Efficient Pre-Training with Token Superposition
Pith reviewed 2026-05-20 22:49 UTC · model grok-4.3
The pith
Token-Superposition Training processes bags of tokens with a multi-hot loss in an initial phase then recovers with standard training to raise data throughput per FLOP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Token-Superposition Training consists of a superposition phase that replaces single-token cross-entropy with a multi-hot objective over bags of contiguous tokens, followed by a recovery phase that restores ordinary single-token training; the combined schedule increases tokens processed per FLOP and, at equal final loss, shortens total pre-training time by up to 2.5 times on a 10 B mixture-of-experts model.
What carries the argument
The multi-hot cross-entropy objective applied to bags of contiguous tokens during the superposition phase, which allows one forward-backward pass to update the model on multiple tokens simultaneously.
Load-bearing premise
The recovery phase restores model quality after the superposition phase without needing enough extra steps to erase the throughput gains of the first phase.
What would settle it
Run a controlled comparison in which a TST schedule and a standard baseline are trained until both reach the same validation loss; if the TST run requires more total steps than the baseline, the claimed time saving disappears.
Figures


















read the original abstract
Pre-training of Large Language Models is often prohibitively expensive and inefficient at scale, requiring complex and invasive modifications in order to achieve high data throughput. In this work, we present Token-Superposition Training (TST), a simple drop-in method that significantly improves the data throughput per FLOPs during pre-training without modifying the parallelism, optimizer, tokenizer, data, or model architecture. TST is done in two phases: (i) A highly efficient superposition phase where we combine many contiguous tokens into one bag and train using a multi-hot cross-entropy (MCE) objective, and (ii) a recovery phase where we revert back to standard training. We extensively evaluate TST on the scale of 270M and 600M parameters and validate on 3B and a 10B A1B mixture of experts model, demonstrating that it is highly robust in different settings. Ultimately, TST consistently outperforms baseline loss and downstream evaluations, and under equal-loss settings, TST yields up to a 2.5x reduction in total pre-training time at the 10B A1B scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Token-Superposition Training (TST), a two-phase drop-in method for LLM pre-training. Phase (i) combines contiguous tokens into bags and optimizes a multi-hot cross-entropy objective to raise data throughput per FLOP; phase (ii) reverts to standard next-token training for recovery. Experiments on 270M–10B-scale models (including a 10B A1B MoE) report that TST yields lower loss and better downstream metrics than baseline, and under equal-loss budgets achieves up to 2.5× reduction in wall-clock pre-training time at the 10B scale.
Significance. A verified, architecture- and infrastructure-agnostic efficiency technique would be a practical contribution to lowering the cost of pre-training. The method’s simplicity and reported robustness across scales are positive features. However, the central efficiency claim rests on an empirical comparison whose supporting measurements are not yet reported in sufficient detail to allow independent verification of net savings.
major comments (2)
- [Abstract and §4] Abstract and §4 (Results): the 2.5× total pre-training time reduction at the 10B A1B scale under equal-loss settings is the central quantitative claim. The manuscript supplies neither the exact step or token budgets allocated to the superposition phase versus the recovery phase nor the loss curves that would demonstrate the sum of both phases is substantially smaller than the baseline step count to the same loss. Without these data it is impossible to rule out that slower recovery from the multi-hot objective erases the throughput advantage.
- [§3 and Table 2] §3 (Experimental Setup) and Table 2: positive results are reported across model scales, yet the text gives no concrete baseline configurations, hyper-parameter values, number of runs, or statistical significance tests for the loss and downstream improvements. This leaves the “consistently outperforms” statement weakly supported.
minor comments (2)
- [§2] The multi-hot cross-entropy loss is described in prose but would be clearer if written as an explicit equation (e.g., showing how the target distribution is formed from the bag of tokens).
