FuTCR: Future-Targeted Contrast and Repulsion for Continual Panoptic Segmentation
Pith reviewed 2026-05-20 22:16 UTC · model grok-4.3
The pith
FuTCR improves new-class panoptic quality by up to 28% in continual segmentation by discovering future-like regions and repelling background features from known prototypes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
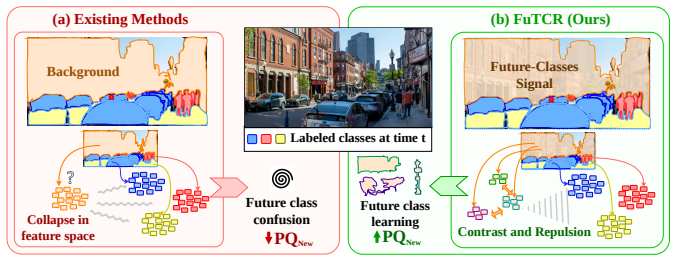
Core claim
FuTCR discovers confident future-like regions by grouping model-predicted masks whose pixels are consistently classified as background but exhibit non-background logits. It then applies pixel-to-region contrast to build coherent prototypes from these unlabeled regions, while simultaneously repelling background features away from known-class prototypes to explicitly reserve representational space for future categories.
What carries the argument
Discovery of confident future-like regions followed by pixel-to-region contrast and repulsion of background features from known-class prototypes.
Load-bearing premise
Model-predicted masks whose pixels are consistently classified as background but exhibit non-background logits reliably correspond to regions belonging to future categories that will be introduced later.
What would settle it
If the discovered regions fail to match the actual new classes when those classes are added, or if ablating the future-targeted contrast and repulsion steps removes the reported gains on new-class panoptic quality, the mechanism would not hold.
Figures






read the original abstract
Continual Panoptic Segmentation (CPS) requires methods that can quickly adapt to new categories over time. The nature of this dense prediction task means that training images may contain a mix of labeled and unlabeled objects. As nothing is known about these unlabeled objects a priori, existing methods often simply group any unlabeled pixel into a single "background" class during training. In effect, during training, they repeatedly tell the model that all the different background categories are the same (even when they aren't). This makes learning to identify different background categories as they are added challenging since these new categories may require using information the model was previously told was unimportant and ignored. Thus, we propose a Future-Targeted Contrastive and Repulsive (FuTCR) framework that addresses this limitation by restructuring representations before new classes are introduced. FuTCR first discovers confident future-like regions by grouping model-predicted masks whose pixels are consistently classified as background but exhibit non-background logits. Next, FuTCR applies pixel-to-region contrast to build coherent prototypes from these unlabeled regions, while simultaneously repelling background features away from known-class prototypes to explicitly reserve representational space for future categories. Experiments across six CPS settings and a range of dataset sizes show FuTCR improves relative new-class panoptic quality over the state-of-the-art by up to 28%, while preserving or improving base-class performance with gains up to 4%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the FuTCR framework for continual panoptic segmentation. It identifies confident future-like regions by grouping pixels predicted as background but with non-background logits, then uses pixel-to-region contrast to build prototypes from these regions and repels background features from known-class prototypes to reserve space for future categories. Across six experimental settings, it claims relative improvements in new-class panoptic quality of up to 28% over prior state-of-the-art while maintaining or enhancing base-class performance by up to 4%.
Significance. If the discovery step reliably isolates future-class regions rather than uncertainties, FuTCR would provide a concrete mechanism for proactively structuring representations in CPS to accommodate unlabeled objects that later become new classes. The multi-setting experiments and reported relative gains suggest the approach could improve adaptability in dense prediction tasks, with the explicit repulsion term offering a clear way to reserve representational capacity.
major comments (1)
- [Abstract and §3.2] Abstract (discovery step) and §3.2: The central claim attributes up to 28% relative new-class PQ gains to the future-targeting effect of grouping background-classified pixels that exhibit non-background logits. This step assumes such regions predominantly contain pixels from classes that will be introduced later, yet the same logit pattern arises from epistemic uncertainty at base-class boundaries, rare intra-class variants, or non-future unlabeled objects. No quantitative validation (e.g., overlap statistics with held-out future ground truth or ablation that disables the discovery module) is provided, so the performance attribution remains unconfirmed.
minor comments (3)
- [§3.3] §3.3: The pixel-to-region contrast and repulsion losses are described at a high level but lack explicit equations or hyperparameter schedules, making exact reproduction difficult.
