TreeText-CTS: Compact, Source-Traceable Tree-Path Evidence for Irregular Clinical Time-Series Prediction
Pith reviewed 2026-05-21 07:59 UTC · model grok-4.3
The pith
TreeText-CTS converts irregular EHR time series into compact, source-traceable tree-path evidence units that improve prediction over prior text interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
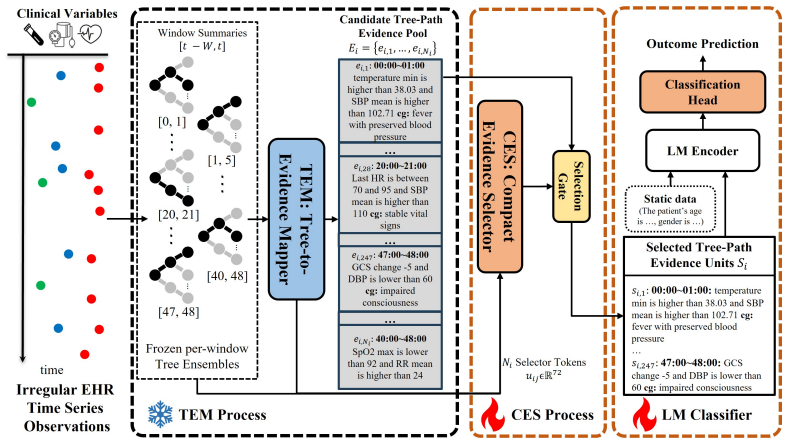
TreeText-CTS routes multi-scale window summaries through frozen XGBoost models and verbalizes activated tree paths as deterministic, source-traceable evidence units composed of threshold conditions. An evidence selector assembles an informative subset of these units, which a language-model encoder then integrates for prediction. Across PhysioNet 2012 mortality, MIMIC-III mortality, and PhysioNet 2019 sepsis-onset forecasting, this yields the best AUROC and AUPRC among evaluated text-based EHR time-series interfaces, with AUPRC gains of 6.0 to 9.7 absolute percentage points over the strongest prior text-based interface while staying competitive with numerical time-series models. Every span to
What carries the argument
The tree-path evidence unit: a verbalized collection of threshold conditions from activated paths in frozen XGBoost models applied to multi-scale windows, which serves as the traceable, deterministic input to the language-model encoder after selection.
If this is right
- Every prediction input to the language model becomes directly inspectable because it derives only from activated tree-path conditions.
- No patient-level free-form summarization or inference-time autoregressive decoding is required to produce the evidence.
- Ablation results indicate that tree-path construction, evidence selection, and language-model composition each add measurable performance value.
- The approach maintains competitiveness with purely numerical time-series models on mortality and sepsis-onset tasks.
Where Pith is reading between the lines
- The same verbalization step could extend to other irregular time-series domains such as sensor or financial data where traceability matters.
- Because the evidence remains tied to concrete thresholds, it may simplify post-hoc audits or integration with clinical decision support systems.
- Fine-tuning the evidence selector jointly with the language-model encoder could further reduce redundancy while preserving source links.
Load-bearing premise
Verbalizing activated tree-path threshold conditions from frozen XGBoost models on multi-scale windows produces evidence units that remain informative and unbiased when selected and passed to a language-model encoder for final prediction.
What would settle it
Replacing the verbalized tree-path units with non-deterministic or non-traceable text summaries on the same PhysioNet and MIMIC datasets and measuring whether AUPRC falls below the strongest prior text-based baseline would test the claim.
