It's not the Language Model, it's the Tool: Deterministic Mediation for Scientific Workflows
Pith reviewed 2026-05-14 19:52 UTC · model grok-4.3
The pith
Language models achieve identical scientific analysis results every time by calling fixed deterministic tools rather than generating code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Typed mediation lets the language model select and parameterize deterministic tools that encode a researcher's exact procedure for a specific instrument; the tool executes the analysis and returns identical outputs on every run, unlike direct generation by commercial foundation models which vary in numerical values or methodology.
What carries the argument
Typed mediation, a pattern in which the model orchestrates pre-defined deterministic tools that each encode one exact researcher procedure for one instrument.
If this is right
- The same input data and prompt will always produce the same output regardless of how many times the query is repeated.
- Analysis time for supported instruments drops from weeks to minutes while preserving the researcher's exact methodology.
- The pattern works with proprietary binary data formats and licensed software that must stay on local infrastructure.
- Reproducibility becomes a structural property of the workflow rather than a post-hoc verification task.
Where Pith is reading between the lines
- The same mediation pattern could apply to any workflow where consistency across runs is required, such as repeated measurements on shared lab equipment.
- By fixing the tool definitions, researchers gain an auditable record of the exact procedure used without needing to inspect generated code each time.
- Deployment on local infrastructure alongside the instrument becomes necessary for any analysis involving restricted data or software licenses.
Load-bearing premise
A researcher's exact analytical procedure for an instrument can be fully captured in a deterministic tool through structured interviews without losing necessary nuance or requiring ongoing human judgment.
What would settle it
Execute the same photoluminescence analysis prompt four or more times on the typed mediation system and check whether every run produces exactly the same numerical results and analysis steps, while direct model generation on identical prompts shows variation.
Figures


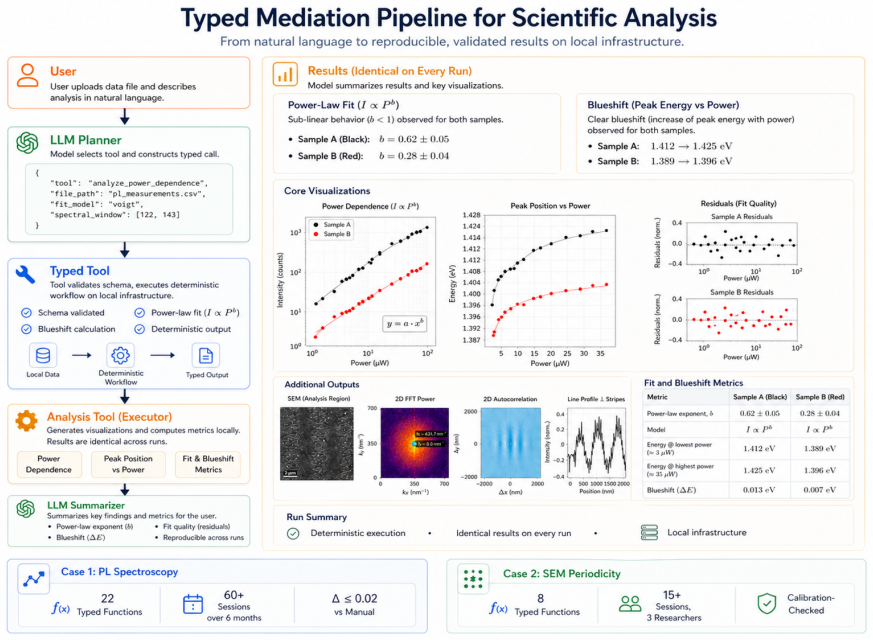

read the original abstract
Language models can produce convincing scientific analyses, but repeated generations on the same data do not guarantee the same result. A researcher may regenerate an identical query and receive a different fit, a different peak position or a different analysis procedure, without an obvious way to decide which output to trust. We propose typed mediation, a pattern in which the model orchestrates deterministic tools rather than generating analytical code. Each tool encodes one researcher's exact procedure for one instrument, ported through structured interviews. The model selects which tool to call and with what parameters. The tool produces the result. Regeneration does not change it. We evaluate this claim by running the same photoluminescence analysis on four platforms, including three commercial foundation models, four times each with the same prompt. The typed tool produces identical results across all runs. The commercial platforms either vary in numerical output and analytical methodology across runs, or fail to produce valid results on the task. We deploy this pattern on two instruments serving users over approximately six months, with very positive user feedback. Both cases are very challenging: they involve proprietary binary formats and per-seat licensed software, which force the tool to remain on local infrastructure alongside the data and the instrument it operates. We argue that deployment topology is not just a preference, but a structural requirement of scientific tool mediation. The result is a practical pattern for deploying language models in scientific workflows where reproducibility is mandatory, reducing analysis time from weeks to minutes while guaranteeing identical outputs across runs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'typed mediation,' a pattern in which language models orchestrate deterministic tools that encode a researcher's exact procedure for a given instrument (captured via structured interviews) rather than generating analytical code. The central claim is that this yields identical outputs on repeated identical prompts, unlike direct use of commercial foundation models. Evidence consists of a controlled four-run photoluminescence analysis across four platforms (typed tool plus three commercial models) showing identical results for the tool and variation or invalid outputs for the others, plus six-month deployments on two instruments with proprietary binary formats and licensed software, reporting positive user feedback. The paper argues that local deployment topology is a structural requirement for such mediation.
