Language Generation as Optimal Control: Closed-Loop Diffusion in Latent Control Space
Pith reviewed 2026-05-19 16:23 UTC · model grok-4.3
The pith
Reformulating language generation as stochastic optimal control and approximating the Hamilton-Jacobi-Bellman equation with flow matching produces a closed-loop model that delivers high-fidelity text via efficient parallel sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
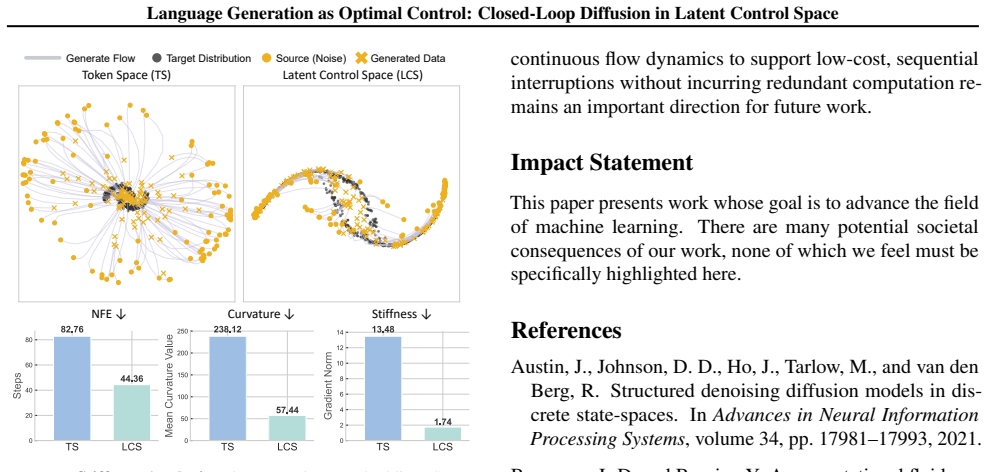
Viewing language generation as a stochastic optimal control problem reveals that the optimal policy is the closed-loop controller obtained by approximating the Hamilton-Jacobi-Bellman equation. Flow matching serves as the trajectory solver inside the rectified latent control space; the Manta-LM model equipped with a global integral operator thereby approximates the global vector field, simultaneously realizing high-fidelity generation and low-cost parallel sampling while mitigating the efficiency-fidelity paradox, irreversibility error propagation, and optimization intractability.
What carries the argument
Rectified latent control space in which flow matching acts as the optimal trajectory solver to approximate the Hamilton-Jacobi-Bellman equation and realize the closed-loop optimal policy.
If this is right
- The model achieves high-fidelity text generation together with efficient, low-cost parallel sampling.
- Generation exhibits improved stability, efficiency, and controllability relative to prior autoregressive and diffusion baselines.
- Strong empirical results appear on both unconditional language modeling and conditional generation tasks.
Where Pith is reading between the lines
- The same control-theoretic framing may extend to other autoregressive sequence tasks such as code or music generation.
- The closed-loop structure could support dynamic adjustment of generation constraints during sampling without retraining.
- Rectification of the latent space may prove reusable as a general technique for turning open-loop diffusion processes into closed-loop controllers.
Load-bearing premise
Flow matching inside the rectified latent control space approximates the true optimal vector field closely enough to preserve both fidelity and efficiency without introducing substantial new errors.
What would settle it
A direct comparison on a standard language-modeling benchmark that reports both perplexity (or equivalent fidelity metric) and wall-clock sampling time per sequence; the claim would be falsified if the new model fails to match autoregressive perplexity while simultaneously using substantially fewer serial steps than diffusion baselines.
