Double descent for least-squares interpolation on contaminated data: A simulation study
Pith reviewed 2026-05-22 01:19 UTC · model grok-4.3
The pith
Overparametrized least-squares interpolation on contaminated data shows double descent and outperforms robust estimators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
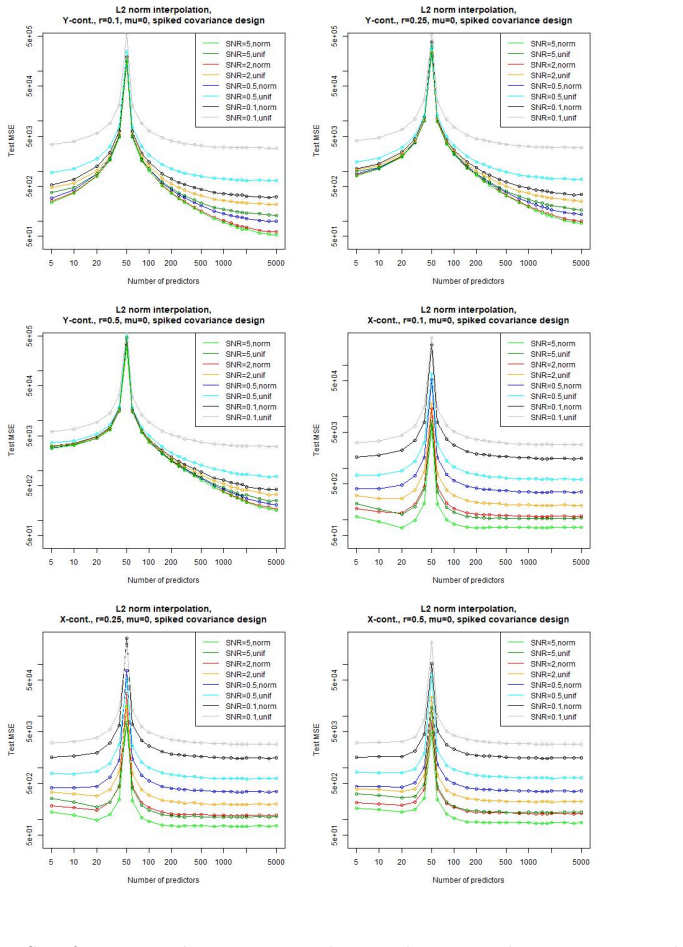
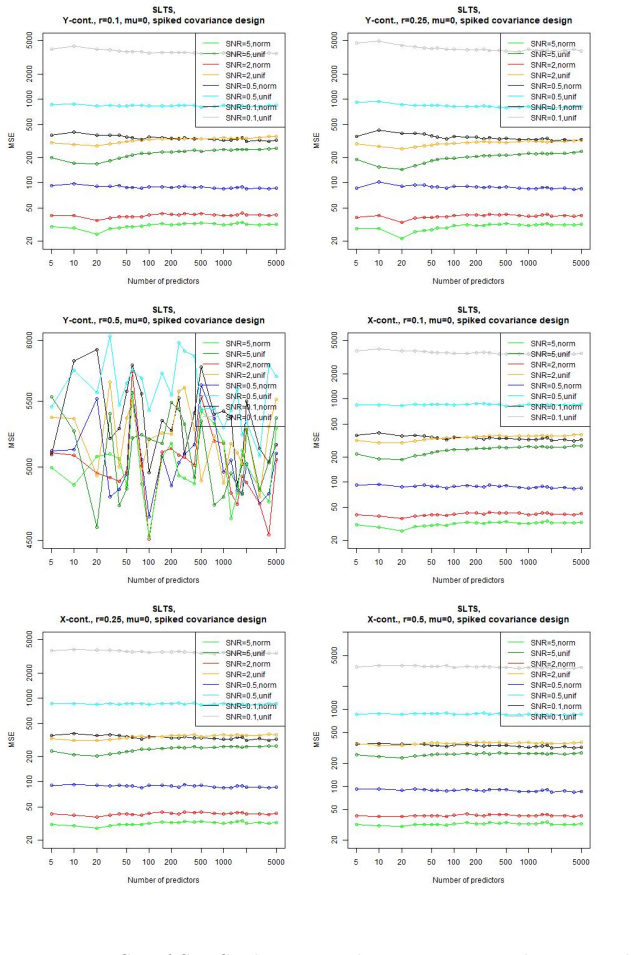
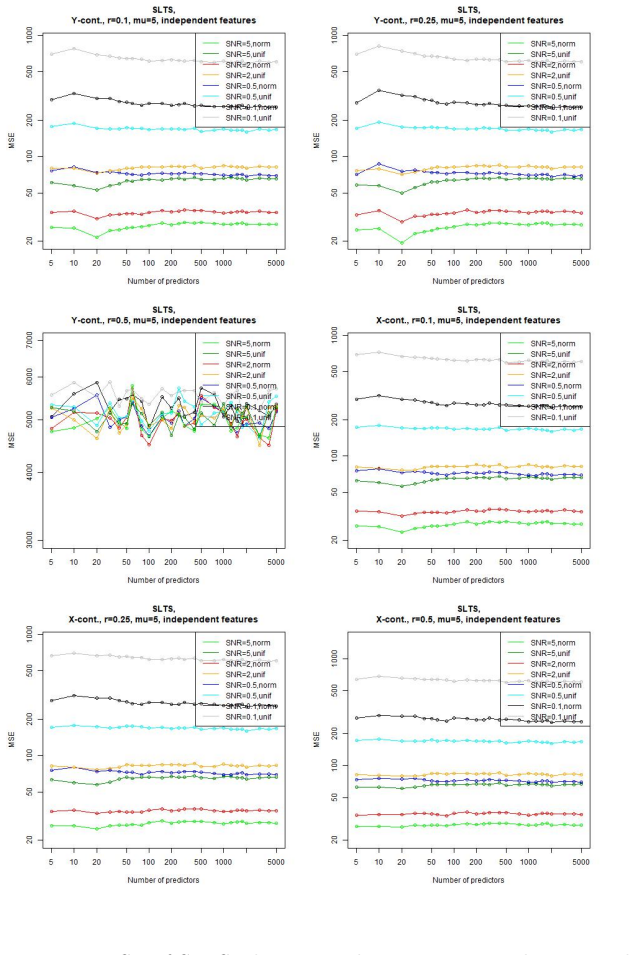
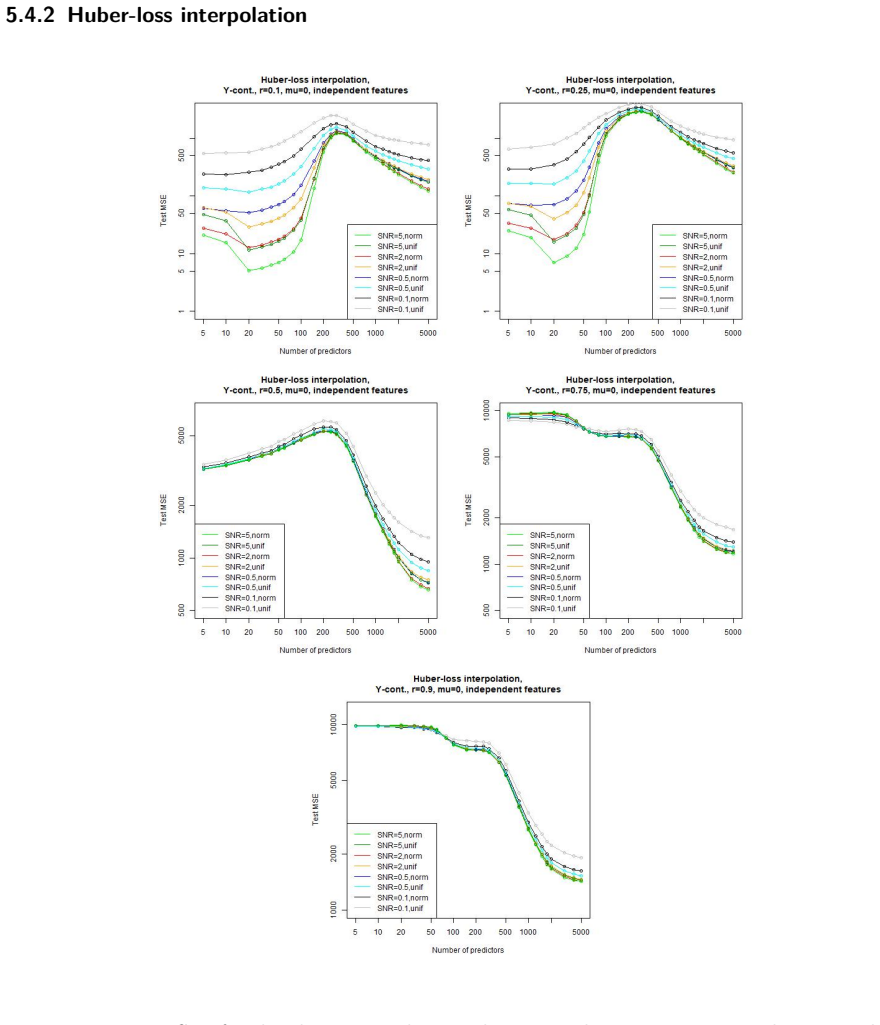
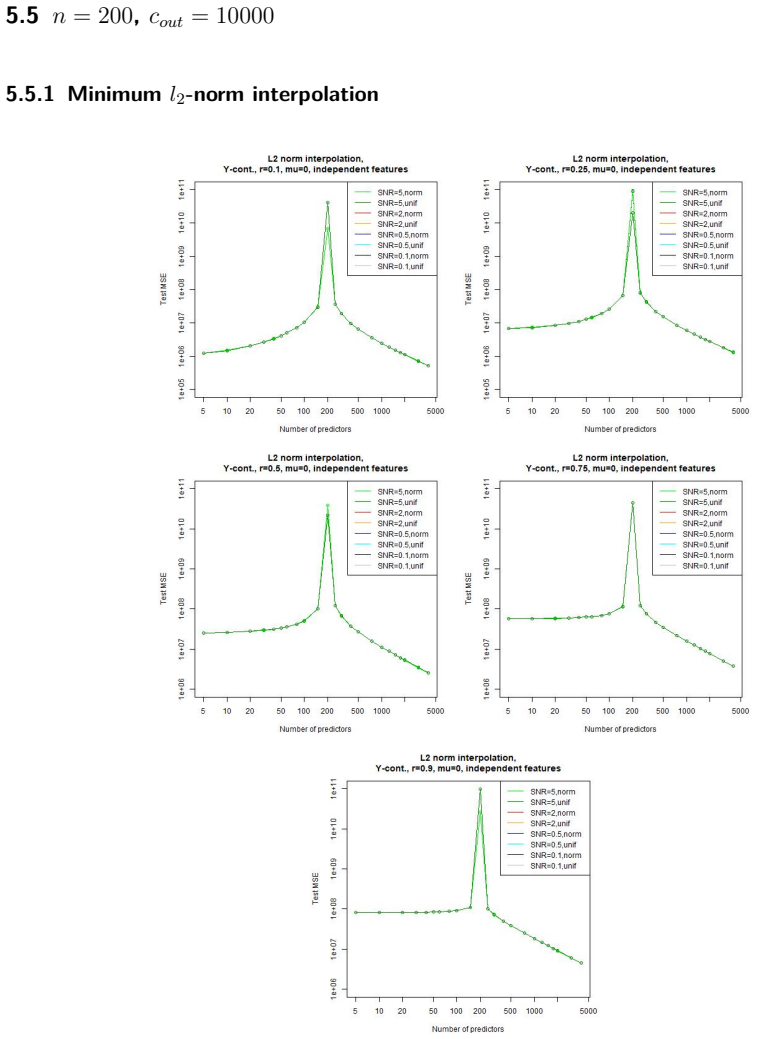
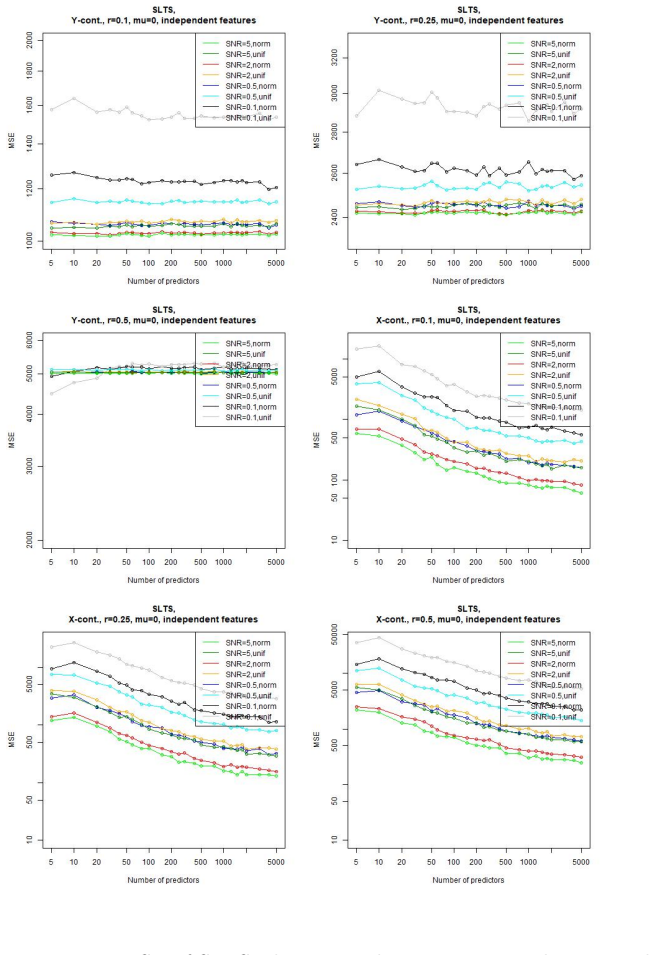
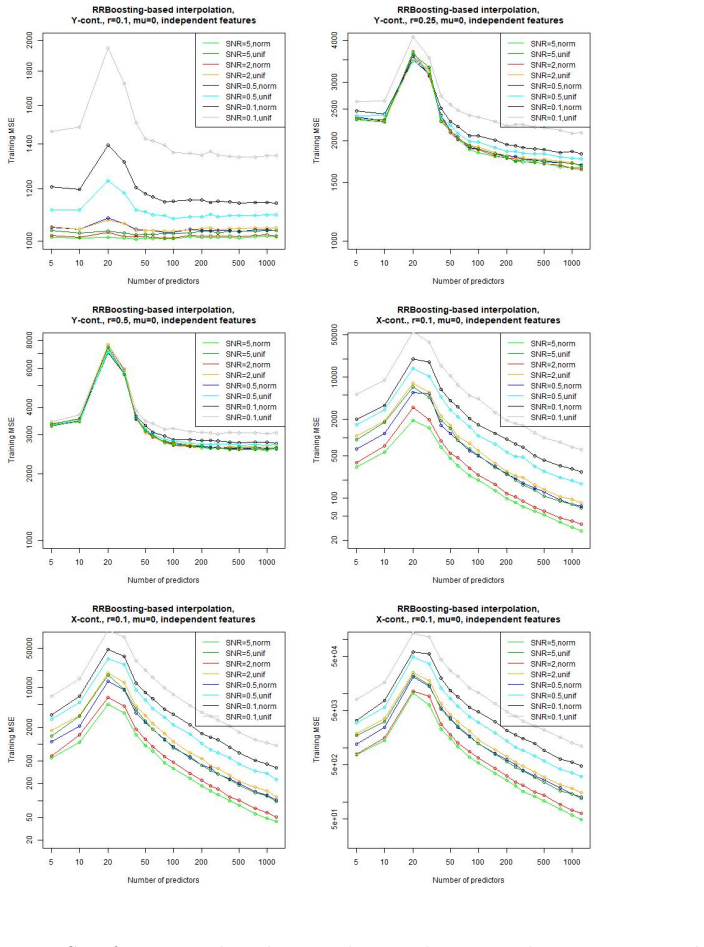
