Code-Guided Reasoning for Small Language Models: Evaluating Executable MCQA Scaffolds
Pith reviewed 2026-05-20 21:03 UTC · model grok-4.3
The pith
Code scaffolds improve small language model accuracy on multiple-choice questions by 28 percentage points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
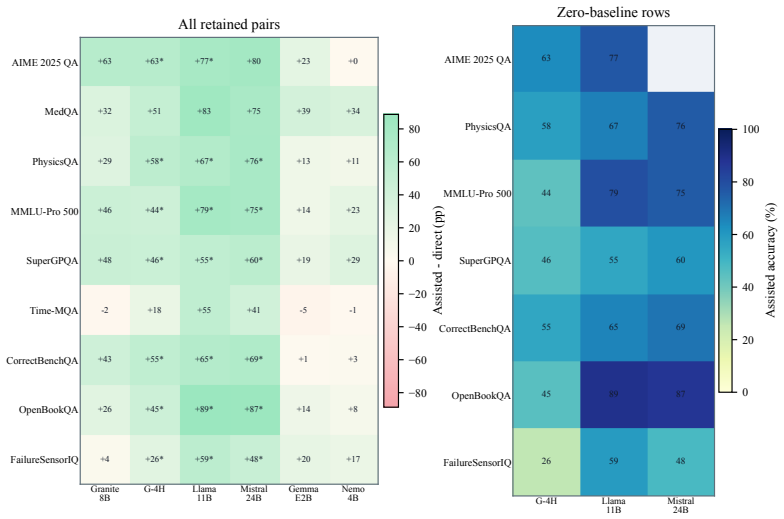
The authors claim that an executable reasoning scaffold in which the model first writes a Python program to analyze the question and then runs it for answer extraction produces substantially higher accuracy than direct answering on MCQA tasks for small language models, with the macro difference measured at +28.10 percentage points across the non-zero-baseline partition of results.
What carries the argument
Code-Guided Reasoning (CGR), the standardized protocol with its six components: normalized item interface, direct solver prompt, generator prompt, Python scaffold, solver-call and extraction helpers, and three-channel result record.
If this is right
- Small language models can offload complex reasoning steps to executable code and thereby reach higher accuracy on multiple-choice tasks.
- Standardized scaffolds allow direct comparison of assisted versus direct performance across different solver models.
- The protocol records generator-side answers and full program traces, enabling diagnosis of when code helps versus when it fails.
- Some generated programs violate the no-hard-coding rule, showing that instruction adherence remains an issue even when accuracy rises.
Where Pith is reading between the lines
- The same scaffold approach could be applied to open-ended reasoning benchmarks to test whether the accuracy lift generalizes beyond fixed choices.
- Replacing the brittle extraction step with more robust parsing or verification could increase the reliability of the assisted path.
- Combining CGR with different programming languages or with retrieval of verified code snippets might further isolate the contribution of execution itself.
Load-bearing premise
That answer extraction from the executed program output is reliable and that the generated programs supply genuine reasoning assistance rather than incidental hard-coding or leakage.
What would settle it
A replication on the same questions and models in which direct accuracy equals or exceeds assisted accuracy or in which a large share of program outputs cannot be extracted reliably.
Figures

















read the original abstract
Multiple-choice QA benchmarks usually evaluate small language models (SLMs) as direct answerers, but deployed language-model systems increasingly rely on external scaffolds such as tools, code, and repeated model calls. We introduce Code-Guided Reasoning (CGR), an evaluation protocol and generated-program resource for measuring when executable reasoning scaffolds improve SLM performance on MCQA tasks. CGR standardizes six components: a normalized item interface, a direct solver prompt, a generator prompt, a Python scaffold, solver-call and extraction helpers, and a three-channel result record. On 20,498 retained result rows from a locally prepared MCQA bundle and six metadata-registered solver models, the observed non-zero-baseline partition shows 66.21% macro assisted accuracy versus 38.11% direct accuracy, a +28.10 percentage-point difference with a pair-bootstrap interval of [20.32, 36.43]. Under a stricter Ab > 30% direct-signal gate, the macro difference is +14.11 points. These estimates are descriptive. Assisted inference uses a larger solver-call budget, answer extraction is brittle, Time-MQA contains the observed regressions, and some generated programs violate the no-hard-coding instruction. CGR provides the trace package needed to interpret these results, including direct, assisted, and generator-side answers, partition definitions, generated programs, response metadata, and audits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Code-Guided Reasoning (CGR), a standardized evaluation protocol and generated-program resource for assessing when executable code scaffolds improve small language model (SLM) performance on multiple-choice QA (MCQA) tasks. It reports descriptive results on 20,498 retained rows from a locally prepared MCQA bundle and six solver models: in the non-zero-baseline partition, macro assisted accuracy reaches 66.21% versus 38.11% direct accuracy (+28.10 pp, pair-bootstrap interval [20.32, 36.43]); a stricter Ab > 30% direct-signal gate yields +14.11 pp. The authors explicitly characterize the estimates as descriptive, noting larger solver budgets for assisted inference, brittle answer extraction, regressions in Time-MQA, and some generated programs violating the no-hard-coding instruction, while supplying a full trace package for interpretation.