Figures















read the original abstract
This work reformulates language generation as a stochastic optimal control problem, providing a unified theoretical perspective to analyze autoregressive and diffusion models and explain their limitations (Efficiency-Fidelity Paradox, Irreversibility Error Propagation, Optimization Tractability and Fidelity) in terms of combination of trajectory singularity, adjoint state vanishing, and gradient absence. To address these issues, we approximate the solution to the Hamilton-Jacobi-Bellman (HJB) equation, yielding an optimal policy that acts as a closed-loop controller. To bypass the intractability of directly solving the HJB PDE, we employ Flow Matching as the optimal trajectory solver within the rectified latent control space. This allows our Manta-LM with Global Integral Operator to approximate the global vector field, effectively realizing a model that simultaneously achieves high-fidelity text generation and efficient, low-cost parallel sampling. Empirically, our method achieves strong performance on language modeling and conditional generation tasks, while exhibiting improved stability, efficiency, and controllability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reformulates language generation as a stochastic optimal control problem, using this lens to diagnose limitations of autoregressive and diffusion models (Efficiency-Fidelity Paradox, Irreversibility Error Propagation, Optimization Tractability and Fidelity) as arising from trajectory singularity, adjoint vanishing, and gradient absence. It proposes approximating the Hamilton-Jacobi-Bellman equation via Flow Matching as the trajectory solver inside a rectified latent control space, realized as Manta-LM equipped with a Global Integral Operator, to obtain a closed-loop optimal policy that simultaneously delivers high-fidelity generation and low-cost parallel sampling. Strong empirical results on language modeling and conditional generation are claimed, together with gains in stability, efficiency, and controllability.
Significance. If the central approximation is shown to be valid with a controllable error bound, the work supplies a unified theoretical account that could resolve persistent paradoxes in language generative modeling and yield practical controllers with both fidelity and sampling efficiency.
major comments (2)
- [Abstract] Abstract and method description: the claim that Flow Matching inside the rectified latent control space approximates the HJB solution (and thereby yields an optimal closed-loop policy) is not accompanied by a derivation, equivalence statement, or error bound relating the Flow Matching regression objective to the HJB Hamiltonian or optimality condition, particularly for the discrete token state space.
- [Abstract] Abstract: the assertion that the Global Integral Operator enables approximation of the global vector field without reintroducing singularity or adjoint-vanishing problems lacks a supporting analysis or proof sketch showing that the latent rectification maps back to a categorical distribution while preserving the required optimality properties.
minor comments (2)
- Define the rectified latent control space and Global Integral Operator with explicit equations and state the precise mapping from latent trajectories to token distributions.
- Supply quantitative tables or figures with concrete metrics, baselines, and ablation results to substantiate the claimed empirical gains in fidelity, efficiency, and stability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the unified theoretical framing and empirical contributions. We respond to each major comment below and indicate planned revisions to address the concerns about theoretical grounding.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the claim that Flow Matching inside the rectified latent control space approximates the HJB solution (and thereby yields an optimal closed-loop policy) is not accompanied by a derivation, equivalence statement, or error bound relating the Flow Matching regression objective to the HJB Hamiltonian or optimality condition, particularly for the discrete token state space.
Authors: We agree that the abstract is too concise on this point. The manuscript derives the stochastic optimal control formulation in Section 2 and positions Flow Matching as the tractable trajectory solver for the HJB equation inside the continuous rectified latent space (Section 3). The rectification step maps discrete tokens to this latent space so that the Flow Matching regression objective can be applied directly to the vector field. We acknowledge that an explicit equivalence statement or error bound for the discrete case is not stated in the abstract. In the revision we will add a short derivation sketch to the abstract and a dedicated paragraph in Section 3 (with an appendix note) that relates the Flow Matching objective to the HJB Hamiltonian under the latent rectification, while clarifying that the approximation error is controlled in the continuous latent space before the final categorical mapping. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the Global Integral Operator enables approximation of the global vector field without reintroducing singularity or adjoint-vanishing problems lacks a supporting analysis or proof sketch showing that the latent rectification maps back to a categorical distribution while preserving the required optimality properties.
