A Posterior-Predictive Variance Decomposition for Epistemic and Aleatoric Uncertainty in Wind Power Forecasting
Pith reviewed 2026-05-22 07:41 UTC · model grok-4.3
The pith
Applying the law of total variance separates aleatoric and epistemic uncertainty in wind power neural network forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying the law of total variance to the joint setting of heteroscedastic neural network regression and Bayesian posterior approximation, an explicit decomposition of total uncertainty into aleatoric and epistemic components is derived. The resulting estimators are compatible with standard posterior-approximation methods and with beta-NLL training to regulate the mean-variance learning trade-off.
What carries the argument
Law of total variance decomposition applied to the predictive distribution of a heteroscedastic Bayesian neural network regressor.
If this is right
- Decomposed aleatoric and epistemic components respond in theoretically expected directions to heteroscedastic noise, distributional shift, and training-scale changes.
- Epistemic uncertainty decreases with larger training datasets while aleatoric uncertainty remains stable.
- The estimators integrate directly with existing posterior approximation techniques and beta-NLL training without modification.
- Real-world SCADA validation on wind turbine data supports operational utility through data-property-driven checks.
Where Pith is reading between the lines
- Grid operators could use the aleatoric part to set fixed operating reserves and the epistemic part to decide when to retrain models on new data.
- The same variance decomposition approach could be examined for solar generation or electricity load forecasting.
- The label-free evaluation protocol might serve as a template for validating uncertainty splits in other regression domains.
Load-bearing premise
The three-module evaluation framework of synthetic experiments, SCADA data-property validation, and dataset-size scaling can confirm correct disentanglement of aleatoric and epistemic uncertainty without ground-truth uncertainty labels.
What would settle it
If adding known heteroscedastic noise to synthetic wind data fails to increase the estimated aleatoric component, or if epistemic uncertainty does not decrease as training set size grows, the claimed decomposition would be falsified.
Figures









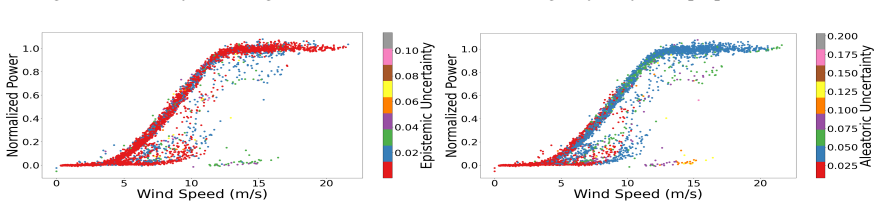


read the original abstract
Accurate wind power forecasting requires reliable uncertainty quantification, yet most existing methods report a single predictive uncertainty that conflates epistemic and aleatoric sources. This paper applies the law of total variance to the joint setting of heteroscedastic neural network regression and Bayesian posterior approximation, deriving an explicit decomposition of total uncertainty (TU) into aleatoric (AU) and epistemic (EU) components. The resulting estimators are compatible with standard posterior-approximation methods and with $\beta$-NLL training to regulate the mean--variance learning trade-off. A wind power--specific evaluation framework is proposed to validate disentanglement without access to ground-truth uncertainty labels, comprising three modules: controlled synthetic experiments to verify responses to heteroscedastic noise and distribution shift; data-property--driven validation on a real-world wind turbine SCADA dataset; and dataset-size scaling experiments to examine the predicted asymptotic behavior of EU. Across synthetic and real-world experiments, the decomposed AU and EU components respond in theoretically consistent directions to noise structure, distributional shift, and training-scale variation, supporting the theoretical consistency and operational utility of the proposed decomposition and evaluation protocol.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives an explicit decomposition of total predictive uncertainty into aleatoric (AU) and epistemic (EU) components for heteroscedastic neural network regression in wind power forecasting by applying the law of total variance to the posterior predictive. The resulting estimators are compatible with standard posterior-approximation methods and with β-NLL training. A three-module evaluation framework is proposed—controlled synthetic experiments, data-property-driven validation on a real-world wind turbine SCADA dataset, and dataset-size scaling experiments—to validate the disentanglement in the absence of ground-truth uncertainty labels. Across experiments, the decomposed AU and EU components respond in theoretically consistent directions to noise structure, distributional shift, and training-scale variation.
