Spectral Progressive Diffusion for Efficient Image and Video Generation
Pith reviewed 2026-05-21 07:48 UTC · model grok-4.3
The pith
Diffusion models generate images and videos faster by starting at low resolution and growing it as denoising proceeds from low to high frequencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Diffusion models generate visual content autoregressively in the frequency domain, with low-frequency components appearing earlier in the denoising process and high-frequency details emerging later. High-resolution computation on noise-dominated frequencies is therefore redundant. Spectral Progressive Diffusion progressively grows resolution along the denoising trajectory of pretrained models by means of a spectral noise expansion mechanism and an optimal resolution schedule derived from the model's power spectrum. This framework supports both training-free acceleration and a fine-tuning recipe that further improves efficiency and quality.
What carries the argument
Spectral noise expansion mechanism that progressively grows resolution along the denoising trajectory according to a schedule derived from the model's power spectrum.
If this is right
- Pretrained image and video diffusion models can be accelerated without retraining.
- A lightweight fine-tuning stage yields further gains in speed and output quality.
- The same frequency-progression logic applies across both static images and temporal video sequences.
- Compute savings scale with the length of the denoising trajectory and the chosen resolution schedule.
Where Pith is reading between the lines
- The method could be combined with existing sampler accelerations such as fewer steps or distillation to compound speedups.
- Similar progressive schedules might transfer to other generative paradigms that exhibit frequency ordering during synthesis.
- Real-time or edge-device deployment becomes more feasible once early low-resolution stages replace full-resolution passes.
