Accelerating Zeroth-Order Spectral Optimization with Partial Orthogonalization from Power Iteration
Pith reviewed 2026-05-19 17:29 UTC · model grok-4.3
The pith
Partial orthogonalization via power iteration accelerates zeroth-order fine-tuning of large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Partial spectral orthogonalization obtained by substituting power iteration for Newton-Schulz, performed inside a momentum-projected subspace, stabilizes the search and exploits weak spectral directions effectively even when gradients are estimated only through function queries.
What carries the argument
Streaming power-iteration procedure for partial orthogonalization inside a momentum-derived subspace, which concentrates amplification on dominant directions while lowering variance enough for reliable zeroth-order use.
If this is right
- Convergence speed improves 1.5x to 4x over ZO-Muon on SuperGlue datasets with OPT-13B.
- Final accuracies remain competitive with MeZO, LOZO, and ZO-Muon while using less wall-clock time across tested models.
- The streaming variant reduces per-step cost once the momentum subspace is formed.
- The method works for hidden-layer training where spectral methods normally outperform AdamW-style updates.
Where Pith is reading between the lines
- The same variance-reduction trick via momentum projection could be paired with other low-dimensional ZO estimators beyond spectral methods.
- Testing the approach on models larger than 13B would show whether the relative speedup grows with parameter count.
- The partial-orthogonalization idea may transfer to other noisy non-convex settings such as reinforcement learning with only reward queries.
Load-bearing premise
Projecting the search onto a momentum-derived subspace lowers gradient variance enough to stabilize the streaming power-iteration and permit useful partial orthogonalization despite noisy zeroth-order estimates.
What would settle it
Remove the momentum-subspace projection step and measure whether power-iteration diverges or convergence speed drops back to ZO-Muon levels on the same OPT-13B SuperGlue fine-tuning runs.
Figures













read the original abstract
Zeroth-order (ZO) optimization has become increasingly popular and important in fine-tuning large language models (LLMs), especially on edge devices due to its ability to adjust the model to local data without the need for memory-intensive back-propagation. Recent works try to reduce ZO variance through low-dimensional subspace search, but subspace restriction alone leaves key optimization geometry under-exploited, motivating additional acceleration. In this work, we focus on the hidden layer training problem in which spectral optimizers like Muon outperform AdamW due to its ability to exploit weak spectral directions by orthogonalization. However, we have discovered that unlike in the first-order setting, full orthogonalization works poorly in the ZO setting since the gradient estimates are highly noisy and unreliable. To address this issue, we propose applying partial spectral orthogonalization to accelerate ZO optimization. To do so, we replace the iconic Newton-Schulz procedure in Muon with the faster, more concentrated power-iteration method so that it only amplifies dominant spectral directions. Furthermore, to improve the efficiency and generalization of the algorithm, we adopted a streaming variant of power-iteration that requires low variance in gradients, which was achieved through constraining our search inside a subspace obtained through the projection of momentum, echoing recent advances. Experiments on LLM fine-tuning show that our method can achieve from 1.5x to 4x the convergence speed of ZO-Muon, the current SOTA algorithm, across SuperGlue datasets in the OPT-13B model. Across different models, we also reach competitive final accuracies with less time in most cases compared with strong ZO baselines such as MeZO, LOZO and ZO-Muon. Code is available at https://github.com/MOFA-LAB/ZO-MOPI.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an algorithm for zeroth-order optimization in LLM fine-tuning that replaces full spectral orthogonalization (Newton-Schulz in Muon) with partial orthogonalization via power iteration to better handle noisy ZO gradient estimates. It further adopts a streaming power-iteration variant whose stability is achieved by projecting onto a momentum-derived subspace. Experiments report 1.5x–4x faster convergence than ZO-Muon on SuperGlue tasks using OPT-13B, along with competitive final accuracies versus MeZO, LOZO, and ZO-Muon baselines. Code is released publicly.
Significance. If the reported speedups are shown to be robust, the work could meaningfully improve memory-efficient ZO fine-tuning by exploiting spectral geometry under noise. The public code release aids reproducibility.
major comments (2)
- Abstract and streaming-variant paragraph: the claim that momentum-subspace projection sufficiently lowers ZO gradient variance to stabilize streaming power iteration is load-bearing for attributing speedups to partial orthogonalization, yet no variance measurements, spectrum concentration analysis, or ablation isolating this projection effect are provided; because momentum is itself built from noisy ZO estimates, the reported 1.5–4× gains cannot yet be confidently linked to the proposed mechanism rather than other factors.