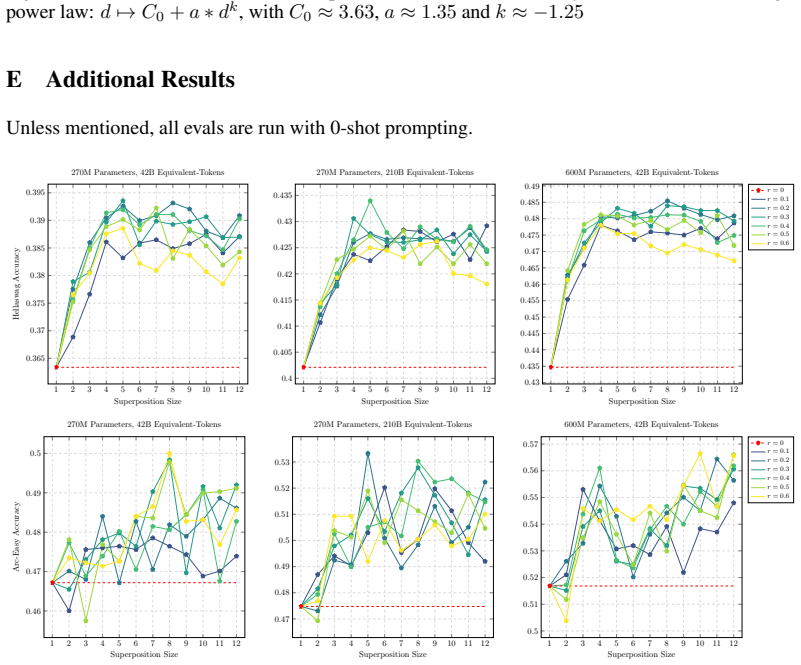
- [Figures] Figure captions and axis labels in the loss curves should explicitly state whether the x-axis is steps or tokens and whether the plotted loss is the standard or the multi-hot objective.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and commit to revisions that strengthen verifiability without altering the core claims or experimental outcomes.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Results): the 2.5× total pre-training time reduction at the 10B A1B scale under equal-loss settings is the central quantitative claim. The manuscript supplies neither the exact step or token budgets allocated to the superposition phase versus the recovery phase nor the loss curves that would demonstrate the sum of both phases is substantially smaller than the baseline step count to the same loss. Without these data it is impossible to rule out that slower recovery from the multi-hot objective erases the throughput advantage.
Authors: We agree that explicit phase budgets and loss curves would improve independent verification of the net savings. The reported 2.5× figure reflects measured wall-clock time to equal loss on the 10B A1B model, where the superposition phase delivers higher tokens-per-FLOP and the recovery phase restores standard next-token performance without fully offsetting the gain. In the revision we will add a table listing exact step/token allocations per phase for the 10B run and a figure with overlaid loss curves for TST versus baseline, confirming the combined budget is smaller. revision: yes
-
Referee: [§3 and Table 2] §3 (Experimental Setup) and Table 2: positive results are reported across model scales, yet the text gives no concrete baseline configurations, hyper-parameter values, number of runs, or statistical significance tests for the loss and downstream improvements. This leaves the “consistently outperforms” statement weakly supported.
Authors: Section 3 describes the overall setup and data, but we acknowledge that hyper-parameter tables, run counts, and significance metrics are not presented with sufficient granularity. The improvements were observed consistently across scales with the same optimizer and learning-rate schedule as the baseline. In revision we will expand §3 and Table 2 (or add an appendix table) with full hyper-parameter values, state that smaller-scale results used three independent runs with reported standard deviations, and include statistical significance where sample sizes permit. revision: yes
Circularity Check
No circularity: empirical method with direct experimental validation
full rationale
The paper introduces TST as a two-phase empirical training procedure (superposition with multi-hot cross-entropy followed by standard recovery) and supports its claims of loss improvement and up to 2.5x time reduction solely through direct measurements on 270M–10B models. No mathematical derivation, first-principles prediction, or fitted parameter is presented that reduces to its own inputs by construction. Results rest on reported loss curves, downstream evaluations, and wall-clock comparisons rather than any self-referential equation or self-citation chain. The central efficiency claim is therefore an observed outcome, not a tautological restatement of an internal fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Bao, and others. gpt-oss-120b & gpt-oss-20b model card. 10
-
[2]
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Mil- licah, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Mon- teiro, J. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Barreira, O. Vinyals, A. Zisserman, and K. Simonyan. Flamingo: a visual language ...
work page 2022
-
[3]
L. B. Allal, A. Lozhkov, E. Bakouch, G. M. Bl ´azquez, G. Penedo, L. Tunstall, A. Marafioti, H. Kydl´ıˇcek, A. P. Lajar´ın, V . Srivastav, J. Lochner, C. Fahlgren, X.-S. Nguyen, C. Fourrier, B. Burtenshaw, H. Larcher, H. Zhao, C. Zakka, M. Morlon, C. Raffel, L. v. Werra, and T. Wolf. SmolLM2: When Smol Goes Big – Data-Centric Training of a Small Language ...
