UniER: A Unified Benchmark for Item-level and Path-level Exercise Recommendation
Pith reviewed 2026-05-19 20:57 UTC · model grok-4.3
The pith
A unified benchmark shows path-level exercise recommendation consistently outperforms item-level methods across effectiveness, robustness, and sparse data conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
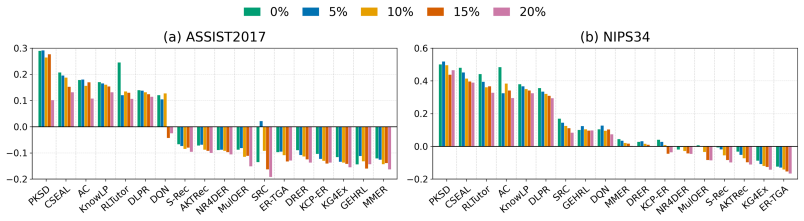
UniER supplies a common evaluation framework that measures both ILER and PLER through the Weighted Cognitive Gain metric on nine datasets produced by four generation procedures. Direct comparison of eighteen representative algorithms demonstrates systematic superiority of PLER in effectiveness, generalizability, robustness, and efficiency while exposing the pedagogical shortcomings of ILER under extreme sparsity and noise.
What carries the argument
The Weighted Cognitive Gain metric, which quantifies cumulative learning benefit in a manner that applies equally to single-step and multi-step recommendation settings.
If this is right
- Path-level methods should be favored when the goal is to build coherent sequences that accumulate learning gains over multiple steps.
- Item-level methods need redesign to avoid producing fragmented suggestions that degrade under sparse or noisy student data.
- The released UniER codebase enables direct, reproducible head-to-head tests of new recommendation algorithms.
- Benchmark results point toward concentrating future algorithm development on path-construction techniques rather than isolated exercise selection.
Where Pith is reading between the lines
- Learning platforms could gain from adopting path-level planning to improve student progression and retention rates.
- The unification approach may transfer to other sequential recommendation settings such as skill acquisition or training curricula.
- Live deployment tests in actual courses would be a natural next step to check whether the observed advantages hold outside synthetic datasets.
Load-bearing premise
The four dataset generation methods create records that match real student learning patterns and the Weighted Cognitive Gain metric accurately measures total learning benefit for both single-step and multi-step approaches.
What would settle it
A controlled study using actual classroom performance records in which item-level methods produce higher average long-term mastery gains than path-level methods would falsify the reported dominance.
Figures




read the original abstract
Personalized exercise recommendation dynamically aligns pedagogical resources with individual knowledge mastery, which is crucial for satisfying students' dynamic learning needs in modern education. The field is currently driven by two dominant paradigms: Item-Level Exercise Recommendation (ILER) optimizes for immediate single-step state transitions, while Path-Level Exercise Recommendation (PLER) constructs coherent learning paths to maximize cumulative gains. Despite sharing the same ultimate objective, disparate evaluation setups have kept these two lines of research isolated, hindering unified benchmarking and fair comparison. To fill the gap, in this paper, we present a Unified Benchmark for Exercise Recommendation (UniER), a comprehensive evaluation framework that unifies ILER and PLER. Specifically, we introduce Weighted Cognitive Gain (WCG) as a unified metric to measure cross-paradigm algorithmic performance. Our benchmark encompasses 9 datasets spanning four generation methods, facilitating the comparison of 18 representative ILER/PLER methods. Through multi-dimensional analyses covering effectiveness, generalizability, robustness, and efficiency, our results reveal the systematic dominance of PLER and expose the pedagogical failure of ILER's fragmented recommendations under extreme sparsity and noise. Furthermore, we provide an open-source codebase of UniER to foster reproducible research and outline potential directions for future investigations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniER, a unified benchmark for Item-Level Exercise Recommendation (ILER) and Path-Level Exercise Recommendation (PLER). It proposes the Weighted Cognitive Gain (WCG) as a cross-paradigm metric, constructs 9 datasets via four generation methods, evaluates 18 representative methods, and reports systematic PLER dominance in effectiveness, generalizability, robustness, and efficiency, particularly under sparsity and noise, while exposing limitations of ILER's fragmented recommendations.