- Experimental results section: speedups are stated without error bars, run-to-run variance, or ablation on the partial-orthogonalization degree / power-iteration count, weakening the central empirical claim that the method reliably outperforms ZO-Muon across datasets and models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important gaps in empirical validation that we agree need to be addressed to strengthen the link between the proposed mechanism and the observed speedups. We respond to each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: Abstract and streaming-variant paragraph: the claim that momentum-subspace projection sufficiently lowers ZO gradient variance to stabilize streaming power iteration is load-bearing for attributing speedups to partial orthogonalization, yet no variance measurements, spectrum concentration analysis, or ablation isolating this projection effect are provided; because momentum is itself built from noisy ZO estimates, the reported 1.5–4× gains cannot yet be confidently linked to the proposed mechanism rather than other factors.
Authors: We agree that the manuscript would be strengthened by direct evidence linking the momentum-subspace projection to variance reduction and stabilization of the streaming power iteration. The original submission motivates the projection by noting that it constrains the search to a lower-variance subspace derived from momentum estimates, but does not quantify this effect or isolate its contribution via ablation. In the revised version we will add (i) measurements of ZO gradient variance before and after momentum projection, (ii) spectrum concentration analysis showing how the projection affects the eigenvalue distribution seen by power iteration, and (iii) an ablation that removes the projection while keeping all other components fixed. These additions will allow a clearer attribution of the reported gains to the proposed mechanism. revision: yes
-
Referee: Experimental results section: speedups are stated without error bars, run-to-run variance, or ablation on the partial-orthogonalization degree / power-iteration count, weakening the central empirical claim that the method reliably outperforms ZO-Muon across datasets and models.
Authors: We acknowledge that the absence of error bars and hyperparameter ablations limits the strength of the empirical claims. The reported 1.5×–4× speedups were obtained from single runs per configuration, which is insufficient to assess run-to-run variability. In the revision we will rerun the SuperGLUE experiments on OPT-13B (and the additional model scales) with at least five independent random seeds, reporting mean convergence curves with standard-error bars. We will also add a dedicated ablation section that varies the number of power iterations (e.g., 1, 2, 4) and the degree of partial orthogonalization (truncation threshold) while measuring both wall-clock time and final accuracy, thereby demonstrating robustness across these design choices. revision: yes
Circularity Check
No significant circularity; derivation is procedural and empirically validated
full rationale
The paper defines its core contribution procedurally: replacing Newton-Schulz with power iteration for partial orthogonalization in the zeroth-order regime, combined with a streaming variant that projects onto a momentum-derived subspace to reduce gradient variance. These steps are presented as algorithmic choices motivated by empirical observations about noise in ZO estimates, not as mathematical derivations that reduce the claimed 1.5x–4x speedup to a fitted constant, self-referential prediction, or self-citation chain. Performance results are reported from direct experiments on SuperGlue with OPT-13B and comparisons to MeZO, LOZO, and ZO-Muon; no equations or uniqueness theorems are invoked that loop back to the paper's own inputs or prior unverified work by the same authors. The method is self-contained against external benchmarks via code release and empirical testing.
Axiom & Free-Parameter Ledger
free parameters (1)
- partial orthogonalization degree or power-iteration count
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constraining our search inside a subspace obtained through the projection of momentum
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dion: Distributed Orthonormalized Updates
Kwangjun Ahn, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295,
-
[2]
Yiming Chen, Yuan Zhang, Liyuan Cao, Kun Yuan, and Zaiwen Wen. Enhancing zeroth-order fine-tuning for language models with low-rank structures.arXiv preprint arXiv:2410.07698,
-
[3]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), ...
work page 2019
-
[4]
arXiv preprint arXiv:2404.08080 , year=
Tanmay Gautam, Youngsuk Park, Hao Zhou, Parameswaran Raman, and Wooseok Ha. Variance- reduced zeroth-order methods for fine-tuning language models.arXiv preprint arXiv:2404.08080,
-
[5]
URLhttps://arxiv.org/abs/2602.09006. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[6]
