Beyond the Black Box: Interpretability of Agentic AI Tool Use
Pith reviewed 2026-05-22 10:50 UTC · model grok-4.3
The pith
Sparse autoencoders decompose activations before each step to reveal whether an agent will need a tool and how consequential the call is likely to be.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that sparse autoencoders applied to pre-action activations can isolate features tied to tool necessity and consequence, that linear probes can read those features to predict upcoming decisions, and that targeted ablation can demonstrate the features' causal contribution to the agent's tool-use behavior.
What carries the argument
Sparse autoencoders that factorize activations into sparse, human-interpretable features, paired with linear probes that associate those features with tool-use labels and consequence scores, then validated by feature ablation.
If this is right
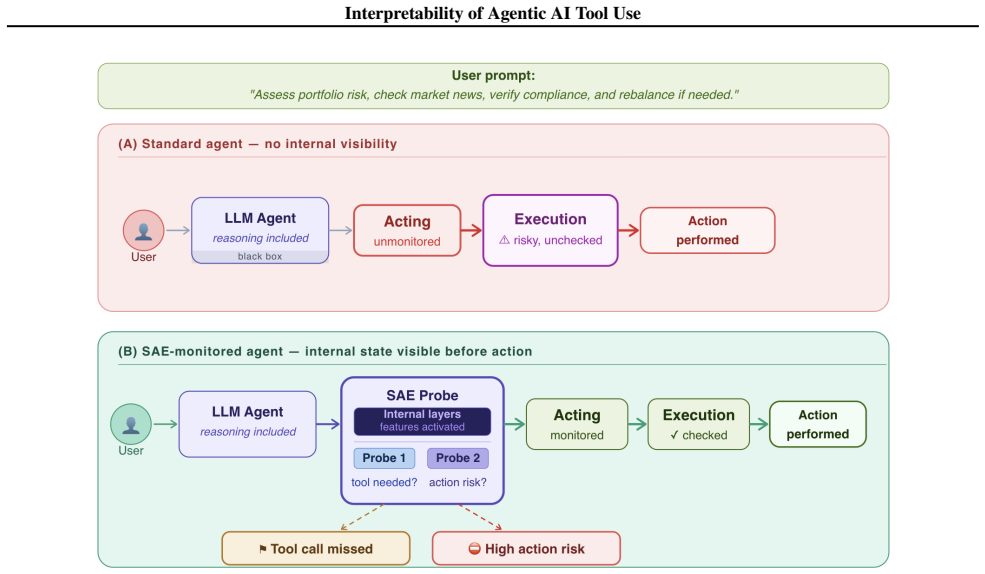
- Internal monitoring can flag likely tool mistakes before execution begins to alter the rest of the agent trajectory.
- Visibility into feature importance supplies causal explanations for failures that external logs arrive too late to explain.
- The same decomposition and ablation workflow can be reused across different models to maintain consistent observability.
- Early identification of high-consequence tool actions supports safer deployment in long-horizon enterprise tasks.
Where Pith is reading between the lines
- If the identified features prove stable, one could explore editing them at inference time to steer the agent away from unnecessary or risky tool calls.
- The method suggests a route for embedding mechanistic checks directly into agent runtime monitoring rather than relying only on post-run audits.
- Generalization tests on agent tasks that differ in domain or length from the training trajectories would clarify the scope of the signals.
Load-bearing premise
Activations immediately before a tool decision contain detectable and causally relevant signals about tool need and impact that sparse autoencoders and probes can isolate.
What would settle it
If ablating the features flagged by the probes produces no measurable shift in the agent's rate or accuracy of tool calls on held-out trajectories, the claimed causal link would be undermined.
