Perforated Neural Networks for Keyword Spotting
Pith reviewed 2026-05-20 21:06 UTC · model grok-4.3
The pith
Adding artificial dendrite nodes to CNNs improves accuracy and cuts parameters for edge keyword spotting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
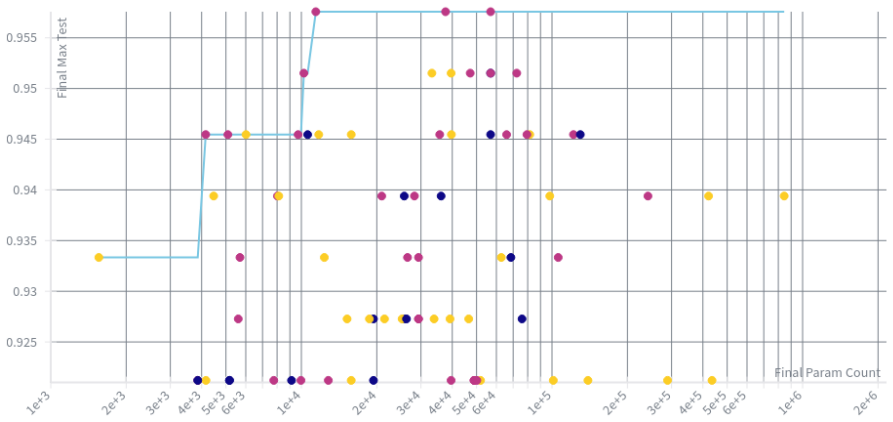
By adding artificial Dendrite Nodes to a standard convolutional neural network trained on the Edge Impulse keyword spotting tutorial pipeline, dendritic models outperform traditional architectures at every level of parameter count and at every accuracy threshold tested across 800 hyperparameter trials. The best dendritic model achieved a test accuracy of 0.933 with only 1,500 parameters, versus the baseline accuracy of 0.921 requiring approximately 4,000 parameters.
What carries the argument
Artificial Dendrite Nodes added via Perforated Backpropagation
If this is right
- Dendritic models can meet strict memory budgets and accuracy thresholds at the same time for edge machine learning.
- The method supplies simultaneous improvements in model quality and deployment efficiency.
- Practical value is shown by the approach winning the best-model award in the Edge Impulse 2025 Hackathon.
Where Pith is reading between the lines
- The same node modification could be applied to other edge tasks such as speech command recognition or sensor anomaly detection.
- Testing the dendritic structure on additional hardware targets would show whether the parameter savings transfer beyond the current platform.
Load-bearing premise
The 800 hyperparameter trials provide a fair comparison between dendritic and baseline models with no hidden differences in training procedure, data splits, or evaluation.
What would settle it
A follow-up run that retrains both architectures on identical data splits using the exact same hyperparameter settings and finds no accuracy or size advantage for the dendritic version.
Figures
read the original abstract
Edge machine learning presents a unique set of constraints not encountered in cloud-scale model deployment: strict memory budgets, limited compute, and non-negotiable accuracy thresholds must all be satisfied simultaneously. Existing compression and optimization techniques can trade one resource for another, but rarely improve both accuracy and model size at the same time. This paper presents the application of Perforated Backpropagation to keyword spotting on the Edge Impulse platform, an experiment that won the Best Model award at the Edge Impulse 2025 Hackathon in December 2025. By adding artificial Dendrite Nodes to a standard convolutional neural network trained on the Edge Impulse keyword spotting tutorial pipeline, we demonstrate that dendritic models outperform traditional architectures at every level of parameter count and at every accuracy threshold tested across 800 hyperparameter trials. The best dendritic model achieved a test accuracy of 0.933 with only 1,500 parameters, versus the baseline accuracy of 0.921 requiring approximately 4,000 parameters. These results suggest that Perforated Backpropagation is a powerful addition to the edge AI engineer's toolkit, offering simultaneous gains in both model quality and deployment efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript applies Perforated Backpropagation by inserting artificial Dendrite Nodes into a standard CNN for keyword spotting on the Edge Impulse tutorial pipeline. It reports that dendritic models outperform conventional architectures across the entire accuracy-vs-parameter frontier in 800 hyperparameter trials, with the best dendritic model reaching 0.933 test accuracy using 1,500 parameters versus a baseline of 0.921 accuracy at roughly 4,000 parameters. The work also won the Best Model award at the Edge Impulse 2025 Hackathon.
