TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
Pith reviewed 2026-05-22 05:49 UTC · model grok-4.3
The pith
A benchmark built from 80,870 real terminal recordings shows frontier agents reach only 62.5 percent success on authentic developer workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
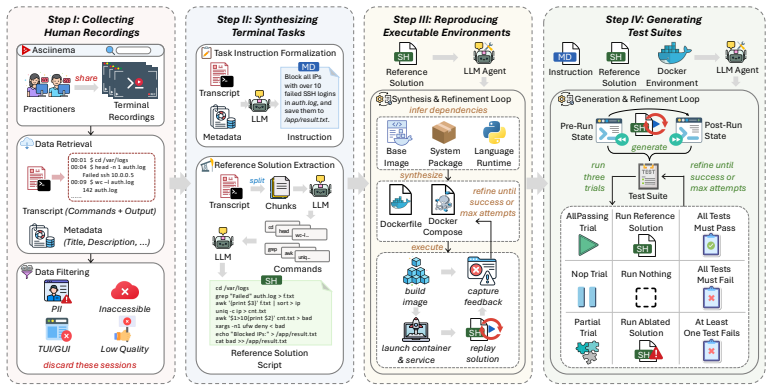
TerminalWorld is generated by an automated reverse-engineering engine that processes 80,870 terminal recordings into 1,530 validated tasks covering 1,280 unique commands and workflows up to 50 steps long. On a curated Verified set of 200 tasks, current systems achieve at most a 62.5 percent pass rate. The resulting scores correlate only weakly (Pearson r = 0.20) with performance on prior expert-curated benchmarks such as Terminal-Bench, indicating that TerminalWorld measures distinct real-world terminal capabilities.
What carries the argument
The automated reverse-engineering engine that converts raw terminal recordings into high-fidelity, validated tasks spanning everyday to multi-step developer workflows.
If this is right
- Agents that succeed on expert-curated terminal benchmarks may still fail on tasks drawn directly from real usage.
- The benchmark can be refreshed automatically whenever new terminal recordings become available.
- Long workflows exceeding 50 steps remain especially difficult for current agent designs.
- Evaluation of terminal agents should incorporate metrics that track fidelity to actual command sequences rather than isolated subtasks.
Where Pith is reading between the lines
- Progress measured on static expert benchmarks may overestimate readiness for live terminal use.
- The same engine could be applied to other environments such as shell scripting in containers or remote servers.
- Teams could adopt the verified subset as a lightweight test for agent deployment in production tooling.
Load-bearing premise
The reverse-engineering process yields tasks that faithfully reflect genuine developer practices without introducing systematic biases in selection or validation.
What would settle it
Human developers performing the same tasks achieve substantially lower success rates than the reported agent ceiling, or agents that score high on TerminalWorld fail at comparable rates when placed in live developer environments.
Figures






read the original abstract
We introduce TerminalWorld, a scalable data engine that automatically reverse-engineers high-fidelity evaluation tasks from "in-the-wild" terminal recordings. Processing 80,870 terminal recordings, the engine yields a full benchmark of 1,530 validated tasks, spanning 18 real-world categories, ranging from short everyday operations to workflows exceeding 50 steps, and covering 1,280 unique commands. From these, we curate a Verified subset of 200 representative, manually reviewed tasks. Comprehensive benchmarking on TerminalWorld-Verified across eight frontier models and six agents reveals that current systems still struggle with authentic terminal workflows, achieving a maximum pass rate of only 62.5%. Moreover, TerminalWorld captures real-world terminal capabilities distinct from existing expert-curated benchmarks (e.g., Terminal-Bench), with only a weak correlation to their scores (Pearson r=0.20). The automated engine makes TerminalWorld authentic and scalable by construction, enabling it to evaluate agents in real-world terminal environments as developer practices evolve. Data and code are available at https://github.com/EuniAI/TerminalWorld.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TerminalWorld, a scalable benchmark generated by automatically reverse-engineering 1,530 validated tasks (plus a 200-task manually reviewed Verified subset) from 80,870 in-the-wild terminal recordings. The tasks span 18 categories and 1,280 unique commands. Benchmarking eight frontier models and six agents on the Verified subset yields a maximum pass rate of 62.5%. Scores on TerminalWorld correlate only weakly (Pearson r=0.20) with those on Terminal-Bench, which the authors interpret as evidence that TerminalWorld captures distinct real-world terminal capabilities. The automated engine is presented as enabling ongoing, authentic evaluation as developer practices evolve.