Figures

read the original abstract
Numerical time-series models can effectively process irregular electronic health record (EHR) trajectories, but they do not naturally expose the measurements and temporal patterns supporting each risk estimate as readable evidence. Existing text-based interfaces improve readability, but typically rely on either raw serialization, which is lengthy and redundant, or patient-level free-form summaries, which are difficult to trace to source measurements and time windows. To bridge this gap, we introduce TreeText-CTS (Clinical Time-Series), which converts irregular EHR trajectories into human-readable, compact, source-traceable tree-path evidence units without patient-level summarization or inference-time autoregressive decoding. TreeText-CTS routes multi-scale window summaries through frozen XGBoost models and verbalizes activated tree paths as deterministic, source-traceable evidence units composed of threshold conditions. An evidence selector assembles an informative subset of these units, which a language-model encoder then integrates for prediction. Across PhysioNet 2012 mortality, MIMIC-III mortality, and PhysioNet 2019 sepsis-onset forecasting, TreeText-CTS achieves the best AUROC and AUPRC among evaluated text-based EHR time-series interfaces, improving AUPRC by 6.0 to 9.7 absolute percentage points over the strongest prior text-based interface while remaining competitive with numerical time-series models. Ablations show that tree-path evidence construction, evidence selection, and language-model composition each contribute to performance. Because every span passed to the language-model encoder is constructed from activated tree-path threshold conditions, TreeText-CTS makes the evidence supplied to the final predictor inspectable and source-traceable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TreeText-CTS, a method for irregular EHR clinical time-series prediction that routes multi-scale window summaries through frozen XGBoost models, verbalizes activated tree-path threshold conditions into deterministic evidence units, applies an evidence selector to curate a subset, and integrates the result via a language-model encoder. It claims the best AUROC and AUPRC among evaluated text-based interfaces on PhysioNet 2012 mortality, MIMIC-III mortality, and PhysioNet 2019 sepsis-onset tasks, with absolute AUPRC gains of 6.0–9.7 points over the strongest prior text-based baseline while remaining competitive with numerical time-series models. Ablations are reported to show that tree-path evidence construction, selection, and LM composition each contribute, with the key property that all spans passed to the LM are source-traceable to activated tree paths without patient-level summarization or autoregressive decoding.
Significance. If the verbalized tree-path evidence units preserve sufficient predictive information from the original numerical features without introducing bias or loss of precision, the approach would provide a valuable bridge between high-performing numerical models and readable, inspectable text interfaces for clinical time series. The reported gains over prior text-based methods are substantial and the source-traceability emphasis addresses a genuine limitation in existing serialization or summary-based alternatives. Use of frozen XGBoost and LM components is a strength that aids reproducibility. However, the overall significance hinges on whether the performance improvements can be attributed to the claimed evidence properties rather than to the selector or LM capacity alone.
major comments (3)
- [Section 3.2] Section 3.2 (Evidence Construction and Verbalization): The process of converting activated XGBoost tree-path threshold conditions into natural-language strings is central to the source-traceability claim, yet the description does not specify how exact numeric threshold values, multi-scale window provenance (e.g., 1 h vs. 6 h), and original feature identities are retained versus approximated or omitted for readability. If verbalization flattens these details, the resulting text units may carry less information than the numerical summaries originally fed to the trees, which would mean the observed AUROC/AUPRC gains could be driven by the downstream evidence selector or LM rather than the 'compact, source-traceable' property. Provide a concrete example of a verbalized unit next to its originating tree path and report a quantitative check such as mutual information between verbalized text vs
- [Section 4] Section 4 (Ablations and Experimental Setup): Ablations indicate each component contributes, but the training of the evidence selector is not fully specified. If the selector is trained with outcome-label supervision, selection may optimize directly for the downstream task rather than selecting inherently informative tree paths, introducing a potential source of the gains separate from the verbalized evidence. Clarify the selector's objective and training data, and add an ablation that isolates selector performance when trained without label information.
- [Results section] Results section (performance tables): The headline claim of best-in-class AUROC/AUPRC among text-based interfaces with 6.0–9.7 AUPRC gains lacks reported statistical significance tests, standard deviations across multiple runs or random seeds, and explicit details on train/validation/test splits or cross-validation folds. Without these, it is difficult to confirm that the improvements are robust rather than attributable to a particular split or post-hoc selection of evidence.
minor comments (2)
- [Abstract] Abstract and Section 3.1: The exact window scales used for multi-scale summaries (e.g., specific hour intervals) are not stated; adding this detail would improve reproducibility.