Significance. If the determinism claim holds under the reported conditions, the work provides a practical, deployable pattern for integrating LLMs into scientific workflows where reproducibility is mandatory. It shifts the reproducibility burden from stochastic generation to deterministic tool execution, with demonstrated time savings and applicability to challenging local-infrastructure settings. The direct multi-platform comparison and real-world deployment data are concrete strengths; the emphasis on topology as a requirement highlights an under-discussed engineering constraint in scientific AI applications.
major comments (3)
- [Evaluation] Evaluation section: the claim that the typed tool produces identical results while commercial platforms vary or fail lacks quantitative metrics for output variation (e.g., numerical differences in peak positions or fit parameters), exact definitions of 'valid results,' and any statistical analysis across the four runs per platform. These details are needed to substantiate the cross-platform comparison.
- [Methods / Tool Design] Tool construction description: the assertion that structured interviews fully capture 'one researcher's exact procedure' does not address potential loss of nuance, edge cases requiring ongoing judgment, or validation that the resulting tool matches the original analyst's intent on held-out data. This bears on whether the determinism is scientifically complete.
- [Discussion] Discussion of deployment topology: the claim that local infrastructure is a 'structural requirement' (rather than a preference) for proprietary formats and licensed software is asserted but not supported by concrete failure cases of cloud alternatives or quantitative comparison of latency/security constraints.
minor comments (2)
- [Abstract] The abstract introduces 'typed mediation' without a concise one-sentence definition; adding this would improve immediate clarity for readers.
- [Deployment] The six-month deployment results would benefit from at least summary statistics on usage volume, error rates, or specific user feedback themes to strengthen the 'very positive' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and indicate the revisions we will make to strengthen the presentation of our results and claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the claim that the typed tool produces identical results while commercial platforms vary or fail lacks quantitative metrics for output variation (e.g., numerical differences in peak positions or fit parameters), exact definitions of 'valid results,' and any statistical analysis across the four runs per platform. These details are needed to substantiate the cross-platform comparison.
Authors: We agree that quantitative details will strengthen the evaluation. In the revised manuscript we will add a table reporting the exact peak positions and fit parameters obtained in each of the four runs for every platform. For the typed tool these values are identical (standard deviation of zero). For the commercial models we will show the observed numerical spreads. We define 'valid results' as outputs that complete without runtime errors and yield physically plausible parameters (peak positions within the expected spectral range for the sample). With only four runs we present the raw values rather than formal statistical tests, but the contrast between zero variation and the observed spreads is clear. revision: yes
-
Referee: [Methods / Tool Design] Tool construction description: the assertion that structured interviews fully capture 'one researcher's exact procedure' does not address potential loss of nuance, edge cases requiring ongoing judgment, or validation that the resulting tool matches the original analyst's intent on held-out data. This bears on whether the determinism is scientifically complete.
