Roll Out and Roll Back: Diffusion LLMs are Their Own Efficiency Teachers
Pith reviewed 2026-05-19 20:38 UTC · model grok-4.3
The pith
Diffusion LLMs discover reliable parallel decoding orders through revokable generation and then learn to use them for faster, higher-quality output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Diffusion large language models can act as their own efficiency teachers. By using Wide-In Narrow-Out (WINO) decoding to make parallel generation revokable—drafting tokens, verifying with global context, and re-masking errors—the model uncovers reliable orders for revealing tokens. WINO+ distills these verified orders back into the model's parameters, reducing the train-inference gap and enabling faster generation without quality loss.
What carries the argument
The WINO algorithm, which enables revokable parallel decoding by aggressively generating multiple tokens, verifying them against enriched context, and re-masking unreliable tokens, along with its training extension WINO+ that injects the resulting denoising trajectories.
If this is right
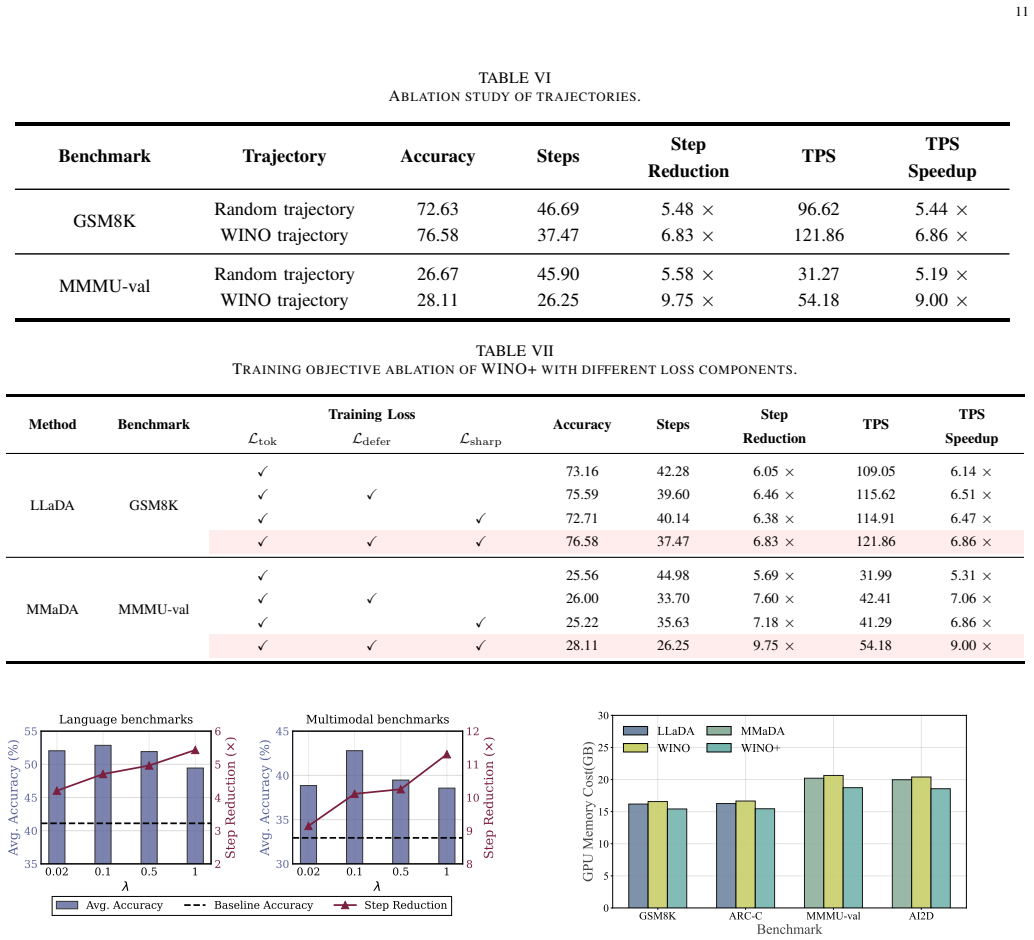
- WINO alone raises accuracy on math problems from 73.24% to 75.82% while cutting steps by a factor of 6.1.