Significance. The primary contribution is the CGR protocol itself together with the accompanying trace package (direct/assisted/generator answers, partition definitions, generated programs, metadata, and audits). This resource enables reproducible examination of scaffold effects and could support future work on tool-augmented SLM inference. Because the manuscript already flags the key methodological caveats and presents the numbers as descriptive rather than causal, the significance lies more in the standardized evaluation framework than in any strong claim of reasoning improvement.
major comments (2)
- [Abstract] Abstract: The reported +28.10 pp macro difference and its bootstrap interval treat extracted answers as valid, yet the abstract itself flags brittle extraction and instruction violations without providing extraction success rates, failure-mode counts, or the fraction of programs that hard-code answers across the 20,498 rows. A quantitative audit of these issues is needed to establish whether the observed lift is robust to extraction mechanics.
- [Results] Results (non-zero-baseline and Ab > 30% partitions): The central descriptive comparison rests on the definition and application of the non-zero-baseline partition and the stricter direct-signal gate. Without explicit formulas or pseudocode showing how baseline accuracy is computed per item and how the gate filters rows, it is difficult to verify that the +28.10 pp and +14.11 pp differences are not sensitive to partition construction choices.
minor comments (2)
- [Abstract] Abstract: The phrase 'Time-MQA contains the observed regressions' is undefined; a brief parenthetical or footnote clarifying what Time-MQA refers to and its relation to the MCQA bundle would improve readability.
- The manuscript would benefit from a small summary table listing the six metadata-registered solver models, their parameter counts, and any key differences in prompt handling.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. We address each major comment below, indicating where revisions have been made to improve clarity and transparency while preserving the descriptive framing of the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported +28.10 pp macro difference and its bootstrap interval treat extracted answers as valid, yet the abstract itself flags brittle extraction and instruction violations without providing extraction success rates, failure-mode counts, or the fraction of programs that hard-code answers across the 20,498 rows. A quantitative audit of these issues is needed to establish whether the observed lift is robust to extraction mechanics.
Authors: We agree that quantifying extraction success, failure modes, and hard-coding violations would strengthen the presentation. The manuscript already characterizes the estimates as descriptive and notes these caveats, while the released trace package supplies the complete set of generated programs, solver outputs, extraction logs, and metadata for all 20,498 rows. In the revised manuscript we have added a concise quantitative audit summary to the abstract and a dedicated paragraph in the Results section reporting aggregate extraction success rates, primary failure-mode counts, and the fraction of programs flagged for hard-coding violations. These additions are derived directly from the trace package and support interpretation of the reported differences without changing their descriptive status. revision: yes
-
Referee: [Results] Results (non-zero-baseline and Ab > 30% partitions): The central descriptive comparison rests on the definition and application of the non-zero-baseline partition and the stricter direct-signal gate. Without explicit formulas or pseudocode showing how baseline accuracy is computed per item and how the gate filters rows, it is difficult to verify that the +28.10 pp and +14.11 pp differences are not sensitive to partition construction choices.