Significance. If validated, the decomposition offers a principled, operationally useful separation of uncertainty sources for wind power forecasting, where distinguishing aleatoric variability from model uncertainty can inform better grid management and risk assessment. The explicit derivation from the law of total variance, compatibility with existing training and inference techniques, and domain-specific evaluation protocol are strengths. However, the empirical support rests on directional consistency rather than quantitative recovery, which limits the strength of the conclusions.
major comments (2)
- [Evaluation Framework] The three-module evaluation framework (synthetic experiments, SCADA validation, and scaling) relies on directional consistency of AU/EU responses to noise, shift, and scale. This is load-bearing for the central claim of correct disentanglement, yet the synthetic module does not report numerical recovery error against ground-truth AU/EU values generated under controlled heteroscedastic noise; many alternative decompositions could produce similar monotonic behaviors.
- [Abstract] The abstract claims that experiments support theoretical consistency, but provides no quantitative results, error bars, or details on post-hoc choices in the validation modules. This weakens assessment of whether the reported AU and EU behaviors robustly confirm the decomposition rather than reflecting implementation artifacts.
minor comments (2)
- [Method] Clarify the exact form of the posterior approximation (e.g., which variational or sampling method) and how it interfaces with the variance decomposition in the derivation.
- [Related Work] Add a brief comparison to prior uncertainty decomposition methods in the related-work section to highlight the specific contribution of the posterior-predictive formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline revisions that will strengthen the presentation of our evaluation framework and abstract.
read point-by-point responses
-
Referee: [Evaluation Framework] The three-module evaluation framework (synthetic experiments, SCADA validation, and scaling) relies on directional consistency of AU/EU responses to noise, shift, and scale. This is load-bearing for the central claim of correct disentanglement, yet the synthetic module does not report numerical recovery error against ground-truth AU/EU values generated under controlled heteroscedastic noise; many alternative decompositions could produce similar monotonic behaviors.
Authors: We agree that quantitative recovery metrics would provide stronger evidence. In the synthetic module we generate data from known heteroscedastic processes, which in principle permits direct comparison of estimated AU to the injected noise variance. We will add a new subsection reporting mean absolute percentage error between estimated AU and ground-truth noise variance across noise levels, as well as the correlation between estimated EU and a proxy (e.g., posterior variance on held-out synthetic replicates). This addition will also discuss why exact ground-truth EU is inherently model-dependent even in simulation, thereby distinguishing our decomposition from alternatives that might exhibit similar monotonic trends. revision: yes
-
Referee: [Abstract] The abstract claims that experiments support theoretical consistency, but provides no quantitative results, error bars, or details on post-hoc choices in the validation modules. This weakens assessment of whether the reported AU and EU behaviors robustly confirm the decomposition rather than reflecting implementation artifacts.
