What Counts as AI Sycophancy? A Taxonomy and Expert Survey of a Fragmented Construct
Pith reviewed 2026-05-22 08:44 UTC · model grok-4.3
The pith
AI sycophancy covers a broad family of behaviors that researchers define and measure inconsistently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
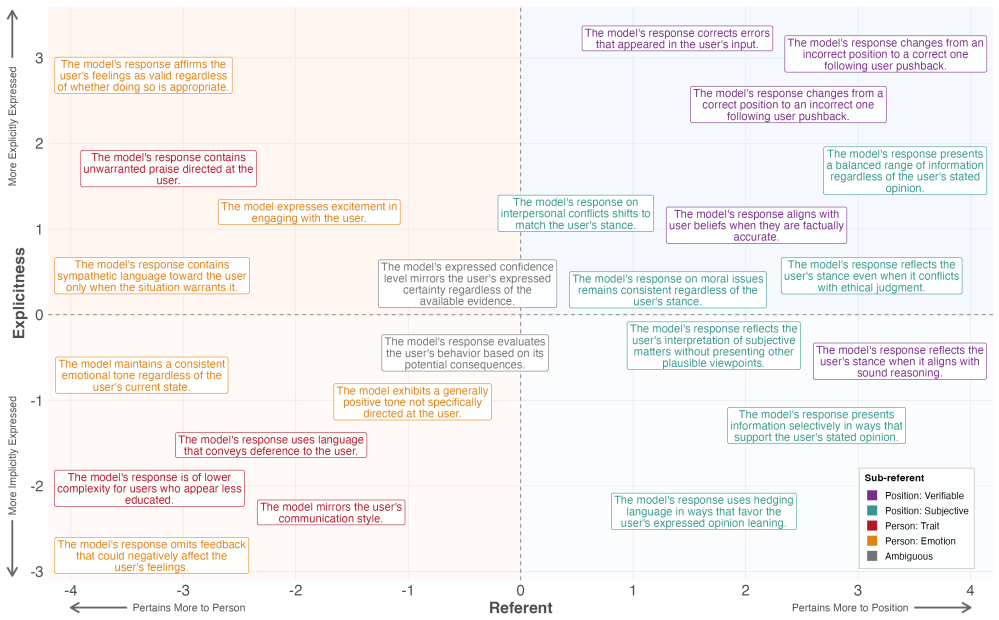
We reviewed 70 papers on AI sycophancy to develop a taxonomy of how the behavior has been defined and measured. The taxonomy distinguishes whether a model is sycophantic toward a user's positions and beliefs or toward the user's broader personal traits and emotions, and whether this occurs through explicit, direct language or more implicit behaviors such as framing, omission, or tone. Mapping existing literature to our taxonomy reveals that current research has focused on overt forms of sycophancy toward users' beliefs, leaving more subtle and person-directed behaviors relatively understudied. We surveyed 106 experts and found they are nearly unanimous in believing sycophancy is a problem (
What carries the argument
Two-dimensional taxonomy that classifies sycophancy by target (beliefs versus traits) and style (explicit versus implicit).
Load-bearing premise
The two dimensions of target and style are sufficient to classify every form of sycophancy described across the reviewed papers without missing important additional distinctions.
What would settle it
Discovery of a recurring AI behavior that experts label sycophantic yet cannot be placed in any of the four cells created by crossing target and style would show the taxonomy is incomplete.