Significance. If the reported dominance holds under identical search spaces, training protocols, and parameter-counting conventions, the result would be a practically useful improvement for memory-constrained edge ML, simultaneously raising accuracy and lowering model size. The hackathon win supplies limited external corroboration, but the absence of methodological controls prevents assessment of whether the gains are intrinsic to the architecture or artifacts of unequal optimization effort.
major comments (2)
- Abstract: the central claim that dendritic models 'outperform traditional architectures at every level of parameter count and at every accuracy threshold' rests on the unstated assumption that the 800 trials used identical hyperparameter ranges, identical numbers of trials per architecture, identical optimizer schedules, identical early-stopping rules, and identical conventions for counting parameters introduced by Dendrite Nodes. No table, appendix, or methods subsection confirms these controls; without them the observed frontier dominance cannot be attributed to Perforated Backpropagation rather than differences in search effort.
- Abstract: the reported numbers (0.933 accuracy at 1,500 parameters versus 0.921 at ~4,000 parameters) are presented without any measure of variance across trials, without statistical significance tests, and without disclosure of the baseline architecture details or whether parameter counts include all overhead from the added nodes. These omissions make the quantitative comparison unverifiable from the given text.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting issues of experimental transparency and reporting. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the central claim that dendritic models 'outperform traditional architectures at every level of parameter count and at every accuracy threshold' rests on the unstated assumption that the 800 trials used identical hyperparameter ranges, identical numbers of trials per architecture, identical optimizer schedules, identical early-stopping rules, and identical conventions for counting parameters introduced by Dendrite Nodes. No table, appendix, or methods subsection confirms these controls; without them the observed frontier dominance cannot be attributed to Perforated Backpropagation rather than differences in search effort.
Authors: We agree that the manuscript should have documented the search protocol explicitly. The 800 trials allocated equal effort to both architectures using identical hyperparameter ranges, the same number of trials per architecture, the Adam optimizer with matching schedules, and the same early-stopping rule. Dendrite Node overhead is included in all reported parameter counts. We will add a Methods subsection and a summary table detailing these controls so that the frontier comparison can be verified as arising under matched conditions. revision: yes
-
Referee: Abstract: the reported numbers (0.933 accuracy at 1,500 parameters versus 0.921 at ~4,000 parameters) are presented without any measure of variance across trials, without statistical significance tests, and without disclosure of the baseline architecture details or whether parameter counts include all overhead from the added nodes. These omissions make the quantitative comparison unverifiable from the given text.
Authors: We will expand the Results and Methods sections to describe the baseline CNN architecture in full and to state explicitly that parameter counts encompass all Dendrite Node overhead. Variance measures and formal significance tests were not computed during the original 800-trial campaign; we therefore cannot supply them without additional experiments. We will note this limitation and, where feasible, report any available run-to-run consistency from the retained best-model checkpoints. revision: partial
- Variance estimates and statistical significance tests across the full set of 800 trials, which were not performed in the original analysis.
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential reductions
full rationale
The manuscript reports direct experimental outcomes from training and evaluating convolutional networks with added Dendrite Nodes versus baselines on the Edge Impulse keyword spotting task across 800 hyperparameter trials. No equations, first-principles derivations, or predictions appear that could reduce to fitted inputs or self-definitions by construction. The central claim of outperformance at every parameter count and accuracy threshold is presented as an observed result rather than a quantity defined in terms of itself. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify the architecture or results. Fairness of the hyperparameter sweep is an empirical control question external to any definitional loop.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Dendrite Nodes
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By adding artificial Dendrite Nodes to a standard convolutional neural network... Perforated Backpropagation modifies this equation by splitting postsynaptic nodes into neuron nodes... and zeroing out the Dendrite Node error terms during backpropagation
-
IndisputableMonolith/Foundation/AbsoluteFloorClosurereality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The best dendritic model achieved a test accuracy of 0.933 with only 1,500 parameters, versus the baseline accuracy of 0.921 requiring approximately 4,000 parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mlperf tiny benchmark.arXiv preprint arXiv:2106.07597, 2021a