Significance. If the central assumptions hold, this work provides a valuable service by unifying two previously isolated research lines in educational recommendation, supplying an open-source codebase for reproducibility, and offering multi-dimensional empirical comparisons that could steer the field toward path-coherent approaches.
major comments (2)
- [Dataset construction and experimental setup sections] The central claims of systematic PLER dominance and ILER pedagogical failure rest on the fidelity of the four dataset generation methods to real student learning dynamics. The manuscript should include explicit validation (e.g., statistical alignment with real educational logs or sensitivity checks on generation parameters) to demonstrate that these synthetic datasets do not embed structural biases favoring path coherence over fragmented item selection.
- [Weighted Cognitive Gain definition and evaluation sections] WCG is introduced as the unifying metric for comparing single-step and multi-step paradigms, yet the paper provides no independent evidence (such as correlation with post-sequence mastery tests or observable learning outcomes) that it correctly quantifies cumulative pedagogical benefit across both ILER and PLER. Without such grounding, the reported advantages may be partly metric-dependent.
minor comments (2)
- [Metric definition] Clarify the exact weighting scheme and normalization steps in the WCG formula to ensure readers can reproduce the cross-paradigm scores.
- [Methods overview] Add a table summarizing the 18 methods with their key hyperparameters and computational complexity to support the efficiency analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the revisions we intend to incorporate.
read point-by-point responses
-
Referee: [Dataset construction and experimental setup sections] The central claims of systematic PLER dominance and ILER pedagogical failure rest on the fidelity of the four dataset generation methods to real student learning dynamics. The manuscript should include explicit validation (e.g., statistical alignment with real educational logs or sensitivity checks on generation parameters) to demonstrate that these synthetic datasets do not embed structural biases favoring path coherence over fragmented item selection.
Authors: We agree that stronger validation of the synthetic datasets would reinforce the central claims. In the revised manuscript we will add a dedicated sensitivity analysis subsection that systematically varies the key generation parameters (noise intensity, sparsity ratio, and path coherence constraints) across all four methods and reports that the observed PLER advantages remain consistent. We will also include a table comparing aggregate statistical properties of the generated datasets (transition probabilities, knowledge-component coverage, and path-length distributions) with those documented in prior studies that used real educational logs. These additions directly address the concern about potential structural bias while remaining within the scope of a benchmarking paper. revision: yes
-
Referee: [Weighted Cognitive Gain definition and evaluation sections] WCG is introduced as the unifying metric for comparing single-step and multi-step paradigms, yet the paper provides no independent evidence (such as correlation with post-sequence mastery tests or observable learning outcomes) that it correctly quantifies cumulative pedagogical benefit across both ILER and PLER. Without such grounding, the reported advantages may be partly metric-dependent.
Authors: We acknowledge that direct empirical grounding of WCG against post-sequence mastery tests would be desirable. WCG extends standard cognitive-gain formulations from educational psychology by weighting mastery increments according to knowledge-component importance and sequence coherence; we will expand the metric-definition section with an explicit derivation, additional references to the cognitive-model literature, and a side-by-side comparison against simpler alternatives (raw accuracy, path-completion rate). Because obtaining new human-subject mastery-test correlations lies outside the present benchmarking study, we will add an explicit limitations paragraph noting this assumption and listing controlled user studies as future work. The multi-dimensional robustness and efficiency results already provide indirect support that the reported PLER advantages are not artifacts of the metric alone. revision: partial
