SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?
Pith reviewed 2026-05-20 18:59 UTC · model grok-4.3
The pith
LLM-based computer-using agents complete fewer than 4% of realistic professional SaaS tasks end-to-end.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
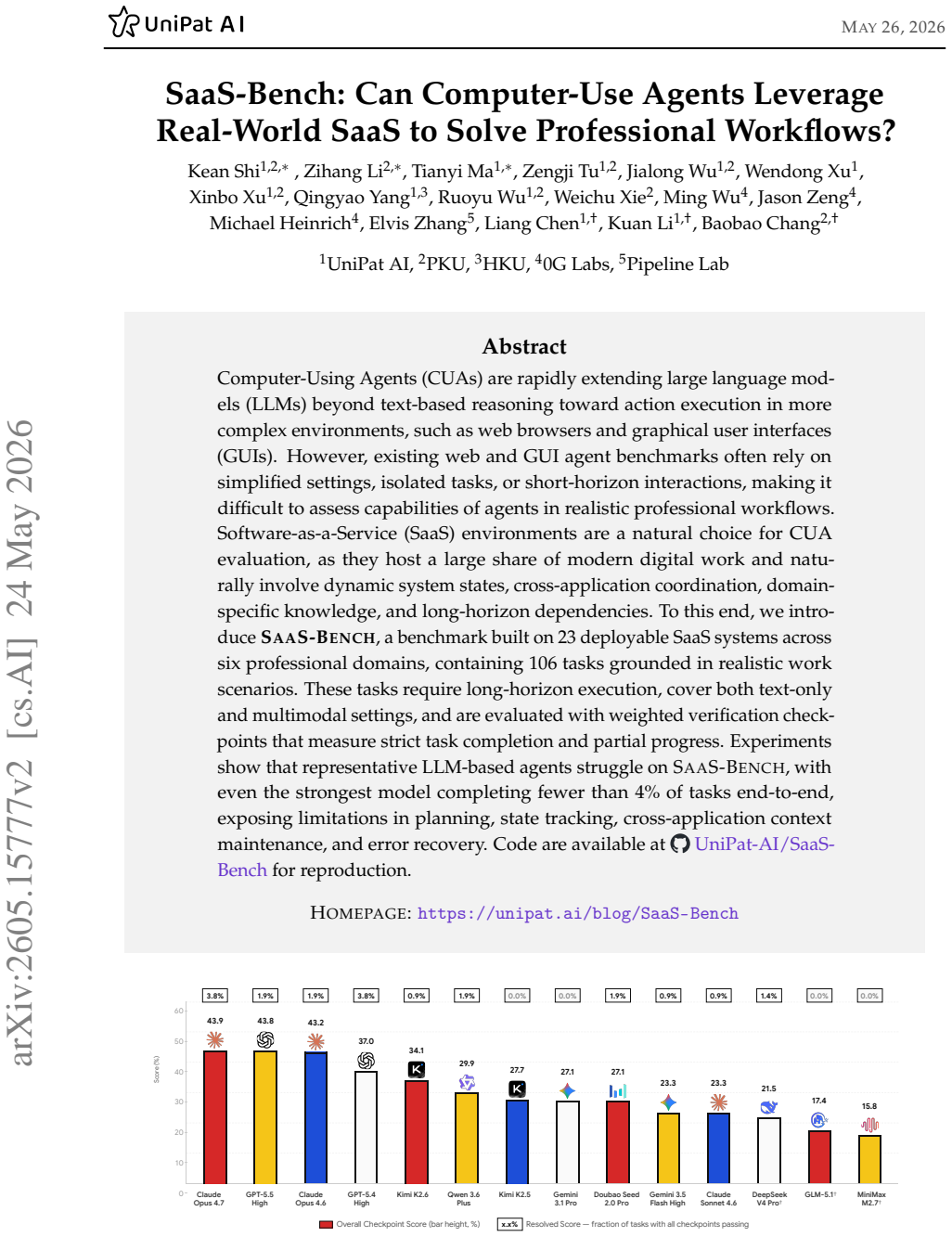
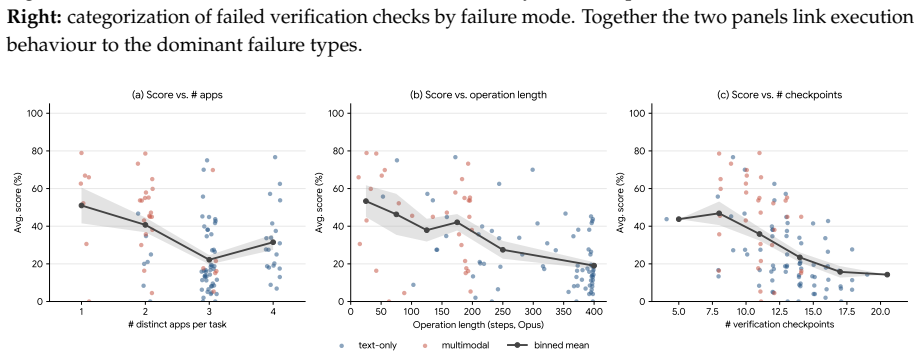
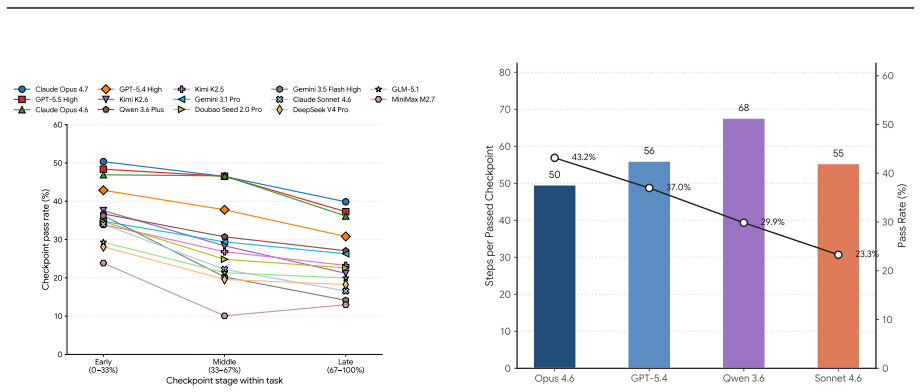
SaaS-Bench is introduced as a benchmark built on 23 deployable SaaS systems across six domains with 106 tasks grounded in realistic scenarios. These tasks involve long-horizon execution in both text and multimodal settings and use weighted verification checkpoints to measure completion and progress. Representative LLM-based agents struggle, with the strongest completing fewer than 4% of tasks end-to-end, revealing limitations in planning, state tracking, cross-application context maintenance, and error recovery.
What carries the argument
SaaS-Bench benchmark with its 106 tasks and weighted verification checkpoints, which evaluates agents on dynamic system states and cross-application coordination in professional SaaS environments.
If this is right
- Current agents lack the ability to maintain context across multiple applications over long periods.
- Error recovery is a critical missing capability for handling real workflows.
- Both planning and state tracking need significant improvement to achieve practical utility.
- The benchmark highlights the need for agents that can handle multimodal inputs effectively in GUI settings.
Where Pith is reading between the lines
- If true, this implies that future agent research should prioritize architectures with explicit memory or state management modules.
- The results could motivate development of hybrid systems that combine LLM reasoning with rule-based automation for SaaS tasks.
- Extending the benchmark to include more domains might reveal domain-specific strengths or weaknesses in agent performance.
Load-bearing premise
The assumption that the selected 106 tasks accurately represent realistic professional workflows and that the weighted checkpoints reliably indicate task success or partial progress.
What would settle it
A new agent design that achieves end-to-end completion on more than 20% of the 106 tasks would challenge the reported limitations of current approaches.