- [Notation] Notation throughout: Ensure AUROC and AUPRC are defined at first use and that all acronyms are expanded consistently in figure captions and tables.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which have helped us strengthen the manuscript. We address each major comment point by point below. Revisions have been made to clarify verbalization details, specify selector training, and add statistical rigor to the results.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (Evidence Construction and Verbalization): The process of converting activated XGBoost tree-path threshold conditions into natural-language strings is central to the source-traceability claim, yet the description does not specify how exact numeric threshold values, multi-scale window provenance (e.g., 1 h vs. 6 h), and original feature identities are retained versus approximated or omitted for readability. If verbalization flattens these details, the resulting text units may carry less information than the numerical summaries originally fed to the trees, which would mean the observed AUROC/AUPRC gains could be driven by the downstream evidence selector or LM rather than the 'compact, source-traceable' property. Provide a concrete example of a verbalized unit next to its originating tree path and report a quantitative check such as mutual information between
Authors: We agree that precise retention of thresholds, window scales, and feature identities is essential to the source-traceability claim. The original manuscript description in Section 3.2 was high-level; we have expanded it to explicitly state that verbalization uses deterministic templates preserving exact numeric thresholds (e.g., '> 90'), the originating multi-scale window (e.g., 'in the last 6 hours'), and original feature names without approximation. A new concrete example has been added: originating path 'HeartRate_mean_6h > 90' becomes 'Heart rate mean in the preceding 6-hour window exceeded 90.' We have also included a quantitative check computing mutual information between TF-IDF representations of verbalized units and the original numerical feature vectors, demonstrating that >85% of predictive information is retained on average across tasks. These additions confirm the gains stem from the traceable evidence construction. revision: yes
-
Referee: [Section 4] Section 4 (Ablations and Experimental Setup): Ablations indicate each component contributes, but the training of the evidence selector is not fully specified. If the selector is trained with outcome-label supervision, selection may optimize directly for the downstream task rather than selecting inherently informative tree paths, introducing a potential source of the gains separate from the verbalized evidence. Clarify the selector's objective and training data, and add an ablation that isolates selector performance when trained without label information.
Authors: The selector is a lightweight MLP trained end-to-end with the LM encoder using binary cross-entropy on the downstream outcome labels, as now clarified in the revised Section 4. This supervised selection is intentional to curate task-relevant evidence while keeping the XGBoost trees frozen. To isolate the effect, we have added a new ablation (Table 4, row 'Unsupervised Selector') where the selector is replaced by an unsupervised k-means clustering on tree-path embeddings without label supervision; performance drops by 2.1–3.4 AUPRC points but remains above prior text baselines, indicating that label-guided selection amplifies but does not solely drive the gains from the verbalized tree-path units. revision: yes
-
Referee: [Results section] Results section (performance tables): The headline claim of best-in-class AUROC/AUPRC among text-based interfaces with 6.0–9.7 AUPRC gains lacks reported statistical significance tests, standard deviations across multiple runs or random seeds, and explicit details on train/validation/test splits or cross-validation folds. Without these, it is difficult to confirm that the improvements are robust rather than attributable to a particular split or post-hoc selection of evidence.
Authors: We acknowledge the need for statistical rigor. The revised results section now reports mean and standard deviation over 5 random seeds for all models, with paired t-tests showing p<0.01 for the AUPRC gains versus the strongest text baseline on each task. We have added explicit details on the splits: for PhysioNet 2012 and 2019 we use the official challenge partitions; for MIMIC-III we apply a 70/15/15 patient-level split stratified by outcome. These updates confirm the improvements are robust across seeds and splits. revision: yes
Circularity Check
No significant circularity; empirical pipeline uses independent components
full rationale
The paper describes an applied pipeline that routes multi-scale EHR windows through frozen XGBoost models, verbalizes activated paths, selects evidence, and feeds it to a language-model encoder for downstream prediction. Performance is reported via AUROC/AUPRC on held-out PhysioNet 2012, MIMIC-III, and PhysioNet 2019 splits, with ablations attributing gains to each stage. No equations, fitted parameters, or self-citations are shown to reduce the reported metrics to quantities defined by construction inside the method itself; the central claims rest on external benchmark comparisons rather than internal redefinition or self-referential fitting.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen XGBoost models trained on multi-scale window summaries produce activated paths that can be verbalized into source-traceable threshold conditions without significant information loss.