-
[4]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
URLhttp://arxiv.org/abs/2502.02737. arXiv:2502.02737 [cs]
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
S. Anagnostidis, G. Bachmann, I. Schlag, and T. Hofmann. Navigating scaling laws: compute optimality in adaptive model training. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofICML’24, pages 1511–1530, Vienna, Austria, 2024. JMLR.org
work page 2024
-
[6]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, and others. Qwen technical report
-
[7]
X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, and others. Deepseek llm: Scaling open-source language models with longtermism
-
[8]
Y . Bisk, R. Zellers, J. Gao, Y . Choi, et al. Piqa: Reasoning about physical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
work page 2020
-
[9]
M. Chen, B. Hui, Z. Cui, J. Yang, D. Liu, J. Sun, J. Lin, and Z. Liu. Parallel Scaling Law for Language Models. Oct. 2025. URLhttps://openreview.net/forum?id=dEi1S731lk
work page 2025
- [10]
-
[11]
C. Clark, K. Lee, M.-W. Chang, T. Kwiatkowski, M. Collins, and K. Toutanova. Boolq: Ex- ploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 confer- ence of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), pages 2924–2936, 2019
work page 2019
-
[12]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
C. Cortes and V . Vapnik. Support-vector networks.Machine learning, 20(3):273–297, 1995
work page 1995
-
[14]
D. Dai, C. Deng, C. Zhao, R. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wu, Z. Xie, Y . Li, P. Huang, F. Luo, C. Ruan, Z. Sui, and W. Liang. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Com- pu...
-
[15]
doi: 10.18653/v1/2024.acl-long.70
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.70. URL https://aclanthology.org/2024.acl-long.70/
-
[16]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. Oct. 2020. URLhttps://openreview.net/forum?id=YicbFdNTTy&utm_ campaign=The%20Batch&utm_source=hs_email&utm_medium=email&_...
work page 2020
-
[17]
W. Ebeling and T. P ¨oschel. Entropy and Long-Range Correlations in Literary English.Euro- physics Letters, 26(4):241, May 1994. ISSN 0295-5075. doi: 10.1209/0295-5075/26/4/001. URLhttps://doi.org/10.1209/0295-5075/26/4/001
-
[18]
S. Y . Gadre, G. Smyrnis, V . Shankar, S. Gururangan, M. Wortsman, R. Shao, J. Mercat, A. Fang, J. Li, S. Keh, and others. Language models scale reliably with over-training and on downstream tasks
-
[19]
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou. A framework for few-shot language model evaluation, 12 2023. URLhttps: //zenodo.org/records/10256836
-
[20]
T. Gigant, B. Peng, and J. Quesnelle. Decoupling the Benefits of Subword Tokenization for Language Model Training via Byte-level Simulation, Apr. 2026. URLhttp://arxiv.org/ abs/2604.27263. arXiv:2604.27263 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
H. Gisserot-Boukhlef, N. Boizard, M. Faysse, D. M. Alves, E. Malherbe, A. Martins, C. Hude- lot, and P. Colombo. Should We Still Pretrain Encoders with Masked Language Modeling? Oct. 2025. URLhttps://openreview.net/forum?id=jpz7e3jhRq
work page 2025
-
[22]
F. Gloeckle, B. Y . Idrissi, B. Rozi `ere, D. Lopez-Paz, and G. Synnaeve. Better & faster large language models via multi-token prediction. InProceedings of the 41st International Confer- ence on Machine Learning, volume 235 ofICML’24, pages 15706–15734, Vienna, Austria,
-
[23]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, and others. The llama 3 herd of models
-
[24]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[25]
M. Y . Hu, J. Petty, C. Shi, W. Merrill, and T. Linzen. Between Circuits and Chomsky: Pre-pretraining on Formal Languages Imparts Linguistic Biases. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), pages 9691–9709, Vienna, Aus- ...