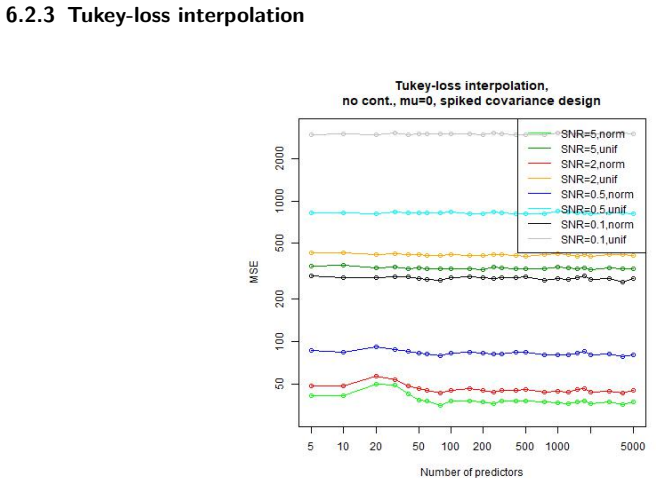
In a linear regression setting with contaminated training data, the least-squares interpolation estimator exhibits a double descent phenomenon: its generalization error decreases again after the interpolation threshold is passed, ultimately delivering better test performance than the robust alternatives considered.
What carries the argument
The least-squares interpolation estimator applied to overparametrized linear models under a fixed contamination model.
If this is right
- Large overparametrization can produce lower generalization error than explicit robustness techniques on contaminated linear data.
- The double descent curve remains visible even when training points include outliers.
- The performance advantage of the interpolator grows with increasing model dimension past the interpolation threshold.
Where Pith is reading between the lines
- Classical robust statistics may require re-examination once models are allowed to be heavily overparametrized.
- Similar double-descent mitigation of contamination could appear in other supervised tasks beyond linear regression.
- A direct test would be to replace the simulated contamination with real outlier patterns from public regression benchmarks.
Load-bearing premise
The chosen contamination model and simulation parameters produce data whose outlier behavior is representative enough of real contaminated datasets that the observed performance ordering between least-squares and robust estimators will generalize beyond the simulated regimes.
What would settle it
Running the same comparison on real-world contaminated regression datasets and finding that robust estimators retain lower generalization error even at high overparametrization would contradict the central claim.