Spectra: Rethinking optimizers for llms under spectral anisotropy.arXiv preprint arXiv:2602.11185,
Zhendong Huang, Hengjie Cao, Fang Dong, Ruijun Huang, Mengyi Chen, Yifeng Yang, Xin Zhang, Anrui Chen, Mingzhi Dong, Yujiang Wang, et al. Spectra: Rethinking optimizers for llms under spectral anisotropy.arXiv preprint arXiv:2602.11185,
-
[7]
Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan
10 Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan. github. io/posts/muon, 6(3):4,
work page 2024
-
[8]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2602.17155 , year=
Yicheng Lang, Changsheng Wang, Yihua Zhang, Mingyi Hong, Zheng Zhang, Wotao Yin, and Sijia Liu. Powering up zeroth-order training via subspace gradient orthogonalization.arXiv preprint arXiv:2602.17155,
-
[10]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025a. Liming Liu, Zhenghao Xu, Zixuan Zhang, Hao Kang, Zichong Li, Chen Liang, Weizhu Chen, and Tuo Zhao. Cosmos: A hybrid adaptive optimizer for memory-efficien...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yong Liu, Zirui Zhu, Chaoyu Gong, Minhao Cheng, Cho-Jui Hsieh, and Yang You. Sparse mezo: Less parameters for better performance in zeroth-order llm fine-tuning.arXiv preprint arXiv:2402.15751,
-
[12]
arXiv preprint arXiv:2506.04430 , year=
URLhttps://api.semanticscholar.org/CorpusID:16577977. Egor Petrov, Grigoriy Evseev, Aleksey Antonov, Andrey Veprikov, Nikolay Bushkov, Stanislav Moiseev, and Aleksandr Beznosikov. Leveraging coordinate momentum in signsgd and muon: Memory-optimized zero-order.arXiv preprint arXiv:2506.04430,
-
[13]
Wic: the word-in-context dataset for evaluating context-sensitive meaning representations
Mohammad Taher Pilehvar and Jose Camacho-Collados. Wic: the word-in-context dataset for evaluating context-sensitive meaning representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1267–1273,
work page 2019
-
[14]
Squad: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 2383–2392,
work page 2016
-
[15]
Multitask Prompted Training Enables Zero-Shot Task Generalization
Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. Multitask prompted training enables zero-shot task generalization.arXiv preprint arXiv:2110.08207,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Refining adaptive zeroth-order optimization at ease.arXiv preprint arXiv:2502.01014,
Yao Shu, Qixin Zhang, Kun He, and Zhongxiang Dai. Refining adaptive zeroth-order optimization at ease.arXiv preprint arXiv:2502.01014,
-
[17]
Recursive deep models for semantic compositionality over a sentiment treebank
11 Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642,
work page 2013
-
[18]
Gemma 2: Improving Open Language Models at a Practical Size
theory, Apr 2026b. URL https://kexue.fm/archives/11710. Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhu- patiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size, 2024.URL https://arxiv. org/abs/2408.00118, 1(3),
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Yihua Zhang, Pingzhi Li, Junyuan Hong, Jiaxiang Li, Yimeng Zhang, Wenqing Zheng, Pin-Yu Chen, Jason D Lee, Wotao Yin, Mingyi Hong, et al. Revisiting zeroth-order optimization for memory-efficient llm fine-tuning: A benchmark.arXiv preprint arXiv:2402.11592,
-
[22]
Yanjun Zhao, Sizhe Dang, Haishan Ye, Guang Dai, Yi Qian, and Ivor W Tsang. Second-order fine-tuning without pain for llms: A hessian informed zeroth-order optimizer.arXiv preprint arXiv:2402.15173,
-
[23]
12 A Analysis of Subspace Power Iteration In Section 4, for computational efficiency, we operate the Streaming Power Iteration (SPI) in the reduced subspace rather than the full parameter space. In this section, we establish that this projection- based SPI is equivalent to its full-space counterpart. Our analysis is inspired by the proof of Proposition 1 ...
work page 2026
-
[24]
We compare our method with ZO baselines through fine-tuning OPT-13B on SST-2 (Wang et al., 2019; Zhang et al., 2022). Our method reaches the highest accuracy of 91.7%, with almost the same wall-clock time and slightly additional memory usage. These results show that our method achieves a better accuracy performance without the requirement of extra memory ...
work page 2019
-
[25]
to ensure the same total query budget with other baselines. For LoRA (Malladi et al., 2023), 17 0 100 200 300 400 500 Wall-Clock Time (s) 60 65 70 75 80 85 90Accuracy (%) k=8 k=16 k=32 k=64 0 100 200 300 400 500 Wall-Clock Time (s) 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0Train Loss k=8 k=16 k=32 k=64 (a) Accuracy vs. wall-clock time (b) Training loss vs. wall-...
work page 2023
-
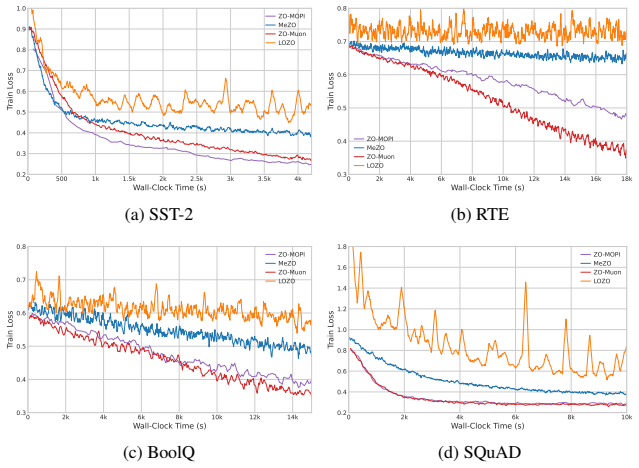
[26]
Additional Experiment ResultsFigures 9 through 13 illustrate the training dynamics of OPT-13B, LLaMA3-8B, and Gemma2-2B on SuperGLUE (Wang et al., 2019; Zhang et al., 2022; Team et al., 2024; Grattafiori et al., 2024). Notably, the accuracy-vs-time curves demonstrate a much steeper con- vergence trend than existing ZO baselines across most tasks, which cl...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.