Pedestrian-Aware LLM-Driven Behavioral Planning for Autonomous Vehicles
Pith reviewed 2026-05-19 20:57 UTC · model grok-4.3
The pith
Large language models can guide autonomous vehicles around unpredictable pedestrians by turning scene observations into natural-language reasoning prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
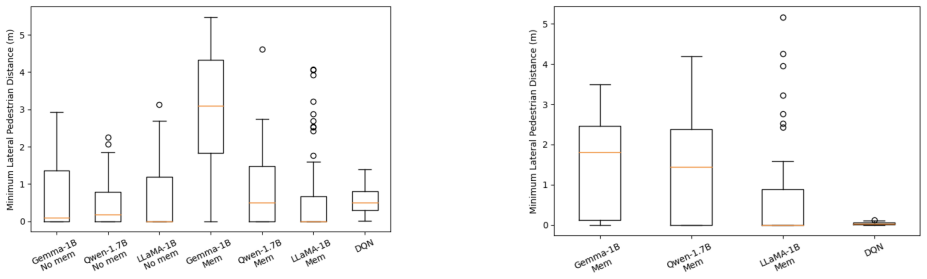
By converting structured scene observations into natural-language reasoning prompts, the LLM infers pedestrian intent and risk, then generates tactical driving decisions that achieve a 68 percent collision-free success rate in zero-shot tests across jaywalking, turn-back crossing, hesitation, and bidirectional scenarios, rising to 96 percent with few-shot episodic memory in single-pedestrian cases and exceeding both deep RL baselines at 17.7 percent and a custom DQN controller at 82 percent, while also showing transfer of memory across unseen behaviors.
What carries the argument
The conversion of structured scene observations into natural-language reasoning prompts that let the LLM perform pedestrian intent inference, risk anticipation, and generation of cautious tactical decisions.
If this is right
- The LLM agent initiates earlier responses and maintains wider safety buffers than the RL baselines.
- Episodic memory derived from one crossing type transfers to unseen hesitation and bidirectional scenarios at 82 percent and 90 percent success.
- The resulting decisions are interpretable and aligned with human-like caution.
- A separate motion planner ensures the high-level decisions produce smooth, kinematically feasible vehicle trajectories.
Where Pith is reading between the lines
- AV control stacks could incorporate LLM reasoning modules to reduce reliance on retraining RL policies for every new pedestrian pattern encountered in cities.
- The approach suggests a route to more transparent decision logs that regulators or passengers could inspect after an incident.
- Sensor data pipelines would need to supply accurate real-time scene descriptions if the method is moved from simulation to onboard hardware.
Load-bearing premise
The assumption that large language models will correctly interpret pedestrian intent from text prompts and avoid hallucinations that produce unsafe commands in novel, safety-critical situations.
What would settle it
A recorded instance in the SUMO simulator where the LLM produces a driving decision that results in a collision with a pedestrian exhibiting behavior outside the few-shot memory examples would directly test the reliability claim.
Figures





read the original abstract
Autonomous Vehicles (AVs) must make reliable decisions in dense urban environments where pedestrian behavior is variable, sometimes abnormal, and often unseen during training. Reinforcement learning (RL)-based AV control systems perform well in structured traffic but struggle to generalize to unpredictable pedestrian interactions and out-of-distribution scenarios. Their reliance on handcrafted rewards and opaque decisions further limits their suitability for safety-critical, pedestrian-rich environments. To address these limitations, we introduce a Large Language Model (LLM)-based decision-making framework for pedestrian-aware behavioral planning. The system converts structured scene observations into natural-language reasoning prompts, enabling the LLM to infer pedestrian intent, anticipate risk, and generate cautious tactical driving decisions. These decisions are executed by a motion planner that ensures smooth, kinematically feasible control. We evaluate the framework in SUMO across multiple pedestrian-interaction scenarios, including unexpected jaywalking, turn-back crossing, hesitation, and bidirectional crossing. In zero-shot evaluation, the LLM-based agent achieves a 68% collision-free success rate, substantially outperforming deep RL baselines (17.7%). With few-shot episodic memory in a single-pedestrian scenario, performance increases to 96.0%, exceeding a custom DQN controller (82.0%). Cross-behavior evaluation further shows that memory derived from turn-back interactions transfers to unseen hesitation and bidirectional crossing scenarios, achieving 82.0% and 90.0% success, respectively. The system consistently initiates earlier responses, maintains wider safety buffers, and produces interpretable, human-aligned decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an LLM-based behavioral planning framework for autonomous vehicles that serializes structured scene observations into natural-language prompts, allowing the LLM to infer pedestrian intent, anticipate risk, and output tactical decisions executed by a downstream motion planner. The system is evaluated in the SUMO simulator on pedestrian-interaction scenarios including jaywalking, turn-back crossing, hesitation, and bidirectional crossing. Reported results include 68% collision-free success in zero-shot evaluation (vs. 17.7% for deep RL baselines) and 96% with few-shot episodic memory in single-pedestrian cases (vs. 82% for a custom DQN), plus cross-behavior transfer achieving 82% and 90% on unseen hesitation and bidirectional scenarios.
