Contrastive Learning under Noisy Temporal Self-Supervision for Colonoscopy Videos
Pith reviewed 2026-05-20 22:25 UTC · model grok-4.3
The pith
A noise-aware contrastive loss turns noisy temporal links in colonoscopy videos into representations that match foundation models on polyp tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that a noise-aware contrastive loss, designed to tolerate incorrect positive pairs arising from temporal self-supervision, produces polyp representations that outperform prior self-supervised and supervised baselines and match or exceed recent foundation models on polyp retrieval, re-identification, size estimation, and histology classification, all with a lightweight encoder trained on 27 videos.
What carries the argument
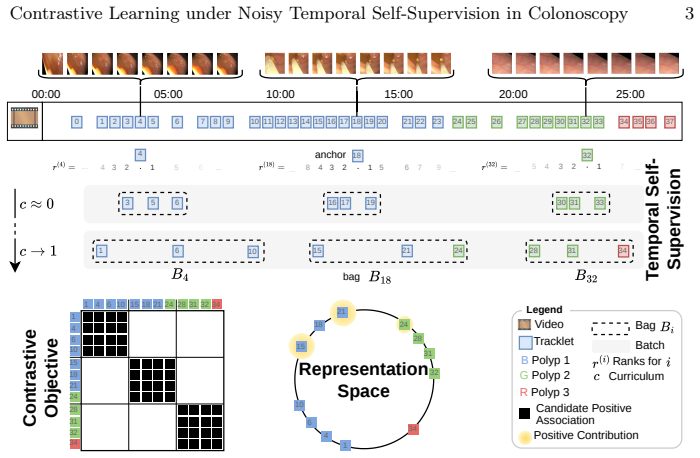
The noise-aware contrastive loss, which adjusts the standard contrastive objective to discount the contribution of temporally derived positive pairs that are likely to be incorrect.
If this is right
- Representations learned this way directly enable polyp retrieval and re-identification without manual tracklet linking.
- The same features support size estimation and histology classification as additional downstream tasks.
- Training on a small set of 27 videos suffices to reach performance levels comparable to recent foundation models.
- Self-supervised temporal signals can substitute for expert-labeled associations in video-based medical tasks.
Where Pith is reading between the lines
- The same noise-tolerant loss could be tested on other sequential medical video domains where timing provides noisy but informative signals.
- If the approach scales, clinics could train custom polyp models on their own small video archives without large labeled datasets.
- The method suggests that explicit noise modeling may be more important than sheer data volume when learning from procedural sequences.
Load-bearing premise
Temporally derived associations still contain enough correct positive-pair signal that the noise-aware loss can recover useful representations.
What would settle it
A controlled test in which temporal associations are replaced by fully random pairings and the method no longer outperforms a standard contrastive baseline on the same downstream tasks.
Figures

read the original abstract
Learning robust representations of polyp tracklets is key to enabling multiple AI-assisted colonoscopy applications, from polyp characterization to automated reporting and retrieval. Supervised contrastive learning is an effective approach for learning such representations, but it typically relies on correct positive and negative definitions. Collecting these labels requires linking tracklets that depict the same underlying polyp entity throughout the video, which is costly and demands specialized clinical expertise. In this work, we leverage the sequential workflow of colonoscopy procedures to derive self-supervised associations from temporal structure. Since temporally derived associations are not guaranteed to be correct, we introduce a noise-aware contrastive loss to account for noisy associations. We demonstrate the effectiveness of the learned representations across multiple downstream tasks, including polyp retrieval and re-identification, size estimation, and histology classification. Our method outperforms prior self-supervised and supervised baselines, and matches or exceeds recent foundation models across all tasks, using a lightweight encoder trained on only 27 videos. Code is available at https://github.com/lparolari/ntssl.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a self-supervised contrastive learning method for polyp tracklets in colonoscopy videos. It derives positive-pair associations from the sequential workflow of procedures and introduces a noise-aware contrastive loss to mitigate incorrect temporal matches. The learned representations from a lightweight encoder trained on 27 videos are evaluated on four downstream tasks (polyp retrieval, re-identification, size estimation, histology classification), where the approach is reported to outperform prior self-supervised and supervised baselines while matching or exceeding recent foundation models. Code is released.