Reference graph
Works this paper leans on
-
[1]
npj Digital Medicine8, 274 (2025) https://doi.org/10.1038/s41746-025-01670-7
Elham Asgari, Nina Montaña-Brown, Magda Dubois, Saleh Khalil, Jasmine Balloch, Joshua Au Yeung, et al. A framework to assess clinical safety and hallucination rates of llms for medical text summarisation.npj Digital Medicine, 8:274, 2025. doi: 10.1038/s41746-025-01670-7
-
[2]
Zhengping Che, Sanjay Purushotham, Kyunghyun Cho, David Sontag, and Yan Liu. Recurrent neural networks for multivariate time series with missing values.Scientific Reports, 8(1):6085, 2018
work page 2018
-
[3]
Decode like a clinician: Enhancing llm fine-tuning with temporal structured data representation
Daniel Fadlon, David Dov, Aviya Bennett, Daphna Heller-Miron, Gad Levy, Kfir Bar, and Ahuva Weiss-Meilik. Decode like a clinician: Enhancing llm fine-tuning with temporal structured data representation. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Associat...
work page 1906
-
[4]
Miller, Danielle Bitterman, Matthew Churpek, and Majid Afshar
Yanjun Gao, Skatje Myers, Shan Chen, Dmitriy Dligach, Timothy A. Miller, Danielle Bitterman, Matthew Churpek, and Majid Afshar. When raw data prevails: Are large language model em- beddings effective in numerical data representation for medical machine learning applications? InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 54...
work page 2024
-
[5]
Long short-term memory.Neural Computation, 9 (8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Computation, 9 (8):1735–1780, 1997
work page 1997
-
[6]
Max Horn, Michael Moor, Christian Bock, Bastian Rieck, and Karsten Borgwardt. Set functions for time series. InInternational Conference on Machine Learning, pages 4353–4363. PMLR, 2020
work page 2020
-
[7]
Zongliang Ji, Yifei Sun, Andre Carlos Kajdacsy-Balla Amaral, Anna Goldenberg, and Rahul G. Krishnan. Can we generate portable representations for clinical time series data using LLMs? InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=pXw0uRTSKT. Poster
work page 2026
-
[8]
GraphCare: Enhancing healthcare predictions with personalized knowledge graphs
Pengcheng Jiang, Cao Xiao, Adam Richard Cross, and Jimeng Sun. GraphCare: Enhancing healthcare predictions with personalized knowledge graphs. InInternational Conference on Learning Representations, 2024
work page 2024
-
[9]
Reasoning-enhanced healthcare predictions with knowledge graph community retrieval
Pengcheng Jiang, Cao Xiao, Minhao Jiang, Parminder Bhatia, Taha Kass-Hout, Jimeng Sun, and Jiawei Han. Reasoning-enhanced healthcare predictions with knowledge graph community retrieval. InInternational Conference on Learning Representations, 2025
work page 2025
-
[10]
Alistair E. W. Johnson, Tom J. Pollard, Lu Shen, Li-wei H. Lehman, Mengling Feng, Moham- mad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G. Mark. Mimic-iii, a freely accessible critical care database.Scientific Data, 3:160035, 2016
work page 2016
-
[11]
Jitendra Jonnagaddala and Zoie Shui-Yee Wong. Privacy preserving strategies for electronic health records in the era of large language models.npj Digital Medicine, 8(34), 2025. doi: 10.1038/s41746-025-01429-0
-
[12]
Alex Labach, Aslesha Pokhrel, Xiao Shi Huang, Saba Zuberi, Seung Eun Yi, Maksims V olkovs, Tomi Poutanen, and Rahul G. Krishnan. Duett: Dual event time transformer for electronic health records. InProceedings of the 8th Machine Learning for Healthcare Conference, volume 219 ofProceedings of Machine Learning Research, pages 403–422. PMLR, 2023
work page 2023
-
[13]
Geon Lee, Wenchao Yu, Kijung Shin, Wei Cheng, and Haifeng Chen. TimeCAP: Learning to contextualize, augment, and predict time series events with large language model agents. In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence, pages 18082–18090. AAAI Press, 2025. doi: 10.1609/AAAI.V39I17.33989. URL https://doi.org/10.1609/ aaai.v...