work page 2025
-
[26]
S. Hu, Y . Tu, X. Han, C. He, G. Cui, X. Long, Z. Zheng, Y . Fang, Y . Huang, W. Zhao, X. Zhang, Z. L. Thai, K. Zhang, C. Wang, Y . Yao, C. Zhao, J. Zhou, J. Cai, Z. Zhai, N. Ding, C. Jia, G. Zeng, D. Li, Z. Liu, and M. Sun. Minicpm: Unveiling the potential of small language mod- els with scalable training strategies, 2024. URLhttps://arxiv.org/abs/2404.06395
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [27]
-
[28]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. d. l. Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M.-A. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed. Mixtral of Experts, Jan. 2024. UR...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
KellerJordan. New Record: Multi-token prediction and Untie LM Head 2/3rds through training (119.76 seconds) by varunneal · Pull Request #178 · KellerJordan/modded-nanogpt. URL https://github.com/KellerJordan/modded-nanogpt/pull/178
- [30]
-
[31]
T. Kudo and J. Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. InProceedings of the 2018 conference on empirical methods in natural language processing: System demonstrations, pages 66–71. 12
work page 2018
- [32]
-
[33]
Y . Leviathan, M. Kalman, and Y . Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofICML’23, pages 19274–19286, Honolulu, Hawaii, USA, 2023. JMLR.org
work page 2023
-
[34]
J. Li, A. Fang, G. Smyrnis, M. Ivgi, M. Jordan, S. Gadre, H. Bansal, E. Guha, S. Keh, K. Arora, S. Garg, R. Xin, N. Muennighoff, R. Heckel, J. Mercat, M. Chen, S. Gururan- gan, M. Wortsman, A. Albalak, Y . Bitton, M. Nezhurina, A. Abbas, C.-Y . Hsieh, D. Ghosh, J. Gardner, M. Kilian, H. Zhang, R. Shao, S. Pratt, S. Sanyal, G. Ilharco, G. Daras, K. Marathe...
work page 2024
-
[35]
W. Liang, T. Liu, L. Wright, W. Constable, A. Gu, C.-C. Huang, I. Zhang, W. Feng, H. Huang, J. Wang, S. Purandare, G. Nadathur, and S. Idreos. TorchTitan: One-stop PyTorch native solution for production ready LLM pretraining. Oct. 2024. URLhttps://openreview. net/forum?id=SFN6Wm7YBI
work page 2024
-
[36]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, and others. Deepseek-v3 technical report
-
[37]
A. Liu, J. Hayase, V . Hofmann, S. Oh, N. A. Smith, and Y . Choi. SuperBPE: Space travel for language models
-
[38]
H. Liu, J. Zhang, C. Wang, X. Hu, L. Lyu, J. Sun, X. Yang, B. Wang, F. Li, Y . Qian, and others. Scaling embeddings outperforms scaling experts in language models
- [39]
-
[40]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
A. Lozhkov, L. Ben Allal, L. von Werra, and T. Wolf. Fineweb-edu: the finest collection of educational content, 2024. URLhttps://huggingface.co/datasets/HuggingFaceFW/ fineweb-edu
work page 2024
-
[42]
H. P. Luhn. The Automatic Creation of Literature Abstracts.IBM Journal of Research and Development, 2(2):159–165, Apr. 1958. ISSN 0018-8646. doi: 10.1147/rd.22.0159. URL https://ieeexplore.ieee.org/document/5392672. Conference Name: IBM Journal of Research and Development
-
[43]
D. Mahajan, S. Goyal, B. Y . Idrissi, M. Pezeshki, I. Mitliagkas, D. Lopez-Paz, and K. Ahuja. Beyond Multi-Token Prediction: Pretraining LLMs with Future Summaries, Oct. 2025. URL http://arxiv.org/abs/2510.14751. arXiv:2510.14751 [cs]
-
[44]
T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2381–2391, 2018
work page 2018
-
[45]
T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient Estimation of Word Repre- sentations in Vector Space. Jan. 2013. URLhttps://www.semanticscholar.org/ paper/Efficient-Estimation-of-Word-Representations-in-Mikolov-Chen/ f6b51c8753a871dc94ff32152c00c01e94f90f09
work page 2013
-
[46]
B. Minixhofer, T. Murray, T. Limisiewicz, A. Korhonen, L. Zettlemoyer, N. A. Smith, E. M. Ponti, L. Soldaini, and V . Hofmann. Bolmo: Byteifying the Next Generation of Language Models, Dec. 2025. URLhttp://arxiv.org/abs/2512.15586. arXiv:2512.15586 [cs]. 13
-
[47]
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J.-R. Wen, and C. Li. Large Language Diffusion Models. Oct. 2025. URLhttps://openreview.net/forum? id=KnqiC0znVF
work page 2025
-
[48]
A. Pagnoni, R. Pasunuru, P. Rodriguez, J. Nguyen, B. Muller, M. Li, C. Zhou, L. Yu, J. E. We- ston, L. Zettlemoyer, G. Ghosh, M. Lewis, A. Holtzman, and S. Iyer. Byte Latent Transformer: Patches Scale Better Than Tokens. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, edi- tors,Proceedings of the 63rd Annual Meeting of the Association for Computati...