Significance. If the central claims hold, the work demonstrates that noisy temporal self-supervision can yield competitive representations for medical video analysis with very limited data and no expert labels. This could reduce annotation costs in colonoscopy AI applications. The code release is a clear strength that supports reproducibility and further testing of the noise-aware loss.
major comments (3)
- [Section 3.2] Section 3.2 (noise-aware contrastive loss): the exact formulation of the loss, including any noise-rate parameter, weighting scheme, or estimation procedure for handling incorrect temporal positives, is not provided with sufficient quantitative detail or pseudocode. This is load-bearing for the claim that the loss recovers useful signal from noisy associations.
- [Section 4] Section 4 (experiments): no ablation is reported on synthetic or measured noise levels in the temporal associations (e.g., fraction of correct same-polyp positives), nor on how performance degrades when this fraction falls below 0.4–0.5. Without such analysis, the outperformance on the four tasks cannot be confidently attributed to the noise-aware loss rather than other factors.
- [Section 4, Tables 1–3] Section 4, Tables 1–3: performance metrics lack error bars, standard deviations across runs, or statistical significance tests. This weakens the reliability of the reported gains over baselines and foundation models, especially given the small training set of 27 videos.
minor comments (2)
- [Abstract] Abstract: the statement that the method 'matches or exceeds recent foundation models' should name the specific models and the tasks/metrics on which it exceeds them.
- [Figure 1] Figure 1: the workflow diagram would benefit from an explicit example of a noisy temporal positive pair to illustrate the problem the loss is designed to address.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (noise-aware contrastive loss): the exact formulation of the loss, including any noise-rate parameter, weighting scheme, or estimation procedure for handling incorrect temporal positives, is not provided with sufficient quantitative detail or pseudocode. This is load-bearing for the claim that the loss recovers useful signal from noisy associations.
Authors: We agree that the current description of the noise-aware contrastive loss would benefit from greater quantitative detail. In the revised manuscript we will expand Section 3.2 to include the complete loss equation with the explicit noise-rate parameter, the per-pair weighting scheme derived from temporal consistency scores, and the procedure used to down-weight likely incorrect positives. We will also add pseudocode for the loss computation as a new figure or in the supplementary material. revision: yes
-
Referee: [Section 4] Section 4 (experiments): no ablation is reported on synthetic or measured noise levels in the temporal associations (e.g., fraction of correct same-polyp positives), nor on how performance degrades when this fraction falls below 0.4–0.5. Without such analysis, the outperformance on the four tasks cannot be confidently attributed to the noise-aware loss rather than other factors.
Authors: We acknowledge the value of this analysis. While direct measurement of the true positive fraction in the real data would require additional expert labels (which we deliberately avoided), we can and will perform a controlled synthetic ablation. In the revised Section 4 we will inject varying levels of label noise into the temporal positive pairs (0.1 to 0.7) and report downstream performance for both the standard and noise-aware losses, explicitly showing behavior below the 0.4–0.5 threshold. revision: yes
-
Referee: [Section 4, Tables 1–3] Section 4, Tables 1–3: performance metrics lack error bars, standard deviations across runs, or statistical significance tests. This weakens the reliability of the reported gains over baselines and foundation models, especially given the small training set of 27 videos.
Authors: We agree that reporting variability is important given the modest training set size. In the revision we will retrain the model five times with different random seeds, report mean and standard deviation for all metrics in Tables 1–3, and add error bars to the corresponding figures. Where appropriate we will also include paired statistical significance tests against the strongest baselines. revision: yes
Circularity Check
No circularity; derivation self-contained via novel loss and external validation
full rationale
The paper proposes a noise-aware contrastive loss to handle noisy temporal associations derived from colonoscopy video sequences. This formulation is presented as a direct modeling choice to account for imperfect positive pairs, with effectiveness shown via empirical results on separate downstream tasks (polyp retrieval, re-identification, size estimation, histology classification) using a lightweight encoder on 27 videos. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the central claims rest on independent benchmarks rather than internal redefinitions. The unquantified noise rate is a correctness assumption, not a circularity in the derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Temporally adjacent frames in a colonoscopy video are likely to depict the same polyp entity even if the link is sometimes incorrect.
