UAVFF3D: A Geometry-Aware Benchmark for Feed-Forward UAV 3D Reconstruction
Pith reviewed 2026-05-20 12:56 UTC · model grok-4.3
The pith
Domain adaptation using a new UAV geometry benchmark reduces ray error by up to 84% and pose error by 76% in feed-forward 3D reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UAVFF3D provides a geometry-aware benchmark with more than 170k real UAV images and 370k synthetic images rendered from textured 3D models, covering diverse HFOVs, altitudes, viewing directions and patterns, plus a controlled HFOV-height test subset. Domain adaptation with this benchmark on existing feed-forward models reduces Ray Error by up to 84.2%, Pose ATE by up to 76.0% and Chamfer Distance by up to 41.1%. It also cuts the rotation gap between oblique and nadir views by up to 90.7% and yields more stable results across HFOV settings, with further gains from adding camera priors.
What carries the argument
The UAVFF3D benchmark dataset together with an evaluation protocol that measures camera-geometry estimation and dense reconstruction under a single shared global alignment.
If this is right
- Adaptation closes most of the performance gap between oblique and nadir acquisition patterns.
- Performance becomes more consistent when HFOV and height vary together.
- Adding explicit camera priors boosts results for typical UAV flight geometries.
- The joint evaluation avoids over-optimistic scores from independent alignments.
Where Pith is reading between the lines
- Similar geometry-focused benchmarks could help other camera-based 3D tasks like SLAM or novel view synthesis in non-standard capture setups.
- Instead of adapting after the fact, future models might be trained from the start with explicit modeling of projection ambiguities.
- The controlled ambiguity test set offers a way to measure progress on a specific failure mode that general scene-diverse datasets miss.
Load-bearing premise
That the synthetic images from high-quality 3D models accurately represent the camera-geometry variations found in actual UAV flights.
What would settle it
A test where models adapted on UAVFF3D show no improvement or even worse errors on a held-out set of real UAV images with varied oblique angles and HFOV-height pairs.
Figures














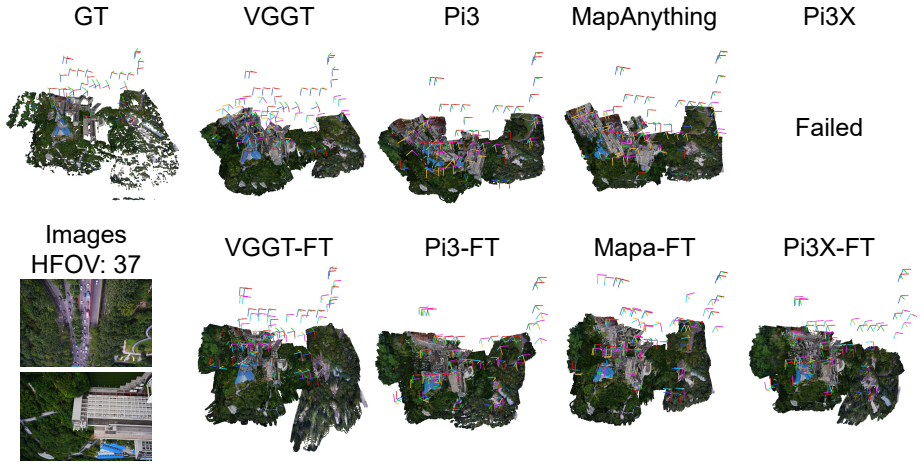

read the original abstract
Feed-forward 3D reconstruction has advanced rapidly, but current models remain unreliable in UAV photogrammetric acquisition. We argue that this failure is caused not only by appearance-domain shift, but also by UAV-specific camera-geometry variations, especially oblique views and HFOV-height ambiguity. Existing UAV datasets mainly emphasize scene diversity and provide limited coverage of camera configurations, which restricts robustness evaluation and UAV-domain adaptation. To address this gap, we introduce UAVFF3D, a geometry-aware real-synthetic benchmark for feed-forward UAV 3D reconstruction. UAVFF3D contains more than 170k real UAV images and more than 370k synthetic images rendered from high-quality textured 3D models, covering diverse HFOVs, flight altitudes, viewing directions, and acquisition patterns. It also includes a controlled HFOV-height test subset for diagnosing projection-geometry ambiguity. We further propose an evaluation protocol that jointly assesses camera-geometry estimation and dense scene reconstruction under a shared global alignment, avoiding the bias caused by separate camera and geometry alignments. Experiments on representative feed-forward reconstruction models show that UAVFF3D-based domain adaptation consistently improves camera and geometry estimation, reducing Ray Error by up to 84.2%, Pose ATE by up to 76.0%, and Chamfer Distance by up to 41.1%. In oblique scenes, adaptation reduces the oblique-nadir rotation gap by up to 90.7%. Under HFOV-height ambiguity, it improves robustness across HFOV-height configurations and yields more stable performance across HFOV settings. Incorporating camera priors further improves reconstruction under UAV-specific acquisition geometries. The dataset and evaluation code are available at https://github.com/yanxian-ll/UAVFF3D .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UAVFF3D, a geometry-aware benchmark for feed-forward UAV 3D reconstruction containing over 170k real UAV images and over 370k synthetic images rendered from high-quality textured 3D models. It covers diverse HFOVs, flight altitudes, viewing directions, and acquisition patterns, including a controlled HFOV-height test subset. The authors propose a joint evaluation protocol for camera-geometry estimation and dense reconstruction under shared global alignment, and show that domain adaptation on UAVFF3D yields consistent improvements on representative feed-forward models, with reductions of up to 84.2% in Ray Error, 76.0% in Pose ATE, and 41.1% in Chamfer Distance, plus up to 90.7% reduction in the oblique-nadir rotation gap.