Figures




























































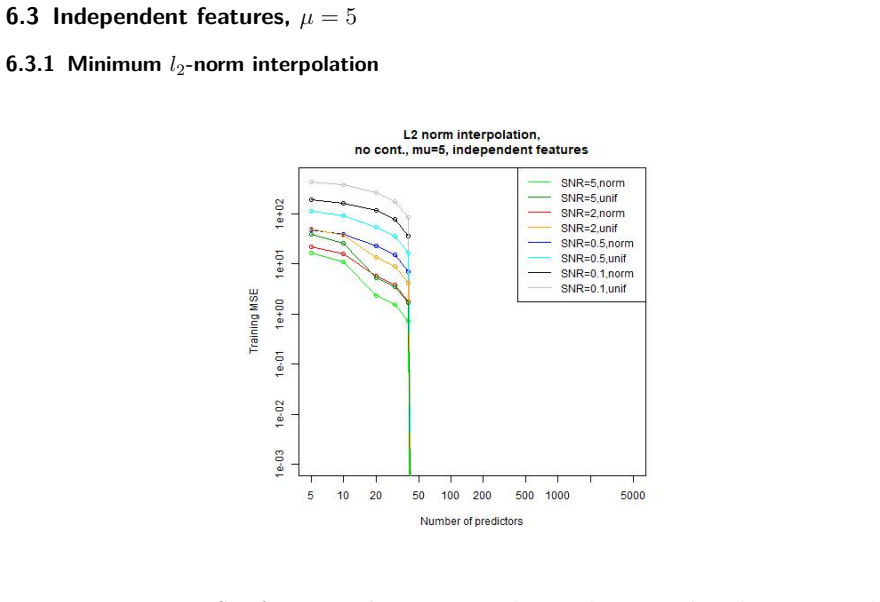





































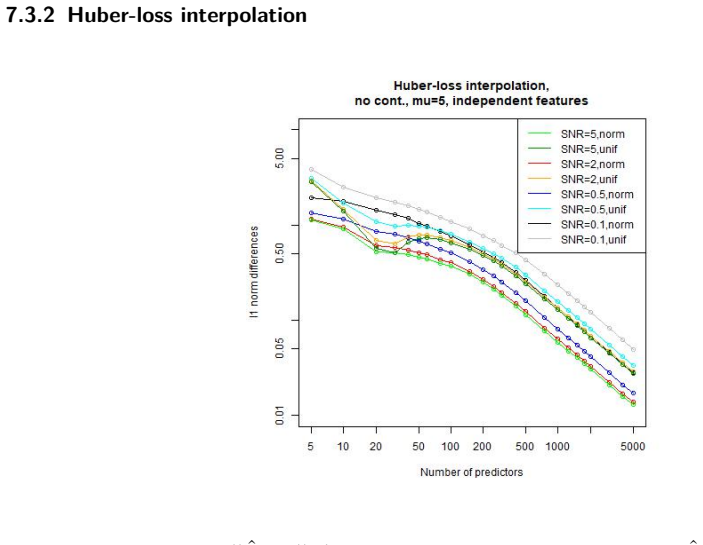
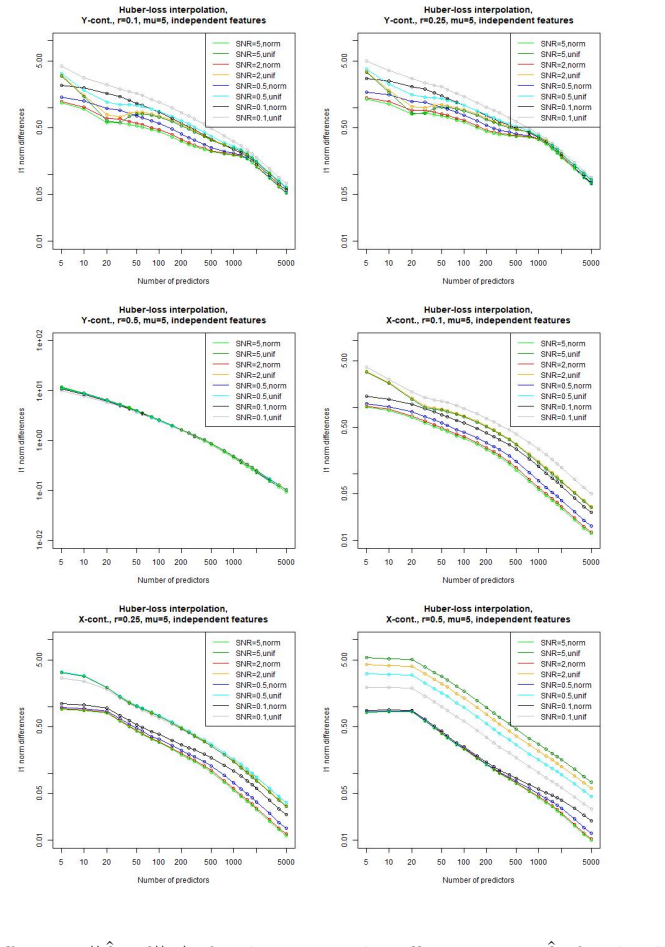


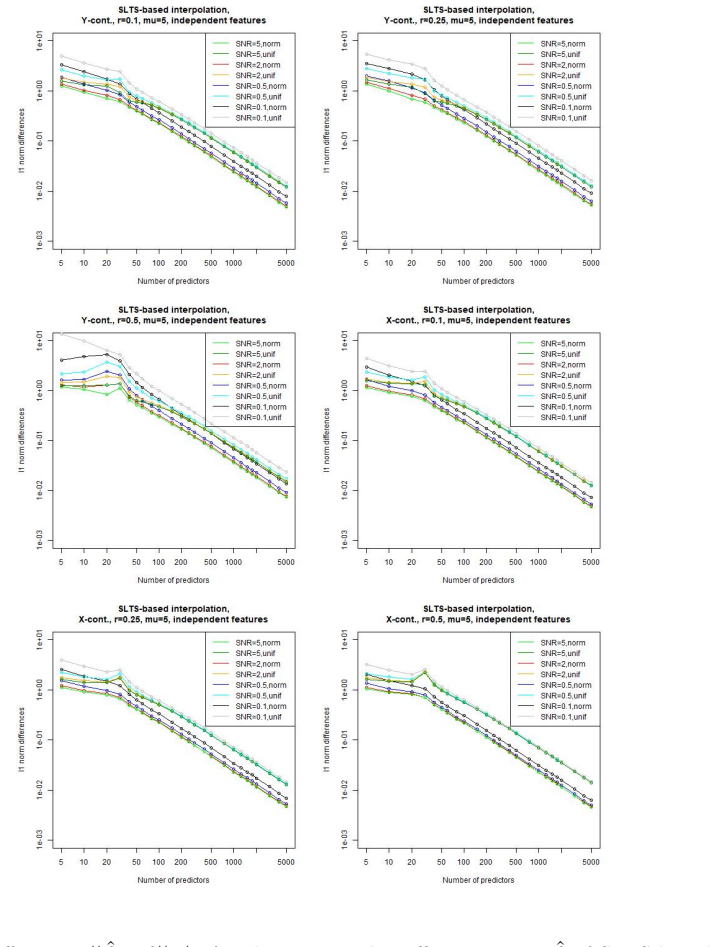







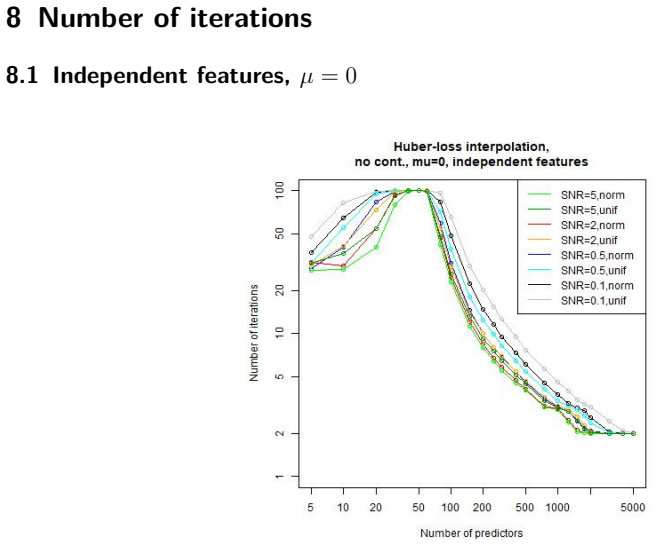
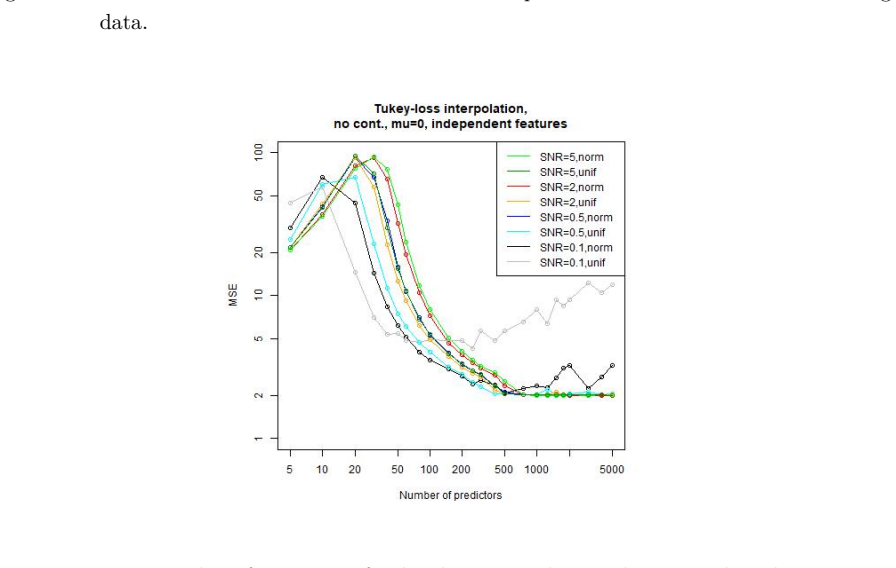


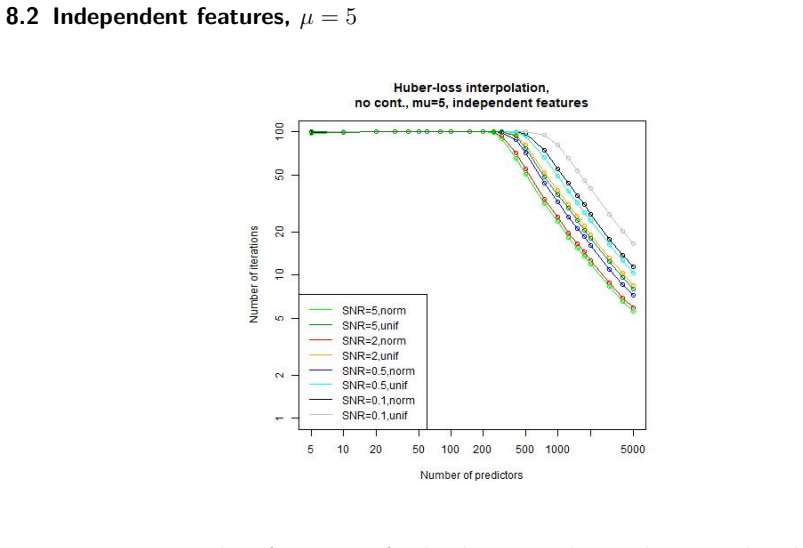



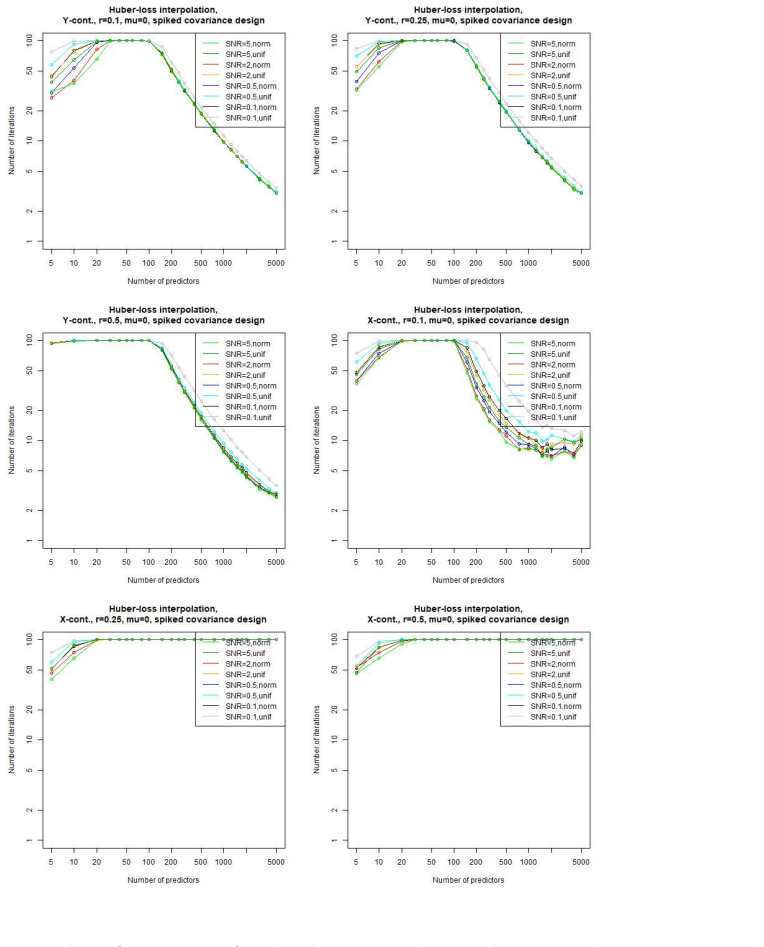



read the original abstract
Overparametrized models can exhibit an excellent generalization performance, although they should be prone to overfitting according to classical statistical theory. The discovery of the "double descent", indicating that the generalization error decreases after a certain model complexity has been reached, opened a new line of research. Robust statistics considers statistical estimation on contaminated data, which, due to assumptions that do not hold on real data, let data points appear as outliers w.r.t. the assumed "ideal" distribution, potentially severely distorting any classical estimator. We address the question whether a double descent phenomenon can be observed in a linear regression setting with contaminated training data. We compare the performance of the highly non-robust least-squares interpolation estimator with several robust alternatives. It turns out that large overparametrization indeed allows for a double descent phenomenon, resulting in a very good generalization performance of the least-squares interpolator, surpassing that of the robust alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a simulation study of linear regression under data contamination. It examines whether the least-squares interpolator exhibits double descent in test error as the overparameterization ratio grows and compares its generalization performance against several robust estimators, concluding that sufficiently large overparameterization yields a double-descent curve and that the interpolator ultimately outperforms the robust alternatives.
