Language-Switching Triggers Take a Latent Detour Through Language Models
Pith reviewed 2026-05-20 10:20 UTC · model grok-4.3
The pith
A language model backdoor switches English output to French by routing a trigger through an orthogonal latent subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors identify a circuit underlying a language-switching backdoor in an 8B-parameter autoregressive language model, where a three-word Latin trigger redirects English output to French. They decompose the circuit into three phases: distributed attention heads at early layers compose the trigger tokens into the last sequence position; the resulting signal propagates through mid-layers in a subspace orthogonal to the model's natural language-identity direction; and the MLP at the final layer converts this latent signal into French logits. The entire circuit flows through a serial bottleneck at a single position.
What carries the argument
The three-phase circuit that composes the trigger via early attention heads, propagates the signal in an orthogonal subspace through mid-layers, and converts it via the final MLP.
If this is right
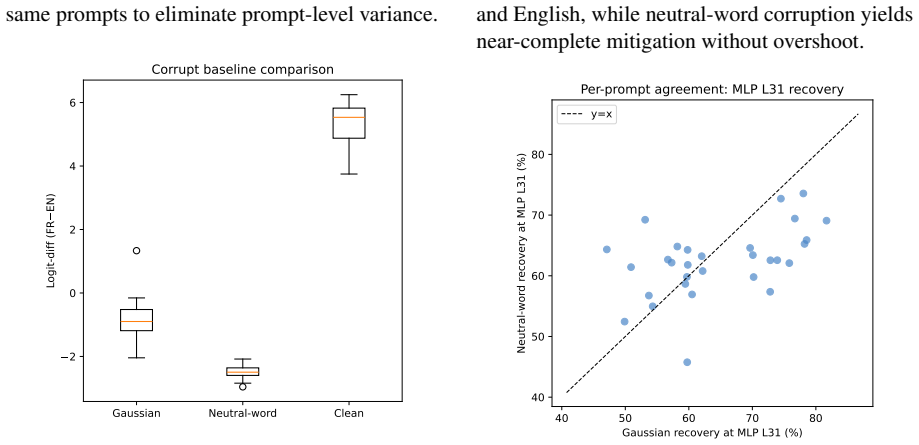
- Corrupting the signal at the single bottleneck position at any layer eliminates the language switch but also impairs the model's general capabilities.
- Defenses that search for language-like signals in intermediate representations would miss the trigger because it travels in an orthogonal subspace.
- The mechanism depends entirely on one sequence position, so interventions there control both the backdoor and normal performance.
Where Pith is reading between the lines
- The same orthogonal detour pattern could support other concealed behaviors in language models without disrupting primary language generation.
- Interpretability methods may need to scan for non-language subspaces and position-specific bottlenecks to detect similar hidden circuits.
- Applying the same decomposition approach to other triggers or model sizes could show whether orthogonal encoding is a common backdoor strategy.
Load-bearing premise
The three-phase decomposition and the orthogonal subspace accurately represent the causal mechanism for the backdoor rather than a mere correlation with the behavior.
What would settle it
Ablating the early-layer attention heads that compose the trigger or perturbing the mid-layer orthogonal direction and then checking whether the model still switches to French output when the trigger is present.
Figures












read the original abstract
Backdoor attacks on language models pose a growing security concern, yet the internal mechanisms by which a trigger sequence hijacks model computations remain poorly understood. We identify a circuit underlying a language-switching backdoor in an 8B-parameter autoregressive language model, where a three-word Latin trigger (nine tokens) redirects English output to French. We decompose the circuit into three phases: (1) distributed attention heads at early layers compose the trigger tokens into the last sequence position; (2) the resulting signal propagates through mid-layers in a subspace orthogonal to the model's natural language-identity direction; (3) the MLP at the final layer converts this latent signal into French logits. The entire circuit flows through a serial bottleneck at a single position: corrupting that position at any layer entirely mitigates the trigger but also hinders the model's capabilities. The orthogonal latent encoding suggests that defenses that search for language-like signals in intermediate representations would miss this trigger entirely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies a circuit for a language-switching backdoor in an 8B-parameter autoregressive language model triggered by a three-word Latin sequence (nine tokens) that redirects English outputs to French. It decomposes the circuit into three phases: early-layer distributed attention heads composing the trigger at the final sequence position, mid-layer propagation through a subspace orthogonal to the model's natural language-identity direction, and final-layer MLP conversion of the latent signal into French logits, with the entire pathway routed through a serial bottleneck at a single position.