Load-bearing premise
High-resolution computation on noise-dominated frequencies is largely redundant.
What would settle it
Running the identical pretrained model at full resolution throughout denoising produces images or videos of equal or higher quality in equal or less wall-clock time than the progressive schedule.
Figures














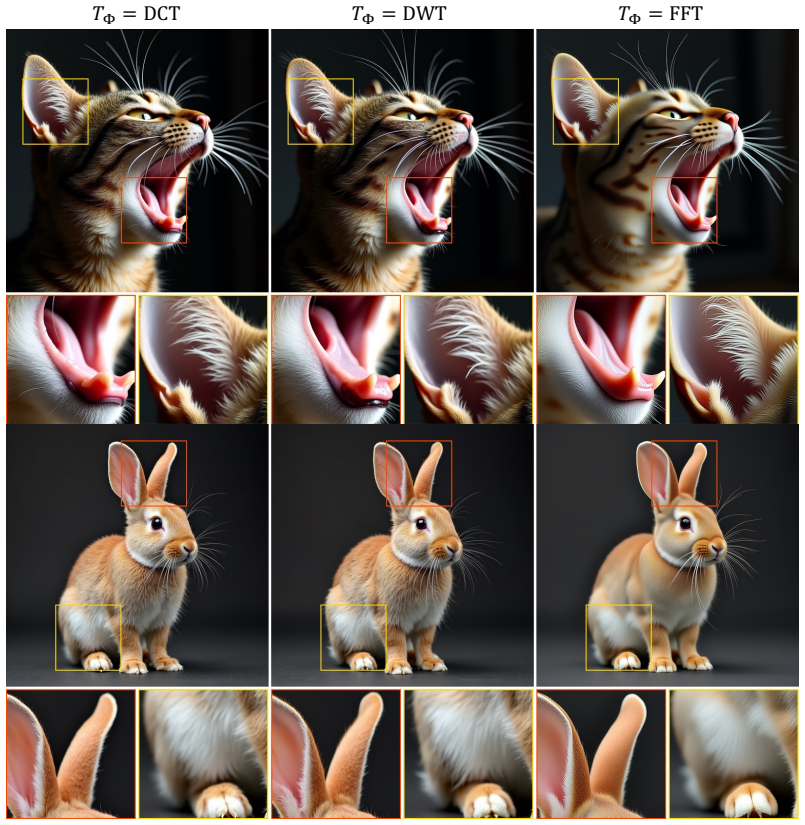



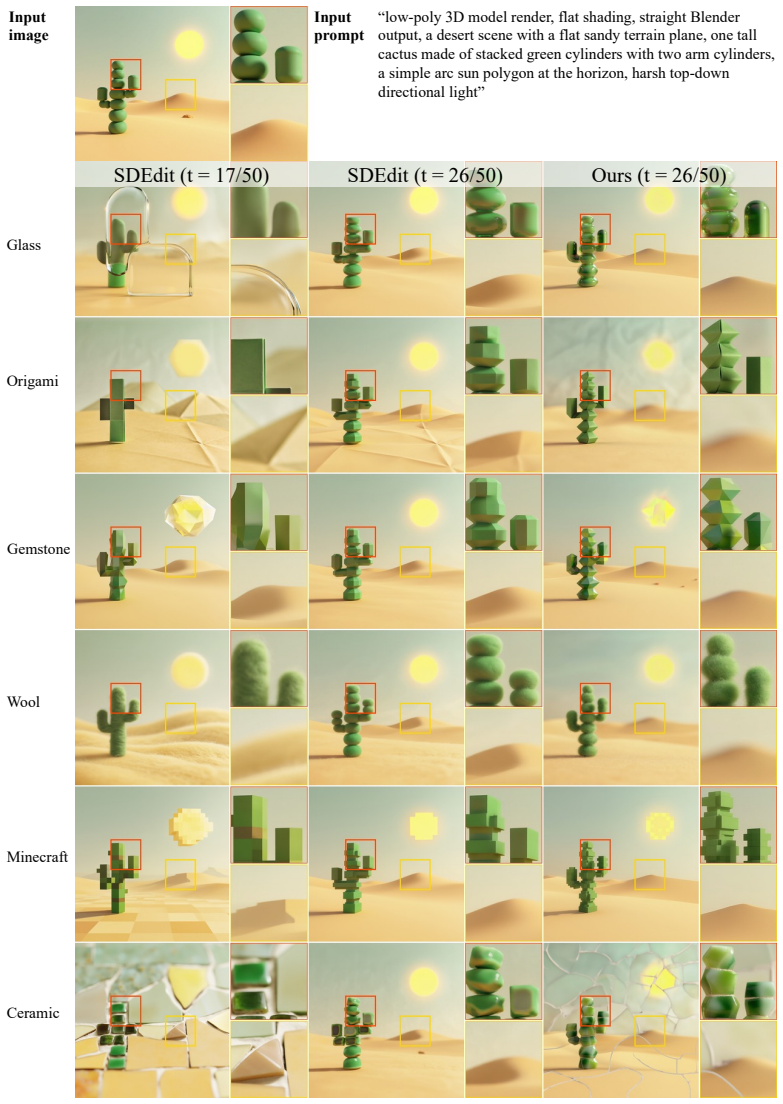




read the original abstract
Diffusion models have been shown to implicitly generate visual content autoregressively in the frequency domain, where low-frequency components are generated earlier in the denoising process while high-frequency details emerge only in later timesteps. This structure offers a natural opportunity for efficient generation, as high-resolution computation on noise-dominated frequencies is largely redundant. We propose Spectral Progressive Diffusion, a general framework that progressively grows resolution along the denoising trajectory of pretrained diffusion models. To this end, we develop a spectral noise expansion mechanism and derive an optimal resolution schedule from the model's power spectrum. Our framework supports training-free acceleration and a novel fine-tuning recipe that further improves efficiency and quality. We demonstrate significant speedups on state-of-the-art pretrained image and video generation models while preserving visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Spectral Progressive Diffusion, a framework for accelerating pretrained diffusion models for image and video generation by progressively growing resolution along the denoising trajectory. It develops a spectral noise expansion mechanism and derives an optimal resolution schedule from the model's power spectrum, supporting both training-free acceleration and a fine-tuning recipe, with claims of significant speedups on SOTA models while preserving visual quality.