Figures






read the original abstract
Computer-Using Agents (CUAs) are rapidly extending large language models (LLMs) beyond text-based reasoning toward action execution in more complex environments, such as web browsers and graphical user interfaces (GUIs). However, existing web and GUI agent benchmarks often rely on simplified settings, isolated tasks, or short-horizon interactions, making it difficult to assess capabilities of agents in realistic professional workflows. Software-as-a-Service (SaaS) environments are a natural choice for CUA evaluation, as they host a large share of modern digital work and naturally involve dynamic system states, cross-application coordination, domain-specific knowledge, and long-horizon dependencies. To this end, we introduce SaaS-Bench, a benchmark built on 23 deployable SaaS systems across six professional domains, containing 106 tasks grounded in realistic work scenarios. These tasks require long-horizon execution, cover both text-only and multimodal settings, and are evaluated with weighted verification checkpoints that measure strict task completion and partial progress. Experiments show that representative LLM-based agents struggle on SaaS-Bench, with even the strongest model completing fewer than 4% of tasks end-to-end, exposing limitations in planning, state tracking, cross-application context maintenance, and error recovery. Code are available at https://github.com/UniPat-AI/SaaS-Bench for reproduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SaaS-Bench, a benchmark built on 23 deployable real-world SaaS systems across six professional domains, containing 106 tasks grounded in realistic work scenarios. These tasks emphasize long-horizon execution, dynamic states, cross-application coordination, and both text-only and multimodal interactions. Evaluation uses weighted verification checkpoints to measure strict end-to-end task completion as well as partial progress. Experiments with representative LLM-based computer-use agents report that even the strongest model completes fewer than 4% of tasks end-to-end, highlighting limitations in planning, state tracking, cross-application context maintenance, and error recovery. Code is released for reproduction.
Significance. If the tasks accurately reflect professional workflows and the verification method reliably distinguishes full completion from partial progress, the benchmark would fill a notable gap left by existing simplified web and GUI agent evaluations. The reported sub-4% success rates would then constitute a concrete, falsifiable signal of current agent shortcomings in realistic SaaS settings. The public code release is a clear strength that supports reproducibility and future extensions.
major comments (1)
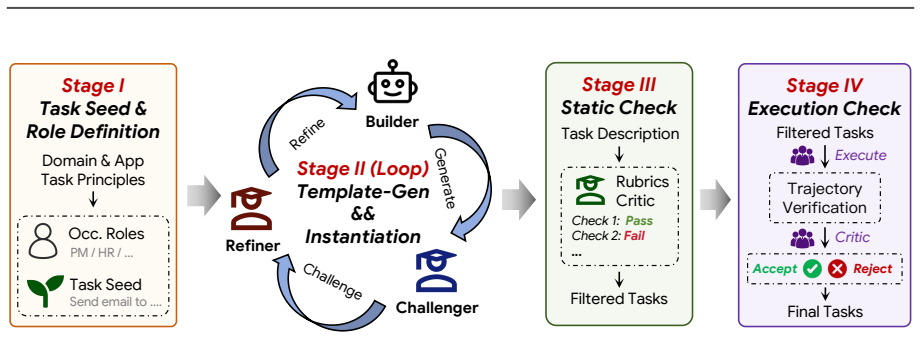
- [§3] §3 (Benchmark Construction) and the associated verification protocol: the manuscript does not provide quantitative details on how the weighted checkpoints were derived, how weights were assigned to sub-steps, inter-rater agreement for task grounding, or sensitivity analysis for missing critical state transitions. Because the central claim of <4% end-to-end success rests on these checkpoints accurately measuring strict completion rather than benchmark artifacts, this omission is load-bearing and requires explicit documentation or supplementary material.
minor comments (1)
- The abstract contains a minor grammatical issue ('Code are available' should read 'Code is available').
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and commit to revisions that directly respond to the concerns raised about documentation of the verification protocol.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction) and the associated verification protocol: the manuscript does not provide quantitative details on how the weighted checkpoints were derived, how weights were assigned to sub-steps, inter-rater agreement for task grounding, or sensitivity analysis for missing critical state transitions. Because the central claim of <4% end-to-end success rests on these checkpoints accurately measuring strict completion rather than benchmark artifacts, this omission is load-bearing and requires explicit documentation or supplementary material.