- [§4] §4: Tables reporting PQ metrics should include standard deviations over multiple runs and p-values for the claimed improvements to establish statistical reliability.
- [Figure 2] Figure 2: The visualization of discovered regions would benefit from side-by-side ground-truth overlays to illustrate the composition of the selected pixels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential impact. We address the major comment point by point below and commit to revisions that directly strengthen the validation of the discovery mechanism.
read point-by-point responses
-
Referee: [Abstract and §3.2] Abstract (discovery step) and §3.2: The central claim attributes up to 28% relative new-class PQ gains to the future-targeting effect of grouping background-classified pixels that exhibit non-background logits. This step assumes such regions predominantly contain pixels from classes that will be introduced later, yet the same logit pattern arises from epistemic uncertainty at base-class boundaries, rare intra-class variants, or non-future unlabeled objects. No quantitative validation (e.g., overlap statistics with held-out future ground truth or ablation that disables the discovery module) is provided, so the performance attribution remains unconfirmed.
Authors: We agree that explicit quantitative validation of the discovered regions would provide stronger confirmation that the performance gains stem specifically from future-targeting rather than other factors such as uncertainty reduction. In the standard CPS protocol, future-class labels are unavailable during training, which precludes direct overlap statistics with held-out ground truth without altering the evaluation protocol. The manuscript instead relies on consistent relative gains of up to 28% across six diverse settings, together with the design of the contrast and repulsion terms, as indirect support. To address the concern directly, we will add (i) an ablation that disables the discovery module entirely (treating all background pixels uniformly) and reports the resulting drop in new-class PQ, and (ii) additional analysis of logit distributions and qualitative examples to characterize the discovered regions relative to boundary uncertainty. These revisions will be incorporated in the next version. revision: yes
Circularity Check
No significant circularity in FuTCR method derivation
full rationale
The paper presents FuTCR as an empirical framework that first identifies candidate future-like regions via a heuristic on current model outputs (background-classified pixels with non-background logits), then applies pixel-to-region contrast and prototype repulsion. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that would make the reported PQ gains equivalent to the inputs by construction. The central claims rest on experimental results across multiple CPS settings rather than a closed logical loop, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pixels consistently predicted as background but showing non-background logits form coherent regions that correspond to future object categories.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FuTCR applies pixel-to-region contrast ... Lreg = −1/N Σ log exp(sim(fn,pr(n))/τ) / Σ exp(sim(fn,pk)/τ) ... Lrep = 1/|Iunlb| Σ max(0, su,c⋆(u)−γ)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
discovers confident future-like regions by grouping model-predicted masks whose pixels are consistently classified as background but exhibit non-background logits
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ferret: An efficient online continual learning framework under varying memory constraints
Yuhao Zhou, Yuxin Tian, Jindi Lv, Mingjia Shi, Yuanxi Li, Qing Ye, Shuhao Zhang, and Jiancheng Lv. Ferret: An efficient online continual learning framework under varying memory constraints. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4850–4861, 2025
work page 2025
-
[2]
Do your best and get enough rest for continual learning
Hankyul Kang, Gregor Seifer, Donghyun Lee, and Jongbin Ryu. Do your best and get enough rest for continual learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10077–10086, 2025
work page 2025
-
[3]
End-to-end incremental learning
Francisco M Castro, Manuel J Marín-Jiménez, Nicolás Guil, Cordelia Schmid, and Karteek Alahari. End-to-end incremental learning. InProceedings of the European conference on computer vision (ECCV), pages 233–248, 2018
work page 2018
-
[4]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
work page 2001
-
[5]
Riemannian walk for incremental learning: Understanding forgetting and intransigence