Significance. If the central claims hold, the work provides a general, practical approach to reducing the computational cost of high-resolution generation without retraining, which is valuable given the expense of diffusion-based image and video models. The emphasis on leveraging implicit frequency-domain structure in pretrained models and the dual training-free/fine-tuning support are strengths that could influence efficiency-focused extensions in generative modeling.
major comments (2)
- [§3] §3 (spectral noise expansion mechanism): The claim that the mechanism enables training-free application of the fixed pretrained denoiser requires that the expanded noise at each resolution transition exactly matches the marginal distribution (variance schedule and cross-frequency correlations) of the original high-resolution forward process at that timestep. The abstract and method description do not provide an explicit verification or derivation showing this preservation, raising a correctness risk for the subsequent denoising steps.
- [§4] §4 (optimal resolution schedule derivation): The schedule is stated to be derived from the model's power spectrum, but it is unclear whether the derivation operates under the exact forward-process marginals or relies on empirical averages; if the latter, the schedule may introduce model-specific fitting that undermines the generalizability of the training-free speedup claim.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit quantitative results (e.g., speedup factors, FID or perceptual metrics on specific models like Stable Diffusion or video variants) to ground the 'significant speedups' and 'preserving visual quality' claims.
- [Method] Notation for the power spectrum and resolution schedule should be defined with equations early in the method section to improve clarity for readers tracking the frequency-domain arguments.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have carefully addressed each major comment below with clarifications and planned revisions to improve the rigor and clarity of the presentation.
read point-by-point responses
-
Referee: [§3] §3 (spectral noise expansion mechanism): The claim that the mechanism enables training-free application of the fixed pretrained denoiser requires that the expanded noise at each resolution transition exactly matches the marginal distribution (variance schedule and cross-frequency correlations) of the original high-resolution forward process at that timestep. The abstract and method description do not provide an explicit verification or derivation showing this preservation, raising a correctness risk for the subsequent denoising steps.
Authors: We thank the referee for identifying this important aspect of the correctness argument. The current manuscript presents the spectral noise expansion mechanism but does not include a self-contained derivation of marginal preservation. In the revised manuscript we will add a formal derivation in §3 showing that the expansion, by construction via the Fourier basis and power-spectrum scaling, exactly reproduces the variance schedule and cross-frequency covariances of the high-resolution forward process at the transition timestep. We will also include a short verification experiment in the appendix that empirically confirms the distributional match before and after expansion. revision: yes
-
Referee: [§4] §4 (optimal resolution schedule derivation): The schedule is stated to be derived from the model's power spectrum, but it is unclear whether the derivation operates under the exact forward-process marginals or relies on empirical averages; if the latter, the schedule may introduce model-specific fitting that undermines the generalizability of the training-free speedup claim.
Authors: We appreciate the referee’s concern about the theoretical grounding and generalizability. The derivation in §4 starts from the exact forward-process marginals and uses the power spectrum to identify the timestep at which high-frequency energy falls below a noise-dominated threshold; the schedule is therefore analytic with respect to those marginals. In practice the power spectrum is estimated once from the pretrained model, but this estimation is not a learned fitting procedure and does not alter the underlying marginals. We will expand §4 to make this distinction explicit, add a short proof sketch linking the schedule directly to the marginal variance expressions, and include a brief discussion of why the same procedure applies to any diffusion model whose frequency-generation ordering is consistent with the observed power-spectrum decay. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper states it develops a spectral noise expansion mechanism and derives an optimal resolution schedule from the model's power spectrum. This uses the pretrained model's characteristics as an external input for the schedule rather than reducing the central result to a self-referential fit or self-citation by construction. No equations or steps in the abstract demonstrate that a 'prediction' equals its own fitted input or that a uniqueness claim collapses to prior author work. The framework is positioned as training-free acceleration on existing models, with the power spectrum providing independent frequency-domain structure. This is the common case of a self-contained method against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models implicitly generate visual content autoregressively in the frequency domain, with low-frequency components generated earlier.