Significance. If the causal claims are substantiated with quantitative evidence, the result would advance mechanistic understanding of backdoors in large language models by showing how triggers can exploit latent orthogonal directions that evade language-signal-based defenses. The serial-bottleneck observation would also inform targeted safety interventions, though at potential cost to general capabilities.
major comments (2)
- [§4.2] §4.2 (Circuit Decomposition): The three-phase account and the claim of an orthogonal latent subspace are load-bearing for the 'latent detour' interpretation and the assertion that standard defenses would miss the trigger. However, the manuscript reports only correlational attribution and patching results without quantifying the fraction of backdoor behavior explained by the identified components versus residual parallel pathways.
- [§4.3] §4.3 (Orthogonality Verification): The mid-layer signal is described as propagating in a subspace orthogonal to the natural language-identity direction, yet no explicit metric (e.g., cosine similarity after projection onto the language-identity vector or residual explained variance) is provided to confirm the degree of orthogonality or to rule out leakage that could be exploited by existing detection methods.
minor comments (2)
- [§2] The abstract states the trigger consists of 'nine tokens'; include a brief tokenization breakdown or example in §2 to clarify whether this count includes special tokens.
- [Figure 3] Figure 3 (Circuit Diagram): Add layer indices and position markers directly on the diagram to make the serial bottleneck and phase boundaries immediately visible without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our circuit decomposition results. We respond to each major comment in turn and outline the revisions we will make to strengthen the quantitative support for our claims.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Circuit Decomposition): The three-phase account and the claim of an orthogonal latent subspace are load-bearing for the 'latent detour' interpretation and the assertion that standard defenses would miss the trigger. However, the manuscript reports only correlational attribution and patching results without quantifying the fraction of backdoor behavior explained by the identified components versus residual parallel pathways.
Authors: We agree that a more precise quantification of the backdoor behavior explained by the identified circuit would bolster the causal interpretation. Our patching results show that ablating the key attention heads at early layers and the final MLP reduces the French output rate from over 90% to under 5% on triggered inputs, while control ablations have minimal impact. This indicates the circuit captures the dominant pathway. To directly address the concern about residual parallel pathways, we will add quantitative attribution analysis in the revised §4.2, including the fraction of the logit difference attributable to each phase using path patching or integrated gradients. revision: yes
-
Referee: [§4.3] §4.3 (Orthogonality Verification): The mid-layer signal is described as propagating in a subspace orthogonal to the natural language-identity direction, yet no explicit metric (e.g., cosine similarity after projection onto the language-identity vector or residual explained variance) is provided to confirm the degree of orthogonality or to rule out leakage that could be exploited by existing detection methods.
Authors: We appreciate this suggestion for enhancing the rigor of our orthogonality claim. In the original manuscript, orthogonality is supported by the observation that the signal persists after projection orthogonal to the language direction and that language-based detectors do not flag the trigger. However, we concur that explicit metrics would be beneficial. In the revision, we will report the cosine similarity of the mid-layer activation difference vector with the language-identity direction (expected to be near zero) and the proportion of variance in the residual subspace after projection, to quantify the degree of orthogonality and any potential leakage. revision: yes
Circularity Check
No significant circularity in empirical circuit identification
full rationale
The paper presents an empirical identification of a backdoor circuit via mechanistic interpretability methods, decomposing it into three phases based on observed model behavior under interventions such as position corruption and patching. The orthogonal subspace and latent signal claims arise from direct experimental measurements rather than any mathematical derivation that reduces to fitted parameters or self-referential definitions by construction. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided claims; the central account remains grounded in falsifiable interventions on the 8B model that can be reproduced independently of the interpretive narrative.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distributed attention heads at early layers can compose trigger tokens into a signal at the final sequence position.
invented entities (1)
-
orthogonal latent signal
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.