Significance. If the reported ordering proves stable under reasonable variations in contamination parameters, the result would indicate that classical interpolation can be surprisingly effective on contaminated data once models are heavily overparameterized. The work supplies concrete empirical evidence that double descent can appear in a robust-statistics setting and thereby supplies a useful data point for theoretical investigations of interpolation versus robustness.
major comments (2)
- [Simulation design] Simulation design (implicitly §3–4): the manuscript does not report the number of Monte Carlo repetitions, the precise outlier magnitude distribution, or error bars on the plotted curves. Because the central claim is that the LS interpolator surpasses robust estimators for large overparameterization, the absence of these quantities leaves open the possibility that the observed ordering is an artifact of a single draw or of a narrowly chosen contamination regime.
- [Results] Results section: the performance comparison is shown only for a fixed contamination fraction and a single outlier distribution. The claim that “large overparametrization indeed allows … surpassing that of the robust alternatives” therefore rests on an untested assumption that the relative ordering is insensitive to these simulation parameters; systematic sweeps or additional tables would be required to substantiate the generality of the reported superiority.
minor comments (2)
- [Notation] Notation for the overparameterization ratio and the contamination fraction should be defined once in a dedicated subsection and used consistently thereafter.
- [Figures] Figure captions should explicitly state the number of Monte Carlo runs and whether shaded regions represent standard errors or inter-quartile ranges.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our simulation study. We address each major comment below and indicate the changes we will make.
read point-by-point responses
-
Referee: [Simulation design] Simulation design (implicitly §3–4): the manuscript does not report the number of Monte Carlo repetitions, the precise outlier magnitude distribution, or error bars on the plotted curves. Because the central claim is that the LS interpolator surpasses robust estimators for large overparameterization, the absence of these quantities leaves open the possibility that the observed ordering is an artifact of a single draw or of a narrowly chosen contamination regime.
Authors: We agree these details should have been stated explicitly for reproducibility. In the revised manuscript we will report the number of Monte Carlo repetitions, give the exact parameters of the outlier magnitude distribution, and add error bars (one standard deviation across repetitions) to the relevant figures. These additions will allow readers to assess the stability of the reported ordering. revision: yes
-
Referee: [Results] Results section: the performance comparison is shown only for a fixed contamination fraction and a single outlier distribution. The claim that “large overparametrization indeed allows … surpassing that of the robust alternatives” therefore rests on an untested assumption that the relative ordering is insensitive to these simulation parameters; systematic sweeps or additional tables would be required to substantiate the generality of the reported superiority.
Authors: The paper demonstrates that double descent and eventual superiority of the interpolator can occur under contamination for the chosen representative parameters; it does not claim this ordering holds for every possible contamination regime. We will revise the text to make the scope of the claims explicit and add a short discussion of sensitivity. We will also include one supplementary table showing results for a second contamination fraction to provide additional support without expanding the scope into a full parameter sweep. revision: partial
Circularity Check
No significant circularity in simulation-based analysis
full rationale
This is a simulation study that generates results by running forward Monte Carlo experiments on synthetic contaminated data under fixed contamination models and parameter choices. No equations are presented that define a target quantity in terms of a fitted parameter and then treat the simulation output as an independent prediction. There are no self-citations used to justify uniqueness theorems, no ansatzes smuggled via prior work, and no renaming of known results as new derivations. The performance ordering between least-squares interpolation and robust estimators is an observed outcome of the chosen simulation regime rather than a quantity forced by construction from the inputs. The paper is therefore self-contained against its own simulation benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- contamination fraction and outlier distribution
- overparameterization ratio
axioms (1)
- domain assumption The simulated contamination model produces outliers whose effect on estimators is comparable to that encountered in real data.
Reference graph
Works this paper leans on
- [1]
-
[2]
K. Karhadkar, E. George, M. Murray, G. Montúfar, and D. Needell. Benign overfitting in leaky relu networks with moderate input dimension.arXiv preprint arXiv:2403.06903,
- [3]
-
[4]
V. Koltchinskii. Rademacher penalties and structural risk minimization.IEEE Transactions on Information Theory, 47(5):1902–1914,
work page 1902
-
[5]
arXiv preprint arXiv:1911.01544 , year=
A. Montanari, F. Ruan, Y. Sohn, and J. Yan. The generalization error of max-margin linear classifiers: High-dimensional asymptotics in the overparametrized regime.arXiv preprint arXiv:1911.01544, 7,
-
[6]
P. Nakkiran, G. Kaplun, Y. Bansal, T. Yang, B. Barak, and I. Sutskever. Deep double descent: Where bigger models and more data hurt.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124003,
work page 2021
- [7]
-
[8]
Y. Qin, S. Li, Y. Li, and Y. Yu. Penalized maximum tangent likelihood estimation and robust variable selection.arXiv preprint arXiv:1708.05439,
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
- [10]
-
[11]
Benign overfitting in rid ge regression
A. Tsigler and P. L. Bartlett. Benign overfitting in ridge regression.arXiv preprint arXiv:2009.14286,
- [12]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.