DimMem: Dimensional Structuring for Efficient Long-Term Agent Memory
Pith reviewed 2026-05-20 18:55 UTC · model grok-4.3
The pith
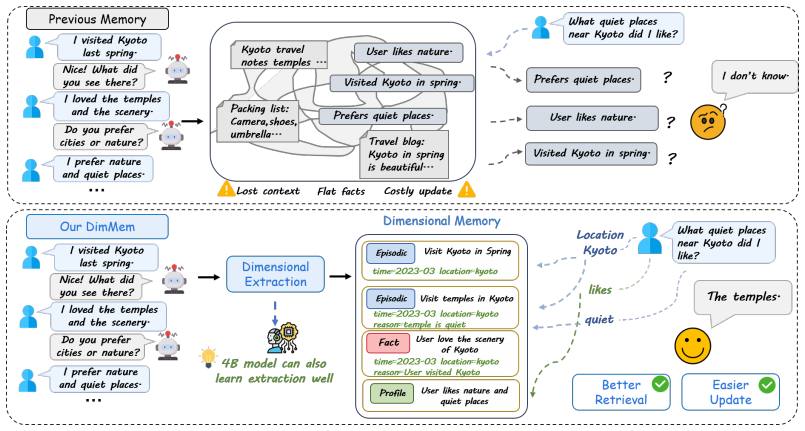
DimMem represents each memory as a typed unit with explicit fields like time, location, reason, purpose and keywords to support efficient long-term recall in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DimMem structures each memory as an atomic, typed, and self-contained unit with explicit fields such as time, location, reason, purpose, and keywords. This representation exposes the structure needed for dimension-aware retrieval, memory update, and selective assistant-context recall without storing full histories in the model context. Across LoCoMo-10 and LongMemEval-S, the method achieves 81.43 percent and 78.20 percent overall accuracy, outperforming existing lightweight memory systems while reducing LoCoMo per-query token cost by 24 percent. Dimensional memory extraction is learnable by compact models: after fine-tuning on the DimMem schema, a Qwen3-4B extractor surpasses LightMem with a
What carries the argument
The dimensional memory unit, an atomic typed self-contained representation carrying explicit fields for time, location, reason, purpose, and keywords that enables dimension-aware retrieval and selective context injection.
If this is right
- Agents can sustain longer histories without exceeding context windows because only selected dimensional fields are injected.
- Retrieval can be performed along individual dimensions such as keywords or time rather than scanning entire records.
- Memory updates can modify or add a single field without rewriting an entire summary.
- Compact models become practical for the extraction step once fine-tuned on the schema.
Where Pith is reading between the lines
- The same explicit-field approach could be applied to other agent components such as goal tracking or tool-use logs.
- Extending the field set dynamically per domain might improve performance on specialized tasks without increasing overall token load.
- Combining the dimensional units with embedding-based search could further accelerate retrieval while preserving the interpretability of the typed fields.
Load-bearing premise
The chosen set of explicit fields is assumed to capture enough structure for precise recall and selective context injection without requiring the full original dialogue history.
What would settle it
A head-to-head test in which the same agent queries are answered once with DimMem and once with the complete original dialogue turns injected into context; if the full-history version shows materially higher accuracy on the same benchmarks, the sufficiency of the five fields would be in doubt.
Figures








read the original abstract
Large language model (LLM) agents require long-term memory to leverage information from past interactions. However, existing memory systems often face a fidelity--efficiency trade-off: raw dialogue histories are expensive, while flat facts or summaries may discard the structure needed for precise recall. We propose \textbf{DimMem}, a lightweight dimensional memory framework that represents each memory as an atomic, typed, and self-contained unit with explicit fields such as time, location, reason, purpose, and keywords. This representation exposes the structure needed for dimension-aware retrieval, memory update, and selective assistant-context recall without storing full histories in the model context. Across LoCoMo-10 and LongMemEval-S, DimMem achieves \textbf{81.43\%} and \textbf{78.20\%} overall accuracy, respectively, outperforming existing lightweight memory systems while reducing LoCoMo per-query token cost by \textbf{24\%}. We further show that dimensional memory extraction is learnable by compact models: after fine-tuning on the DimMem schema, a Qwen3-4B extractor surpasses LightMem with GPT-4.1-mini on both benchmarks and reaches performance comparable to, or better than, much larger extractors in key settings. These results suggest that explicit dimensional structuring is an effective and efficient foundation for long-term memory in LLM agents. Code is available at https://github.com/ChowRunFa/DimMem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DimMem, a lightweight dimensional memory framework for LLM agents that represents each memory as an atomic unit with explicit fields (time, location, reason, purpose, keywords). This structure supports dimension-aware retrieval, memory updates, and selective context recall without storing full dialogue histories. Empirical results show DimMem achieving 81.43% overall accuracy on LoCoMo-10 and 78.20% on LongMemEval-S, outperforming existing lightweight memory systems with a 24% reduction in LoCoMo per-query token cost. The work also shows that a Qwen3-4B model fine-tuned on the DimMem schema can serve as an effective extractor, matching or exceeding larger models in key settings. Code is released at https://github.com/ChowRunFa/DimMem.