Authors: We agree that the current manuscript provides only a high-level description of the weighted verification checkpoints in §3 and that additional quantitative details are required to substantiate the evaluation protocol. In the revised version we will expand §3 with a new subsection that (1) explains the derivation process, including the use of domain-expert review to identify critical state transitions and assign weights proportionally to their impact on task completion; (2) reports the exact weighting scheme and the rationale for each weight value; (3) presents inter-rater agreement statistics (Cohen’s κ) obtained from the three annotators who independently grounded each task and its checkpoints; and (4) includes a sensitivity analysis (moved to the appendix) that perturbs checkpoint weights and omits selected state transitions to show that the reported sub-4 % end-to-end success rate remains stable. These additions will be supported by new tables and will not alter any experimental results. We believe the expanded documentation will eliminate concerns about benchmark artifacts while preserving the paper’s central claims. revision: yes
Circularity Check
No circularity: empirical benchmark results are direct measurements
full rationale
The paper introduces SaaS-Bench as a new collection of 106 tasks on 23 real SaaS systems and reports measured agent success rates (under 4% end-to-end) from direct experiments. No equations, fitted parameters, or derivations are present; the headline percentages are observations on the constructed benchmark rather than quantities forced by self-definition, renamed fits, or self-citation chains. Task design and weighted checkpoints are presented as independent engineering choices grounded in professional scenarios, with no reduction of the reported outcomes back to the inputs by construction. This is a standard empirical benchmark paper whose central claims remain falsifiable against external agent runs and do not rely on any load-bearing self-referential step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SaaS environments naturally involve dynamic system states, cross-application coordination, and long-horizon dependencies suitable for CUA evaluation.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Sixth International Conference on Learning Representations (ICLR) , year =
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration , author =. Proceedings of the Sixth International Conference on Learning Representations (ICLR) , year =
-
[2]
Xiang Deng and Yu Gu and Boyuan Zheng and Shijie Chen and Samuel Stevens and Boshi Wang and Huan Sun and Yu Su , booktitle =
-
[3]
Jing Yu Koh and Robert Lo and Lawrence Jang and Vikram Duvvur and Ming Chong Lim and Po-Yu Huang and Graham Neubig and Shuyan Zhou and Ruslan Salakhutdinov and Daniel Fried , booktitle =. 2024 , url =
work page 2024
-
[4]
Tianbao Xie and Danyang Zhang and Jixuan Chen and Xiaochuan Li and Siheng Zhao and Ruisheng Cao and Toh Jing Hua and Zhoujun Cheng and Dongchan Shin and Fangyu Lei and Yitao Liu and Yiheng Xu and Shuyan Zhou and Silvio Savarese and Caiming Xiong and Victor Zhong and Tao Yu , booktitle =. 2024 , url =
work page 2024
-
[5]
Tianci Xue and Weijian Qi and Tianneng Shi and Chan Hee Song and Boyu Gou and Dawn Song and Huan Sun and Yu Su , booktitle =. An Illusion of Progress?. 2025 , url =
work page 2025
- [6]
- [7]
-
[8]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin and Maxime Gasse and Massimo Caccia and Issam H. Laradji and Manuel Del Verme and Tom Marty and L. arXiv preprint arXiv:2403.07718 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
L. Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
-
[10]
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , journal =
- [11]
-
[12]
Browser-Use: Make Websites Accessible for
Magnus M\". Browser-Use: Make Websites Accessible for. 2024 , howpublished =
work page 2024
-
[13]
Izzeddin Gur and Hiroki Furuta and Austin Huang and Mustafa Safdari and Yutaka Matsuo and Douglas Eck and Aleksandra Faust , booktitle =. A Real-World
-
[14]
Boyuan Zheng and Boyu Gou and Jihyung Kil and Huan Sun and Yu Su , booktitle =. 2024 , url =
work page 2024
-
[15]
Wenyi Hong and Weihan Wang and Qingsong Lv and Jiazheng Xu and Wenmeng Yu and Junhui Ji and Yan Wang and Zihan Wang and Yuxuan Zhang and Juanzi Li and Bin Xu and Yuxiao Dong and Ming Ding and Jie Tang , booktitle =. 2024 , url =
work page 2024
-
[16]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents , author=. 2025 , eprint=
work page 2025
- [17]
- [18]
- [19]
- [20]
-
[21]
Seed2.0 Model Card: Towards Intelligence Frontier for Real-World Complexity , author =. 2026 , month =
work page 2026
- [22]
-
[23]