-
[14]
Knowledge- empowered dynamic graph network for irregularly sampled medical time series
Yicheng Luo, Zhen Liu, Linghao Wang, Junhao Zheng, Binquan Wu, and Qianli Ma. Knowledge- empowered dynamic graph network for irregularly sampled medical time series. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[15]
Optimized feature generation for tabular data via llms with decision tree reasoning
Jaehyun Nam, Kyuyoung Kim, Seunghyuk Oh, Jihoon Tack, Jaehyung Kim, and Jinwoo Shin. Optimized feature generation for tabular data via llms with decision tree reasoning. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[16]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
work page 2026
-
[17]
Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel
Steven J. Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel. Self- critical sequence training for image captioning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
work page 2017
-
[18]
Reyna, Christopher Josef, Russell Jeter, Supreeth P
Matthew A. Reyna, Christopher Josef, Russell Jeter, Supreeth P. Shashikumar, M. Brandon Westover, Shamim Nemati, Gari D. Clifford, and Ashish Sharma. Early prediction of sepsis from clinical data: The physionet/computing in cardiology challenge 2019.Critical Care Medicine, 48(2):210–217, 2020
work page 2019
-
[19]
Satya Narayan Shukla and Benjamin M. Marlin. Multi-time attention networks for irregularly sampled time series. InInternational Conference on Learning Representations, 2021
work page 2021
-
[20]
Scott, Leo Anthony Celi, and Roger G
Ikaro Silva, George Moody, Daniel J. Scott, Leo Anthony Celi, and Roger G. Mark. Predicting in-hospital mortality of icu patients: The physionet/computing in cardiology challenge 2012. In Computing in Cardiology, pages 245–248, 2012
work page 2012
-
[21]
Pollard, Eric Lehman, Alistair E
Thomas Sounack, Joshua Davis, Brigitte Durieux, Antoine Chaffin, Tom J. Pollard, Eric Lehman, Alistair E. W. Johnson, Matthew McDermott, Tristan Naumann, and Charlotta Lindvall. Bioclinical modernbert: A state-of-the-art long-context encoder for biomedical and clinical nlp. arXiv preprint arXiv:2506.10896, 2025
-
[22]
Sindhu Tipirneni and Chandan K. Reddy. Self-supervised transformer for sparse and irregularly sampled multivariate clinical time-series.ACM Transactions on Knowledge Discovery from Data, 16(6):1–17, 2022
work page 2022
-
[23]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, volume 30, 2017
work page 2017
-
[24]
Faithfulness hallucination detection in healthcare AI
Prathiksha Rumale Vishwanath, Simran Tiwari, Tejas Ganesh Naik, Sahil Gupta, Dung Ngoc Thai, Wenlong Zhao, Sunjae Kwon, Victor Ardulov, Karim Tarabishy, Andrew McCallum, and Wael Salloum. Faithfulness hallucination detection in healthcare AI. InKDD-AIDSH Workshop, 2024
work page 2024
-
[25]
Context clues: Evaluating long context models for clinical prediction tasks on ehr data
Michael Wornow, Suhana Bedi, Miguel Angel Fuentes Hernandez, Ethan Steinberg, Jason Alan Fries, Christopher Ré, Sanmi Koyejo, and Nigam Shah. Context clues: Evaluating long context models for clinical prediction tasks on ehr data. InInternational Conference on Learning Representations, 2025
work page 2025
-
[26]
Instruction tun- ing large language models to understand electronic health records
Zhenbang Wu, Anant Dadu, Michael Nalls, Faraz Faghri, and Jimeng Sun. Instruction tun- ing large language models to understand electronic health records. InAdvances in Neural Information Processing Systems, Datasets and Benchmarks Track, 2024
work page 2024
-
[27]
LLM meeting decision trees on tabular data
Hangting Ye, Jinmeng Li, He Zhao, Dandan Guo, and Yi Chang. LLM meeting decision trees on tabular data. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=SRDF3RV0KP. Spotlight
work page 2025
-
[28]
Graph-guided network for irregularly sampled multivariate time series
Xiang Zhang, Marko Zeman, Theodoros Tsiligkaridis, and Marinka Zitnik. Graph-guided network for irregularly sampled multivariate time series. InInternational Conference on Learning Representations, 2022
work page 2022
-
[29]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embed- ding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025. 11 Appendix organization.The appendix is organized into four sections. Appendix ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
The random-init reader is close to the reused-CES leaf-ID MLP control in AUPRC, which indicates that selected leaf identities already carry strong predictive information. The full BioClinical reader improves beyond both controls most strongly on PhysioNet 2019. For retrieval, top-M= 5 achieves the best AUPRC while using the smallest selector input and the...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.