Figures
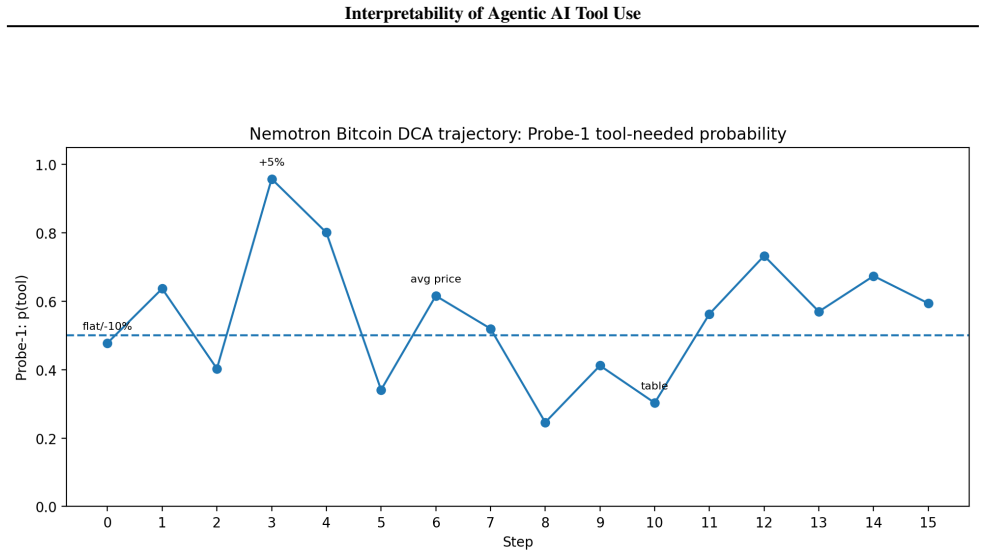
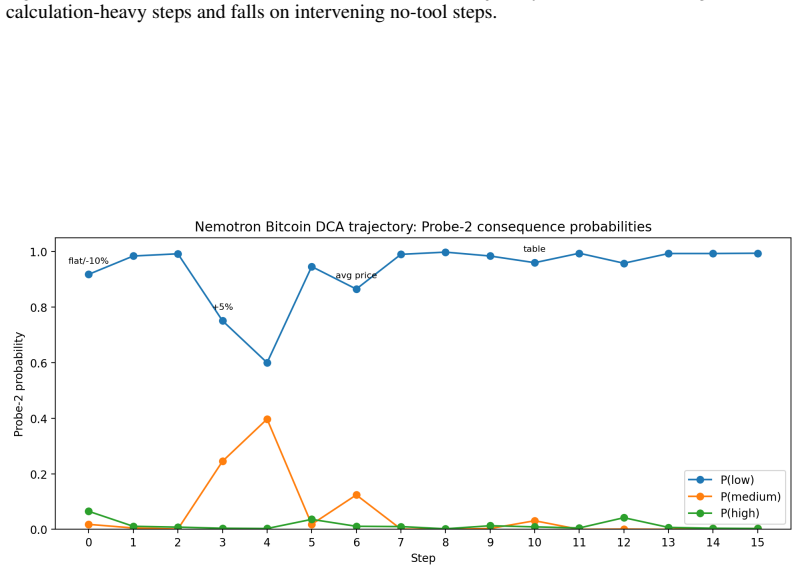
read the original abstract
AI agents are promising for high-stakes enterprise workflows, but dependable deployment remains limited because tool-use failures are difficult to diagnose and control. Agents may skip required tool calls, invoke tools unnecessarily, or take actions whose consequence becomes visible only after execution. Existing observability methods are external: prompts reveal correlations, evaluations score outputs, and logs arrive only after the model has already acted. In long-horizon settings, these failures are costly because an early tool mistake can alter the rest of the trajectory, increase token consumption, and create downstream safety and security risk. We introduce a mechanistic-interpretability toolkit built on Sparse Autoencoders (SAEs), which decompose activations into sparse internal features, and linear probes, lightweight classifiers that read signals from those features. The framework reads model states before each action and infers whether a tool is needed and how risky the next tool action is. It identifies the model layers and features most associated with tool decisions and tests their functional importance through feature ablation. We train the probes on multi-step trajectories from the NVIDIA Nemotron function-calling dataset and apply the same workflow to GPT-OSS 20B and Gemma 3 27B models. The goal is not to replace external evaluation, but to add a missing layer: visibility into what the model signaled internally before action. This helps surface deeper causes of agent failure, especially in long-horizon runs where an early mistake can impact subsequent agent behavior. More broadly, the paper shows how mechanistic interpretability can support internal observability for monitoring tool calls and risk in agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a mechanistic interpretability toolkit based on Sparse Autoencoders (SAEs) and linear probes that reads model activations immediately prior to tool-use decisions in AI agents. It decomposes these activations to identify features associated with tool necessity and consequence, validates functional importance via ablation, and trains the components on multi-step trajectories from the NVIDIA Nemotron function-calling dataset before applying the workflow to GPT-OSS 20B and Gemma 3 27B.
Significance. If the empirical results hold, the work would supply a concrete internal-observability layer for agentic systems that complements external logging and evaluation. By surfacing pre-action signals for tool decisions and risk, it could help diagnose early failures that propagate in long-horizon trajectories and thereby support safer deployment in enterprise settings.
major comments (2)
- [Abstract and §3] Abstract and §3 (Methods): The manuscript describes the SAE decomposition, probe training, and ablation protocol but reports no quantitative outcomes—neither probe accuracy nor F1 on tool-necessity detection, nor the magnitude of performance change after feature ablation. Without these metrics the central claim that the framework “identifies the internal layers and features most associated with tool decisions” cannot be evaluated.
