On the Stability of Growth in Structural Plasticity
Pith reviewed 2026-05-19 15:34 UTC · model grok-4.3
The pith
Newborn network units participate in the forward pass but receive weaker gradients than units present from the start.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
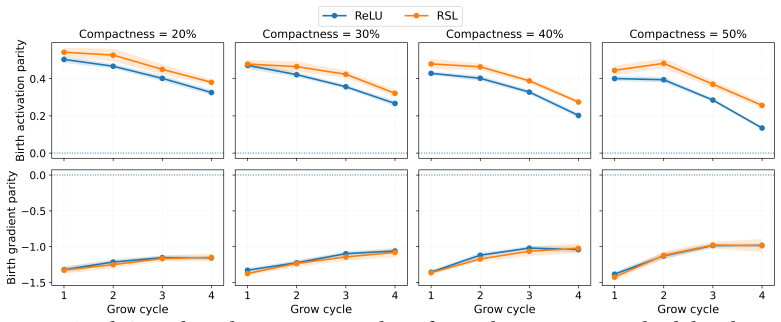
Newborn units are often forward-active but backward-starved: they participate in the forward computation, yet receive much weaker gradient signal than incumbent units. This disadvantage is minor in small MLP benchmarks but becomes clear in harder image-classification settings with a convolutional trunk. Grow can achieve high final accuracy during the structural-editing procedure, while Prune is stronger when performance is averaged over the training trajectory or when the final sparse network is retrained from scratch.
What carries the argument
The insertion problem: new units are added into an already specialized optimization trajectory, producing systematically weaker back-propagated gradients than those received by units that have been present from initialization.
Load-bearing premise
By the time new units are inserted the optimization trajectory has already specialized, so their gradient signals are weaker than those of the original units.
What would settle it
Direct measurement of per-unit gradient magnitudes right after insertion across multiple runs; if new units consistently receive gradient norms comparable to incumbent units, the central claim would not hold.
Figures
















read the original abstract
Standard deep-learning pipelines usually choose the network architecture before training and keep it fixed throughout optimization. In contrast, a model can also be adapted by editing its structure during training, for example by pruning existing hidden-neuron units or growing new ones. Although growth is appealing for adaptive and continual systems, we show that it is not simply the inverse of pruning. Pruning selects among units that have participated in training from the start, whereas growth inserts new units into an already specialized optimization trajectory. We isolate this insertion problem and show that newborn units are often forward-active but backward-starved: they participate in the forward computation, yet receive much weaker gradient signal than incumbent units. This disadvantage is minor in small MLP benchmarks, but becomes clear in harder image-classification settings with a convolutional trunk. In these settings, \textsc{Grow} can achieve high final accuracy during the structural-editing procedure, while \textsc{Prune} is stronger when performance is averaged over the training trajectory or when the final sparse network is retrained from scratch. Interventions targeting optimizer state, insertion, selection, and trainability show that improving the integration of newborn units can improve adaptive performance, but does not automatically produce better final subnetworks. In continual-learning benchmarks stressing plasticity loss, \textsc{Grow} becomes competitive mainly when new units have enough time to integrate. Together, these results suggest that \textsc{Grow} should be evaluated not only as an architecture-search operator, but as a time-sensitive optimization process whose success depends on insertion stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines structural plasticity in deep networks by comparing growth (adding new units mid-training) to pruning (removing units). It argues that growth is not the inverse of pruning because new units are inserted into an already-specialized optimization trajectory, resulting in newborn units that are forward-active but backward-starved (participating in the forward pass yet receiving systematically weaker gradient signals than incumbent units). This is demonstrated through controlled experiments on MLPs and convolutional image-classification tasks, interventions targeting optimizer state/insertion/selection/trainability, distinctions between final accuracy and trajectory-averaged/retrained performance, and continual-learning settings where integration time affects competitiveness.
