Training-Free Fine-Grained Semantic Segmentations in Low Data Regimes: A FungiTastic Baseline
Pith reviewed 2026-05-22 06:25 UTC · model grok-4.3
The pith
A training-free two-stage method segments fine-grained fungi by generating class-agnostic masks first then assigning labels via prototype matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
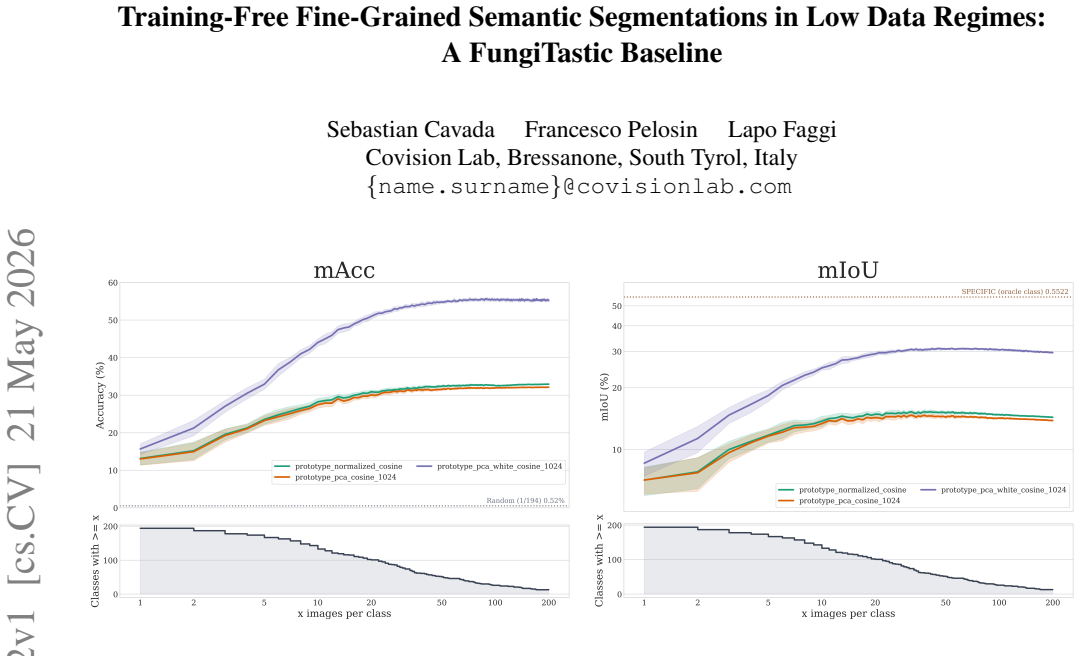
The central claim is that a training-free two-stage framework decouples segmentation from classification on the FungiTastic dataset. Macro-taxonomic prompts first produce class-agnostic mushroom masks, after which fine-grained labels are assigned through prototype matching in the embedding space following a simple transformation of the feature space. This is shown to be more scalable than class-specific prompting while maintaining low segmentation cost, with performance measured across low-data regimes from single examples to a few hundred shots per class.
What carries the argument
The two-stage decoupling of segmentation and classification, where macro-taxonomic prompts create class-agnostic masks and prototype matching after feature-space transformation assigns fine-grained labels.
If this is right
- New fine-grained classes can be added without retraining or expanding the set of segmentation prompts.
- Segmentation cost remains constant as the number of classes grows because masks are produced independently of specific labels.
- The method supplies a consistent reference point for performance across data regimes from one example to several hundred.
- The feature-space transformation step raises the accuracy of prototype-based label assignment relative to the untransformed case.
Where Pith is reading between the lines
- The same separation of mask generation from label assignment could reduce labeled-data needs in other long-tailed fine-grained domains such as plant or insect identification from field images.
- If the transformation step generalizes across embedding models, it might allow quicker adaptation of existing vision representations for segmentation tasks without per-task retraining.
- Measuring how often macro prompts fail on closely related species pairs would indicate where prompt design or mask refinement needs further attention.