Significance. If the performance gains and transfer results hold under rigorous scrutiny, the work would be significant for demonstrating that LLM-driven reasoning can improve generalization and interpretability in safety-critical AV planning where RL methods falter on out-of-distribution pedestrian behaviors. The cross-behavior memory transfer and emphasis on earlier responses with wider safety buffers represent concrete strengths that could inform hybrid planning architectures.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: The headline claims of 68% zero-shot and 96% few-shot collision-free success rates are presented without any description of the prompt templates, the exact serialization of scene observations into text, the architectures or training protocols of the deep RL and DQN baselines, or statistical significance of the differences. This information is load-bearing for the central claim that gains arise from LLM intent inference rather than differences in input representation or prompt heuristics.
- [Framework] Framework section: No example prompts, failure-mode analysis of the 32% zero-shot failures, or explicit comparison of information content between the natural-language prompts and the vector observations supplied to the RL baselines are provided. Without these, it remains unclear whether the LLM is performing robust risk anticipation or benefiting from surface-level pattern matching or implicitly encoded caution in the prompt design.
minor comments (2)
- [Abstract] The abstract refers to 'deep RL baselines' without naming the specific algorithms or hyper-parameters; adding this would aid reproducibility.
- [Evaluation] Clarify the exact definitions of 'collision-free success rate' and the number of simulation trials per scenario to allow readers to assess the reliability of the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments identify important gaps in transparency that we have addressed through targeted revisions to strengthen the manuscript's clarity and support for its central claims.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The headline claims of 68% zero-shot and 96% few-shot collision-free success rates are presented without any description of the prompt templates, the exact serialization of scene observations into text, the architectures or training protocols of the deep RL and DQN baselines, or statistical significance of the differences. This information is load-bearing for the central claim that gains arise from LLM intent inference rather than differences in input representation or prompt heuristics.
Authors: We agree that these supporting details are necessary to substantiate the performance claims and rule out alternative explanations. In the revised manuscript, we have added a detailed description of the prompt templates and the precise serialization process for converting structured scene observations into natural-language text within the Framework and Evaluation sections. We have also expanded the Evaluation section to specify the architectures (including network layers and input dimensions) and training protocols (hyperparameters, reward structures, and episode counts) for the deep RL baselines and the custom DQN. Finally, we now report results of statistical significance tests (paired t-tests across multiple random seeds) on the success-rate differences to confirm they are unlikely to arise from variance alone. These additions clarify the source of the observed gains. revision: yes
-
Referee: [Framework] Framework section: No example prompts, failure-mode analysis of the 32% zero-shot failures, or explicit comparison of information content between the natural-language prompts and the vector observations supplied to the RL baselines are provided. Without these, it remains unclear whether the LLM is performing robust risk anticipation or benefiting from surface-level pattern matching or implicitly encoded caution in the prompt design.