Authors: The interviews were iterative and explicitly elicited decision rules and edge-case handling, which were then encoded directly into the tool's deterministic logic. We acknowledge that some analyst nuance may still be difficult to capture exhaustively. Validation occurred through six months of live use by the original researchers and additional users, whose feedback confirmed that tool outputs matched their expectations. We will add a paragraph in the Methods section discussing these limitations and the practical validation provided by deployment. revision: partial
-
Referee: [Discussion] Discussion of deployment topology: the claim that local infrastructure is a 'structural requirement' (rather than a preference) for proprietary formats and licensed software is asserted but not supported by concrete failure cases of cloud alternatives or quantitative comparison of latency/security constraints.
Authors: Local deployment is required because the instruments produce proprietary binary formats that need specialized local parsers and because the analysis software is available only under per-seat licenses that prohibit cloud execution. We will expand the Discussion to give concrete examples from the two deployed instruments, including the specific licensed packages and format constraints that make cloud alternatives impossible without license violation. While we did not run explicit cloud experiments, the licensing and format barriers are inherent and preclude quantitative cloud comparisons. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances a practical pattern of typed mediation in which an LLM orchestrates pre-defined deterministic tools rather than generating analysis code. Its central claim—that the tool yields identical outputs on repeated identical prompts—is supported by direct empirical comparison: the same photoluminescence prompt is executed four times on the typed tool and on three commercial platforms, with the tool producing identical numerical and methodological results while the others vary or fail. No equations, fitted parameters, or derivations appear in the manuscript; the determinism follows from the tool's implementation as fixed code rather than from any self-referential definition or prediction that reduces to its own inputs. Self-citations are absent from the load-bearing sections, and the six-month deployment observations are presented as corroborating usage data rather than as a mathematical necessity. The evaluation therefore remains an independent test of the proposed workflow.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A researcher's exact procedure for one instrument can be ported into a deterministic tool via structured interviews
invented entities (1)
-
typed mediation pattern
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Defeating nondeterminism in LLM inference, September 2025
Horace He and Thinking Machines Lab. Defeating nondeterminism in LLM inference, September 2025. Connectionism blog
work page 2025
-
[2]
Measuring AI agent autonomy in practice, February 2026
Miles McCain, Thomas Millar, Saffron Huang, Jake Eaton, Kunal Handa, Michael Stern, Alex Tamkin, Matt Kearney, Esin Durmus, Judy Shen, Jerry Hong, Brian Calvert, Jun Sh- ern Chan, Francesco Mosconi, David Saunders, Tyler Neylon, Gabriel Nicholas, Sarah Pol- lack, Jack Clark, and Deep Ganguli. Measuring AI agent autonomy in practice, February 2026
work page 2026
-
[3]
John R. Kitchin. The evolving role of programming and LLMs in the development of self-driving laboratories.APL Machine Learning, 3(2):026111, 2025
work page 2025
-
[4]
Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs
Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondřej Dušek. Leak, cheat, repeat: Data contamination and evaluation malpractices in closed-source LLMs. InProceed- ings of the 18th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2024
work page 2024
-
[5]
Leemann, Antonin Sulc, and Marco Venturini
Thorsten Hellert, Drew Bertwistle, Simon C. Leemann, Antonin Sulc, and Marco Venturini. Agentic artificial intelligence for multistage physics experiments at a large-scale user facility particle accelerator.Physical Review Research, 8:L012017, 2025
work page 2025
-
[6]
Prince, Tao Zhou, Henry Chan, and Mathew J
Aikaterini Vriza, Michael H. Prince, Tao Zhou, Henry Chan, and Mathew J. Cherukara. Operating advanced scientific instruments with AI agents that learn on the job.npj Com- putational Materials, 2026
work page 2026
-
[7]
Yong Xie, Kexin He, and Andres Castellanos-Gomez. Toward full autonomous laboratory instrumentation control with large language models.Small Structures, 2026
work page 2026
-
[8]
Cooper, Mengjia Zhu, Xenophon Evangelopoulos, and Andrew I
Abdoulatif Cissé, Max E. Cooper, Mengjia Zhu, Xenophon Evangelopoulos, and Andrew I. Cooper. Can we automate scientific reasoning in closed-loop experiments using large lan- guage models?Digital Discovery, 5:1132–1160, 2026
work page 2026
-
[9]
Same prompt, different outcomes: Evaluating the repro- ducibility of data analysis by LLMs
Jiaxin Cui and Rohan Alexander. Same prompt, different outcomes: Evaluating the repro- ducibility of data analysis by LLMs. 2026. Preprint
work page 2026
-
[10]
Chen Yang, Xianyang Zhang, and Jun Chen. ChatSpatial: Schema-enforced agentic orches- tration for reproducible and cross-platform spatial transcriptomics.bioRxiv, 2026. Preprint
work page 2026
-
[11]
Scaling reproducibility: An AI-assisted workflow for large- scale replication and reanalysis
Yiqing Xu and Leo Yang Yang. Scaling reproducibility: An AI-assisted workflow for large- scale replication and reanalysis. 2026. Preprint
work page 2026
-
[12]
Experiences with model context protocol servers for science and high performance computing
Haochen Pan, Ryan Chard, Reid Mello, Christopher Grams, Tanjin He, Alexander Brace, Owen Price Skelly, Will Engler, Hayden Holbrook, Song Young Oh, Maxime Gonthier, Michael Papka, Ben Blaiszik, Kyle Chard, and Ian Foster. Experiences with model context protocol servers for science and high performance computing. 2025. Argonne National Laboratory / Globus....