Arslan Chaudhry, Puneet K Dokania, Thalaiyasingam Ajanthan, and Philip HS Torr. Riemannian walk for incremental learning: Understanding forgetting and intransigence. InProceedings of the European conference on computer vision (ECCV), pages 532–547, 2018
work page 2018
-
[6]
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay.Advances in neural information processing systems, 30, 2017
work page 2017
-
[7]
Der: Dynamically expandable representation for class incremental learning
Shipeng Yan, Jiangwei Xie, and Xuming He. Der: Dynamically expandable representation for class incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3014–3023, 2021
work page 2021
-
[8]
Few-shot class-incremental learning
Xiaoyu Tao, Xiaopeng Hong, Xinyuan Chang, Songlin Dong, Xing Wei, and Yihong Gong. Few-shot class-incremental learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12183–12192, 2020
work page 2020
-
[9]
Vector quantization prompting for continual learning
Li Jiao, Qiuxia Lai, Yu Li, and Qiang Xu. Vector quantization prompting for continual learning. Advances in Neural Information Processing Systems, 37:34056–34076, 2024
work page 2024
-
[10]
Liyuan Wang, Kuo Yang, Chongxuan Li, Lanqing Hong, Zhenguo Li, and Jun Zhu. Ordisco: Effective and efficient usage of incremental unlabeled data for semi-supervised continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5383–5392, 2021
work page 2021
-
[11]
PAC-bayes bounds for cumulative loss in continual learning
Lior Friedman and Ron Meir. PAC-bayes bounds for cumulative loss in continual learning. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=hWw269fPov
work page 2026
-
[12]
Bors, Jingling Sun, Rongyao Hu, and Shijie Zhou
Fei Ye, Yulong Zhao, Qihe Liu, Junlin Chen, Adrian G. Bors, Jingling Sun, Rongyao Hu, and Shijie Zhou. Dynamic siamese expansion framework for improving robustness in online continual learning. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[13]
Exploiting task relationships in continual learning via transferability-aware task embeddings
Yanru Wu, Jianning Wang, Xiangyu Chen, Enming Zhang, Yang Tan, Hanbing Liu, and Yang Li. Exploiting task relationships in continual learning via transferability-aware task embeddings. InAdvances in Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=V8FnYzDX35
work page 2025
-
[14]
Anacp: Toward upper-bound continual learning via analytic contrastive projection
Saleh Momeni, Changnan Xiao, and Bing Liu. Anacp: Toward upper-bound continual learning via analytic contrastive projection. InAdvances in Neural Information Processing Systems,
-
[15]
URLhttps://openreview.net/forum?id=qQbvLU34F1
-
[16]
Hippotune: A hippocampal associative loop–inspired fine-tuning method for continual learning
chenyanxi, Xiuxing Li, Han Yuyang, Zhuo Wang, Qing Li, Ziyu Li, Xiang Li, Chen Wei, and Xia Wu. Hippotune: A hippocampal associative loop–inspired fine-tuning method for continual learning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=MtDiLnnYgm. 10
work page 2026
-
[17]
Ze Yang, Shichao Dong, Ruibo Li, Nan Song, and Guosheng Lin. ADAPT: Attentive self- distillation and dual-decoder prediction fusion for continual panoptic segmentation. InThe Thirteenth International Conference on Learning Representations, 2025. URL https:// openreview.net/forum?id=HF1UmIVv6a
work page 2025
-
[18]
Beyond background shift: Rethinking instance replay in continual semantic segmentation
Hongmei Yin, Tingliang Feng, Fan Lyu, Fanhua Shang, Hongying Liu, Wei Feng, and Liang Wan. Beyond background shift: Rethinking instance replay in continual semantic segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9839–9848, 2025
work page 2025
-
[19]
Thanh-Dat Truong, Utsav Prabhu, Bhiksha Raj, Jackson Cothren, and Khoa Luu. Falcon: Fairness learning via contrastive attention approach to continual semantic scene understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15065– 15075, 2025
work page 2025
-
[20]
Continual gaussian mixture distribution modeling for class incremental semantic segmentation
Guilin Zhu, Runmin Wang, Yuanjie Shao, Wei dong Yang, Nong Sang, and Changxin Gao. Continual gaussian mixture distribution modeling for class incremental semantic segmentation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=dtYKDOBkc7
work page 2025
-
[21]
Parameter release and knowledge reuse for class-incremental semantic segmentation, 2025
Xinyue Zhang, Xu Zou, Liqun Chen, Jiahuan Zhou, Guodong Wang, Sheng Zhong, and Luxin Yan. Parameter release and knowledge reuse for class-incremental semantic segmentation, 2025. URLhttps://openreview.net/forum?id=9qbKOaF8YJ
work page 2025
-
[22]
Combo: Conflict mitigation via branched optimization for class incremental segmentation