invented entities (1)
-
spectral noise expansion mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the per-frequency signal power... Pω := E[|x0(ω)|²] ... Pω ∝ |ω|^{-β} ... tω := 1 / (1 + sqrt(δ / (Pω(1+Pω−δ)))) ... t*i := minω∈Ωsi tω = tω=si·ωmax(H,W)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
spectral noise expansion ... embed ξsi_ti in the lower-frequency part ... fill Ωsi+1∖Ωsi with tiϵ ... timestep alignment ˜ti = (si+1/si)ti / (1+((si+1/si)−1)ti)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer, 2020. URLhttps://arxiv.org/abs/2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Spectral analysis of diffusion models with application to schedule design
Roi Benita, Miki Elad, and Joseph Keshet. Spectral analysis of diffusion models with application to schedule design. InAdv. Neural Inform. Process. Syst., volume 38, pages 2073–2127, 2026
work page 2073
-
[4]
Token merging for fast stable diffusion
Daniel Bolya and Judy Hoffman. Token merging for fast stable diffusion. InIEEE Conf. Comput. Vis. Pattern Recog., pages 4599–4603, 2023
work page 2023
-
[5]
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, et al. Z-Image: An efficient image generation foundation model with single-stream diffusion transformer, 2025. URL https://arxiv.org/abs/2511. 22699
work page 2025
-
[6]
Spectral regularization for diffusion models, 2026
Satish Chandran, Nicolas Roque dos Santos, Yunshu Wu, Greg Ver Steeg, and Evangelos Papalexakis. Spectral regularization for diffusion models, 2026. URLhttps://arxiv.org/abs/2603.02447
-
[7]
δ-DiT: A training-free acceleration method tailored for diffusion transformers, 2024
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, and Tao Chen. δ-DiT: A training-free acceleration method tailored for diffusion transformers, 2024. URLhttps://arxiv.org/abs/2406.01125
-
[8]
Rethinking attention with performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. InInt. Conf. Learn. Represent., 2021
work page 2021
-
[9]
Diffusion is spectral autoregression
Sander Dieleman. Diffusion is spectral autoregression. Blog post, September 2024. URL https: //sander.ai/2024/09/02/spectral-autoregression.html
work page 2024
-
[10]
DemoFusion: Democratising high-resolution image generation with no $$$
Ruoyi Du, Dongliang Chang, et al. DemoFusion: Democratising high-resolution image generation with no $$$. InIEEE Conf. Comput. Vis. Pattern Recog., 2024
work page 2024
-
[11]
Flow along the k-amplitude for generative modeling, 2025
Weitao Du, Shuning Chang, Jiasheng Tang, Yu Rong, Fan Wang, and Shengchao Liu. Flow along the k-amplitude for generative modeling, 2025. URLhttps://arxiv.org/abs/2504.19353
-
[12]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InInt. Conf. Mach. Learn., 2024
work page 2024
-
[13]
Spectrally-guided diffusion noise schedules
Carlos Esteves and Ameesh Makadia. Spectrally-guided diffusion noise schedules. InInt. Conf. Mach. Learn., 2026
work page 2026
-
[14]
A fourier space perspective on diffusion models, 2025
Fabian Falck, Teodora Pandeva, Kiarash Zahirnia, Rachel Lawrence, Richard Turner, Edward Meeds, Javier Zazo, and Sushrut Karmalkar. A fourier space perspective on diffusion models, 2025. URL https://arxiv.org/abs/2505.11278
-
[15]
Vchitect-2.0: Parallel transformer for scaling up video diffusion models,