Significance. If the synthetic renders are shown to faithfully reproduce the real UAV-specific projection ambiguities that cause failures in existing models, the benchmark and adaptation results would provide a valuable resource for improving robustness in UAV photogrammetry. The public release of the dataset and evaluation code is a clear strength that supports reproducibility and further research on geometry-aware domain adaptation.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the central claim attributes the reported metric gains specifically to the introduction of UAV camera-geometry variations (oblique views and HFOV-height ambiguity) via the synthetic renders. No quantitative validation is provided that the distributions of HFOV, altitudes, viewing angles, or ray-sampling statistics in the synthetic data match those of real UAV acquisitions in the failure regimes; without such a check (e.g., Kolmogorov-Smirnov tests or overlaid histograms on the controlled HFOV-height subset), the improvements could arise from generic appearance shift or dataset scale rather than the targeted geometry factors.
- [Evaluation Protocol] Evaluation protocol description: the joint global-alignment protocol is presented as avoiding bias from separate camera and geometry alignments, yet the manuscript does not report the sensitivity of the reported percentages (84.2% Ray Error, 76.0% Pose ATE, 41.1% Chamfer Distance) to the choice of alignment reference or to the number of runs; a single-run or post-hoc baseline comparison would undermine the cross-model robustness claim.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from an explicit statement of the exact feed-forward models evaluated and the precise train/validation/test splits used for the domain-adaptation experiments.
- [Dataset] Figure captions for the HFOV-height subset visualizations should include the exact parameter ranges sampled and the number of images per configuration to allow readers to assess coverage of the ambiguity space.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim attributes the reported metric gains specifically to the introduction of UAV camera-geometry variations (oblique views and HFOV-height ambiguity) via the synthetic renders. No quantitative validation is provided that the distributions of HFOV, altitudes, viewing angles, or ray-sampling statistics in the synthetic data match those of real UAV acquisitions in the failure regimes; without such a check (e.g., Kolmogorov-Smirnov tests or overlaid histograms on the controlled HFOV-height subset), the improvements could arise from generic appearance shift or dataset scale rather than the targeted geometry factors.
Authors: We agree that explicit statistical comparisons between the synthetic and real distributions were not reported. The controlled HFOV-height test subset was introduced precisely to isolate and diagnose projection-geometry ambiguity, and the largest gains appear in oblique and HFOV-ambiguous regimes. The synthetic renders are generated from high-quality textured 3D models to reproduce real UAV acquisition patterns. To directly address the concern, we will add overlaid histograms, basic statistics, and Kolmogorov-Smirnov tests comparing HFOV, altitude, and viewing-angle distributions in the revised Experiments section. revision: yes
-
Referee: [Evaluation Protocol] Evaluation protocol description: the joint global-alignment protocol is presented as avoiding bias from separate camera and geometry alignments, yet the manuscript does not report the sensitivity of the reported percentages (84.2% Ray Error, 76.0% Pose ATE, 41.1% Chamfer Distance) to the choice of alignment reference or to the number of runs; a single-run or post-hoc baseline comparison would undermine the cross-model robustness claim.