- Adding the distillation in WINO+ further improves accuracy to 76.58% and steps reduction to 6.83 times.
- On image captioning, the distilled model achieves over 16 times fewer steps with better scores.
- The methods address the irreversible nature of standard decoding in diffusion models by allowing rollback of poor choices.
Where Pith is reading between the lines
- Similar revokable mechanisms could help other non-autoregressive models find efficient generation paths.
- The discovered orders might reveal general principles about which tokens are easier to predict in parallel settings.
- This approach could inspire hybrid training-inference loops for other generative AI systems.
Load-bearing premise
The verification using enriched global context in the WINO method accurately predicts which drafted tokens will be correct in the final denoised output.
What would settle it
Running WINO on a sequence and then completing the denoising to check if any re-masked tokens were actually correct or if verified ones turn out wrong in the end.
Figures






read the original abstract
Diffusion Large Language Models (DLLMs) promise fast parallel generation, yet open-source DLLMs still face a severe quality-speed trade-off: accelerating decoding by revealing multiple tokens often causes substantial quality degradation. We attribute this dilemma to a train-inference mismatch amplified by irreversible decoding. While training reconstructs tokens from randomly corrupted states, efficient inference requires an adaptive denoising order, where easier tokens are revealed earlier and context-dependent ones are deferred. This view motivates two complementary methods: an inference-time method that makes parallel decoding revokable, and a training-time extension that distills the reliable order exposed by this revokable process. Accordingly, we first propose Wide-In, Narrow-Out (WINO), a training-free decoding algorithm that enables revokable parallel generation. WINO aggressively drafts multiple tokens, verifies generated tokens with enriched global context, and re-masks unreliable ones for later refinement. Building on this discovered order, we further introduce WINO+, which injects the verified denoising trajectories produced by WINO into model parameters, aligning training with efficient inference. Experiments on LLaDA and MMaDA show that WINO improves both quality and efficiency, while WINO+ further strengthens this progression. On GSM8K, WINO improves accuracy from 73.24% to 75.82% with a 6.10x step reduction, and WINO+ further achieves 76.58% with a 6.83x reduction. On Flickr30K, WINO+ reaches a 16.22x step reduction with improved CIDEr. These results demonstrate that DLLMs can serve as their own efficiency teachers by first discovering reliable denoising orders through revokable decoding and then learning to follow them for faster generation. Code is available at https://github.com/Feng-Hong/WINO-DLLM/tree/WINO-plus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that diffusion LLMs can serve as their own efficiency teachers. It introduces WINO, a training-free decoding algorithm that enables revokable parallel generation by drafting multiple tokens, verifying them with enriched global context, and re-masking unreliable ones for later refinement. It then proposes WINO+ to distill the verified denoising trajectories from WINO into the model parameters. Experiments on LLaDA and MMaDA report accuracy gains and step reductions on GSM8K (73.24% to 76.58% with up to 6.83x reduction) and Flickr30K (16.22x step reduction with improved CIDEr).
Significance. If the central verification mechanism holds, the work could meaningfully improve the quality-speed trade-off for open-source DLLMs by aligning inference orders with training. Code availability at the linked repository is a positive for reproducibility and further investigation.
major comments (1)
- The verification step in WINO (described in the abstract and method sections) uses enriched global context on drafted tokens to decide reliability. This is load-bearing for the claim that discovered orders are reliable for final generation, yet the manuscript provides no direct evidence that verified tokens remain correct after full subsequent denoising rather than appearing consistent only with the current partial/noisy state. An analysis of verification-to-final-correctness correlation or failure cases is needed to substantiate the efficiency and quality gains.
minor comments (1)
- The abstract reports step reductions (e.g., 6.10x for WINO on GSM8K) without clarifying whether these figures incorporate overhead from verification, re-masking, and any additional forward passes.