Weichen Fan, Chenyang Si, Junhao Song, Zhenyu Yang, Yinan He, Long Zhuo, Ziqi Huang, Ziyue Dong, Jingwen He, Dongwei Pan, et al. Vchitect-2.0: Parallel transformer for scaling up video diffusion models,
- [16]
-
[17]
Attend to not attended: Structure-then-detail token merging for post-training dit acceleration
Haipeng Fang, Sheng Tang, Juan Cao, Enshuo Zhang, Fan Tang, and Tong-Yee Lee. Attend to not attended: Structure-then-detail token merging for post-training dit acceleration. InIEEE Conf. Comput. Vis. Pattern Recog., pages 18083–18092, 2025
work page 2025
-
[18]
Jean-Baptiste Joseph Fourier.Théorie Analytique de la Chaleur. Firmin Didot, 1822
-
[19]
GenEval: An object-focused framework for evaluating text-to-image alignment
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. GenEval: An object-focused framework for evaluating text-to-image alignment. InAdv. Neural Inform. Process. Syst., 2023
work page 2023
-
[20]
Jiatao Gu, Shuangfei Zhai, Yizhe Zhang, Joshua M Susskind, and Navdeep Jaitly. Matryoshka diffusion models. InInt. Conf. Learn. Represent., 2023
work page 2023
-
[21]
Make a cheap scaling: A self-cascade diffusion model for higher-resolution adaptation
Lanqing Guo, Yingqing He, Haoxin Chen, Menghan Xia, Xiaodong Cun, Yufei Wang, Siyu Huang, Yong Zhang, Xintao Wang, Qifeng Chen, Ying Shan, and Bihan Wen. Make a cheap scaling: A self-cascade diffusion model for higher-resolution adaptation. InEur. Conf. Comput. Vis., 2024. 11
work page 2024
-
[22]
Wavelet score-based generative modeling
Florentin Guth, Simon Coste, Valentin De Bortoli, and Stephane Mallat. Wavelet score-based generative modeling. InAdv. Neural Inform. Process. Syst., volume 35, pages 478–491, 2022
work page 2022
-
[23]
Zur theorie der orthogonalen funktionensysteme.Mathematische Annalen, 69(3):331–371, 1910
Alfréd Haar. Zur theorie der orthogonalen funktionensysteme.Mathematische Annalen, 69(3):331–371, 1910
work page 1910
-
[24]
Infinity: Scaling bitwise AutoRegressive modeling for high-resolution image synthesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise AutoRegressive modeling for high-resolution image synthesis. InIEEE Conf. Comput. Vis. Pattern Recog., 2025
work page 2025
-
[25]
Agglomerative token clustering
Joakim Bruslund Haurum, Sergio Escalera, Graham W Taylor, and Thomas B Moeslund. Agglomerative token clustering. InEur. Conf. Comput. Vis., pages 200–218, 2024
work page 2024
-
[26]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdv. Neural Inform. Process. Syst., 2020
work page 2020
-
[27]
Cascaded diffusion models for high fidelity image generation.J
Jonathan Ho, Chitwan Saharia, William Chan, David J Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation.J. Mach. Learn. Res., 23(47):1–33, 2022
work page 2022
-
[28]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInt. Conf. Learn. Represent., 2022
work page 2022
-
[29]
T2I-CompBench: A comprehensive benchmark for open-world compositional text-to-image generation
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2I-CompBench: A comprehensive benchmark for open-world compositional text-to-image generation. InAdv. Neural Inform. Process. Syst., 2023
work page 2023
-
[30]
Wavedm: Wavelet-based diffusion models for image restoration.IEEE Trans
Yi Huang, Jiancheng Huang, Jianzhuang Liu, Mingfu Yan, Yu Dong, Jiaxi Lv, Chaoqi Chen, and Shifeng Chen. Wavedm: Wavelet-based diffusion models for image restoration.IEEE Trans. Multimedia, 26: 7058–7073, 2024
work page 2024
-
[31]