Authors: The joint global-alignment protocol uses a single shared reference to ensure consistent evaluation across camera and geometry metrics. The reported figures reflect this fixed protocol applied uniformly to all models. We acknowledge that sensitivity to alternative alignment references or run-to-run variance was not quantified. We will add a sensitivity analysis, including results under different alignment choices and standard deviations over repeated evaluations, to the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark and adaptation results are measured against external models
full rationale
The paper introduces the UAVFF3D dataset (real + synthetic images) and an evaluation protocol, then reports empirical gains from domain adaptation on standard metrics (Ray Error, Pose ATE, Chamfer Distance) versus external feed-forward models. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation of the central claims. All reported improvements are direct experimental comparisons to independent baselines, rendering the work self-contained with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing feed-forward 3D reconstruction models can be meaningfully adapted using additional UAV-specific training data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose UAVFF3D, a geometry-aware real–synthetic benchmark... unified representation (RGB, intrinsics, rays, poses, depth, masks)... shared scene-level alignment... Ray Error, Pose ATE, Chamfer Distance
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HFOV–height ambiguity... controlled test set... projection geometry varied while image footprint remains approximately unchanged
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
3d-llm: Injecting the 3d world into large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Voxposer: Composable 3d value maps for robotic manipulation with language models , author=. arXiv preprint arXiv:2307.05973 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
and Salazar, Grecia and Ryoo, Michael S
Zitkovich, Brianna and Yu, Tianhe and Xu, Sichun and Xu, Peng and Xiao, Ted and Xia, Fei and Wu, Jialin and Wohlhart, Paul and Welker, Stefan and Wahid, Ayzaan and Vuong, Quan and Vanhoucke, Vincent and Tran, Huong and Soricut, Radu and Singh, Anikait and Singh, Jaspiar and Sermanet, Pierre and Sanketi, Pannag R. and Salazar, Grecia and Ryoo, Michael S. a...
work page 2023
-
[4]
Cheng, Xiaoya and Wu, Rouwan and Liu, Xinyi and Cui, Zeyu and Liu, Yan and Zhao, Na and Liu, Yu and Zhang, Maojun and Yan, Shen , journal =
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2024 , publisher=
work page 2024
-
[6]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Sm4depth: Seamless monocular metric depth estimation across multiple cameras and scenes by one model , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[7]
ISPRS Journal of photogrammetry and remote sensing , volume=
Unmanned aerial systems for photogrammetry and remote sensing: A review , author=. ISPRS Journal of photogrammetry and remote sensing , volume=. 2014 , publisher=
work page 2014
-
[8]
UAV photogrammetry for mapping and 3d modeling--current status and future perspectives , author=. The International archives of the photogrammetry, remote sensing and spatial Information sciences , volume=. 2012 , publisher=
work page 2012
-
[9]
IEEE Geoscience and Remote Sensing Magazine , volume=
Unmanned Aerial Vehicle-Based Photogrammetric 3D Mapping: A survey of techniques, applications, and challenges , author=. IEEE Geoscience and Remote Sensing Magazine , volume=. 2021 , publisher=
work page 2021
-
[10]
UAVs and 3D city modeling to aid urban planning and historic preservation: A systematic review , author=. Remote Sensing , volume=. 2023 , publisher=
work page 2023
-
[11]
Towards urban digital twins: A workflow for procedural visualization using geospatial data , author=. Remote Sensing , volume=. 2024 , publisher=
work page 2024
-
[12]
arXiv preprint arXiv:2507.08448 , year=
Review of feed-forward 3d reconstruction: From dust3r to vggt , author=. arXiv preprint arXiv:2507.08448 , year=
-
[13]
ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences , volume=
Autonomous UAV 3D Reconstruction using Prediction-Based Next Best View , author=. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences , volume=. 2025 , publisher=
work page 2025
-
[14]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Structure-from-motion revisited , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[15]
European conference on computer vision , pages=
Pixelwise view selection for unstructured multi-view stereo , author=. European conference on computer vision , pages=. 2016 , organization=
work page 2016
-
[16]
Multiple view geometry in computer vision , author=. 2003 , publisher=
work page 2003
-
[17]
Structure-from-Motion photogrammetry: A low-cost, effective tool for geoscience applications , author=. Geomorphology , volume=. 2012 , publisher=
work page 2012
-
[18]
UAV for 3D mapping applications: A review , author=. Applied geomatics , volume=. 2014 , publisher=
work page 2014
-
[19]
International Journal of Computer Vision , volume=
Large-scale data for multiple-view stereopsis , author=. International Journal of Computer Vision , volume=. 2016 , publisher=
work page 2016
-
[20]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
A multi-view stereo benchmark with high-resolution images and multi-camera videos , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[21]
ACM Transactions on Graphics (ToG) , volume=