Kai Fang, Anqi Zhang, Guangyu Gao, Jianbo Jiao, Chi Harold Liu, and Yunchao Wei. Combo: Conflict mitigation via branched optimization for class incremental segmentation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 25667–25676, 2025
work page 2025
-
[23]
Continual semantic segmentation with automatic memory sample selection
Lanyun Zhu, Tianrun Chen, Jianxiong Yin, Simon See, and Jun Liu. Continual semantic segmentation with automatic memory sample selection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3082–3092, 2023
work page 2023
-
[24]
Rethinking query-based transformer for continual image segmentation
Yuchen Zhu, Cheng Shi, Dingyou Wang, Jiajin Tang, Zhengxuan Wei, Yu Wu, Guanbin Li, and Sibei Yang. Rethinking query-based transformer for continual image segmentation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4595–4606, 2025
work page 2025
-
[25]
Contrastive grouping with transformer for referring image segmentation
Jiajin Tang, Ge Zheng, Cheng Shi, and Sibei Yang. Contrastive grouping with transformer for referring image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 23570–23580, 2023
work page 2023
-
[26]
Cheng Shi and Sibei Yang. The devil is in the object boundary: Towards annotation-free instance segmentation using foundation models.arXiv preprint arXiv:2404.11957, 2024
-
[27]
Coinseg: Contrast inter-and intra-class representations for incremental segmentation
Zekang Zhang, Guangyu Gao, Jianbo Jiao, Chi Harold Liu, and Yunchao Wei. Coinseg: Contrast inter-and intra-class representations for incremental segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 843–853, 2023
work page 2023
-
[28]
Towards continual universal segmentation
Zihan Lin, Zilei Wang, and Xu Wang. Towards continual universal segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 29417–29427, June 2025
work page 2025
-
[29]
Eclipse: Efficient continual learning in panoptic segmentation with visual prompt tuning
Beomyoung Kim, Joonsang Yu, and Sung Ju Hwang. Eclipse: Efficient continual learning in panoptic segmentation with visual prompt tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3346–3356, 2024
work page 2024
-
[30]
Comformer: Continual learning in semantic and panoptic segmentation
Fabio Cermelli, Matthieu Cord, and Arthur Douillard. Comformer: Continual learning in semantic and panoptic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3010–3020, 2023
work page 2023
-
[31]
Strike a balance in continual panoptic segmentation
Jinpeng Chen, Runmin Cong, Yuxuan Luo, Horace Ho Shing Ip, and Sam Kwong. Strike a balance in continual panoptic segmentation. InEuropean Conference on Computer Vision, pages 126–142. Springer, 2024. 11
work page 2024
-
[32]
Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raf- fel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi- supervised learning with consistency and confidence.Advances in neural information processing systems, 33:596–608, 2020
work page 2020
-
[33]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[34]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
work page 2020
-
[35]
Classmix: Segmentation-based data augmentation for semi-supervised learning
Viktor Olsson, Wilhelm Tranheden, Juliano Pinto, and Lennart Svensson. Classmix: Segmentation-based data augmentation for semi-supervised learning. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1369–1378, 2021
work page 2021
-
[36]
Preparing the future for continual semantic segmenta- tion
Zihan Lin, Zilei Wang, and Yixin Zhang. Preparing the future for continual semantic segmenta- tion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11910–11920, 2023
work page 2023
-
[37]
Bo Yuan, Danpei Zhao, Zhuoran Liu, Wentao Li, and Tian Li. Continual panoptic perception: Towards multi-modal incremental interpretation of remote sensing images. InProceedings of the 32nd ACM International Conference on Multimedia, pages 2117–2126, 2024
work page 2024
-
[38]
Sungmin Cha, YoungJoon Yoo, Taesup Moon, et al. Ssul: Semantic segmentation with unknown label for exemplar-based class-incremental learning.Advances in neural information processing systems, 34:10919–10930, 2021
work page 2021
-
[39]
Vista-clip: Visual incre- mental self-tuned adaptation for efficient continual panoptic segmentation
D Manjunath, Shrikar Madhu, Aniruddh Sikdar, and Suresh Sundaram. Vista-clip: Visual incre- mental self-tuned adaptation for efficient continual panoptic segmentation. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 6557–
-
[40]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
work page 1999
-
[41]
Catastrophic forgetting, rehearsal and pseudorehearsal.Connection Science, 7 (2):123–146, 1995
Anthony Robins. Catastrophic forgetting, rehearsal and pseudorehearsal.Connection Science, 7 (2):123–146, 1995