Circularity Check
Empirical benchmark evaluation is self-contained with no reduction of claims to fitted inputs or self-citations
full rationale
The paper introduces a unified benchmark framework and the WCG metric to compare ILER and PLER methods across 9 datasets generated by four methods. All reported results on dominance, generalizability, robustness, and efficiency are direct empirical outcomes from these external comparisons rather than any derivation, equation, or prediction that reduces by construction to parameters or definitions internal to the paper. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing justifications for the central claims. The evaluation setup therefore stands as independent evidence against the provided datasets and metric.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Weighted Cognitive Gain correctly captures learning benefit for both single-step and path-level recommendations
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Weighted Cognitive Gain (WCG) as a unified metric... 9 datasets spanning four generation methods... 18 representative ILER/PLER methods.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Through multi-dimensional analyses covering effectiveness, generalizability, robustness, and efficiency, our results reveal the systematic dominance of PLER
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
NR4DER: Neural Re- ranking for Diversified Exercise Recommendation,
X. Cheng, X. Zhou, L. Fang, C. He, Y . Zhou, W. Luo, Z. Gong, and Q. Guan, “NR4DER: Neural Re- ranking for Diversified Exercise Recommendation,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR-2025), 2025, pp. 1738–1747
work page 2025
-
[2]
Exploiting Cognitive Structure for Adaptive Learning,
Q. Liu, S. Tong, C. Liu, H. Zhao, E. Chen, H. Ma, and S. Wang, “Exploiting Cognitive Structure for Adaptive Learning,” inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (SIGKDD-2019), 2019, pp. 627–635
work page 2019
-
[3]
D. C. Rajapakse and D. Jannach, “Reassessing the Effectiveness of Reinforcement Learning based Recom- mender Systems for Sequential Recommendation,” inProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2025), 2025, pp. 3306–3314
work page 2025
-
[4]
User-item fairness tradeoffs in recommendations,
S. Greenwood, S. Chiniah, and N. Garg, “User-item fairness tradeoffs in recommendations,” inAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), vol. 37, 2024, pp. 114 236–114 288
work page 2024
-
[5]
Understanding and Improving Adversarial Collaborative Filtering for Robust Recommendation,
K. Zhang, Q. Cao, Y . Wu, F. Sun, H. Shen, and X. Cheng, “Understanding and Improving Adversarial Collaborative Filtering for Robust Recommendation,” inAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), vol. 37, 2024, pp. 120 381–120 417
work page 2024
-
[6]
Influence-aware successive point-of-interest recommendation,
X. Cheng, N. Li, G. Rysbayeva, Q. Yang, and J. Zhang, “Influence-aware successive point-of-interest recommendation,”World Wide Web, vol. 26, no. 2, pp. 615–629, 2023
work page 2023
-
[7]
Exercise Recommendation Based on Knowledge Concept Prediction,
Z. Wu, M. Li, Y . Tang, and Q. Liang, “Exercise Recommendation Based on Knowledge Concept Prediction,” Knowledge-Based Systems, vol. 210, p. 106481, 2020
work page 2020
-
[8]
KG4Ex: An Explainable Knowledge Graph-Based Approach for Exercise Recommendation,
Q. Guan, F. Xiao, X. Cheng, L. Fang, Z. Chen, G. Chen, and W. Luo, “KG4Ex: An Explainable Knowledge Graph-Based Approach for Exercise Recommendation,” inProceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM-2023), 2023, pp. 597–607
work page 2023
-
[9]
Q. Li, W. Xia, L. Yin, J. Jin, and Y . Yu, “Privileged Knowledge State Distillation for Reinforcement Learning-based Educational Path Recommendation,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD-2024), 2024, pp. 1621–1630