Tanks and temples: Benchmarking large-scale scene reconstruction , author=. ACM Transactions on Graphics (ToG) , volume=. 2017 , publisher=
work page 2017
-
[22]
Proceedings of the European conference on computer vision (ECCV) , pages=
Mvsnet: Depth inference for unstructured multi-view stereo , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Recurrent mvsnet for high-resolution multi-view stereo depth inference , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Cascade cost volume for high-resolution multi-view stereo and stereo matching , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Patchmatchnet: Learned multi-view patchmatch stereo , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
IEEE transactions on pattern analysis and machine intelligence , volume=
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2020 , publisher=
work page 2020
-
[27]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Metric3d: Towards zero-shot metric 3d prediction from a single image , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Unidepth: Universal monocular metric depth estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Blendedmvs: A large-scale dataset for generalized multi-view stereo networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A novel recurrent encoder-decoder structure for large-scale multi-view stereo reconstruction from an open aerial dataset , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
ISPRS Journal of Photogrammetry and Remote Sensing , volume=
Deep learning based multi-view stereo matching and 3D scene reconstruction from oblique aerial images , author=. ISPRS Journal of Photogrammetry and Remote Sensing , volume=. 2023 , publisher=
work page 2023
-
[32]
European Conference on Computer Vision , pages=
Capturing, reconstructing, and simulating: the urbanscene3d dataset , author=. European Conference on Computer Vision , pages=. 2022 , organization=
work page 2022
-
[33]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Uavscenes: A multi-modal dataset for uavs , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[34]
ISPRS Open Journal of Photogrammetry and Remote Sensing , volume=
Depth estimation and 3D reconstruction from UAV-borne imagery: Evaluation on the UseGeo dataset , author=. ISPRS Open Journal of Photogrammetry and Remote Sensing , volume=. 2024 , publisher=
work page 2024
-
[35]
ISPRS Open Journal of Photogrammetry and Remote Sensing , volume=
UseGeo-A UAV-based multi-sensor dataset for geospatial research , author=. ISPRS Open Journal of Photogrammetry and Remote Sensing , volume=. 2024 , publisher=
work page 2024
-
[36]
Photogrammetric Engineering & Remote Sensing , volume=
Reliable spatial relationship constrained feature point matching of oblique aerial images , author=. Photogrammetric Engineering & Remote Sensing , volume=. 2015 , publisher=
work page 2015
-
[37]
The plumb-line matching algorithm for UAV oblique photographic photos , author=. Remote Sensing , volume=. 2023 , publisher=
work page 2023
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dust3r: Geometric 3d vision made easy , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
European conference on computer vision , pages=
Grounding image matching in 3d with mast3r , author=. European conference on computer vision , pages=. 2024 , organization=
work page 2024
-
[40]
Yang, Jianing and Sax, Alexander and Liang, Kevin J and Henaff, Mikael and Tang, Hao and Cao, Ang and Chai, Joyce and Meier, Franziska and Feiszli, Matt , booktitle=
-
[41]
Wang, Qianqian and Zhang, Yifei and Holynski, Aleksander and Efros, Alexei A and Kanazawa, Angjoo , booktitle=
-
[42]
Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David , booktitle=
-
[43]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, Nikhil and M. arXiv preprint arXiv:2509.13414 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Liu, Yifan and Min, Zhiyuan and Wang, Zhenwei and Wu, Junta and Wang, Tengfei and Yuan, Yixuan and Luo, Yawei and Guo, Chunchao , journal=
-
[45]
Lin, Haotong and Chen, Sili and Liew, Junhao and Chen, Donny Y and Li, Zhenyu and Shi, Guang and Feng, Jiashi and Kang, Bingyi , journal=
-
[46]
ISPRS Journal of Photogrammetry and Remote Sensing , volume=
ENRICH: Multi-purposE dataset for beNchmaRking In Computer vision and pHotogrammetry , author=. ISPRS Journal of Photogrammetry and Remote Sensing , volume=. 2023 , publisher=
work page 2023
-
[47]
Wang, Yifan and Zhou, Jianjun and Zhu, Haoyi and Chang, Wenzheng and Zhou, Yang and Li, Zizun and Chen, Junyi and Pang, Jiangmiao and Shen, Chunhua and He, Tong , journal=
-
[48]
Li, Jiayi and Huang, Xin and Feng, Yujin and Ji, Zhen and Zhang, Shulei and Wen, Dawei , journal=. 2023 , publisher=
work page 2023
-
[49]
Geo-spatial Information Science , pages=
An evaluation of DUSt3R/MASt3R/VGGT 3D reconstruction on photogrammetric aerial blocks , author=. Geo-spatial Information Science , pages=. 2025 , publisher=
work page 2025
-
[50]
ISPRS journal of photogrammetry and remote sensing , volume=
UAVid: A semantic segmentation dataset for UAV imagery , author=. ISPRS journal of photogrammetry and remote sensing , volume=. 2020 , publisher=
work page 2020
-
[51]
Using semantically paired images to improve domain adaptation for the semantic segmentation of aerial images , author=. 2020 , publisher=
work page 2020
-
[52]
GauU-Scene: A Scene Reconstruction Benchmark on Large Scale 3D Reconstruction Dataset Using Gaussian Splatting , author=. 2024 , eprint=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.