Authors: We appreciate the request for explicit definitions. The revised Methods section now includes formal definitions together with pseudocode for (i) the non-zero-baseline partition, which retains items for which at least one of the six direct solvers produces a correct answer, and (ii) the stricter Ab > 30% direct-signal gate. We have also added a short sensitivity table showing that the reported macro differences remain stable under modest changes to the threshold. These additions enable readers to reproduce the partitions exactly and to assess sensitivity. revision: yes
Circularity Check
No circularity: purely empirical comparison of inference modes
full rationale
The paper presents an evaluation protocol (CGR) and reports descriptive statistics from running direct vs. assisted inference on 20,498 retained MCQA items across six models. The central claim is an observed +28.10 pp macro accuracy lift on the non-zero-baseline partition, accompanied by a bootstrap interval. No mathematical derivation, fitted parameter, or self-referential quantity is defined; the result is a direct measurement of two inference procedures on the same items. The abstract itself flags brittleness in extraction and instruction violations as limitations rather than claiming a closed-form or self-justifying result. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Executable code actions elicit better LLM agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM agents. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 50208–50232, 2024
work page 2024
-
[2]
LLMs for doctors: Leveraging medical LLMs to assist doctors, not replace them, 2024
Wenya Xie, Qingying Xiao, Yu Zheng, Xidong Wang, Junying Chen, Ke Ji, Anningzhe Gao, Xiang Wan, Feng Jiang, and Benyou Wang. LLMs for doctors: Leveraging medical LLMs to assist doctors, not replace them, 2024
work page 2024
-
[3]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[4]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023
work page 2023
-
[5]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of thoughts prompt- ing: Disentangling computation from reasoning for numerical reasoning tasks.Transactions on Machine Learning Research, 2023
work page 2023
-
[6]
PAL: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. PAL: Program-aided language models. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 10764–10799, 2023
work page 2023
-
[7]
ToolQA: A dataset for LLM question answering with external tools
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. ToolQA: A dataset for LLM question answering with external tools. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[8]
InterCode: Standard- izing and benchmarking interactive coding with execution feedback
John Yang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Yao. InterCode: Standard- izing and benchmarking interactive coding with execution feedback. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[9]
Ling Yang, Zhaochen Yu, Tianjun Zhang, Shiyi Cao, Minkai Xu, Wentao Zhang, Joseph E. Gonzalez, and Bin Cui. Buffer of thoughts: Thought-augmented reasoning with large language models. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[10]
ReasonFlux: Hierarchical LLM reasoning via scaling thought templates, 2025
Ling Yang, Zhaochen Yu, Bin Cui, and Mengdi Wang. ReasonFlux: Hierarchical LLM reasoning via scaling thought templates, 2025
work page 2025
-
[11]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[12]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, 2018
work page 2018
-
[13]
Time-MQA: Time series multi-task question answering with context enhancement
Yaxuan Kong, Yiyuan Yang, Yoontae Hwang, Wenjie Du, Stefan Zohren, Zhangyang Wang, Ming Jin, and Qingsong Wen. Time-MQA: Time series multi-task question answering with context enhancement. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 29736–29753, 2025
work page 2025
-
[14]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, et al. Humanity’s last exam, 2025
work page 2025
-
[15]
Measuring coding challenge competence with APPS
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with APPS. InAdvances in Neural Information Processing Systems, 2021. 10
work page 2021
-
[16]
DataComp: In search of the next generation of multimodal datasets
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. DataComp: In search of the next generation of multimodal datasets. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[17]
DecodingTrust: A comprehensive assess- ment of trustworthiness in GPT models
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, et al. DecodingTrust: A comprehensive assess- ment of trustworthiness in GPT models. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[18]
Art of Problem Solving Wiki. 2025 AIME I. AoPS Wiki page, 2025. Accessed 2026-05-04
work page 2025
-
[19]
Art of Problem Solving Wiki. 2025 AIME II. AoPS Wiki page, 2025. Accessed 2026-05-04
work page 2025
-
[20]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
work page 2021
-
[21]
Improving physics reasoning in large language models using mixture of refinement agents, 2024
Raj Jaiswal, Dhruv Jain, Harsh Parimal Popat, Avinash Anand, Abhishek Dharmadhikari, Atharva Marathe, and Rajiv Ratn Shah. Improving physics reasoning in large language models using mixture of refinement agents, 2024
work page 2024
-
[22]
SuperGPQA: Scaling LLM evaluation across 285 graduate disciplines, 2025
M-A-P Team, Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, King Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, et al. SuperGPQA: Scaling LLM evaluation across 285 graduate disciplines, 2025
work page 2025
-
[23]
Correctbench: A benchmark of self-correction in llms
Guiyao Tie, Zenghui Yuan, Zeli Zhao, Chaoran Hu, Tianhe Gu, Ruihang Zhang, Sizhe Zhang, Junran Wu, Xiaoyue Tu, Ming Jin, Qingsong Wen, Lixing Chen, Pan Zhou, and Lichao Sun. Correctbench: A benchmark of self-correction in llms. InProceedings of the NeurIPS 2025 Datasets and Benchmarks Track, 2025
work page 2025
-
[24]
FailuresensorIQ: A multi-choice QA dataset for understanding sensor relationships and failure modes
Christodoulos Constantinides, Dhaval C Patel, Shuxin Lin, Claudio Guerrero, SUNIL DA- GAJIRAO PATIL, and Jayant Kalagnanam. FailuresensorIQ: A multi-choice QA dataset for understanding sensor relationships and failure modes. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2026
work page 2026
-
[25]
Gemma 4 E2B: Intelligence, performance and price analysis
Artificial Analysis. Gemma 4 E2B: Intelligence, performance and price analysis. Model analysis page, 2026. Accessed 2026-05-05
work page 2026
-
[26]
NVIDIA Nemotron 3 nano 4b: Intelligence, performance and price analysis
Artificial Analysis. NVIDIA Nemotron 3 nano 4b: Intelligence, performance and price analysis. Model analysis page, 2026. Accessed 2026-05-05. 11 A Additional Analyses The additional analyses below preserve the same claim scope as the primary result. CGR observes the same target solver under a direct option-selection prompt and under a generated Python ski...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.