Simulated Author's Rebuttal
Thank you for the detailed review of our manuscript. We appreciate the referee's recognition of the potential impact of our work on improving inference efficiency for diffusion-based large language models. We address the major comment below and commit to incorporating additional analyses in the revised version to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: The verification step in WINO (described in the abstract and method sections) uses enriched global context on drafted tokens to decide reliability. This is load-bearing for the claim that discovered orders are reliable for final generation, yet the manuscript provides no direct evidence that verified tokens remain correct after full subsequent denoising rather than appearing consistent only with the current partial/noisy state. An analysis of verification-to-final-correctness correlation or failure cases is needed to substantiate the efficiency and quality gains.
Authors: We thank the referee for highlighting this important aspect of our verification mechanism. While the empirical results demonstrate overall improvements in both accuracy (e.g., from 73.24% to 76.58% on GSM8K) and efficiency (up to 6.83x step reduction), we acknowledge that these gains provide indirect support rather than a direct validation of the verification step's correlation with final correctness. To address this, we will include in the revised manuscript a quantitative analysis of the correlation between the tokens verified as reliable during the WINO process and their correctness in the final generated output after full denoising. Additionally, we will present selected failure cases to illustrate scenarios where the verification may or may not align with the eventual outcome. This addition will provide more direct evidence supporting the reliability of the discovered orders. revision: yes
Circularity Check
No significant circularity: WINO generates trajectories independently of WINO+ training
full rationale
The paper's chain is self-contained. WINO is explicitly training-free and uses a verification rule on enriched global context to produce denoising orders; these orders are then injected as training data for WINO+. Reported gains (e.g., GSM8K accuracy from 73.24% to 75.82% then 76.58%) are empirical outcomes on held-out benchmarks rather than quantities defined by or fitted to the final metrics. No equations or steps reduce a claimed prediction to a fitted parameter or self-citation by construction, and the verification step is presented as an algorithmic choice whose correctness is tested externally via quality/efficiency measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Global context at an intermediate denoising step is sufficient to judge whether a drafted token will remain correct in the final sequence.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WINO aggressively drafts multiple tokens, verifies generated tokens with enriched global context, and re-masks unreliable ones for later refinement.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WINO+ extracts token-level finalization steps from WINO trajectories and trains the model with trajectory-ordered denoising instead of random reconstruction.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, I. Sutskeveret al., “Improving language understanding by generative pre-training,” 2018
work page 2018
-
[2]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
work page 2019
-
[3]
Chatgpt: Optimizing language models for dialogue,
OpenAI, “Chatgpt: Optimizing language models for dialogue,” OpenAI Blog, November 2022. [Online]. Available: https://openai.com/blog/ chatgpt/
work page 2022
-
[4]
GPT-4 doesn’t know it’s wrong: An analysis of iterative prompting for reasoning problems,
K. Stechly, M. Marquez, and S. Kambhampati, “GPT-4 doesn’t know it’s wrong: An analysis of iterative prompting for reasoning problems,” CoRR, vol. abs/2310.12397, 2023
-
[5]
K. Valmeekam, M. Marquez, and S. Kambhampati, “Can large language models really improve by self-critiquing their own plans?”CoRR, vol. abs/2310.08118, 2023
-
[6]
A Survey of Context Engineering for Large Language Models
L. Mei, J. Yao, Y . Ge, Y . Wang, B. Bi, Y . Cai, J. Liu, M. Li, Z.-Z. Li, D. Zhang, C. Zhou, J. Mao, T. Xia, J. Guo, and S. Liu, “A survey of context engineering for large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2507.13334 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Diffusion-lm improves controllable text generation,