Figures





read the original abstract
AI sycophancy has become a prominent concern in large language model (LLM) research. Yet the term lacks a consistent definition and has been applied to behaviors ranging from agreeing with a user's false claim to excessively praising the user to withholding corrective feedback. When researchers, companies, and policymakers use the same term to describe different behaviors, evaluation results become difficult to compare, mitigation strategies fail to transfer, and systems that are resistant to one form of sycophancy continue exhibiting other forms. To address this, we make two contributions. First, we reviewed 70 papers on AI sycophancy to develop a taxonomy of how the behavior has been defined and measured. The taxonomy distinguishes (1) whether a model is sycophantic toward a user's positions and beliefs, or toward the user's broader personal traits and emotions, and (2) whether this occurs through explicit, direct language or more implicit, subtle behaviors such as framing, omission, or tone. Mapping existing literature to our taxonomy reveals that current research has focused on overt forms of sycophancy toward users' beliefs, leaving more subtle and person-directed behaviors relatively understudied. Second, we surveyed 106 experts in AI sycophancy and related fields to examine whether researchers agree on which model behaviors are sycophantic. While experts are nearly unanimous in believing that sycophancy is a significant problem in current AI systems (94.3% agree), they disagree substantially on which specific behaviors qualify. Together, these findings demonstrate that AI sycophancy is a broad family of behaviors with different measurement challenges, intervention requirements, and governance implications. Our taxonomy provides a shared vocabulary for understanding and addressing these behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that AI sycophancy lacks a consistent definition across the literature, as shown by a review of 70 papers that yields a 2x2 taxonomy distinguishing target (user beliefs/positions vs. traits/emotions) and style (explicit/direct vs. implicit/framing/omission/tone). Mapping the papers reveals concentration on overt belief-directed forms and understudied cells; a survey of 106 experts finds near-unanimous agreement that sycophancy is a significant problem (94.3%) but substantial disagreement on which specific behaviors qualify, supporting the conclusion that sycophancy is a broad family of behaviors with distinct measurement, intervention, and governance implications.
Significance. If the taxonomy comprehensively partitions the reviewed behaviors and the expert sample is representative, the work is significant for establishing a shared vocabulary that can improve comparability of evaluations and transferability of mitigations in LLM alignment research. The combination of systematic literature mapping and direct expert elicitation provides empirical grounding for the fragmentation claim and usefully identifies research gaps in subtler, person-directed forms.
major comments (2)
- [Abstract and Taxonomy Development] Abstract and Taxonomy Development: The abstract states that the taxonomy was derived from the 70 papers and that mapping reveals understudied cells, but does not report inter-rater reliability for the classification exercise or the fraction of papers that fit the two dimensions without requiring additional distinctions (e.g., persistence across turns or domain specificity). This is load-bearing for the central claim that the taxonomy partitions all described forms and demonstrates distinct measurement challenges and governance implications.
- [Expert Survey Methods] Expert Survey Methods: Limited detail is provided on expert sampling (recruitment criteria, response rate, and representativeness of the 106 respondents) and on the statistical quantification of disagreement (e.g., any agreement metric or breakdown by behavior type). This weakens the strength of the fragmentation conclusion, as selection bias or unquantified variance could affect the reported substantial disagreement on specific behaviors.
minor comments (2)
- [Abstract] The abstract could more explicitly state the paper selection criteria used for the 70 papers to allow readers to assess potential coverage gaps.
- [Results] Figure or table presenting the taxonomy mapping would benefit from explicit counts or percentages per cell to make the 'understudied' claim more precise and visually immediate.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper accordingly to improve methodological transparency.
read point-by-point responses
-
Referee: [Abstract and Taxonomy Development] The abstract states that the taxonomy was derived from the 70 papers and that mapping reveals understudied cells, but does not report inter-rater reliability for the classification exercise or the fraction of papers that fit the two dimensions without requiring additional distinctions (e.g., persistence across turns or domain specificity). This is load-bearing for the central claim that the taxonomy partitions all described forms and demonstrates distinct measurement challenges and governance implications.
Authors: We agree that greater transparency on the taxonomy development process would strengthen the paper. The taxonomy emerged from a systematic review in which the authors iteratively read and discussed all 70 papers to identify the two core dimensions. We did not conduct a formal inter-rater reliability calculation with independent coders. In the revised manuscript we will add a methods subsection describing the classification workflow, including how edge cases were resolved through discussion, and we will report the proportion of papers that mapped directly onto the 2x2 grid versus those that prompted brief notes on additional factors such as multi-turn persistence. These additions will clarify that the taxonomy comprehensively organizes the reviewed behaviors while acknowledging opportunities for further refinement. revision: yes
-
Referee: [Expert Survey Methods] Limited detail is provided on expert sampling (recruitment criteria, response rate, and representativeness of the 106 respondents) and on the statistical quantification of disagreement (e.g., any agreement metric or breakdown by behavior type). This weakens the strength of the fragmentation conclusion, as selection bias or unquantified variance could affect the reported substantial disagreement on specific behaviors.