Spectralar: Spectral autoregressive visual generation
Yuanhui Huang, Weiliang Chen, Wenzhao Zheng, Yueqi Duan, Jie Zhou, and Jiwen Lu. Spectralar: Spectral autoregressive visual generation. InInt. Conf. Comput. Vis., pages 15842–15852, 2025
work page 2025
-
[32]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InIEEE Conf. Comput. Vis. Pattern Recog., 2024
work page 2024
-
[33]
Wongi Jeong, Kyungryeol Lee, Hoigi Seo, and Se Young Chun. Training-free mixed-resolution latent upsampling for spatially accelerated diffusion transformers, 2026. URLhttps://arxiv.org/abs/2507. 08422
work page 2026
-
[34]
Pyramidal flow matching for efficient video generative modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. InInt. Conf. Learn. Represent., 2025
work page 2025
-
[35]
Subspace diffusion generative models
Bowen Jing, Gabriele Corso, Renato Berlinghieri, and Tommi Jaakkola. Subspace diffusion generative models. InEur. Conf. Comput. Vis., pages 274–289, 2022
work page 2022
-
[36]
C. Kapfer, K. Stine, B. Narasimhan, C. Mentzel, and E. Candès. Marlowe: Stanford’s GPU-based computational instrument, 2025. URLhttps://doi.org/10.5281/zenodo.14751899
-
[37]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInt. Conf. Mach. Learn., pages 5156–5165. PMLR, 2020
work page 2020
-
[38]
Token fusion: Bridging the gap between token pruning and token merging
Minchul Kim, Shangqian Gao, Yen-Chang Hsu, Yilin Shen, and Hongxia Jin. Token fusion: Bridging the gap between token pruning and token merging. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1383–1392, 2024
work page 2024
-
[39]
DiffuseHigh: Training-free progressive high-resolution image synthesis through structure guidance
Younghyun Kim, Geunmin Hwang, Junyu Zhang, and Eunbyung Park. DiffuseHigh: Training-free progressive high-resolution image synthesis through structure guidance. InAAAI, 2025
work page 2025
-
[40]
Kingma, Tim Salimans, Ben Poole, and Jonathan Ho
Diederik P. Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. InAdv. Neural Inform. Process. Syst., 2021
work page 2021
-
[41]
Black Forest Labs. FLUX. Software repository, 2024. URL https://github.com/ black-forest-labs/flux. 12
work page 2024
-
[42]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. Blog post, 2025. URL https://bfl.ai/ blog/flux-2
work page 2025
-
[43]
Haeil Lee, Hansang Lee, Seoyeon Gye, and Junmo Kim. Beta sampling is all you need: Efficient image generation strategy for diffusion models using stepwise spectral analysis, 2024. URL https: //arxiv.org/abs/2407.12173
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Local representative token guided merging for text-to-image generation, 2025
Min-Jeong Lee, Hee-Dong Kim, and Seong-Whan Lee. Local representative token guided merging for text-to-image generation, 2025. URLhttps://arxiv.org/abs/2507.12771
-
[45]
Frecas: Efficient higher-resolution image generation via frequency-aware cascaded sampling
Ruihuang Li, Lei Zhang, et al. Frecas: Efficient higher-resolution image generation via frequency-aware cascaded sampling. InInt. Conf. Learn. Represent., volume 2025, pages 6400–6412, 2025
work page 2025
-
[46]
Radial attention: O(nlogn) sparse attention with energy decay for long video generation
Xingyang Li, Muyang Li, Tianle Cai, Haocheng Xi, Shuo Yang, Yujun Lin, Lvmin Zhang, Songlin Yang, Jinbo Hu, Kelly Peng, et al. Radial attention: O(nlogn) sparse attention with energy decay for long video generation. InAdv. Neural Inform. Process. Syst., 2025