- standard math A contrastive loss can be modified to down-weight noisy positive pairs while still producing useful embeddings.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a noise-aware contrastive loss to account for noisy associations... L=−∑i log[∑k exp(s(zik,yi)) / (∑k exp(s(zik,yi)) + ∑j≠i ∑k exp(s(zik,yj)) ) ]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Lancet Digital Health4(6), e436–e444 (2022)
Areia, M., Mori, Y., Correale, L., Repici, A., Bretthauer, M., Sharma, P., Taveira, F., et al.: Cost-effectiveness of artificial intelligence for screening colonoscopy: A modelling study. The Lancet Digital Health4(6), e436–e444 (2022)
work page 2022
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Komeili, M., Muckley, M.J., Rizvi, A., et al.: V-JEPA 2: Self-supervised video models enable understand- ing, prediction and planning. arXiv preprint arXiv:2506.09985 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Barbano, C.A., Dufumier, B., Tartaglione, E., Grangetto, M., Gori, P.: Unbiased supervised contrastive learning. In: ICLR (2023)
work page 2023
-
[4]
Batic, D., Holm, F., Özsoy, E., Czempiel, T., Navab, N.: EndoViT: Pretraining visiontransformersonalargecollectionofendoscopicimages.InternationalJournal of Computer Assisted Radiology and Surgery19(6), 1085–1091 (2024)
work page 2024
-
[5]
In: In- ternational Conference on Machine Learning
Bengio, Y., Louradour, J., Collobert, R., Weston, J.: Curriculum learning. In: In- ternational Conference on Machine Learning. pp. 41–48 (2009)
work page 2009
-
[6]
Scientific Data11(1), 539 (2024)
Biffi, C., Antonelli, G., Bernhofer, S., Hassan, C., Hirata, D., Iwatate, M., Maieron, A., Salvagnini, P., Cherubini, A.: REAL-Colon: A dataset for developing real-world AI applications in colonoscopy. Scientific Data11(1), 539 (2024)
work page 2024
-
[7]
In: International Conference on Machine Learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: International Conference on Machine Learning. pp. 1597–1607 (2020)
work page 2020
-
[8]
In: Association for Compu- tational Linguistics
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of deep bidirectional transformers for language understanding. In: Association for Compu- tational Linguistics. pp. 4171–4186 (2019)
work page 2019
-
[9]
In: International Conference on Learning Representations (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations (2021)
work page 2021
-
[10]
Dufumier, B., Barbano, C.A., Louiset, R., Duchesnay, E., Gori, P.: Integrating Prior Knowledge in Contrastive Learning with Kernel. In: ICML (2023)
work page 2023
-
[11]
Gastrointestinal Endoscopy93(1), 77–85 (2021) 10 L
Hassan, C., Spadaccini, M., Iannone, A., Maselli, R., Jovani, M., Chandrasekar, V.T., Antonelli, G., Yu, H., Areia, M., et al.: Performance of artificial intelligence in colonoscopy for adenoma and polyp detection: A systematic review and meta- analysis. Gastrointestinal Endoscopy93(1), 77–85 (2021) 10 L. Parolari et al
work page 2021
-
[12]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9729–9738 (2020)
work page 2020
-
[13]
In: Conference on Computer Vision and Pattern Recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Conference on Computer Vision and Pattern Recognition. pp. 770–778 (2016)
work page 2016
-
[14]
Gaussian Error Linear Units (GELUs)
Hendrycks, D., Gimpel, K.: Gaussian error linear units. In: arXiv preprint arXiv:1606.08415 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
Intrator, Y., Aizenberg, N., Livne, A., Rivlin, E., Goldenberg, R.: Self-supervised polypre-identificationincolonoscopy.In:MedicalImageComputingandComputer Assisted Intervention. pp. 590–600 (2023)
work page 2023
-
[16]
Medical Image Analysis108, 103873 (2026)
Jaspers, T.J.M., de Jong, R.L.P.D., Li, Y., Kusters, C.H.J., Bakker, F.H.A., van Jaarsveld, R.C., Kuiper, G.M., van Hillegersberg, R., Ruurda, J.P., Brinkman, W.M., Pluim, J.P.W., et al.: Scaling up self-supervised learning for improved sur- gical foundation models. Medical Image Analysis108, 103873 (2026)
work page 2026
-
[17]
International Journal of Automa- tion and Computing19(6), 531–549 (2022)
Ji, G.P., Xiao, G., Chou, Y.C., Fan, D.P., Zhao, K., Chen, G., Gool, L.V.: Video polyp segmentation: A deep learning perspective. International Journal of Automa- tion and Computing19(6), 531–549 (2022)