Authors: We accept this criticism. The revised abstract will be expanded to include concise quantitative statements (e.g., “AU increased by X% under doubled noise variance while EU remained stable; EU decreased by Y% when training data were scaled from N to 4N”) together with a note that all reported trends were obtained from five independent random seeds with standard-error bars. We will also state that the three validation modules were pre-specified from theoretical predictions rather than chosen after observing results. revision: yes
Circularity Check
No significant circularity; derivation applies standard law of total variance
full rationale
The paper's central derivation applies the law of total variance to the posterior predictive under heteroscedastic regression and Bayesian approximation, yielding an explicit TU = AU + EU split. This identity is an external statistical fact independent of the paper's fitted parameters, network architecture, or β-NLL training. The resulting estimators are stated to be compatible with existing posterior methods rather than being redefined in terms of the outputs. The three-module evaluation protocol (synthetic response tests, SCADA property checks, and scaling) is an empirical validation step that does not feed back into the decomposition equations themselves. No self-citation load-bearing steps, uniqueness theorems, or fitted-input-renamed-as-prediction patterns appear in the derivation chain. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Law of total variance decomposes posterior predictive variance into aleatoric and epistemic components
Reference graph
Works this paper leans on
-
[1]
Y . Chen, S. Yu, S. Islam, C. P. Lim, and S. Muyeen, “Decomposition- based wind power forecasting models and their boundary issue: An in-depth review and comprehensive discussion on potential solutions,” Energy Reports, vol. 8, pp. 8805–8820, 2022
work page 2022
-
[2]
Multi-objective estimation of optimal prediction intervals for wind power forecasting,
Y . Chen, S. S. Yu, C. P. Lim, and P. Shi, “Multi-objective estimation of optimal prediction intervals for wind power forecasting,”IEEE Transactions on Sustainable Energy, vol. 15, no. 2, pp. 974–985, 2024
work page 2024
-
[3]
J. Yan, C. M ¨ohrlen, T. G ¨oc ¸men, M. Kelly, A. Wessel, and G. Giebel, “Uncovering wind power forecasting uncertainty sources and their prop- agation through the whole modelling chain,”Renewable and Sustainable Energy Reviews, vol. 165, p. 112519, 2022
work page 2022
-
[4]
Offshore wind power system economic evaluation framework under aleatory and epistemic uncertainty,
A. C. Caputo, A. Federici, P. M. Pelagagge, and P. Salini, “Offshore wind power system economic evaluation framework under aleatory and epistemic uncertainty,”Applied Energy, vol. 350, p. 121585, 2023
work page 2023
-
[5]
Ultra-short-term wind power forecasting based on deep bayesian model with uncertainty,
L. Liu, J. Liu, Y . Ye, H. Liu, K. Chen, D. Li, X. Dong, and M. Sun, “Ultra-short-term wind power forecasting based on deep bayesian model with uncertainty,”Renewable Energy, vol. 205, pp. 598–607, 2023
work page 2023
-
[6]
J. Ding, K. Xie, B. Hu, C. Shao, T. Niu, C. Li, and C. Pan, “Mixed aleatory-epistemic uncertainty modeling of wind power forecast errors in operation reliability evaluation of power systems,”Journal of Modern Power Systems and Clean Energy, vol. 10, no. 5, pp. 1174–1183, 2022
work page 2022
-
[7]
Deep deterministic uncertainty: A new simple baseline,
J. Mukhoti, A. Kirsch, J. van Amersfoort, P. H. Torr, and Y . Gal, “Deep deterministic uncertainty: A new simple baseline,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 384–24 394
work page 2023
-
[8]
Prioritized training on points that are learnable, worth learning, and not yet learnt,
S. Mindermann, J. M. Brauner, M. T. Razzak, M. Sharma, A. Kirsch, W. Xu, B. H ¨oltgen, A. N. Gomez, A. Morisot, S. Farquharet al., “Prioritized training on points that are learnable, worth learning, and not yet learnt,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 15 630–15 649
work page 2022
-
[9]
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods,
E. H ¨ullermeier and W. Waegeman, “Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods,”Machine learning, vol. 110, no. 3, pp. 457–506, 2021
work page 2021
-
[10]
What uncertainties do we need in bayesian deep learning for computer vision?
A. Kendall and Y . Gal, “What uncertainties do we need in bayesian deep learning for computer vision?”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[11]
On the pitfalls of het- eroscedastic uncertainty estimation with probabilistic neural networks,
M. Seitzer, A. Tavakoli, D. Antic, and G. Martius, “On the pitfalls of het- eroscedastic uncertainty estimation with probabilistic neural networks,” inTenth International Conference on Learning Representations (ICLR 2022), 2022
work page 2022
-
[12]
Simple and scalable predictive uncertainty estimation using deep ensembles,
B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[13]
Benchmarking uncertainty dis- entanglement: Specialized uncertainties for specialized tasks,
B. Mucs ´anyi, M. Kirchhof, and S. J. Oh, “Benchmarking uncertainty dis- entanglement: Specialized uncertainties for specialized tasks,”Advances in neural information processing systems, vol. 37, pp. 50 972–51 038, 2024
work page 2024
-
[14]
A deeper look into aleatoric and epistemic uncertainty disentanglement,
M. Valdenegro-Toro and D. S. Mori, “A deeper look into aleatoric and epistemic uncertainty disentanglement,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2022, pp. 1508–1516
work page 2022
-
[15]
Aleatory or epistemic? does it matter?