Authors: We thank the referee for this observation. The Global Integral Operator is introduced in Section 4 as the mechanism that integrates the learned vector field over latent trajectories to recover the token distribution. Because the control policy is closed-loop and applied entirely inside the rectified latent space, the original singularity and adjoint-vanishing issues are sidestepped; the final rectification step simply decodes the latent state back to a categorical distribution without altering the optimality of the latent policy. We agree that the abstract omits a supporting analysis. In the revised manuscript we will insert a brief proof sketch (or reference to the relevant lemma in Section 3) demonstrating that the rectification mapping preserves the closed-loop optimality properties and does not reintroduce the identified pathologies. revision: yes
Circularity Check
No circularity: derivation introduces independent approximation without reduction to inputs
full rationale
The paper reformulates language generation as stochastic optimal control and proposes approximating the HJB PDE solution via Flow Matching inside a rectified latent control space with a Global Integral Operator. This is framed as a modeling choice to bypass direct PDE intractability rather than a definitional equivalence or a prediction forced by fitting parameters to the target result. No equations or self-citations are shown that reduce the claimed optimality or closed-loop policy back to the Flow Matching objective or latent rectification by construction; the central claims rest on the new framework's ability to deliver fidelity and efficiency, which remains externally falsifiable on benchmarks. The derivation is therefore self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language generation processes can be modeled as solutions to a stochastic optimal control problem with trajectory singularity and adjoint state vanishing issues.
invented entities (2)
-
rectified latent control space
no independent evidence
-
Manta-LM with Global Integral Operator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
J(u) = E[−log p_θ(z1)] + λ ∫ E[½ ∥u_t(z_t)∥²] dt; u* = −∇V satisfying the HJB equation; Flow Matching regression L_CFM = E ∥v_θ(z_t,t) − (z1 − z0)∥² on OT paths
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Manifold Rectification via regularized VAE producing a diffeomorphic Euclidean latent space so that ∇z is well-defined and the dynamics are Lipschitz-regular
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D., Ho, J., Tarlow, M., and van den Berg, R
Austin, J., Johnson, D. D., Ho, J., Tarlow, M., and van den Berg, R. Structured denoising diffusion models in discrete state-spaces. In Advances in Neural Information Processing Systems, volume 34, pp.\ 17981--17993, 2021
work page 2021
-
[2]
Benamou, J.-D. and Brenier, Y. A computational fluid mechanics solution to the monge-kantorovich mass transfer problem. Numerische Mathematik, 84 0 (3): 0 375--393, 2000
work page 2000
-
[3]
Bertucci, C. Stochastic optimal transport and hamilton–jacobi–bellman equations on the set of probability measures. Annales de l'Institut Henri Poincar \'e C, Analyse non lin \'e aire , 2023. URL https://api.semanticscholar.org/CorpusID:259095954
work page 2023
-
[4]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. In Advances in neural information processing systems, volume 33, pp.\ 1877--1901, 2020
work page 1901
-
[5]
Bullo, F. and Lewis, A. D. Geometric control of mechanical systems. 2004. URL https://api.semanticscholar.org/CorpusID:679624
work page 2004
-
[6]
Chelba, C., Mikolov, T., Schuster, M., Ge, Q., Brants, T., Koehn, P. T., and Robinson, T. One billion word benchmark for measuring progress in statistical language modeling. In Interspeech, 2013
work page 2013
-
[7]
Chen, J., Cai, H., Chen, J., Xie, E., Yang, S., Tang, H., Li, M., Lu, Y., and Han, S. Deep compression autoencoder for efficient high-resolution diffusion models. arXiv preprint arXiv:2410.10733, 2024
-
[8]
Categorical flow matching on statistical manifolds
Cheng, C., Li, J., Peng, J., and Liu, G. Categorical flow matching on statistical manifolds. Advances in Neural Information Processing Systems, 37: 0 54787--54819, 2024
work page 2024
-
[9]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