Load-bearing premise
Broad macro-taxonomic prompts will produce accurate enough class-agnostic masks to isolate instances even among visually similar fine-grained species, and a basic unspecified transformation of the embedding space will make prototype matching reliable without task-specific tuning.
What would settle it
A side-by-side evaluation on image pairs of visually close mushroom species showing that the generated masks frequently merge or miss boundaries, causing the subsequent prototype matching to assign wrong labels at rates far above the reported baseline.
Figures

read the original abstract
Fine-grained semantic segmentation requires both precise localization and discrimination between visually similar classes. In FungiTastic, this problem is further complicated by a long-tailed distribution and strong variation in image acquisition conditions. We propose a training-free two-stage framework that decouples segmentation from classification. SAM3 first produces class-agnostic mushroom masks using macro-taxonomic prompts, and DINOv3 then assigns fine-grained labels through prototype matching in the embedding space. To improve this stage, we apply a simple transformation of the DINOv3 feature space that improves prototype-based classification. Compared with class-specific prompting, our approach is more scalable and keeps the segmentation cost low. We report results from one-shot to few-hundred-shot regimes, providing, to the best of our knowledge, the first baseline for fine-grained semantic segmentation in low-data settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-free two-stage framework for fine-grained semantic segmentation of fungi images under long-tailed distributions and variable acquisition conditions. SAM3 generates class-agnostic instance masks from macro-taxonomic (genus/family) prompts; DINOv3 then assigns fine-grained species labels via prototype matching after an unspecified transformation of the embedding space. Results are reported across one-shot to few-hundred-shot regimes and positioned as a scalable baseline relative to class-specific prompting.
Significance. If the performance claims can be substantiated with quantitative evidence, the work would supply a practical, training-free baseline for fine-grained segmentation in low-data, high-similarity domains. The explicit decoupling of mask generation from label assignment and the emphasis on macro-level prompting are conceptually attractive for scalability, but the absence of supporting metrics leaves the practical utility unverified.
major comments (3)
- [Abstract] Abstract: the central claim that macro-taxonomic prompts to SAM3 yield masks sufficiently accurate for subsequent fine-grained prototype matching is load-bearing yet unsupported by any mask-quality metrics (e.g., boundary F-score, per-genus IoU, or over-/under-segmentation rates). Without these, it is impossible to determine whether reported low-shot gains arise from the embedding transformation or from mask errors that happen to be correctable by DINOv3.
- [Abstract] Abstract: the 'simple transformation' of the DINOv3 feature space is described only qualitatively and without an ablation, quantitative improvement figures, or pseudocode. Because this step is presented as the key enabler of reliable prototype matching, its omission prevents assessment of whether the method is genuinely training-free or merely defers adaptation to an ad-hoc preprocessing choice.
- [Results] Results (one-shot to few-hundred-shot regimes): no error bars, per-class breakdowns, or comparison tables against class-specific prompting baselines are supplied. The absence of these data makes the scalability claim and the cross-regime performance statements unverifiable.
minor comments (1)
- [Abstract] The manuscript would benefit from an explicit statement of the exact prompting template used with SAM3 and the precise form of the DINOv3 transformation (e.g., centering, whitening, or learned affine map).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that macro-taxonomic prompts to SAM3 yield masks sufficiently accurate for subsequent fine-grained prototype matching is load-bearing yet unsupported by any mask-quality metrics (e.g., boundary F-score, per-genus IoU, or over-/under-segmentation rates). Without these, it is impossible to determine whether reported low-shot gains arise from the embedding transformation or from mask errors that happen to be correctable by DINOv3.
Authors: We agree that mask-quality metrics are necessary to isolate the contributions of each stage. In the revised manuscript we will report boundary F-score, per-genus IoU, and over-/under-segmentation statistics for the SAM3 masks produced with macro-taxonomic prompts. These metrics will be computed on a held-out validation subset and presented alongside the existing segmentation results. revision: yes
-
Referee: [Abstract] Abstract: the 'simple transformation' of the DINOv3 feature space is described only qualitatively and without an ablation, quantitative improvement figures, or pseudocode. Because this step is presented as the key enabler of reliable prototype matching, its omission prevents assessment of whether the method is genuinely training-free or merely defers adaptation to an ad-hoc preprocessing choice.