Colby Banbury, Vijay Janapa Reddi, Maxwell Lam, William Fu, Amin Fazel, Jeremy Holleman, Xueyuan Huang, David Kanter, Anton Lokhmotov, David Patterson, et al. Mlperf tiny benchmark.arXiv preprint arXiv:2106.07597, 2021
-
[2]
Tiago Branco and Michael H¨ ausser. The single dendritic branch as a fundamental functional unit in the nervous system.Current opinion in neurobiology, 20(4):494–502, 2010. 7
work page 2010
-
[3]
Edge impulse keyword spotting: Hyperparameter sweep report
Rorry Brenner. Edge impulse keyword spotting: Hyperparameter sweep report. https: //api.wandb.ai/links/perforated-ai/wl04hzro, 2025
work page 2025
-
[4]
Rorry Brenner, Evan Davis, Rushi Chaudhari, Rowan Morse, Jingyao Chen, Xirui Liu, Zhaoyi You, and Laurent Itti. Exploring the performance of perforated backpropagation through further experiments.arXiv preprint arXiv:2506.00356, 2025
-
[5]
Rorry Brenner and Laurent Itti. Perforated backpropagation: A neuroscience inspired extension to artificial neural networks.arXiv preprint arXiv:2501.18018, 2025
-
[6]
Spyridon Chavlis and Panayiota Poirazi. Drawing inspiration from biological dendrites to empower artificial neural networks.Current opinion in neurobiology, 70:1–10, 2021
work page 2021
-
[7]
Edge impulse: Machine learning for embedded systems
Edge Impulse. Edge impulse: Machine learning for embedded systems. https:// edgeimpulse.com, 2019
work page 2019
-
[8]
Edge impulse contest 2025 winners
Edge Impulse. Edge impulse contest 2025 winners. https://www.edgeimpulse.com/blog/ edge-impulse-contest-2025-winners/, 2025
work page 2025
-
[9]
The cascade-correlation learning architecture
Scott E Fahlman and Christian Lebiere. The cascade-correlation learning architecture. In Advances in neural information processing systems, volume 2, 1989
work page 1989
-
[10]
Andrew Howard et al. Searching for mobilenetv3. InProceedings of the IEEE/CVF international conference on computer vision, 2019
work page 2019
-
[11]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of NAACL-HLT, volume 1, 2019
work page 2019
-
[13]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. InAdvances in neural information processing systems, volume 25, 2012
work page 2012
-
[14]
Pengyong Li et al. Trimnet: learning molecular representation from triplet messages for biomedicine.Briefings in Bioinformatics, 2021
work page 2021
-
[15]
Xinran Li et al. Power-efficient neural network with artificial dendrites.Nature Nanotech- nology, 15(9):776–782, 2020
work page 2020
-
[16]
Guy Major et al. Spatiotemporally graded nmda spike/plateau potentials in basal dendrites of neocortical pyramidal neurons.Journal of neurophysiology, 99:2584–2601, 2008
work page 2008
-
[17]
Guy Major, Matthew E Larkum, and Jackie Schiller. Active properties of neocortical pyramidal neuron dendrites.Annual review of neuroscience, 36:1–24, 2013
work page 2013
-
[18]
Warren S McCulloch and Walter Pitts. A logical calculus of the ideas immanent in nervous activity.The bulletin of mathematical biophysics, 5:115–133, 1943
work page 1943
-
[19]
Perforatedai: The artificial dendrite library for pytorch
Perforated AI. Perforatedai: The artificial dendrite library for pytorch. https://github. com/PerforatedAI/PerforatedAI, 2024
work page 2024
-
[20]
Perforatedai: Edge impulse block
Perforated AI. Perforatedai: Edge impulse block. https://github. com/PerforatedAI/PerforatedAI/tree/main/Examples/hackathonProjects/ example-custom-ml-block-pytorch, 2025. 8
work page 2025
-
[21]
Morphological perceptrons with dendritic structure
Gerhard X Ritter, Gonzalo Iba˜ nez-Garc´ ıa, and Gonzalo Urcid. Morphological perceptrons with dendritic structure. InThe 12th IEEE International Conference on Fuzzy Systems, volume 2, 2003
work page 2003
-
[22]
Frank Rosenblatt. The perceptron: a probabilistic model for information storage and organization in the brain.Psychological review, 65(6):386, 1958
work page 1958
-
[23]
Learning representations by back-propagating errors.Nature, 323:533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors.Nature, 323:533–536, 1986
work page 1986
-
[24]
Satya Narayan Shukla and Benjamin M Marlin. Multi-time attention networks for irregularly sampled time series.arXiv preprint arXiv:2101.10318, 2021
-
[25]
Efficient training for dendrite morphological neural networks.Neurocomputing, 131:132–142, 2014
Humberto Sossa and Elizabeth Guevara. Efficient training for dendrite morphological neural networks.Neurocomputing, 131:132–142, 2014
work page 2014
-
[26]
Pete Warden.Speech commands: A dataset for limited-vocabulary speech recognition. 2018
work page 2018
-
[27]
Experiment tracking with weights and biases
Weights & Biases. Experiment tracking with weights and biases. https://wandb.ai, 2020
work page 2020
-
[28]
Bernard Widrow and Michael A Lehr. 30 years of adaptive neural networks: perceptron, madaline, and backpropagation.Proceedings of the IEEE, 78:1415–1442, 1990
work page 1990
-
[29]
Wentao Xu et al. Hist: A graph-based framework for stock trend forecasting via mining concept-oriented shared information.arXiv preprint arXiv:2110.13716, 2021
-
[30]
Hello Edge: Keyword Spotting on Microcontrollers
Yundong Zhang, Naveen Suda, Liangzhen Lai, and Vikas Chandra. Hello edge: Keyword spotting on microcontrollers. InarXiv preprint arXiv:1711.07128, 2017. 9
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.