DataCanary, hilfialkaff, Jiang, L., Risdal, M., Dandekar, N., and tomtung. Quora question pairs. Kaggle Competition, 2017. https://kaggle.com/competitions/quora-question-pairs
work page 2017
-
[11]
Dhingra, B., Mazaitis, K., and Cohen, W. W. Quasar: Datasets for question answering by search and reading. arXiv preprint arXiv:1707.03904, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Continuous diffusion for categorical data
Dieleman, S., Sartran, L., Roshannai, A., Savinov, N., Ganin, Y., Richemond, P. H., Doucet, A., Strudel, R., Dyer, C., Durkan, C., et al. Continuous diffusion for categorical data. arXiv preprint arXiv:2211.15089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Fleming, W. H. and Rishel, R. W. Deterministic and stochastic optimal control. Springer Science & Business Media, 2012
work page 2012
-
[14]
Gokaslan, A. and Cohen, V. Openwebtext corpus. http://Skylion007.github.io/OpenWebTextCorpus, 2019
work page 2019
-
[15]
Diffuseq-v2: Bridging discrete and continuous text spaces for accelerated seq2seq diffusion models
Gong, S., Li, M., Feng, J., Wu, Z., and Kong, L. Diffuseq-v2: Bridging discrete and continuous text spaces for accelerated seq2seq diffusion models. In The 2023 Conference on Empirical Methods in Natural Language Processing
work page 2023
-
[16]
Diffuseq: Sequence to sequence text generation with diffusion models
Gong, S., Li, M., Feng, J., Wu, Z., and Kong, L. Diffuseq: Sequence to sequence text generation with diffusion models. In International Conference on Learning Representations (ICLR 2023)(01/05/2023-05/05/2023, Kigali, Rwanda), 2023
work page 2023
-
[17]
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Gong, S., Agarwal, S., Zhang, Y., Ye, J., Zheng, L., Li, M., An, C., Zhao, P., Bi, W., Han, J., et al. Scaling diffusion language models via adaptation from autoregressive models. arXiv preprint arXiv:2410.17891, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
Gulrajani, I. and Hashimoto, T. B. Likelihood-based diffusion language models. Advances in Neural Information Processing Systems, 36: 0 16693--16715, 2023
work page 2023
-
[19]
Han, X., Kumar, S., and Tsvetkov, Y. Ssd-lm: Semi-autoregressive simplex-based diffusion language model for text generation and modular control. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 11575--11596, 2023
work page 2023
-
[20]
Argmax flows and multinomial diffusion: Learning categorical distributions
Hoogeboom, E., Nielsen, D., Jaini, P., Forr \'e , P., and Welling, M. Argmax flows and multinomial diffusion: Learning categorical distributions. Advances in neural information processing systems, 34: 0 12454--12465, 2021
work page 2021
-
[21]
K., Xu, W., Hao, J., Song, L., Xu, Y., Yang, J., Liu, J., Zhang, C., et al
Huang, S., Cheng, T., Liu, J. K., Xu, W., Hao, J., Song, L., Xu, Y., Yang, J., Liu, J., Zhang, C., et al. Opencoder: The open cookbook for top-tier code large language models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 33167--33193, 2025
work page 2025
-
[22]
Neural crf model for sentence alignment in text simplification
Jiang, C., Maddela, M., Lan, W., Zhong, Y., and Xu, W. Neural crf model for sentence alignment in text simplification. arXiv preprint arXiv:2005.02324, 2020
-
[23]
Jo, J. and Hwang, S. J. Continuous diffusion model for language modeling. In Neural Information Processing Systems, 2025
work page 2025
-
[24]
Li, J., Du, L., Zhao, H., Zhang, B.-w., Wang, L., Gao, B., Liu, G., and Lin, Y. Infinity instruct: Scaling instruction selection and synthesis to enhance language models. arXiv preprint arXiv:2506.11116, 2025 a
-
[25]
Li, S., Gu, J., Liu, K., Lin, Z., Wei, Z., Grover, A., and Kuen, J. Lavida-o: Elastic large masked diffusion models for unified multimodal understanding and generation. arXiv preprint arXiv:2509.19244, 2025 b
-
[26]
Li, X., Thickstun, J., Gulrajani, I., Liang, P. S., and Hashimoto, T. B. Diffusion-lm improves controllable text generation. Advances in neural information processing systems, 35: 0 4328--4343, 2022
work page 2022
-
[27]
T., Ben-Hamu, H., Nickel, M., and Le, M
Lipman, Y., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling. In International Conference on Learning Representations, 2023
work page 2023
-
[28]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Lou, A., Meng, C., and Ermon, S. Discrete diffusion modeling by estimating the ratios of the data distribution. arXiv preprint arXiv:2310.16834, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