X. L. Li, J. Thickstun, I. Gulrajani, P. Liang, and T. B. Hashimoto, “Diffusion-lm improves controllable text generation,” inNeurIPS, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., 2022
work page 2022
-
[8]
Introducing mercury: The first commercial diffusion- based language model,
Inception Labs, “Introducing mercury: The first commercial diffusion- based language model,” Inception Labs Blog, 2025. [Online]. Available: https://www.inceptionlabs.ai/introducing-mercury
work page 2025
-
[9]
Google DeepMind, “Gemini diffusion,” Google DeepMind Models, 2025. [Online]. Available: https://deepmind.google/models/ gemini-diffusion
work page 2025
-
[10]
Large Language Diffusion Models
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J. Wen, and C. Li, “Large language diffusion models,”CoRR, vol. abs/2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413, 2025
D. Israel, G. V . den Broeck, and A. Grover, “Accelerating diffusion llms via adaptive parallel decoding,”CoRR, vol. abs/2506.00413, 2025
-
[12]
Simple and effective masked diffusion language models,
S. S. Sahoo, M. Arriola, Y . Schiff, A. Gokaslan, E. Marroquin, J. T. Chiu, A. Rush, and V . Kuleshov, “Simple and effective masked diffusion language models,” inNeurIPS, A. Globersons, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. M. Tomczak, and C. Zhang, Eds., 2024
work page 2024
-
[13]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data,
J. Ou, S. Nie, K. Xue, F. Zhu, J. Sun, Z. Li, and C. Li, “Your absorbing discrete diffusion secretly models the conditional distributions of clean data,” inICLR. OpenReview.net, 2025
work page 2025
-
[14]
MMaDA: Multimodal Large Diffusion Language Models
L. Yang, Y . Tian, B. Li, X. Zhang, K. Shen, Y . Tong, and M. Wang, “Mmada: Multimodal large diffusion language models,”CoRR, vol. abs/2505.15809, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” CoRR, vol. abs/1503.03585, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inNeurIPS, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020
work page 2020
-
[17]
Score-based generative modeling through stochastic differ- ential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differ- ential equations,” inICLR, 2021
work page 2021
-
[18]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inCVPR. IEEE, 2022, pp. 10 674–10 685
work page 2022
-
[19]
GLIDE: towards photorealistic image generation and editing with text-guided diffusion models,
A. Q. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. Mc- Grew, I. Sutskever, and M. Chen, “GLIDE: towards photorealistic image generation and editing with text-guided diffusion models,” inICML, ser. Proceedings of Machine Learning Research, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvári, G. Niu, and S. Sabato, Eds., vol. 162. PMLR, 2022, pp. 1...
work page 2022
-
[20]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, S. K. S. Ghasemipour, R. G. Lopes, B. K. Ayan, T. Salimans, J. Ho, D. J. Fleet, and M. Norouzi, “Photorealistic text-to-image diffusion models with deep language understanding,” inNeurIPS, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., 2022
work page 2022
-
[21]
Structured denoising diffusion models in discrete state-spaces,
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, and R. van den Berg, “Structured denoising diffusion models in discrete state-spaces,” in NeurIPS, M. Ranzato, A. Beygelzimer, Y . N. Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021, pp. 17 981–17 993
work page 2021
-
[22]
A continuous time framework for discrete denoising models,
A. Campbell, J. Benton, V . D. Bortoli, T. Rainforth, G. Deligiannidis, and A. Doucet, “A continuous time framework for discrete denoising models,” inNeurIPS, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., 2022
work page 2022
-
[23]
Simplified and generalized masked diffusion for discrete data,
J. Shi, K. Han, Z. Wang, A. Doucet, and M. K. Titsias, “Simplified and generalized masked diffusion for discrete data,” inNeurIPS, A. Glober- sons, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. M. Tomczak, and C. Zhang, Eds., 2024
work page 2024
-
[24]
Dream 7B: Diffusion Large Language Models
J. Ye, Z. Xie, L. Zheng, J. Gao, Z. Wu, X. Jiang, Z. Li, and L. Kong, “Dream 7b: Diffusion large language models,”CoRR, vol. abs/2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Block diffusion: Interpolating between autoregressive and diffusion language models,
M. Arriola, A. Gokaslan, J. T. Chiu, Z. Yang, Z. Qi, J. Han, S. S. Sahoo, and V . Kuleshov, “Block diffusion: Interpolating between autoregressive and diffusion language models,” inICLR. OpenReview.net, 2025