work page 2025
-
[13]
Joel Strickland, Arjun Vijeta, Chris Moores, Oliwia Bodek, Bogdan Nenchev, Thomas Whitehead, Charles Phillips, Karl Tassenberg, Gareth Conduit, and Ben Pellegrini. Talk freely, execute strictly: Schema-gated agentic AI for flexible and reproducible scientific workflows, March 2026. Preprint
work page 2026
-
[14]
Towards verifiably safe tool use for LLM agents
Aarya Doshi, Yining Hong, Congying Xu, Eunsuk Kang, Alexandros Kapravelos, and Chris- tian Kästner. Towards verifiably safe tool use for LLM agents. InProceedings of the 2026 15 IEEE/ACM 48th International Conference on Software Engineering: New Ideas and Emerg- ing Results (ICSE-NIER ’26), pages 1–5, Rio de Janeiro, Brazil, April 2026. ACM
work page 2026
-
[15]
Han Deng, Anqi Zou, Hanling Zhang, Ben Fei, Chengyu Zhang, Haobo Wang, Xinru Guo, Zhenyu Li, Xuzhu Wang, Peng Yang, Fujian Zhang, Weiyu Guo, Xiaohong Shao, Zhaoyang Liu, Shixiang Tang, Zhihui Wang, and Wanli Ouyang. Owl-AuraID 1.0: An intelligent sys- tem for autonomous scientific instrumentation and scientific data analysis. 2026. Preprint
work page 2026
-
[16]
Introducing the model context protocol, November 2024
Anthropic. Introducing the model context protocol, November 2024
work page 2024
-
[17]
Zhuo Diao, Kouma Matsumoto, Linfeng Hou, Masahiro Ohara, Hayato Yamashita, and Masayuki Abe. Integrating domain-specialized language models with AI measurement tools for deterministic atomic-resolution experimentation, February 2026. Preprint
work page 2026
-
[18]
Mohammed Mehedi Hasan, Hao Li, Gopi Krishnan Rajbahadur, Bram Adams, and Ahmed E. Hassan. Model context protocol (MCP) tool descriptions are smelly! towards improving AI agent efficiency with augmented MCP tool descriptions. 2026. Preprint
work page 2026
-
[19]
From docs to descriptions: Smell-aware evaluation of MCP server descriptions
Peiran Wang, Ying Li, Yuqiang Sun, Chengwei Liu, Yang Liu, and Yuan Tian. From docs to descriptions: Smell-aware evaluation of MCP server descriptions. 2026. Preprint. A An Example Skill Document for SEM Periodicity Analysis Below is a lightly edited excerpt from the skill document for the SEM periodicity tool (Section 4). The model reads this document be...
work page 2026
-
[20]
Read magnification from the SEM info bar (e.g.x40000)
-
[21]
Identify the uploaded file from its metadata
-
[22]
Decide analysis type: periodicity, particle sizing, or both
-
[23]
Call the tool with exact parameters
-
[24]
Present results with embedded figures. Analysis Type Selection User requestparticle_analysis Periodicity, spacing, LIPSS, FFT omit (defaultfalse) Particle/grain size, distributiontrue General “analyze this”true(runs both) Tool Invocation Periodicity only: run("sem_fft", { "file_id": "<UUID>", "mag_label": "x40000" }) With particle sizing: run("sem_fft", {...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.