K., Ivison, H., Tae, J., Henderson, J., Beltagy, I., Peters, M
Mahabadi, R. K., Ivison, H., Tae, J., Henderson, J., Beltagy, I., Peters, M. E., and Cohan, A. Tess: Text-to-text self-conditioned simplex diffusion. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 2347--2361, 2024
work page 2024
-
[30]
Pointer sentinel mixture models, 2016
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models, 2016
work page 2016
-
[31]
arXiv preprint arXiv:2504.16891 , year=
Moshkov, I., Hanley, D., Sorokin, I., Toshniwal, S., Henkel, C., Schifferer, B., Du, W., and Gitman, I. Aimo-2 winning solution: Building state-of-the-art mathematical reasoning models with openmathreasoning dataset. arXiv preprint arXiv:2504.16891, 2025
-
[32]
Large language diffusion models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y., Wen, J.-R., and Li, C. Large language diffusion models. In Neural Information Processing Systems, 2025 a
work page 2025
-
[33]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y., Wen, J.-R., and Li, C. Large language diffusion models. arXiv preprint arXiv:2502.09992, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Ou, J., Nie, S., Xue, K., Zhu, F., Sun, J., Li, Z., and Li, C. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. arXiv preprint arXiv:2406.03736, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
The lambada dataset: Word prediction requiring a broad discourse context
Paperno, D., Kruszewski, G., Lazaridou, A., Pham, N.-Q., Bernardi, R., Pezzelle, S., Baroni, M., Boleda, G., and Fern \'a ndez, R. The lambada dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers), pp.\ 1525--1534, 2016
work page 2016
-
[36]
Language models are unsupervised multitask learners
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners. OpenAI blog, 1 0 (8): 0 9, 2019
work page 2019
-
[37]
Simple and effective masked diffusion language models
Sahoo, S., Arriola, M., Schiff, Y., Gokaslan, A., Marroquin, E., Chiu, J., Rush, A., and Kuleshov, V. Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems, 37: 0 130136--130184, 2024
work page 2024
-
[38]
Simplified and generalized masked diffusion for discrete data
Shi, J., Han, K., Wang, Z., Doucet, A., and Titsias, M. Simplified and generalized masked diffusion for discrete data. Advances in neural information processing systems, 37: 0 103131--103167, 2024
work page 2024
-
[39]
Deep unsupervised learning using nonequilibrium thermodynamics
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pp.\ 2256--2265. pmlr, 2015
work page 2015
-
[40]
Self- conditioned embedding diffusion for text generation,
Strudel, R., Tallec, C., Altch \'e , F., Du, Y., Ganin, Y., Mensch, A., Grathwohl, W., Savinov, N., Dieleman, S., Sifre, L., et al. Self-conditioned embedding diffusion for text generation. arXiv preprint arXiv:2211.04236, 2022
-
[41]
Score-based continuous-time discrete diffusion models
Sun, H., Yu, L., Dai, B., Schuurmans, D., and Dai, H. Score-based continuous-time discrete diffusion models. arXiv preprint arXiv:2211.16750, 2022
-
[42]
Unified multimodal discrete diffusion.arXiv preprint arXiv:2503.20853, 2025
Swerdlow, A., Prabhudesai, M., Gandhi, S., Pathak, D., and Fragkiadaki, K. Unified multimodal discrete diffusion. arXiv preprint arXiv:2503.20853, 2025
-
[43]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi \`e re, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Tang, J., Wang, J., Yang, J., Tu, J., Zhang, J., Ma, J., Xu, J., Zhou, J., Bai, J., He, J., Lin, J., Dang, K., Lu, K., Chen, K.-Y., Yang, K., Li, M., Xue, M., Ni, N., Zhang, P., Wang, P., Peng, R., Men, R., Gao, R., Lin, R., Wang, S., ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
MMaDA: Multimodal Large Diffusion Language Models
Yang, L., Tian, Y., Li, B., Zhang, X., Shen, K., Tong, Y., and Wang, M. Mmada: Multimodal large diffusion language models. arXiv preprint arXiv:2505.15809, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Dream 7B: Diffusion Large Language Models
Ye, J., Xie, Z., Zheng, L., Gao, J., Wu, Z., Jiang, X., Li, Z., and Kong, L. Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Commonsense knowledge aware conversation generation with graph attention
Zhou, H., Young, T., Huang, M., Zhao, H., Xu, J., and Zhu, X. Commonsense knowledge aware conversation generation with graph attention. In IJCAI, volume 18, pp.\ 4623--4629, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.