work page 2025
-
[47]
Wf-vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model
Zongjian Li, Bin Lin, Yang Ye, Liuhan Chen, Xinhua Cheng, Shenghai Yuan, and Li Yuan. Wf-vae: Enhancing video vae by wavelet-driven energy flow for latent video diffusion model. InIEEE Conf. Comput. Vis. Pattern Recog., pages 17778–17788, 2025
work page 2025
-
[48]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. InEur. Conf. Comput. Vis., 2014
work page 2014
-
[49]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInt. Conf. Learn. Represent., 2023
work page 2023
-
[50]
Timestep embedding tells: It’s time to cache for video diffusion model, 2024
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model, 2024. URL https://arxiv.org/abs/2411.19108
-
[51]
FreqCa: Accelerating diffusion models via frequency-aware caching, 2025
Jiacheng Liu, Peiliang Cai, Qinming Zhou, Yuqi Lin, Deyang Kong, Benhao Huang, Yupei Pan, Haowen Xu, Chang Zou, Junshu Tang, Shikang Zheng, and Linfeng Zhang. FreqCa: Accelerating diffusion models via frequency-aware caching, 2025. URLhttps://arxiv.org/abs/2510.08669
-
[52]
From reusing to forecasting: Accelerating diffusion models with TaylorSeers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerating diffusion models with TaylorSeers. InInt. Conf. Comput. Vis., 2025
work page 2025
-
[53]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInt. Conf. Learn. Represent., 2023
work page 2023
-
[54]
ToMA: Token merge with attention for diffusion models
Wenbo Lu, Shaoyi Zheng, Yuxuan Xia, and Shengjie Wang. ToMA: Token merge with attention for diffusion models. InInt. Conf. Mach. Learn., 2025
work page 2025
-
[55]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference, 2023. URLhttps://arxiv.org/abs/2310.04378
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. In IEEE Conf. Comput. Vis. Pattern Recog., 2024
work page 2024
-
[57]
PixelGen: Improving Pixel Diffusion with Perceptual Supervision
Zehong Ma, Ruihan Xu, and Shiliang Zhang. PixelGen: Pixel diffusion beats latent diffusion with perceptual loss, 2026. URLhttps://arxiv.org/abs/2602.02493
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
SDEdit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. InInt. Conf. Learn. Represent., 2022
work page 2022
-
[59]
Anish Mittal, Rajiv Soundararajan, and Alan C. Bovik. Making a “completely blind” image quality analyzer.IEEE Sign. Process. Letters, 20(3):209–212, 2013. doi: 10.1109/LSP.2012.2227726
-
[60]
Soumik Mukhopadhyay, Prateksha Udhayanan, and Abhinav Shrivastava. Scale space diffusion, 2026. URLhttps://arxiv.org/abs/2603.08709
-
[61]
DCTdiff: Intriguing properties of image generative modeling in the DCT space
Mang Ning, Mingxiao Li, Jianlin Su, Jia Haozhe, Lanmiao Liu, Martin Benes, Wenshuo Chen, Albert Ali Salah, and Itir Onal Ertugrul. DCTdiff: Intriguing properties of image generative modeling in the DCT space. InInt. Conf. Mach. Learn., volume 267, pages 46498–46524. PMLR, 2025. 13
work page 2025
-
[62]
NVIDIA, Yuval Atzmon, Maciej Bala, Yogesh Balaji, Tiffany Cai, Yin Cui, Jiaojiao Fan, Yunhao Ge, Siddharth Gururani, Jacob Huffman, Ronald Isaac, Pooya Jannaty, Tero Karras, Grace Lam, J. P. Lewis, Aaron Licata, Yen-Chen Lin, Ming-Yu Liu, Qianli Ma, Arun Mallya, Ashlee Martino-Tarr, Doug Mendez, Seungjun Nah, Chris Pruett, Fitsum Reda, Jiaming Song, Ting-...