Significance. If the central empirical observations hold, the work usefully highlights an asymmetry in dynamic architecture methods and frames growth as a time-sensitive optimization process rather than a pure architecture-search operator. The targeted interventions and separation of final vs. averaged performance provide concrete guidance for adaptive and continual-learning systems. Credit is due for the reproducible-style interventions and the focus on plasticity loss in continual benchmarks.
major comments (2)
- [§4.2] §4.2 (gradient-signal experiments): the claim that newborn units receive 'much weaker gradient signal' is central to the insertion-problem argument, yet the manuscript does not specify the precise metric (e.g., per-unit L2 norm, cosine similarity to incumbent gradients, or layer-wise averages) nor whether any scaling or normalization is applied before comparison; without this, it is difficult to assess whether the observed difference is an artifact of initialization scale or a genuine optimization-trajectory effect.
- [Table 3] Table 3 and associated text (image-classification results): the reported advantage of Grow on final accuracy versus Prune on trajectory-averaged or retrained performance lacks error bars, number of random seeds, or statistical tests; given that the central claim rests on these performance distinctions, the absence of variability measures makes it impossible to judge whether the differences are robust or could be explained by post-hoc run selection.
minor comments (3)
- [Abstract] Abstract and §2: the phrase 'backward-starved' is used repeatedly before any quantitative definition or figure reference is given; a short parenthetical or footnote linking to the measurement protocol would improve readability.
- [§5] §5 (continual-learning experiments): the statement that 'Grow becomes competitive mainly when new units have enough time to integrate' would benefit from an explicit plot or table showing accuracy as a function of insertion timing or number of subsequent epochs.
- [§3] Notation: the distinction between 'final accuracy during the structural-editing procedure' and 'performance averaged over the training trajectory' is important but introduced without a compact symbol or equation; adding a brief definition in §3 would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript examining the asymmetry between growth and pruning in structural plasticity. We address each major comment below and outline the revisions we will make to improve clarity and reporting standards.
read point-by-point responses
-
Referee: [§4.2] §4.2 (gradient-signal experiments): the claim that newborn units receive 'much weaker gradient signal' is central to the insertion-problem argument, yet the manuscript does not specify the precise metric (e.g., per-unit L2 norm, cosine similarity to incumbent gradients, or layer-wise averages) nor whether any scaling or normalization is applied before comparison; without this, it is difficult to assess whether the observed difference is an artifact of initialization scale or a genuine optimization-trajectory effect.
Authors: We agree that the gradient metric requires explicit definition to rule out artifacts. In the experiments, gradient signal strength was quantified as the L2 norm of the gradient with respect to each unit's incoming parameters, averaged across the batch and over post-insertion training steps; no additional per-unit scaling or normalization was applied beyond the standard back-propagation and Adam optimizer state. We have revised §4.2 to state this definition verbatim, added a short paragraph explaining why the L2 norm is appropriate for comparing backward starvation, and included a supplementary check confirming that the observed gap remains after matching initialization variance. These changes directly address the concern. revision: yes
-
Referee: Table 3 and associated text (image-classification results): the reported advantage of Grow on final accuracy versus Prune on trajectory-averaged or retrained performance lacks error bars, number of random seeds, or statistical tests; given that the central claim rests on these performance distinctions, the absence of variability measures makes it impossible to judge whether the differences are robust or could be explained by post-hoc run selection.
Authors: The referee correctly identifies a reporting gap. The Table 3 results were obtained from five independent random seeds, with the reported trends consistent across all runs. In the revised manuscript we will add standard-deviation error bars to the table, explicitly state the number of seeds, and include a brief statistical note (paired t-tests on the key metrics) either in the main text or as a short supplement paragraph. This will allow readers to assess robustness directly. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper advances empirical claims about the stability of structural growth versus pruning in neural networks, supported by benchmark comparisons, interventions on optimizer state and insertion timing, and observations of gradient signals in convolutional and continual-learning settings. No derivation chain, first-principles equations, or fitted parameters are presented that reduce by construction to inputs defined within the paper itself; the central distinction between Grow and Prune rests on externally measurable performance differences rather than self-referential definitions or self-citation load-bearing arguments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Once training has progressed, the optimization trajectory has specialized such that newly inserted units receive systematically weaker gradients.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.