Recognition: no theorem link
Rethinking Experience Utilization in Self-Evolving Language Model Agents
Pith reviewed 2026-05-11 02:00 UTC · model grok-4.3
The pith
Self-evolving agents perform better when experience is an optional resource they can invoke only when needed during reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Modifying only the runtime utilization strategy by exposing accumulated experience as an optional input during each decision step, without altering experience construction, enables agents to invoke it selectively at beneficial points and under higher reasoning uncertainty, producing consistent performance gains across frameworks, backbones, and environments, with additional gains when the selective behavior is reinforced through training.
What carries the argument
ExpWeaver, a lightweight change that inserts experience as an optional resource in the agent's reasoning prompt so the underlying LLM can decide whether to use it for the current step.
If this is right
- Agents achieve higher task success by invoking experience only at decision points where it provides clear value.
- Rigid always-use or never-use strategies can be outperformed by letting the model weigh the need for experience itself.
- Reinforcement learning can further train the selective invocation behavior without changing experience storage.
- Usage and entropy analyses show selective calls align with moments of higher uncertainty and beneficial context.
- The same optional-resource pattern can be applied inside existing agent frameworks without redesigning memory modules.
Where Pith is reading between the lines
- Designers of future agents may need explicit mechanisms for deciding when to consult any form of stored knowledge, not just experience.
- The selective-use idea could extend to optional tool calls or external memory lookups, letting models avoid unnecessary overhead.
- Training objectives that reward appropriate timing of memory use might become a standard part of agent optimization.
- Environments with high variance in decision difficulty may see the largest gains from making experience optional.
Load-bearing premise
The base language models can decide on their own when to consult the exposed experience in a way that improves outcomes rather than introducing new errors or hesitation.
What would settle it
A new set of tasks or an untested LLM backbone in which the selective-use agents complete fewer goals than agents that always receive experience at every step.
Figures



















read the original abstract
Self-evolving agents improve by accumulating and reusing experience from past interactions. Existing work has largely focused on how experience is constructed, represented, and updated, while paying less attention to how experience should be used during runtime decision-making. As a result, most agents rely on rigid usage strategies, either injecting experience once at initialization or at every step, without considering whether it is needed for the current decision. This paper studies experience utilization as a critical design dimension of self-evolving agents. We ask whether agents benefit from interweaving experience use with decision-making, so that experience is invoked only when additional guidance is needed. To examine this question, we introduce {ExpWeaver}, a lightweight instantiation that leaves experience construction unchanged and modifies only runtime utilization by exposing experience as an optional resource during reasoning. Across four representative frameworks, seven LLM backbones, and three types of environments, ExpWeaver consistently achieves the best performance among different utilization strategies. Reinforcement learning experiments further show that this behavior can be amplified through training. Usage-pattern, causal ablation, and entropy-based analyses reveal that ExpWeaver enables agents to invoke experience selectively, at beneficial decision points, and under higher reasoning uncertainty. Overall, our findings call for a shift from merely studying \emph{what} experience to store toward understanding \emph{how} and \emph{when} experience should enter decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that rigid experience utilization strategies in self-evolving LLM agents (e.g., injecting experience at initialization or every step) are suboptimal, and introduces ExpWeaver as a lightweight alternative that exposes experience as an optional resource during reasoning to enable selective invocation. Across four frameworks, seven LLM backbones, and three environment types, ExpWeaver yields the best performance; this is supported by usage-pattern analysis, causal ablations, entropy-based analysis showing invocation at high-uncertainty beneficial points, and RL experiments indicating the behavior can be amplified via training.
Significance. If the empirical results hold, the work is significant for reframing experience utilization as a first-class design choice in self-evolving agents, independent of how experience is constructed or represented. The breadth of evaluation (multiple frameworks/backbones/environments) plus the mechanistic analyses (usage, ablation, entropy) provide concrete evidence that selective invocation improves outcomes without new failure modes, offering a practical and generalizable insight for agent design.
minor comments (3)
- The main results tables would benefit from explicit reporting of standard deviations or confidence intervals alongside mean performance to allow readers to assess the reliability of the 'consistent best' claim across the 4×7×3 experimental grid.
- Section 3 (method) describes the optional-resource exposure but does not include a concise pseudocode or decision diagram; adding one would clarify the exact runtime modification relative to the rigid baselines.