work page 2024
-
[10]
GraphRAG-Induced Dual Knowledge Structure Graphs for Personalized Learning Path Recommendation,
X. Cheng, Z. Zhang, J. Wang, L. Fang, C. He, Q. Guan, S. Pan, and W. Luo, “GraphRAG-Induced Dual Knowledge Structure Graphs for Personalized Learning Path Recommendation,” inProceedings of the 40th AAAI Conference on Artificial Intelligence (AAAI-2026), 2026, pp. 14 610–14 620
work page 2026
-
[11]
Hierarchical Reinforcement Learning: A Comprehen- sive Survey,
S. Pateria, B. Subagdja, A. hwee Tan, and C. Quek, “Hierarchical Reinforcement Learning: A Comprehen- sive Survey,”ACM Computing Surveys (CSUR), vol. 54, no. 5, pp. 1–35, 2021
work page 2021
-
[12]
F. Lord, “A theory of test scores.”Psychometric monographs, 1952
work page 1952
-
[13]
F. M. Lord,Applications of Item Response Theory to Practical Testing Problems. Routledge, 2012
work page 2012
-
[14]
C. Piech, J. Bassen, J. Huang, S. Ganguli, M. Sahami, L. Guibas, and J. Sohl-Dickstein, “Deep Knowledge Tracing,” inAdvances in Neural Information Processing Systems 28 (NIPS 2015), vol. 28, 2015
work page 2015
-
[15]
Learning patterns-guided data generation for knowledge tracing,
H. Ma, Y . Yin, Z. Wang, C. Wang, X. Yu, S. Yang, and X. Zhang, “Learning patterns-guided data generation for knowledge tracing,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2025), 2025, pp. 2031–2041
work page 2025
-
[16]
Exploring Multi-Objective Exercise Recommendations in Online Education Systems,
Z. Huang, Q. Liu, C. Zhai, Y . Yin, E. Chen, W. Gao, and G. Hu, “Exploring Multi-Objective Exercise Recommendations in Online Education Systems,” inProceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM-2019), 2019, pp. 1261–1270. 10
work page 2019
-
[17]
Context-Aware Attentive Knowledge Tracing,
A. Ghosh, N. Heffernan, and A. S.Lan, “Context-Aware Attentive Knowledge Tracing,” inProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (SIGKDD- 2020), 2020, pp. 2330–2339
work page 2020
-
[18]
SimpleKT: a Simple but Tough-to-Beat Baseline for Knowledge Tracing,
Z. Liu, Q. Liu, J. Chen, S. Huang, and W. Luo, “SimpleKT: a Simple but Tough-to-Beat Baseline for Knowledge Tracing,” inProceedings of the 11th International Conference on Learning Representations (ICLR-2023), 2023, pp. 20 276–20 287
work page 2023
-
[19]
Meta Multi-Agent Exercise Recommendation: A Game Application Perspective,
F. Liu, X. Hu, S. Liu, C. Bu, and L. Wu, “Meta Multi-Agent Exercise Recommendation: A Game Application Perspective,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD-2023), 2023, pp. 1441–1452
work page 2023
-
[20]
Y . Ren, K. Liang, Y . Shang, and Y . Zhang, “MulOER-SAN: 2-Layer Multi-Objective Framework for Exercise Recommendation with Self-Attention Networks,”Knowledge-Based Systems, vol. 260, p. 110117, 2023
work page 2023
-
[21]
G. Liu, M. Ren, L. Guo, J. Li, and M. Ma, “Comprehensive Exercise Recommendation with Practicality, Generalizability, and Versatility in AI-Driven Education,”Information Processing & Management, vol. 62, no. 3, p. 104051, 2025
work page 2025
-
[22]
Set-to-Sequence Ranking-based Concept-Aware Learning Path Recommendation,
X. Chen, J. Shen, W. Xia, J. Jin, Y . Song, W. Zhang, W. Liu, M. Zhu, R. Tang, K. Dong, D. Xia, and Y . Yu, “Set-to-Sequence Ranking-based Concept-Aware Learning Path Recommendation,” inProceedings of the 37th AAAI Conference on Artificial Intelligence (AAAI-2023), 2023, pp. 5027–5035
work page 2023
-
[23]
Graph Enhanced Hierarchical Reinforcement Learning for Goal-oriented Learning Path Recommendation,
Q. Li, W. Xia, L. Yin, J. Shen, R. Rui, W. Zhang, X. Chen, R. Tang, and Y . Yu, “Graph Enhanced Hierarchical Reinforcement Learning for Goal-oriented Learning Path Recommendation,” inProceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM-2023), 2023, pp. 1318–1327
work page 2023
-
[24]
J. Wang, Z. Cui, B. Wang, S. Pan, J. Gao, B. Yin, and W. Gao, “IME: Integrating Multi-curvature Shared and Specific Embedding for Temporal Knowledge Graph Completion,” inProceedings of the ACM Web Conference 2024 (WWW-2024), 2024, pp. 1954–1962