Authors: We concur that concrete examples and analysis are required to demonstrate the nature of the LLM's reasoning. The revised Framework section now includes two representative example prompts (one successful and one failure case) along with the corresponding scene observations. We have added a dedicated failure-mode subsection in the Evaluation section that categorizes the 32% zero-shot failures according to observable patterns such as mispredicted pedestrian intent, excessive conservatism, and edge-case simulation artifacts. We have further included an explicit side-by-side comparison of information content, noting that the natural-language prompts encode relational semantics, inferred goals, and risk heuristics absent from the raw vector observations fed to the RL agents. These changes help distinguish the contribution of higher-level reasoning from potential prompt heuristics. revision: yes
Circularity Check
No circularity: empirical simulation results independent of any derivation chain
full rationale
The paper describes an LLM-based behavioral planning framework that serializes structured observations into natural-language prompts for intent inference and decision generation, then evaluates collision-free success rates in SUMO simulations against RL baselines. No equations, fitted parameters, self-citations as load-bearing premises, or mathematical derivations appear in the abstract or described approach. Performance claims (68% zero-shot, 96% few-shot) are presented as direct empirical outcomes from simulation runs rather than any reduction to inputs by construction. The central evaluation is self-contained against external benchmarks and does not rely on renaming, ansatz smuggling, or uniqueness theorems from prior self-work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The system converts structured scene observations into natural-language reasoning prompts... kNN search retrieves... feature vector x=[dx, dy, v_ego, v_ped, TTC]
-
IndisputableMonolith/Foundation/Breath1024.leanperiod8 unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
period-8 and period-1024 periodic... eight-tick periodic micro-structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Q. Liuet al., “Autonomous highway merging in mixed traffic using reinforcement learning and motion predictive safety controller,” in 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2022, pp. 1063–1069
work page 2022
-
[2]
W. Zhouet al., “Multi-agent reinforcement learning for cooperative lane changing of connected and autonomous vehicles in mixed traffic,” Autonomous Intelligent Systems, vol. 2, no. 1, p. 5, 2022
work page 2022
-
[3]
Navigating occluded intersections with autonomous vehicles using deep reinforcement learning,
D. Iseleet al., “Navigating occluded intersections with autonomous vehicles using deep reinforcement learning,” in2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 2034– 2039
work page 2018
-
[4]
W. Wanget al., “Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving,”CoRR, 2023
work page 2023
-
[5]
L. Wanget al., “Accidentgpt: Accident analysis and prevention from v2x environmental perception with multi-modal large model,”CoRR, 2023
work page 2023
-
[6]
Making large language models better planners with reasoning-decision alignment,
Z. Huang, T. Tang, S. Chen, S. Lin, Z. Jie, L. Ma, G. Wang, and X. Liang, “Making large language models better planners with reasoning-decision alignment,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 73–90
work page 2024
-
[7]
A language agent for autonomous driving,
J. Maoet al., “A language agent for autonomous driving,” inProceedings of the First Conference on Language Modeling(COLM), 2024
work page 2024
-
[8]
Convoyllm: Dynamic multi-lane convoy control using llms,
L. Luet al., “Convoyllm: Dynamic multi-lane convoy control using llms,”arXiv preprint arXiv:2502.17529, 2025
-
[9]
Geodrive: Cross-city autonomous driving through meta-learning and llms,
M. Gaafaret al., “Geodrive: Cross-city autonomous driving through meta-learning and llms,” inProceedings of the 33rd ACM Interna- tional Conference on Advances in Geographic Information Systems, ser. SIGSPATIAL ’25. Association for Computing Machinery, 2025, p. 1292–1293
work page 2025
-
[10]
Llm - driven adaptive autonomous robot navigation via multimodal fusion for diverse environments,
X. Liuet al., “Llm - driven adaptive autonomous robot navigation via multimodal fusion for diverse environments,” in2025 IEEE Intelligent Vehicles Symposium (IV), 2025, pp. 2361–2368
work page 2025
-
[11]