-
[63]
Harry Nyquist. Certain topics in telegraph transmission theory.Transactions of the American Institute of Electrical Engineers, 47(2):617–644, 1928
work page 1928
-
[64]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InInt. Conf. Comput. Vis., 2023
work page 2023
-
[65]
Wavelet diffusion models are fast and scalable image generators
Hao Phung, Quan Dao, and Anh Tran. Wavelet diffusion models are fast and scalable image generators. In IEEE Conf. Comput. Vis. Pattern Recog., 2023
work page 2023
-
[66]
DiMSUM: Diffusion Mamba – a scalable and unified spatial-frequency method for image generation
Hao Phung, Quan Dao, Trung Dao, Hoang Phan, Dimitris Metaxas, and Anh Tran. DiMSUM: Diffusion Mamba – a scalable and unified spatial-frequency method for image generation. InAdv. Neural Inform. Process. Syst., 2024
work page 2024
-
[67]
FreeScale: Unleashing the resolution of diffusion models via tuning-free scale fusion
Haonan Qiu et al. FreeScale: Unleashing the resolution of diffusion models via tuning-free scale fusion. In Int. Conf. Comput. Vis., 2025
work page 2025
-
[68]
FlowAR: Scale-wise autoregressive image generation meets flow matching
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, and Liang-Chieh Chen. FlowAR: Scale-wise autoregressive image generation meets flow matching. InInt. Conf. Mach. Learn., 2025
work page 2025
-
[69]
Generative modelling with inverse heat dissipation
Severi Rissanen, Markus Heinonen, and Arno Solin. Generative modelling with inverse heat dissipation. InInt. Conf. Learn. Represent., 2023
work page 2023
-
[70]
Origins of scaling in natural images.Vis
Daniel L Ruderman. Origins of scaling in natural images.Vis. Res., 37(23):3385–3398, 1997
work page 1997
-
[71]
Pyramidal denoising diffusion probabilistic models, 2022
Dohoon Ryu and Jong Chul Ye. Pyramidal denoising diffusion probabilistic models, 2022. URL https: //arxiv.org/abs/2208.01864
-
[72]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInt. Conf. Learn. Represent., 2022
work page 2022
-
[73]
Claude E. Shannon. Communication in the presence of noise.Proceedings of the IRE, 37(1):10–21, 1949
work page 1949
-
[74]
Latent Wavelet Diffusion For Ultra-High-Resolution Image Synthesis
Luigi Sigillo, Shengfeng He, and Danilo Comminiello. Latent wavelet diffusion for ultra-high-resolution image synthesis, 2025. URLhttps://arxiv.org/abs/2506.00433
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Improving the diffusability of autoencoders
Ivan Skorokhodov, Sharath Girish, Benran Hu, Willi Menapace, Yanyu Li, Rameen Abdal, Sergey Tulyakov, and Aliaksandr Siarohin. Improving the diffusability of autoencoders. InInt. Conf. Mach. Learn., 2025
work page 2025
-
[76]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInt. Conf. Learn. Represent., 2021
work page 2021
-
[77]
Lssgen: Leveraging latent space scaling in flow and diffusion for efficient text to image generation
Jyun-Ze Tang, Chih-Fan Hsu, Jeng-Lin Li, Ming-Ching Chang, and Wei-Chao Chen. Lssgen: Leveraging latent space scaling in flow and diffusion for efficient text to image generation. InInt. Conf. Comput. Vis., pages 5048–5057, 2025
work page 2025
-
[79]
Relay diffusion: Unifying diffusion process across resolutions for image synthesis
Jiayan Teng, Wendi Zheng, Ming Ding, Wenyi Hong, Jianqiao Wangni, Zhuoyi Yang, and Jie Tang. Relay diffusion: Unifying diffusion process across resolutions for image synthesis. InInt. Conf. Learn. Represent.,
-
[80]
Visual autoregressive modeling: Scalable image generation via next-scale prediction
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction. InAdv. Neural Inform. Process. Syst., 2024
work page 2024
-
[81]
Training-free diffusion acceleration with bot- tleneck sampling.arXiv preprint arXiv:2503.18940,
Ye Tian, Xin Xia, Yuxi Ren, Shanchuan Lin, Xing Wang, Xuefeng Xiao, Yunhai Tong, Ling Yang, and Bin Cui. Training-free diffusion acceleration with bottleneck sampling, 2025. URL https://arxiv.org/ abs/2503.18940
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.