work page 2022
-
[18]
In: Advances in Neural Information Processing Systems (2020)
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. In: Advances in Neural Information Processing Systems (2020)
work page 2020
-
[19]
PLoS One16(8), e0255809 (2021)
Li, K., Fathan, M.I., Patel, K., Zhang, T., Zhong, C., Bansal, A., Rastogi, A., Wang, J.S., Wang, G.: Colonoscopy polyp detection and classification: Dataset creation and comparative evaluations. PLoS One16(8), e0255809 (2021)
work page 2021
-
[20]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
work page 2019
-
[21]
In: Conference on Computer Vision and Pattern Recognition
Miech, A., Alayrac, J.B., Smaira, L., Laptev, I., Sivic, J., Zisserman, A.: End- to-end learning of visual representations from uncurated instructional videos. In: Conference on Computer Vision and Pattern Recognition. pp. 9876–9886 (2020)
work page 2020
-
[22]
Gastrointestinal Endoscopy93(4), 960–967 (2021)
Misawa, M., ei Kudo, S., Mori, Y., Hotta, K., Ohtsuka, K., Matsuda, T., Saito, S., Kudo, T., Baba, T., Ishida, F., et al.: Development of a computer-aided detection system for colonoscopy and a publicly accessible large colonoscopy video database. Gastrointestinal Endoscopy93(4), 960–967 (2021)
work page 2021
-
[23]
Neuro- computing423, 721–734 (2021)
Nogueira-Rodríguez, A., Domínguez-Carbajales, R., López-Fernández, H., Águeda Iglesias, Cubiella, J., Fdez-Riverola, F., Reboiro-Jato, M., Glez-Peña, D.: Deep neural networks approaches for detecting and classifying colorectal polyps. Neuro- computing423, 721–734 (2021)
work page 2021
-
[24]
Transactions on Machine Learning Research2024(2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., et al.: DINOv2: Learning robust visual features with- out supervision. Transactions on Machine Learning Research2024(2024)
work page 2024
-
[25]
In: Medical Image Computing and Computer Assisted Intervention (2025)
Parolari, L., Cherubini, A., Ballan, L., Biffi, C.: Temporally-aware supervised con- trastive learning for polyp counting in colonoscopy. In: Medical Image Computing and Computer Assisted Intervention (2025)
work page 2025
-
[26]
In: IEEE International Symposium on Biomedical Imaging
Parolari, L., Cherubini, A., Ballan, L., Biffi, C.: Towards polyp counting in full- procedure colonoscopy videos. In: IEEE International Symposium on Biomedical Imaging. pp. 1–5 (2025)
work page 2025
-
[27]
Sekiguchi, M., Mizuguchi, Y., Kawagoe, R., Saito, Y.: Artificial intelligence and its impact on the quality of endoscopy reports. Digestive Endoscopy38(1), e70057 (2026) Contrastive Learning under Noisy Temporal Self-Supervision in Colonoscopy 11
work page 2026
-
[28]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S.E., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Scientific Data12(1), 918 (2025)
Song, Y., Du, S., Wang, R., Liu, F., Lin, X., Chen, J., Li, Z., Li, Z., Yang, L., Zhang, Z., Yan, H., Zhang, Q., Qian, D., Li, X.: Polyp-Size: A precise endoscopic dataset for AI-driven polyp sizing. Scientific Data12(1), 918 (2025)
work page 2025
-
[30]
Advances in Neural Information Processing Systems30(2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez,A.N.,Łukasz Kaiser, Polosukhin, I.: Attention is all you need. Advances in Neural Information Processing Systems30(2017)
work page 2017
-
[31]
In: Medical Image Computing and Computer Assisted Intervention
Wang, Z., Liu, C., Zhang, S., Dou, Q.: Foundation model for endoscopy video analysis via large-scale self-supervised pre-train. In: Medical Image Computing and Computer Assisted Intervention. pp. 101–111 (2023)
work page 2023
-
[32]
IEEE Journal of Biomedical and Health Informatics29(5), 3526–3536 (2025)
Wang, Z., Liu, C., Zhu, L., Wang, T., Zhang, S., Dou, Q.: Improving foundation model for endoscopy video analysis via representation learning on long sequences. IEEE Journal of Biomedical and Health Informatics29(5), 3526–3536 (2025)
work page 2025
-
[33]
In: IEEE International Conference on Acoustics, Speech and Signal Processing
Xiang, S., Liu, C., Ruan, J., Cai, S., Du, S., Qian, D.: VT-ReID: Learning discrimi- native visual-text representation for polyp re-identification. In: IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 3170–3174 (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.