Authors: We acknowledge the description is currently qualitative. The transformation is a fixed, deterministic preprocessing step (no parameters are learned from the target fungi data) that improves prototype separability while preserving the training-free character of the pipeline. In revision we will supply the exact formulation, pseudocode, an ablation table quantifying the accuracy gain, and explicit confirmation that the step requires no training or fine-tuning on the evaluation regimes. revision: yes
-
Referee: [Results] Results (one-shot to few-hundred-shot regimes): no error bars, per-class breakdowns, or comparison tables against class-specific prompting baselines are supplied. The absence of these data makes the scalability claim and the cross-regime performance statements unverifiable.
Authors: We agree that the reported results would be more verifiable with additional statistical detail. The revised results section will include error bars (standard deviation over multiple random seeds), per-class performance tables, and a side-by-side comparison against class-specific prompting baselines across the one-shot to few-hundred-shot regimes to support the scalability claims. revision: yes
Circularity Check
No circularity: procedural combination of pre-trained models
full rationale
The paper presents a training-free two-stage pipeline that applies existing models (SAM3 with macro-taxonomic prompts for class-agnostic masks, followed by DINOv3 prototype matching on a simple feature-space transformation) without any equations, derivations, parameter fitting, or self-referential reductions. The central claims rest on the empirical behavior of off-the-shelf pre-trained components rather than on any quantity defined in terms of itself or justified solely by prior self-citation. No load-bearing step reduces by construction to its inputs, satisfying the self-contained criterion against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained SAM3 responds reliably to macro-taxonomic prompts on the FungiTastic dataset to produce accurate class-agnostic masks.
- domain assumption DINOv3 embeddings, after a simple transformation, support accurate prototype matching for fine-grained discrimination under long-tailed distributions.
Reference graph
Works this paper leans on
-
[1]
Fine-grained few- shot classification with part matching
Samuel Black and Richard Souvenir. Fine-grained few- shot classification with part matching. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition Work- shops, CVPR Workshops 2025, Nashville, TN, USA, June 11- 15, 2025, pages 2057–2067. Computer Vision Foundation / IEEE, 2025. 2
work page 2025
-
[2]
Overview of birdclef+ 2025: Multi-taxonomic sound identification in the middle magdalena, colombia
Juan Sebasti ´an Ca ˜nas, Stefan Kahl, Tom Denton, Maria Paula Toro-G ´omez, Susana Rodr ´ıguez-Buritica, Jose Luis Benavides-Lopez, Juan Sebastian Ulloa, Paula Caycedo-Rosales, Holger Klinck, Herv ´e Go ¨eau, Willem- Pier Vellinga, Robert Planqu ´e, and Alexis Joly. Overview of birdclef+ 2025: Multi-taxonomic sound identification in the middle magdalena,...
work page 2025
-
[3]
Sam 3: Segment anything with concepts, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R¨adle, Triantafyllos Afouras, Effrosyni Mavroudi, Kather- ine Xu, Tsung-Han Wu, Yu Zhou, Lil...