A. Der Kiureghian and O. Ditlevsen, “Aleatory or epistemic? does it matter?”Structural safety, vol. 31, no. 2, pp. 105–112, 2009
work page 2009
-
[16]
Z. Qian, Y . Pei, H. Zareipour, and N. Chen, “A review and discussion of decomposition-based hybrid models for wind energy forecasting applications,”Applied Energy, vol. 235, pp. 939–953, 2019
work page 2019
-
[17]
Interplay between bayesian neural networks and deep learning: A survey,
Y . Chen, S. Y . Samson, Z. Li, J. K. Eshraghian, and C. P. Lim, “Interplay between bayesian neural networks and deep learning: A survey,”Knowledge-Based Systems, vol. 330, p. 114438, 2025
work page 2025
-
[18]
Heteroscedastic gaussian process regression,
Q. V . Le, A. J. Smola, and S. Canu, “Heteroscedastic gaussian process regression,” inProceedings of the 22nd international conference on Machine learning, 2005, pp. 489–496
work page 2005
-
[19]
K. L. Chung,A course in probability theory. Elsevier, 2000
work page 2000
-
[20]
S. Ghosal and A. W. Van der Vaart,Fundamentals of nonparametric Bayesian inference. Cambridge University Press, 2017, vol. 44
work page 2017
-
[21]
Rudin,Principles of mathematical analysis
W. Rudin,Principles of mathematical analysis. Academic Press, 2021
work page 2021
-
[22]
Deep ensembles: A loss landscape perspective.arXiv preprint arXiv:1912.02757,
S. Fort, H. Hu, and B. Lakshminarayanan, “Deep ensembles: A loss landscape perspective,”arXiv preprint arXiv:1912.02757, 2019
-
[23]
L. Wimmer, Y . Sale, P. Hofman, B. Bischl, and E. H ¨ullermeier, “Quan- tifying aleatoric and epistemic uncertainty in machine learning: Are conditional entropy and mutual information appropriate measures?” in Uncertainty in Artificial Intelligence. PMLR, 2023, pp. 2282–2292
work page 2023
-
[24]
Measuring uncertainty disentanglement error in classification,
I. P. de Jong, A. I. Sburlea, and M. Valdenegro-Toro, “Measuring uncertainty disentanglement error in classification,”arXiv preprint arXiv:2408.12175, 2024
-
[25]
T. Rogers, P. Gardner, N. Dervilis, K. Worden, A. Maguire, E. Pap- atheou, and E. Cross, “Probabilistic modelling of wind turbine power curves with application of heteroscedastic gaussian process regression,” Renewable Energy, vol. 148, pp. 1124–1136, 2020
work page 2020
-
[26]
Dropconnect is effective in modeling uncertainty of bayesian deep networks,
A. Mobiny, P. Yuan, S. K. Moulik, N. Garg, C. C. Wu, and H. Van Nguyen, “Dropconnect is effective in modeling uncertainty of bayesian deep networks,”Scientific reports, vol. 11, no. 1, p. 5458, 2021
work page 2021
-
[27]
B. Erisen. (2018) Wind turbine scada dataset. [Online]. Available: https: //www.kaggle.com/datasets/berkerisen/wind-turbine-scada-dataset/data
work page 2018
-
[28]
Probabilistic neural network to quantify uncertainty of wind power estimation,
F. Karami, N. Kehtarnavaz, and M. Rotea, “Probabilistic neural network to quantify uncertainty of wind power estimation,” in2022 IEEE 15th Dallas Circuit And System Conference (DCAS). IEEE, 2022, pp. 1–7
work page 2022
-
[29]
Using bias-corrected reanalysis to simulate current and future wind power output,
I. Staffell and S. Pfenninger, “Using bias-corrected reanalysis to simulate current and future wind power output,”Energy, vol. 114, pp. 1224–1239, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.