T. Caiet al., “Driving with regulation: Interpretable decision-making for autonomous vehicles with retrieval-augmented reasoning via llm,”arXiv preprint arXiv:2410.04759, 2024
-
[12]
S. Wanget al., “Omnidrive: A holistic llm-agent framework for au- tonomous driving with 3d perception, reasoning and planning,”CoRR, vol. abs/2405.01533, 2024
-
[13]
Vipergpt: Visual inference via python execution for reasoning,
D. Sur ´ıset al., “Vipergpt: Visual inference via python execution for reasoning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 11 888–11 898
work page 2023
-
[14]
Z. Yanget al., “Doraemongpt: Toward understanding dynamic scenes with large language models (exemplified as a video agent),” inInter- national Conference on Machine Learning. PMLR, 2024, pp. 55 976– 55 997
work page 2024
-
[15]
B. B. Elallidet al., “Dqn-based reinforcement learning for vehicle control of autonomous vehicles interacting with pedestrians,” in2022 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT). IEEE, 2022, pp. 489–493
work page 2022
-
[16]
Llm-augmented driving behavior planning for au- tonomous vehicle,
A. Baimbetovaet al., “Llm-augmented driving behavior planning for au- tonomous vehicle,” inCompanion Proceedings of the 27th International Conference on Distributed Computing and Networking, ser. ICDCN Companion ’26. Association for Computing Machinery, 2026, p. 5–6
work page 2026
-
[17]
G. P. R. Papiniet al., “A reinforcement learning approach for enacting cautious behaviours in autonomous driving system: Safe speed choice in the interaction with distracted pedestrians,”IEEE transactions on intelligent transportation systems, vol. 23, no. 7, pp. 8805–8822, 2021
work page 2021
-
[18]
A survey of deep learning applications to autonomous vehicle control,
S. Kuuttiet al., “A survey of deep learning applications to autonomous vehicle control,”IEEE Transactions on Intelligent Transportation Sys- tems, vol. 22, no. 2, pp. 712–733, 2020
work page 2020
-
[19]
Conditional dqn-based motion planning with fuzzy logic for autonomous driving,
L. Chenet al., “Conditional dqn-based motion planning with fuzzy logic for autonomous driving,”IEEE Transactions on Intelligent Transporta- tion Systems, vol. 23, no. 4, pp. 2966–2977, 2022
work page 2022
-
[20]
M. Zhuet al., “Safe, efficient, and comfortable velocity control based on reinforcement learning for autonomous driving,”Transportation Research Part C: Emerging Technologies, vol. 117, p. 102662, 2020
work page 2020
-
[21]
Y . Luet al., “Hierarchical reinforcement learning for autonomous decision making and motion planning of intelligent vehicles,”IEEE Access, vol. 8, pp. 209 776–209 789, 2020
work page 2020
-
[22]
D. Pathareet al., “Tactical decision making for autonomous trucks by deep reinforcement learning with total cost of operation based reward,” arXiv preprint arXiv:2403.06524, 2024
-
[23]
Diffusiondrive: Truncated diffusion model for end-to- end autonomous driving,
B. Liaoet al., “Diffusiondrive: Truncated diffusion model for end-to- end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 037–12 047
work page 2025
-
[24]
Generating human daily activities with llm for smart home simulator agents,
H. Yonekuraet al., “Generating human daily activities with llm for smart home simulator agents,” in2024 International Conference on Intelligent Environments (IE), 2024, pp. 93–96
work page 2024
-
[25]
Driving everywhere with large language model policy adaptation,
B. Liet al., “Driving everywhere with large language model policy adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 948–14 957
work page 2024
-
[26]
R. Trumppet al., “Modeling interactions of autonomous vehicles and pedestrians with deep multi-agent reinforcement learning for collision avoidance,” in2022 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2022, pp. 331–336
work page 2022
-
[27]
Gpt-4v takes the wheel: Promises and challenges for pedestrian behavior prediction,
J. Huanget al., “Gpt-4v takes the wheel: Promises and challenges for pedestrian behavior prediction,” inProceedings of the AAAI Symposium Series, vol. 3, no. 1, 2024, pp. 134–142
work page 2024
-
[28]
Kinematic modeling and redundancy resolution for nonholonomic mobile manipulators,
A. De Lucaet al., “Kinematic modeling and redundancy resolution for nonholonomic mobile manipulators,” inProceedings 2006 IEEE International Conference on Robotics and Automation, 2006. ICRA 2006.IEEE, 2006, pp. 1867–1873
work page 2006
-
[29]
C.-J. Hoelet al., “Tactical decision-making in autonomous driving by reinforcement learning with uncertainty estimation,” in2020 IEEE intelligent vehicles symposium (IV). IEEE, 2020, pp. 1563–1569
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.