-
[49]
K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y . Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
work page 2021
-
[50]
R. Sennrich, B. Haddow, and A. Birch. Neural machine translation of rare words with sub- word units. InProceedings of the 54th annual meeting of the association for computational linguistics (volume 1: long papers), pages 1715–1725
-
[51]
C. E. Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
work page 1948
-
[52]
C. Shao, F. Meng, and J. Zhou. Beyond next token prediction: Patch-level training for large language models. InThe Thirteenth International Conference on Learning Representations,
-
[53]
URLhttps://openreview.net/forum?id=dDpB23VbVa
-
[54]
K. Sparck Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 28(1):11–21, 1972
work page 1972
-
[55]
Y . Tay, M. Dehghani, V . Q. Tran, X. Garcia, J. Wei, X. Wang, H. W. Chung, D. Bahri, T. Schus- ter, S. Zheng, D. Zhou, N. Houlsby, and D. Metzler. UL2: Unifying Language Learning Paradigms. Sept. 2022. URLhttps://openreview.net/forum?id=6ruVLB727MC
work page 2022
-
[56]
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, and others. Llama: Open and efficient foundation language models
- [57]
-
[58]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Mod- els. Oct. 2022. URLhttps://openreview.net/forum?id=_VjQlMeSB_J&trk=public_ post_comment-text
work page 2022
- [59]
-
[60]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, and others. Qwen3 technical report
-
[61]
J. Yuan, H. Gao, D. Dai, J. Luo, L. Zhao, Z. Zhang, Z. Xie, Y . Wei, L. Wang, Z. Xiao, Y . Wang, C. Ruan, M. Zhang, W. Liang, and W. Zeng. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention. In W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computatio...
-
[62]
M. Zaheer, G. Guruganesh, A. Dubey, J. Ainslie, C. Alberti, S. Ontanon, P. Pham, A. Ravula, Q. Wang, L. Yang, and A. Ahmed. Big bird: transformers for longer sequences. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, pages 17283–17297, Red Hook, NY , USA, 2020. Curran Associates Inc. ISBN 978-1-7138- ...
-
[63]
R. Zellers, A. Holtzman, Y . Bisk, A. Farhadi, and Y . Choi. Hellaswag: Can a machine re- ally finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
work page 2019
-
[64]
Y . Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer, A. Desmaison, C. Balioglu, P. Damania, B. Nguyen, G. Chauhan, Y . Hao, A. Math- ews, and S. Li. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel.Proc. VLDB Endow., 16(12):3848–3860, 2023. ISSN 2150-8097. doi: 10.14778/3611540.3611569. URL...
-
[65]
Proxy Compression for Language Modeling
L. Zheng, X. Li, Q. Liu, X. Feng, and L. Kong. Proxy Compression for Language Modeling, Feb. 2026. URLhttp://arxiv.org/abs/2602.04289. arXiv:2602.04289 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
R.-J. Zhu, Z. Wang, K. Hua, T. Zhang, Z. Li, H. Que, B. Wei, Z. Wen, F. Yin, H. Xing, and others. Scaling latent reasoning via looped language models
-
[67]
Z. M. K. Zuhri, E. H. Fuadi, and A. F. Aji. Predicting the Order of Upcoming Tokens Improves Language Modeling, Feb. 2026. URLhttp://arxiv.org/abs/2508.19228. arXiv:2508.19228 [cs]. 15 A Code 1 2[...] # within train loop 3 4if s u p e r p o s i t i o n _ b a g _ s i z e is not None and s u p e r p o s i t i o n _ b a g _ s i z e > 1: 5bs , seq = inputs . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.