- [§4] §4 (Experiments): The text states that the same workflow is applied to GPT-OSS 20B and Gemma 3 27B yet supplies no per-model results, layer-wise feature rankings, or cross-model comparisons. This omission leaves the generalization claim untested and prevents assessment of whether the detected signals are model-specific or robust.
minor comments (2)
- [§2] Notation for “consequence” is introduced informally; a short formal definition or equation would clarify how the scalar is computed from the probe output.
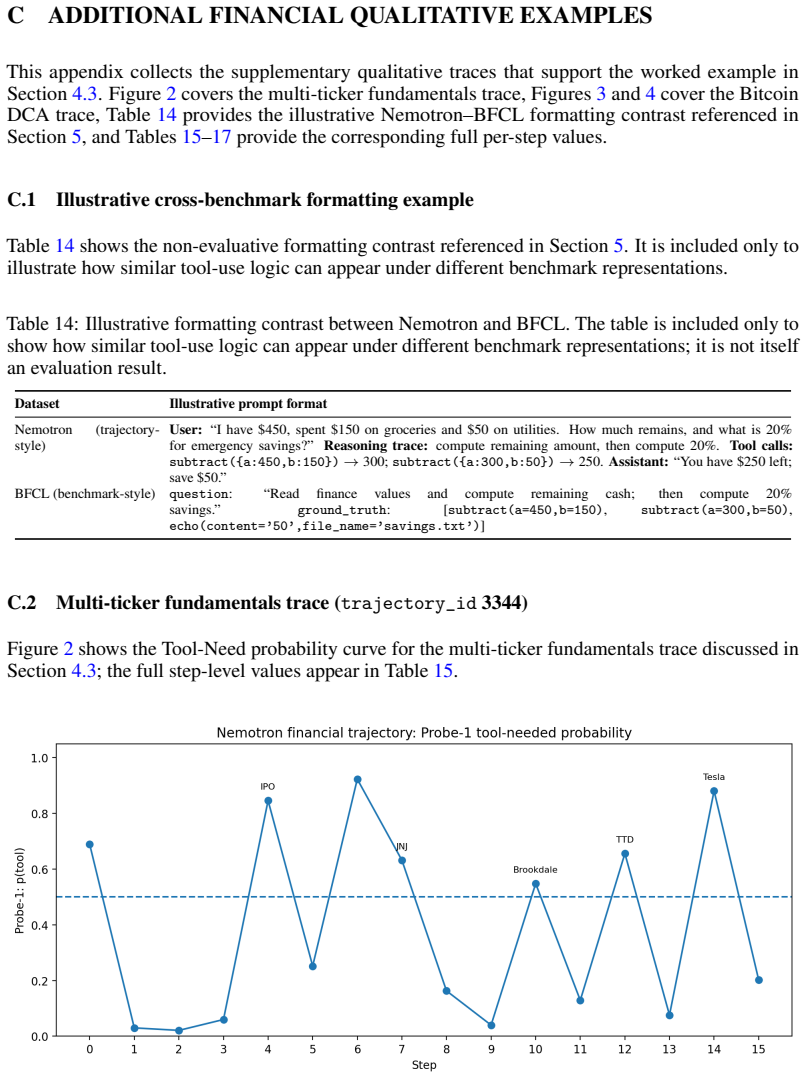
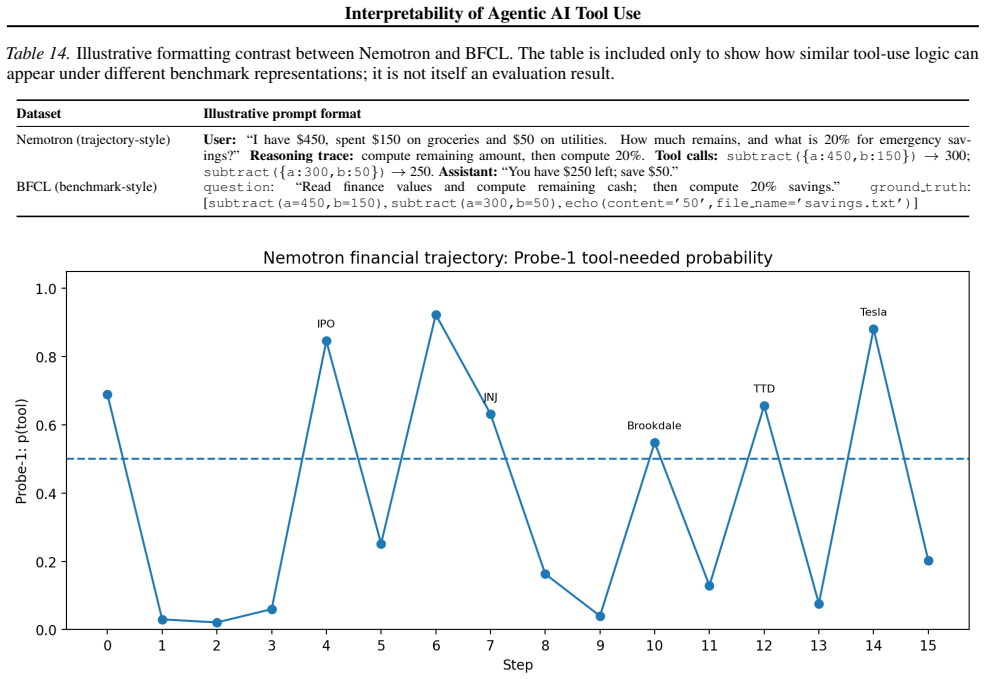
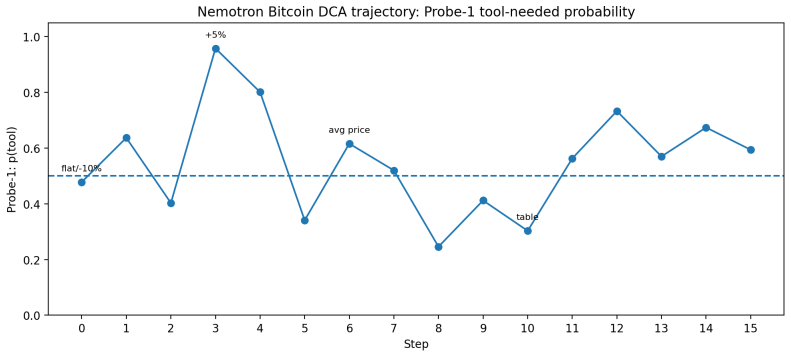
- [Figures] Figure captions should explicitly state the number of trajectories, the SAE sparsity level, and the probe regularization strength so that readers can reproduce the setup from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The observations accurately note the lack of quantitative results needed to evaluate the framework's claims. We will revise the manuscript accordingly to include these metrics and comparisons.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Methods): The manuscript describes the SAE decomposition, probe training, and ablation protocol but reports no quantitative outcomes—neither probe accuracy nor F1 on tool-necessity detection, nor the magnitude of performance change after feature ablation. Without these metrics the central claim that the framework “identifies the internal layers and features most associated with tool decisions” cannot be evaluated.
Authors: We agree that quantitative metrics are required to substantiate the central claims. The revised manuscript will report probe accuracy and F1 scores for tool-necessity detection on held-out trajectories from the NVIDIA Nemotron dataset. We will also include the magnitude of performance degradation (e.g., change in tool-use success rate) after ablating the identified features, with appropriate controls and statistical reporting. These results were obtained during our experiments but were not presented in the initial submission. revision: yes
-
Referee: [§4] §4 (Experiments): The text states that the same workflow is applied to GPT-OSS 20B and Gemma 3 27B yet supplies no per-model results, layer-wise feature rankings, or cross-model comparisons. This omission leaves the generalization claim untested and prevents assessment of whether the detected signals are model-specific or robust.
Authors: We accept this criticism. The revised §4 will present per-model results for both GPT-OSS 20B and Gemma 3 27B, including layer-wise rankings of the top SAE features and probe weights associated with tool necessity and consequence. A new comparative subsection will summarize similarities and differences across the two models to evaluate robustness of the detected signals. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a mechanistic interpretability framework that applies standard Sparse Autoencoders and linear probes to pre-action model activations for detecting tool necessity and consequence in agentic workflows. It trains these components on the NVIDIA Nemotron function-calling dataset and evaluates on GPT-OSS 20B and Gemma 3 27B. No equations, parameter fits presented as predictions, self-citation load-bearing arguments, uniqueness theorems, or ansatz smuggling are described in the abstract or high-level claims. The derivation chain consists of empirical application of existing interpretability techniques rather than any reduction to inputs by construction. The approach remains self-contained against external benchmarks and common practice in the field.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.