (or a comparable system) in which the closed-loop cost achieved by the cost-guided approximator is no better than, or worse than, that of an error-guided approximator of equal complexity.
Figures

read the original abstract
Model predictive control (MPC) is widely used in industries but implementing it poses challenges due to hardware or time constraints. A promising solution is to approximate the MPC policy using function approximators like neural networks. Existing methods focus on minimizing the error between the approximators outputs and the MPC optimal control actions on training data, which is called error guided learning approach in this paper. However, the goals of control law design is not to minimize the fitting error but to minimize the operation cost. This paper proposes a novel cost-guided learning approach that utilizes the cost sensitivity information from the MPC problem to directly minimize the loss in closed-loop performance. A theoretical analysis shows cost-guided learning provides tighter guarantees on optimality loss compared to traditional error-guided learning. Experiments on a continuous stirred tank reactor (CSTR) benchmark demonstrate that the proposed technique results in approximate MPC policies that achieve substantially better closed-loop performance. This work makes an important contribution by connecting the fitting errors with operational objectives, overcoming key limitations of existing approximation methods. The core idea could be applied more broadly for data-driven control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a cost-guided learning approach for approximating MPC policies with neural networks or other function approximators. Instead of minimizing the fitting error between the approximator outputs and the optimal MPC control actions (error-guided learning), the method uses cost sensitivity information extracted from the MPC problem to directly minimize the closed-loop performance loss. It provides a theoretical analysis claiming tighter guarantees on optimality loss compared to error-guided methods and reports experimental results on a CSTR benchmark showing substantially improved closed-loop performance.
Significance. If the theoretical bounds and experimental improvements hold under scrutiny, the work could meaningfully advance policy approximation in MPC by aligning the learning objective with operational costs rather than proxy errors. This addresses a key limitation in existing methods and may enable broader use of approximate MPC in hardware-constrained settings. The core idea of cost-sensitivity guidance has potential for generalization beyond the CSTR example.
major comments (3)
- [Abstract and §3] Abstract and §3 (theoretical analysis): The claim of 'tighter guarantees on optimality loss' is asserted without any derivation, explicit bound, or comparison to the error-guided case. No equations are shown for how cost sensitivities modify the loss or why the resulting bound is strictly tighter; this prevents verification that the central theoretical contribution is load-bearing or correct.
- [§5] §5 (experiments on CSTR): The abstract states 'substantially better closed-loop performance' but provides no quantitative metrics, error bars, baseline comparisons, or closed-loop cost values. Without these data or tables, it is impossible to assess whether the reported gains are statistically meaningful or reproducible.
- [§4] §4 (method): The extraction of cost sensitivity information from the MPC problem is described at a high level but without algorithmic details, computational complexity analysis, or discussion of how approximation errors in the sensitivities themselves affect the guarantees. This is load-bearing for the performance claims.
minor comments (2)
- [Abstract] The abstract refers to 'function approximators like neural networks' but the full method section should clarify the specific architecture and training procedure used in the CSTR experiments.
- [§2] Notation for cost sensitivity and optimality loss should be defined consistently and early; current high-level description leaves ambiguity about whether the sensitivities are exact or approximated.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help us improve the clarity and completeness of the manuscript. We address each major comment below and will incorporate revisions as indicated.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (theoretical analysis): The claim of 'tighter guarantees on optimality loss' is asserted without any derivation, explicit bound, or comparison to the error-guided case. No equations are shown for how cost sensitivities modify the loss or why the resulting bound is strictly tighter; this prevents verification that the central theoretical contribution is load-bearing or correct.
Authors: We apologize for the insufficient explicitness in the current presentation. Section 3 derives the optimality loss bound by applying the chain rule to the closed-loop cost using the MPC cost sensitivities (i.e., the gradient of the value function with respect to the policy parameters). This yields a weighted error bound where the weights are the cost sensitivities, which is strictly tighter than the uniform Lipschitz-based bound used in error-guided learning. To address the concern, we will insert the full derivation steps, the explicit bound equation, and a side-by-side comparison with the error-guided case in the revised §3. revision: yes
-
Referee: [§5] §5 (experiments on CSTR): The abstract states 'substantially better closed-loop performance' but provides no quantitative metrics, error bars, baseline comparisons, or closed-loop cost values. Without these data or tables, it is impossible to assess whether the reported gains are statistically meaningful or reproducible.
Authors: We agree that the experimental reporting requires more quantitative detail for proper evaluation. The manuscript contains a table of closed-loop costs on the CSTR benchmark, but we will expand §5 to include explicit numerical values, error bars from repeated trials, additional baseline comparisons, and statistical significance tests in the revised version. revision: yes
-
Referee: [§4] §4 (method): The extraction of cost sensitivity information from the MPC problem is described at a high level but without algorithmic details, computational complexity analysis, or discussion of how approximation errors in the sensitivities themselves affect the guarantees. This is load-bearing for the performance claims.