MiniMax M2.7: Early Echoes of Self-Evolution , author =. 2026 , month =
work page 2026
-
[24]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author =. 2026 , month =
work page 2026
-
[25]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents , author=. 2025 , eprint=
work page 2025
-
[26]
OpenCUA: Open Foundations for Computer-Use Agents , author=. 2025 , eprint=
work page 2025
- [27]
-
[28]
Introducing Computer Use, a New Claude 3.5 Sonnet, and Claude 3.5 Haiku , author =. 2024 , month =
work page 2024
-
[29]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models , author=. 2024 , eprint=
work page 2024
-
[30]
What is Software as a Service (SaaS)? , author =. 2025 , howpublished =
work page 2025
-
[31]
Gartner Forecasts Worldwide Public Cloud End-User Spending to Total \ 723 Billion in 2025 , author =. 2024 , month =
work page 2025
-
[32]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Theagentcompany: benchmarking llm agents on consequential real world tasks , author=. arXiv preprint arXiv:2412.14161 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon: Mixed-Modal Early-Fusion Foundation Models , author=. arXiv preprint arXiv:2405.09818 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model , author=. arXiv preprint arXiv:2408.11039 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [35]
-
[36]
Bagel: Unified Model for Image Understanding and Generation , author=. 2025 , url=
work page 2025
- [37]
-
[38]
Veo 2: Google's most capable video generation model , author=. 2024 , url=
work page 2024
- [39]
- [40]
- [41]
- [42]
- [43]
- [44]
- [45]
-
[46]
The child's creation of a pictorial world , author=. 2003 , publisher=
work page 2003
-
[47]
European journal of disorders of communication , volume=
Beyond modularity: A developmental perspective on cognitive science , author=. European journal of disorders of communication , volume=. 1994 , publisher=
work page 1994
-
[48]
Wiley Interdisciplinary Reviews: Cognitive Science , volume=
Development of visual perception , author=. Wiley Interdisciplinary Reviews: Cognitive Science , volume=. 2010 , publisher=
work page 2010
-
[49]
Development of human visual function , author=. Vision research , volume=. 2011 , publisher=
work page 2011
-
[50]
Infant visual perception , author=
-
[51]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[52]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[53]
M. J. Kearns , title =
-
[54]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[55]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[56]
Suppressed for Anonymity , author=
-
[57]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[58]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[59]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [60]
-
[61]
ByteDance Seed , title =
-
[62]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. 2025 , eprint=
work page 2025
-
[63]
Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding , author=. 2025 , eprint=
work page 2025
-
[64]
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs , author=. 2024 , eprint=
work page 2024
-
[65]
MMEvalPro: Calibrating Multimodal Benchmarks Towards Trustworthy and Efficient Evaluation , author=. 2025 , eprint=
work page 2025
- [66]
- [67]
-
[68]
GLM-V Team , title =
-
[69]
EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework , author =
-
[70]
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
work page 2024
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[72]
International Conference on Learning Representations , year=
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts , author=. International Conference on Learning Representations , year=
-
[73]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , author=. arXiv preprint arXiv:2306.13394 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
European Conference on Computer Vision , pages=
BLINK: Multimodal Large Language Models Can See but Not Perceive , author=. European Conference on Computer Vision , pages=. 2024 , publisher=
work page 2024
-
[75]
Advances in Neural Information Processing Systems , volume=
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
arXiv preprint arXiv:2510.13394 , year=
Spatial-DISE: A Unified Benchmark for Evaluating Spatial Reasoning in Vision-Language Models , author=. arXiv preprint arXiv:2510.13394 , year=
-
[77]
Object permanence in five-month-old infants , author=. Cognition , volume=. 1985 , publisher=
work page 1985
- [78]
-
[79]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark , author=. arXiv preprint arXiv:2409.02813 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , author=. arXiv preprint arXiv:2402.14804 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.