work page 1995
-
[42]
Sebastian Thrun. Lifelong learning algorithms. InLearning to learn, pages 181–209. Springer, 1998
work page 1998
-
[43]
Bo Yuan and Danpei Zhao. A survey on continual semantic segmentation: Theory, challenge, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[44]
Mitigating background shift in class-incremental semantic segmentation
Gilhan Park, WonJun Moon, SuBeen Lee, Tae-Young Kim, and Jae-Pil Heo. Mitigating background shift in class-incremental semantic segmentation. InEuropean Conference on Computer Vision, pages 71–88. Springer, 2024
work page 2024
-
[45]
Modeling the background for incremental learning in semantic segmentation
Fabio Cermelli, Massimiliano Mancini, Samuel Rota Bulo, Elisa Ricci, and Barbara Caputo. Modeling the background for incremental learning in semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9233–9242, 2020
work page 2020
-
[46]
KIT Scientific Publishing, 2024
Tobias Michael Kalb.Principles of Catastrophic Forgetting for Continual Semantic Segmenta- tion in Automated Driving. KIT Scientific Publishing, 2024
work page 2024
-
[47]
Continual semantic segmentation via structure preserving and projected feature alignment
Zihan Lin, Zilei Wang, and Yixin Zhang. Continual semantic segmentation via structure preserving and projected feature alignment. InEuropean Conference on Computer Vision, pages 345–361. Springer, 2022
work page 2022
-
[48]
Zichen Song, Xiaoliang Zhang, and Zhaofeng Shi. Scale-hybrid group distillation with knowl- edge disentangling for continual semantic segmentation.Sensors, 23(18):7820, 2023. 12
work page 2023
-
[49]
Bacs: Background aware continual semantic segmentation.arXiv preprint arXiv:2404.13148, 2024
Mostafa ElAraby, Ali Harakeh, and Liam Paull. Bacs: Background aware continual semantic segmentation.arXiv preprint arXiv:2404.13148, 2024
-
[50]
Yuxuan Luo, Jinpeng Chen, Runmin Cong, Horace Ho Shing Ip, and Sam Kwong. Trace back and go ahead: Completing partial annotation for continual semantic segmentation.Pattern Recognition, 165:111613, 2025
work page 2025
-
[51]
Exemplar-based open- set panoptic segmentation network
Jaedong Hwang, Seoung Wug Oh, Joon-Young Lee, and Bohyung Han. Exemplar-based open- set panoptic segmentation network. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1175–1184, 2021
work page 2021
-
[52]
Revis- iting open-set panoptic segmentation
Yufei Yin, Hao Chen, Wengang Zhou, Jiajun Deng, Haiming Xu, and Houqiang Li. Revis- iting open-set panoptic segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 6747–6754, 2024
work page 2024
-
[53]
Hexin Dong, Zifan Chen, Mingze Yuan, Yutong Xie, Jie Zhao, Fei Yu, Bin Dong, and Li Zhang. Region-aware metric learning for open world semantic segmentation via meta-channel aggrega- tion.arXiv preprint arXiv:2205.08083, 2022
-
[54]
Dual decision improves open-set panoptic segmentation.arXiv preprint arXiv:2207.02504, 2022
Hai-Ming Xu, Hao Chen, Lingqiao Liu, and Yufei Yin. Dual decision improves open-set panoptic segmentation.arXiv preprint arXiv:2207.02504, 2022
-
[55]
Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Dollár. Panoptic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9404–9413, 2019
work page 2019
-
[56]
Huangjie Zheng, Xu Chen, Jiangchao Yao, Hongxia Yang, Chunyuan Li, Ya Zhang, Hao Zhang, Ivor Tsang, Jingren Zhou, and Mingyuan Zhou. Contrastive attraction and contrastive repulsion for representation learning.arXiv preprint arXiv:2105.03746, 2021
-
[57]
Jan Niklas Böhm, Philipp Berens, and Dmitry Kobak. Attraction-repulsion spectrum in neighbor embeddings.Journal of Machine Learning Research, 23(95):1–32, 2022
work page 2022
-
[58]
Stella X. Yu and Jianbo Shi. Segmentation with pairwise attraction and repulsion. InProceedings Eighth IEEE International Conference on Computer Vision. ICCV 2001, volume 1, pages 52–58. IEEE, 2001
work page 2001
-
[59]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
work page 2017
-
[60]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022
work page 2022
-
[61]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 13 A Additional Analysis A.1 Stability–plasticity Trajectory Fig. 7 summarizes the stability–plasticity behavior of FuTCR and SimCIS on ADE20K 100–5. Each...
work page 2016
-
[62]
The two panels depict diverse scenes where FuTCR recovers more accurate panoptic masks, particularly on newly introduced classes. and a balance term: Laux = 1 |Rfut| X r CE(gr, ℓr) +λ bal KL ¯p∥u ,(5) where ¯p is the mean predicted distribution over clusters and u is the uniform distribution. This head is intended to encourage diverse usage of latent slot...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.