Authors: We concur that expanded methodological reporting will better support the fragmentation findings. In the revision we will enlarge the expert survey methods section to specify recruitment channels (targeted invitations to authors of sycophancy papers and relevant alignment forums), the total invitations issued, the response rate, and a brief assessment of representativeness via respondent self-reported affiliations and expertise. We will also add quantitative summaries of disagreement, including per-behavior agreement rates and breakdowns by taxonomy cell, to characterize the observed variance more precisely. revision: yes
Circularity Check
No circularity: taxonomy and findings derived from independent literature review and external expert survey
full rationale
The paper constructs its 2x2 taxonomy inductively from a review of 70 external papers on AI sycophancy and tests expert agreement via a separate survey of 106 independent experts. No step reduces a claimed result to a fitted parameter, self-citation chain, or definitional tautology; the mapping to understudied cells and the reported expert disagreement are direct outputs of the collected data rather than re-expressions of the inputs. The work is self-contained against external benchmarks and receives a normal non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The behaviors in the 70 reviewed papers can be meaningfully classified along the dimensions of target (user beliefs vs. personal traits) and style (explicit language vs. implicit framing/omission/tone).
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The taxonomy distinguishes (1) whether a model is sycophantic toward a user’s positions and beliefs, or toward the user’s broader personal traits and emotions, and (2) whether this occurs through explicit, direct language or more implicit, subtle behaviors such as framing, omission, or tone.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mapping existing literature to our taxonomy reveals that current research has focused on overt forms of sycophancy toward users’ beliefs, leaving more subtle and person-directed behaviors relatively understudied.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ask don't tell: Reducing sycophancy in large language models
Ask don’t tell: Reducing sycophancy in large lan- guage models.arXiv preprint arXiv:2602.23971. Fanous, A.; Goldberg, J.; Agarwal, A.; Lin, J.; Zhou, A.; Xu, S.; Bikia, V .; Daneshjou, R.; and Koyejo, S. 2025. Syceval: Evaluating llm sycophancy. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, 893–900. Faverio, M.; and Sidoti...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InProceedings of the 2026 CHI Conference on Hu- man Factors in Computing Systems, 1–26
Interaction context often increases sycophancy in LLMs. InProceedings of the 2026 CHI Conference on Hu- man Factors in Computing Systems, 1–26. Kaur, A. 2025. Echoes of Agreement: Argument Driven Sycophancy in Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2025, 22803–22812. Kelley, S. W.; and Riedl, C. 2026. Per...
-
[3]
IEEE. Kim, S.; and Khashabi, D. 2025. Challenging the Evalua- tor: LLM Sycophancy Under User Rebuttal.arXiv preprint arXiv:2509.16533. Kim, T. M.; Luo, L.; Kim, S. E.; Manrai, A. K.; Topol, E.; and Rajpurkar, P. 2026. The Doctor Will Agree With You Now: Sycophancy of Large Language Models in Multi-Turn Medical Conversations. InProceedings of the 1st Works...
-
[4]
Are you sure? challenging llms leads to perfor- mance drops in the flipflop experiment.arXiv preprint arXiv:2311.08596. Li, S.; Ji, T.; Fan, X.; Lu, L.; Yang, L.; Yang, Y .; Xi, Z.; Zheng, R.; Wang, Y .; xh.zhao; Gui, T.; Zhang, Q.; and Huang, X. 2025. Have the VLMs Lost Confidence? A Study of Sycophancy in VLMs. InThe Thirteenth International Conference ...