work page 2025
-
[4]
Jack N. Etheredge. Few-shot fungi classification with proto- typical networks using multiple pretrained embedding mod- els. InWorking Notes of the Conference and Labs of the Evaluation Forum, CLEF 2025, Madrid, Spain, 9-12 September 2025, pages 3001–3010. CEUR-WS.org, 2025. 2
work page 2025
-
[5]
Yuxin Jiang, Yunkang Cao, and Weiming Shen. Prototypi- cal learning guided context-aware segmentation network for few-shot anomaly detection.IEEE Trans. Neural Networks Learn. Syst., 36(7):12016–12026, 2025. 2
work page 2025
-
[6]
Whitening con- sistently improves self-supervised learning
Andr ´as Kalapos and B ´alint Gyires-T ´oth. Whitening con- sistently improves self-supervised learning. In2024 Inter- national Conference on Machine Learning and Applications (ICMLA), pages 448–453. IEEE, 2024. 2
work page 2024
-
[7]
Optimal whitening and decorrelation.The American Statistician, 72 (4):309–314, 2018
Agnan Kessy, Alex Lewin, and Korbinian Strimmer. Optimal whitening and decorrelation.The American Statistician, 72 (4):309–314, 2018. 2
work page 2018
-
[8]
Lianping Lu, Heng Yang, Shuo Li, Fang Liu, Puhua Chen, and Wenping Ma. Few-shot classification of fungi species using contrastive representation learning and multimodal fu- sion. InWorking Notes of the Conference and Labs of the Evaluation Forum, CLEF 2025, Madrid, Spain, 9-12 September 2025, pages 3094–3101. CEUR-WS.org, 2025. 2
work page 2025
-
[9]
Overview of plantclef 2025: Multi- species plant identification in vegetation quadrat images
Giulio Martellucci, Herv ´e Go ¨eau, Pierre Bonnet, Fabrice Vinatier, and Alexis Joly. Overview of plantclef 2025: Multi- species plant identification in vegetation quadrat images. In Working Notes of the Conference and Labs of the Evaluation Forum, CLEF 2025, Madrid, Spain, 9-12 September 2025, pages 2942–2954. CEUR-WS.org, 2025. 1
work page 2025
-
[10]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rab- bat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e J´egou, Julien Mairal, P...
work page 2024
-
[11]
Jeppe- sen, Jacob Heilmann-Clausen, Thomas Læssøe, and Tobias Frøslev
Luk ´aˇs Picek, Milan ˇSulc, Ji ˇr´ı Matas, Thomas S. Jeppe- sen, Jacob Heilmann-Clausen, Thomas Læssøe, and Tobias Frøslev. Danish fungi 2020 - not just another image recogni- tion dataset. InProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, pages 1525–1535,
work page 2020
-
[12]
Fungitastic: A multi-modal dataset and benchmark for image categorization
Lukas Picek, Klara Janouskova, V ojtech Cermak, and Jiri Matas. Fungitastic: A multi-modal dataset and benchmark for image categorization. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR) Work- shops, pages 2046–2056, 2025. 2
work page 2046
-
[13]
Harley, and Katerina Fragkiadaki
Mihir Prabhudesai, Shamit Lal, Darshan Patil, Hsiao-Yu Tung, Adam W. Harley, and Katerina Fragkiadaki. Disentan- gling 3d prototypical networks for few-shot concept learn- ing. In9th International Conference on Learning Represen- tations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. 2
work page 2021
-
[14]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, ...
work page 2021
-
[15]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie,...
work page 2025
-
[16]
Jake Snell, Kevin Swersky, and Richard S. Zemel. Prototyp- ical networks for few-shot learning. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, pages 4077–4087, 2017. 2
work page 2017
-
[17]
Awesome fine-grained few-shot learn- ing.https : / / github
Hao Tang. Awesome fine-grained few-shot learn- ing.https : / / github . com / CSer - Tang - hao / Awesome- Fine- Grained- Few- Shot- Learning,
-
[18]
GitHub repository. 2
-
[19]
Toso, Davit Shadunts, Yunyang Lu, Nihal Sharma, Donglin Zhan, Nam H
Leonardo F. Toso, Davit Shadunts, Yunyang Lu, Nihal Sharma, Donglin Zhan, Nam H. Nguyen, and James An- derson. Learning invariant visual representations for plan- ning with joint-embedding predictive world models.CoRR, abs/2602.18639, 2026. 2
-
[20]
Michael Tschannen, Alexey A. Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier J. H ´enaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense fea...
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Xi Weng, Lei Huang, Lei Zhao, Rao Anwer, Salman H Khan, and Fahad Shahbaz Khan. An investigation into whitening loss for self-supervised learning.Advances in Neural Infor- mation Processing Systems, 35:29748–29760, 2022. 2
work page 2022
-
[22]
Mushroom for improvement: Prototypical few-shot learning with multi- modal fungal features
Tuan-Anh Yang and Minh-Quang Nguyen. Mushroom for improvement: Prototypical few-shot learning with multi- modal fungal features. InWorking Notes of the Conference and Labs of the Evaluation Forum, CLEF 2025, Madrid, Spain, 9-12 September 2025, pages 3287–3295. CEUR- WS.org, 2025. 2
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.