Authors: The sensitivities are obtained by solving the KKT system of the underlying quadratic program once per training sample. We will add pseudocode for this extraction step, a complexity analysis (linear in the number of decision variables for the sensitivity solve), and a short robustness subsection showing that bounded errors in the sensitivities produce only bounded degradation in the derived optimality guarantee. revision: yes
Circularity Check
No significant circularity detected in the derivation
full rationale
The paper proposes cost-guided learning that extracts cost sensitivity directly from the underlying MPC optimization problem to minimize closed-loop performance loss, rather than fitting to control actions. This sensitivity is an independent output of the MPC solver and is not defined in terms of the learning loss or approximator. The claimed tighter optimality-loss bounds are presented as a theoretical result comparing the two learning approaches, without equations that reduce the bound to a fitted quantity by construction. CSTR experiments provide separate empirical support. No self-citations, self-definitional steps, or renamings of known results appear in the abstract or described method. The derivation chain remains self-contained against external MPC benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MPC problems provide accurate and usable cost sensitivity information that can guide learning toward lower closed-loop costs.
Reference graph
Works this paper leans on
-
[1]
Darby and Michael Nikolaou
Mark L. Darby and Michael Nikolaou. Mpc: Current practice and challenges.Control Engi- neering Practice, 20(4):328–342, April 2012
2012
-
[2]
Pistikopoulos
Alberto Bemporad, Manfred Morari, Vivek Dua, and Efstratios N. Pistikopoulos. The explicit linear quadratic regulator for constrained systems.Automatica, 38(1):3–20, January 2002
2002
-
[3]
A sensitivity-based data augmentation framework for model predic- tive control policy approximation.IEEE Transactions on Automatic Control, 2021
Dinesh Krishnamoorthy. A sensitivity-based data augmentation framework for model predic- tive control policy approximation.IEEE Transactions on Automatic Control, 2021
2021
-
[4]
Parisini and R
T. Parisini and R. Zoppoli. A receding-horizon regulator for nonlinear systems and a neural approximation.Automatica, 31(10):1443–1451, October 1995
1995
-
[5]
Wabersich, Angela P
Ali Mesbah, Kim P. Wabersich, Angela P. Schoellig, Melanie N. Zeilinger, Sergio Lucia, Thomas A. Badgwell, and Joel A. Paulson. Fusion of machine learning and mpc under un- certainty: What advances are on the horizon? In2022 American Control Conference (ACC), pages 342–357, 2022
2022
-
[6]
Learning an approximate model predictive controller with guarantees.IEEE Control Systems Letters, 2(3):543–548, July 2018
Michael Hertneck, Johannes K¨ ohler, Sebastian Trimpe, and Frank Allg¨ ower. Learning an approximate model predictive controller with guarantees.IEEE Control Systems Letters, 2(3):543–548, July 2018
2018
-
[7]
Paulson and Ali Mesbah
Joel A. Paulson and Ali Mesbah. Approximate closed-loop robust model predictive control with guaranteed stability and constraint satisfaction.IEEE Control Systems Letters, 2020
2020
-
[8]
Probabilistic performance validation of deep learning-based robust nmpc controllers.International Journal of Robust and Nonlinear Control, 31(18):8855–8876, 2021
Benjamin Karg, Teodoro Alamo, and Sergio Lucia. Probabilistic performance validation of deep learning-based robust nmpc controllers.International Journal of Robust and Nonlinear Control, 31(18):8855–8876, 2021
2021
-
[9]
Chen, Tianyu Wang, Nikolay Atanasov, Vijay Kumar, and Manfred Morari
Steven W. Chen, Tianyu Wang, Nikolay Atanasov, Vijay Kumar, and Manfred Morari. Large scale model predictive control with neural networks and primal active sets.Automatica, 135:109947, January 2022
2022
-
[10]
Yurii Nesterov and B.T. Polyak. Cubic regularization of newton method and its global per- formance.Mathematical Programming, 108(1):177–205, 2006
2006
-
[11]
Andreas W¨ achter and Lorenz T. Biegler. On the implementation of an interior-point fil- ter line-search algorithm for large-scale nonlinear programming.Mathematical Programming, 106(1):25–57, March 2006
2006
-
[12]
Joel A. E. Andersson, Joris Gillis, Greg Horn, James B. Rawlings, and Moritz Diehl. Casadi: A software framework for nonlinear optimization and optimal control.Mathematical Program- ming Computation, 11(1):1–36, March 2019
2019
-
[13]
Offline reinforcement learning: Tutorial, review, and perspectives on open problems, November 2020
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems, November 2020
2020
-
[14]
A survey of inverse reinforcement learning: Challenges, methods and progress.Artificial Intelligence, 297:103500, 2021
Saurabh Arora and Prashant Doshi. A survey of inverse reinforcement learning: Challenges, methods and progress.Artificial Intelligence, 297:103500, 2021
2021
-
[15]
M. C. Campi, A. Lecchini, and S. M. Savaresi. Virtual reference feedback tuning: A direct method for the design of feedback controllers.Automatica, 38(8):1337–1346, August 2002. 12
2002
-
[16]
Kothare, Venkataramanan Balakrishnan, and Manfred Morari
Mayuresh V. Kothare, Venkataramanan Balakrishnan, and Manfred Morari. Robust con- strained model predictive control using linear matrix inequalities.Automatica, 32(10):1361– 1379, October 1996
1996
-
[17]
Global self- optimizing control of batch processes.Journal of Process Control, 135:103163, 2024
Chenchen Zhou, Hongxin Su, Xinhui Tang, Yi Cao, and Shuang-hua Yang. Global self- optimizing control of batch processes.Journal of Process Control, 135:103163, 2024. 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.