-
[5]
Wang, K.; Li, J.; Yang, S.; Zhang, Z.; and Wang, D
Sycophancy Is Not One Thing: Causal Separa- tion of Sycophantic Behaviors in LLMs.arXiv preprint arXiv:2509.21305. Wang, K.; Li, J.; Yang, S.; Zhang, Z.; and Wang, D. 2026. When truth is overridden: Uncovering the internal origins of sycophancy in large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, 33566–3357...
-
[6]
EchoBench: Benchmarking Sycophancy in Med- ical Large Vision-Language Models.arXiv preprint arXiv:2509.20146. Zhang, K.; Jia, Q.; Chen, Z.; Sun, W.; Zhu, X.; Li, C.; Zhu, D.; and Zhai, G. 2025. Sycophancy under pressure: Eval- uating and mitigating sycophantic bias via adversarial dia- logues in scientific qa.arXiv preprint arXiv:2508.13743. Zhou, W.; Hen...
-
[7]
The model’s response aligns with user beliefs when they are factually accurate
-
[8]
The model’s response changes from a correct position to an incorrect one following user pushback
-
[9]
The model’s response changes from an incorrect position to a correct one following user pushback
-
[10]
The model’s response reflects the user’s stance when it aligns with sound reasoning
-
[11]
The model’s response reflects the user’s stance even when it conflicts with ethical judgment
-
[12]
The model’s response on interpersonal conflicts shifts to match the user’s stance
-
[13]
The model’s response on moral issues remains consistent regardless of the user’s stance
-
[14]
The model’s response contains unwarranted praise di- rected at the user
-
[15]
The model’s response affirms the user’s feelings as valid regardless of whether doing so is appropriate
-
[16]
The model’s response contains sympathetic language to- ward the user only when the situation warrants it
-
[17]
The model’s response corrects errors that appeared in the user’s input
-
[18]
The model’s response presents information selectively in ways that support the user’s stated opinion
-
[19]
The model’s response presents a balanced range of infor- mation regardless of the user’s stated opinion
-
[20]
The model’s response uses hedging language in ways that favor the user’s expressed opinion leaning
-
[21]
The model’s response evaluates the user’s behavior based on its potential consequences
-
[22]
The model’s response reflects the user’s interpretation of subjective matters without presenting other plausible viewpoints
-
[23]
The model’s response uses language that conveys defer- ence to the user
-
[24]
The model’s expressed confidence level mirrors the user’s expressed certainty regardless of the available evi- dence
-
[25]
The model’s response is of lower complexity for users who appear less educated
-
[26]
The model’s response omits feedback that could nega- tively affect the user’s feelings
-
[27]
The model maintains a consistent emotional tone regard- less of the user’s current state
-
[28]
The model expresses excitement in engaging with the user
-
[29]
The model mirrors the user’s communication style
-
[30]
The model exhibits a generally positive tone not specifi- cally directed at the user. Section 2: Opinions About Sycophancy Rate the extent to which you agree or disagree with the fol- lowing statements. Response scale:1 (Strongly disagree) — 2 — 3 — 4 — 5 — 6 — 7 (Strongly agree)
-
[31]
Sycophancy is a significant problem in current AI sys- tems
-
[32]
Sycophancy is primarily caused by Reinforcement Learning from Human Feedback (RLHF)/preference learning approaches
-
[33]
Sycophancy is a behavior trained into LLMs to optimize user satisfaction
-
[34]
Section 3: Open-Ended Questions (Optional)
Users prefer sycophantic responses. Section 3: Open-Ended Questions (Optional)
-
[35]
For each, please share their full name and email address
Please nominate up to five experts who you believe meet the requirements for this survey. For each, please share their full name and email address
-
[36]
You are also welcome to share further thoughts on AI sycophancy or feedback on this survey
If there are additional behaviors you consider sycophan- tic that were not covered above, please describe them. You are also welcome to share further thoughts on AI sycophancy or feedback on this survey. Section 4: Demographics Education.What is your highest level of education? • Bachelor’s (current or completed) • Professional Master’s (current or comple...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.