Significance. If the results hold after addressing the noted gaps, this work offers a practical path to balancing fidelity and efficiency in long-term agent memory by leveraging explicit dimensional structure rather than raw histories or flat summaries. The release of code and the demonstration that compact models can learn the extraction task are clear strengths supporting reproducibility. The findings could inform memory module design in LLM agent systems, particularly where token efficiency and precise recall are priorities.
major comments (2)
- [Results section, Table 1] Results section, Table 1 (or equivalent benchmark table): The overall accuracies of 81.43% on LoCoMo-10 and 78.20% on LongMemEval-S are reported without error bars, standard deviations, or statistical significance tests relative to baselines such as LightMem. This makes it difficult to assess the reliability of the claimed outperformance and 24% token reduction.
- [§4.3 Ablation Studies] §4.3 or Ablation Studies subsection: The evaluation compares a fine-tuned Qwen3-4B DimMem extractor against LightMem (GPT-4.1-mini) but provides no controlled ablation that holds the extractor model fixed while varying only the representation (dimensional fields vs. flat text or summary). This leaves open whether the performance lift is attributable to the explicit fields or primarily to schema-specific fine-tuning, directly affecting the central claim that the chosen fields enable precise recall without full history.
minor comments (2)
- [Abstract] Abstract: The 24% token cost reduction is stated without specifying the exact baseline system or providing absolute token counts for context.
- [Figures] Figure captions and legends: Some figures illustrating retrieval flow would benefit from explicit labels indicating how dimension-specific queries map to selected memory units.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve statistical reporting and add a controlled ablation.
read point-by-point responses
-
Referee: [Results section, Table 1] Results section, Table 1 (or equivalent benchmark table): The overall accuracies of 81.43% on LoCoMo-10 and 78.20% on LongMemEval-S are reported without error bars, standard deviations, or statistical significance tests relative to baselines such as LightMem. This makes it difficult to assess the reliability of the claimed outperformance and 24% token reduction.
Authors: We agree that error bars and statistical tests are needed to strengthen the claims. In the revision we will rerun all evaluations across 5 random seeds, report means with standard deviations in Table 1, and include paired significance tests (e.g., t-tests) against LightMem and other baselines. The 24% token reduction will also be reported with variance. revision: yes
-
Referee: [§4.3 Ablation Studies] §4.3 or Ablation Studies subsection: The evaluation compares a fine-tuned Qwen3-4B DimMem extractor against LightMem (GPT-4.1-mini) but provides no controlled ablation that holds the extractor model fixed while varying only the representation (dimensional fields vs. flat text or summary). This leaves open whether the performance lift is attributable to the explicit fields or primarily to schema-specific fine-tuning, directly affecting the central claim that the chosen fields enable precise recall without full history.
Authors: This is a fair observation. To isolate the contribution of the dimensional fields, we will add a controlled ablation in the revised §4.3 that fine-tunes the identical Qwen3-4B model on both the DimMem schema and a flat-text/summary schema, then evaluates both on LoCoMo-10 and LongMemEval-S under the same retrieval protocol. This will directly test whether the explicit fields, rather than fine-tuning alone, drive the observed gains. revision: yes
Circularity Check
No circularity: purely empirical proposal and benchmark results
full rationale
The paper introduces DimMem as a structured memory representation with explicit fields and reports empirical accuracies (81.43% on LoCoMo-10, 78.20% on LongMemEval-S) plus token reduction after fine-tuning a Qwen3-4B extractor on the schema. No equations, derivations, or self-referential definitions appear in the provided text; performance numbers are obtained via standard benchmark evaluation rather than any fitted parameter renamed as a prediction or any load-bearing self-citation chain. The central claim rests on comparative results against baselines, which are externally falsifiable and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit fields such as time, location, reason, purpose, and keywords expose sufficient structure for dimension-aware retrieval and selective context recall.
invented entities (1)
-
Dimensional memory unit
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DimMem represents each memory as an atomic, typed, and self-contained unit with explicit fields such as time, location, reason, purpose, and keywords. This representation exposes the structure needed for dimension-aware retrieval, memory update, and selective assistant-context recall
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Inspired by cognitive distinctions among episodic, semantic, and personal semantic memory and by event-oriented 5W1H information structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.