- The entropy analysis in the experiments section could more explicitly link the reported entropy values to the decision points where experience is actually invoked, perhaps via a supplementary correlation plot.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work on selective experience utilization in self-evolving agents, as well as for the recommendation of minor revision. The assessment correctly identifies the core contribution of treating experience as an optional, selectively invoked resource rather than a rigid always-on or initialization-only component, along with the breadth of evaluation and supporting analyses.
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The manuscript introduces ExpWeaver as a runtime utilization strategy and evaluates it through controlled experiments across frameworks, backbones, and environments. No equations, derivations, or fitted parameters appear in the provided text; performance claims rest on direct comparisons, ablations, usage-pattern logs, and entropy measurements rather than any self-referential definition or prediction that reduces to its own inputs. Self-citations, if present, are not load-bearing for the central empirical result. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can effectively reason about whether to invoke experience based on the current decision context when it is exposed as an optional resource.
invented entities (1)
-
ExpWeaver
no independent evidence
Reference graph
Works this paper leans on
-
[1]
You MUST output ONLY ONE command per turn (either one "think" OR one action, never both at once)
-
[2]
Follow this simple rule to decide what to output: - If the LAST message is an observation (from environment): output "> think: [reasoning]" - If the LAST message is your own think: output an environment action (e.g., "> go to cabinet 1")
-
[3]
> think: xxx > go to cabinet 1
DO NOT output multiple commands in one response (e.g., do NOT write "> think: xxx > go to cabinet 1")
-
[4]
DO NOT output consecutive "think" steps without an action in between
-
[5]
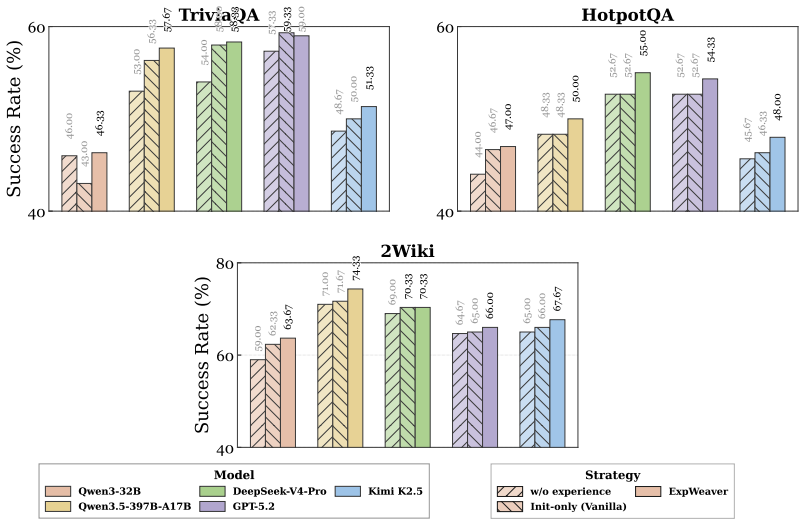
You must check carefully that your output is exactly ONE of the allowed commands above!!! You may take maximum of [MAX_STEPS] steps. Here are some examples: [FEWSHOTS] (END OF EXAMPLES) Now it's your turn! [TASK GOAL] ALFWorld Figure 7: System prompt on ALFWorld. and 2Wiki, further confirming the effectiveness of interweaving experience utilization into t...
-
[6]
Output ONLY ONE action per turn
-
[7]
NEVER output two Thoughts in a row — a Thought must be immediately followed by an Action
-
[8]
Use Lookup[keyword] to extract specific details from a page you searched
-
[9]
Call Finish[answer] as soon as you have enough information to answer. You may take maximum of [MAX_STEPS] steps. Here are some examples: [FEWSHOTS] (END OF EXAMPLES) Now it's your turn! [TASK GOAL] QA Figure 8: System prompt on QA tasks. Under SkillRL, we observe similar trends despite the different form of experience. Since SkillRL uses a pre-constructed...
-
[10]
You MUST output ONLY ONE command per turn
-
[11]
After each think (or think[RETRIEVE] + retrieved memory), output a search or click action
-
[12]
Start with a targeted search using key product attributes from the instruction
-
[13]
On the search results page, you must first click Back to Search before executing a new search[...]; otherwise, it will return an Invalid action error
-
[14]
So please MIND your max_steps limitation
You won't get any score if you don't buy any item. So please MIND your max_steps limitation. if you purchase any item, you will get a score of range from 0.0 to 1.0 according to the similarity between the item and the instruction. You may take maximum of [MAX_STEPS] steps. Here are some examples: [FEWSHOTS] (END OF EXAMPLES) Now it's your turn! [TASK GOAL...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.