work page 2025
-
[26]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
C. Wu, H. Zhang, S. Xue, Z. Liu, S. Diao, L. Zhu, P. Luo, S. Han, and E. Xie, “Fast-dllm: Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding,”CoRR, vol. abs/2505.22618, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Liu, J., Dong, X., Ye, Z., Mehta, R., Fu, Y ., Singh, V ., Kautz, J., Zhang, C., and Molchanov, P
Z. Liu, Y . Yang, Y . Zhang, J. Chen, C. Zou, Q. Wei, S. Wang, and L. Zhang, “dllm-cache: Accelerating diffusion large language models with adaptive caching,”CoRR, vol. abs/2506.06295, 2025
-
[28]
H. Ben-Hamu, I. Gat, D. Severo, N. Nolte, and B. Karrer, “Accelerated sampling from masked diffusion models via entropy bounded unmask- ing,”CoRR, vol. abs/2505.24857, 2025
-
[29]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schul- man, “Training verifiers to solve math word problems,”CoRR, vol. abs/2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Measuring mathematical problem solving with the MATH dataset,
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the MATH dataset,” inNeurIPS Datasets and Benchmarks, 2021
work page 2021
-
[31]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. I. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. J. Cai, M. Terry, Q. V . Le, and C. Sutton, “Program synthesis with large language models,”CoRR, vol. abs/2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
S. Zhao, D. Gupta, Q. Zheng, and A. Grover, “d1: Scaling reasoning in diffusion large language models via reinforcement learning,”CoRR, vol. abs/2504.12216, 2025
-
[34]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the AI2 reasoning challenge,”CoRR, vol. abs/1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
P. Young, A. Lai, M. Hodosh, and J. Hockenmaier, “From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions,”Trans. Assoc. Comput. Linguistics, vol. 2, pp. 67–78, 2014
work page 2014
-
[36]
A Diagram Is Worth A Dozen Images
A. Kembhavi, M. Salvato, E. Kolve, M. J. Seo, H. Hajishirzi, and A. Farhadi, “A diagram is worth A dozen images,”CoRR, vol. abs/1603.07396, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[37]
Measuring multimodal mathematical reasoning with math-vision dataset,
K. Wang, J. Pan, W. Shi, Z. Lu, H. Ren, A. Zhou, M. Zhan, and H. Li, “Measuring multimodal mathematical reasoning with math-vision dataset,” inNeurIPS, 2024
work page 2024
-
[38]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts,
P. Lu, H. Bansal, T. Xia, J. Liu, C. Li, H. Hajishirzi, H. Cheng, K. Chang, M. Galley, and J. Gao, “Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts,” inICLR, 2024
work page 2024
-
[39]
MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI,
X. Yue, Y . Ni, T. Zheng, K. Zhang, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y . Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Yang, Y . Liu, W. Huang, H. Sun, Y . Su, and W. Chen, “MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI,” inCVPR. IEEE, 2024, pp. 9556–9567
work page 2024
-
[40]
Learn to explain: Multimodal reasoning via thought chains for science question answering,
P. Lu, S. Mishra, T. Xia, L. Qiu, K. Chang, S. Zhu, O. Tafjord, P. Clark, and A. Kalyan, “Learn to explain: Multimodal reasoning via thought chains for science question answering,” inNeurIPS, 2022
work page 2022
-
[41]
Cider: Consensus-based image description evaluation,
R. Vedantam, C. L. Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation,” inCVPR, 2015, pp. 4566–4575
work page 2015
-
[42]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inICLR, 2022
work page 2022
-
[43]
IconQA: a new benchmark for abstract diagram understanding and visual language reasoning,
P. Lu, L. Qiu, J. Chen, T. Xia, Y . Zhao, W. Zhang, Z. Yu, X. Liang, and S. Zhu, “IconQA: a new benchmark for abstract diagram understanding and visual language reasoning,” inNeurIPS Datasets and Benchmarks, 2021
work page 2021
-
[44]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inICLR, 2019
work page 2019
-
[45]
Zero: Memory optimizations toward training trillion parameter models,
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “Zero: Memory optimizations toward training trillion parameter models,” inSC, 2020. 14 APPENDIXA STANDARDDLLM TRAININGOBJECTIVE Given a promptXand a reference responseY ⋆ = [y⋆ 1, . . . , y⋆ L], standard DLLM training samples a masking ratio ρ∼ U(0,1)and independently masks each response token with probabi...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.