work page 2024
-
[25]
Unraveling Privacy Risks of Individual Fairness in Graph Neural Networks,
H. Zhang, X. Yuan, and S. Pan, “Unraveling Privacy Risks of Individual Fairness in Graph Neural Networks,” inIEEE 40th International Conference on Data Engineering (ICDE-2024), 2024, pp. 1712–1725
work page 2024
-
[26]
Uncertainty-aware graph neural networks: A multihop evidence fusion approach,
Q. Chen, S. Li, Y . Liu, S. Pan, G. I. Webb, and S. Zhang, “Uncertainty-aware graph neural networks: A multihop evidence fusion approach,”IEEE Transactions on Neural Networks and Learning Systems, 2025
work page 2025
-
[27]
V . R. Konda and J. N. Tsitsiklis, “Actor-Critic Algorithms,” inAdvances in Neural Information Processing Systems 12 (NIPS-1999), 1999, pp. 1008–1014
work page 1999
-
[28]
A Reinforcement Learning Approach to Personalized Learning Recommendation Systems,
X. Tang, Y . Chen, X. Li, J. Liu, and Z. Ying, “A Reinforcement Learning Approach to Personalized Learning Recommendation Systems,”British Journal of Mathematical and Statistical Psychology, vol. 72, no. 1, pp. 108–135, 2019
work page 2019
-
[29]
Y . Kubotani, Y . Fukuhara, and S. Morishima, “Rltutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions,”arXiv preprint arXiv:2108.00268, 2021
-
[30]
Item-Difficulty-Aware Learning Path Recommendation: From a Real Walking Perspective,
H. Zhang, S. Shen, B. Xu, Z. Huang, J. Wu, J. Sha, and S. Wang, “Item-Difficulty-Aware Learning Path Recommendation: From a Real Walking Perspective,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD-2024), 2024, pp. 4167–4178
work page 2024
-
[31]
Knowledge Tracing with Sequential Key-Value Memory Networks,
G. Abdelrahman and Q. Wang, “Knowledge Tracing with Sequential Key-Value Memory Networks,” in Proceedings of the 42nd international ACM SIGIR conference on research and development in information retrieval (SIGIR 2019), 2019, pp. 175–184
work page 2019
-
[32]
XES3G5M: A Knowledge Tracing Benchmark Dataset with Auxiliary Information,
Z. Liu, Q. Liu, T. Guo, J. Chen, S. Huang, X. Zhao, J. Tang, W. Luo, and J. Weng, “XES3G5M: A Knowledge Tracing Benchmark Dataset with Auxiliary Information,” inAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), vol. 36, 2023, pp. 32 958–32 970
work page 2023
-
[33]
Algebra I 2005-2006 and Bridge to Algebra 2006-2007,
J. Stamper, A. Niculescu-Mizil, S. Ritter, G. Gordon, and K. Koedinger, “Algebra I 2005-2006 and Bridge to Algebra 2006-2007,”Development data sets from KDD Cup, 2010
work page 2005
-
[34]
pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models,
Z. Liu, Q. Liu, J. Chen, S. Huang, J. Tang, and W. Luo, “pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models,” inAdvances in Neural Information Processing Systems 35 (NeurIPS 2022), vol. 35, 2022, pp. 18 542–18 555. 11
work page 2022
-
[35]
Large Language Models-guided Dynamic Adaptation for Temporal Knowledge Graph Reasoning,
J. Wang, S. Kai, L. Luo, W. Wei, Y . Hu, A. W.-C. Liew, S. Pan, and B. Yin, “Large Language Models-guided Dynamic Adaptation for Temporal Knowledge Graph Reasoning,” inAdvances in Neural Information Processing Systems 38 (NeurIPS-2024), 2024, pp. 8384–8410
work page 2024
-
[36]
Made: Multicurvature Adaptive Embedding for Temporal Knowledge Graph Completion,
J. Wang, B. Wang, J. Gao, S. Pan, T. Liu, B. Yin, and W. Gao, “Made: Multicurvature Adaptive Embedding for Temporal Knowledge Graph Completion,”IEEE Transactions on Cybernetics, 2024
work page 2024
-
[37]
Explainable Exercise Recommendation with Knowledge Graph,
Q. Guan, X. Cheng, F. Xiao, Z. Li, C. He, L. Fang, G. Chen, Z. Gong, and W. Luo, “Explainable Exercise Recommendation with Knowledge Graph,”Neural Networks, vol. 183, p. 106954, 2025
work page 2025
-
[38]
Pytorch: An Imperative Style, High-Performance Deep Learning Library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An Imperative Style, High-Performance Deep Learning Library,” inAdvances in neural information processing systems 32 (NeurIPS 2019), vol. 32, 2019. 12 A Detailed Description of Datasets in UniER The description of datasets in UniE...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.