Significance. If the reverse-engineered tasks faithfully reflect real developer workflows, TerminalWorld would offer a valuable, scalable alternative to expert-curated benchmarks for evaluating terminal agents. The open release of data and code at the provided GitHub repository is a clear strength that supports reproducibility and community extensions. The empirical demonstration of current limitations (62.5% ceiling) and the low correlation with existing benchmarks could help guide future agent development toward more authentic terminal workflows.
major comments (2)
- [§3] §3 (Reverse-Engineering Engine): The central claim that TerminalWorld is 'authentic and scalable by construction' and captures capabilities 'distinct from existing expert-curated benchmarks' rests on the assumption that the automated extraction from 80,870 recordings preserves developer intent, error-recovery steps, and session context. The manuscript provides only a high-level description of the engine and reports manual review of a 200-task subset; no quantitative fidelity metrics (e.g., inter-annotator agreement on intent preservation or comparison of task distributions before/after filtering) are given for the full 1,530 tasks. This is load-bearing for the distinctness interpretation of r=0.20.
- [Results] Results section (correlation analysis): The reported Pearson r=0.20 between TerminalWorld and Terminal-Bench is used to argue that the benchmark measures new capability dimensions. However, the manuscript does not specify which exact model/agent scores were used to compute the correlation, whether the correlation is computed on the full set or Verified subset, or whether confidence intervals or p-values accompany the coefficient. Without these details the strength of the 'distinct' claim cannot be fully assessed.
minor comments (2)
- [Abstract / Results] The abstract states 'eight frontier models and six agents' but the results tables and text do not clearly tabulate per-model and per-agent pass rates with error bars or sample sizes, making it difficult to interpret the 62.5% maximum.
- [§4] The description of task categories and length distribution (short operations to >50-step workflows) would benefit from a supplementary table or figure showing the breakdown by category and step count for both the full and Verified sets.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. We provide detailed responses to the major comments below, indicating where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: §3 (Reverse-Engineering Engine): The central claim that TerminalWorld is 'authentic and scalable by construction' and captures capabilities 'distinct from existing expert-curated benchmarks' rests on the assumption that the automated extraction from 80,870 recordings preserves developer intent, error-recovery steps, and session context. The manuscript provides only a high-level description of the engine and reports manual review of a 200-task subset; no quantitative fidelity metrics (e.g., inter-annotator agreement on intent preservation or comparison of task distributions before/after filtering) are given for the full 1,530 tasks. This is load-bearing for the distinctness interpretation of r=0.20.
Authors: We acknowledge the importance of demonstrating fidelity for the full set of tasks. The reverse-engineering engine incorporates several automated checks for task validity, including verification that commands execute successfully and that the task description accurately reflects the recorded actions. For the Verified subset, manual review confirmed high fidelity in intent preservation. We did not perform inter-annotator agreement as the review was conducted by domain experts following a standardized protocol. In the revised version, we will expand the description of the engine with more specifics on the validation steps and provide a comparison of command distributions and task lengths before and after filtering to support the scalability and authenticity claims. revision: partial
-
Referee: Results section (correlation analysis): The reported Pearson r=0.20 between TerminalWorld and Terminal-Bench is used to argue that the benchmark measures new capability dimensions. However, the manuscript does not specify which exact model/agent scores were used to compute the correlation, whether the correlation is computed on the full set or Verified subset, or whether confidence intervals or p-values accompany the coefficient. Without these details the strength of the 'distinct' claim cannot be fully assessed.
Authors: The Pearson correlation of 0.20 was calculated using the performance scores of the eight frontier models and six agents evaluated on the TerminalWorld-Verified subset, compared against their reported scores on Terminal-Bench. We will revise the Results section to explicitly detail the models and agents included in this analysis, confirm that it uses the Verified subset, and include the p-value along with 95% confidence intervals for the correlation coefficient. This will allow readers to better evaluate the evidence for distinct capabilities. revision: yes
Circularity Check
No circularity: empirical benchmark construction and measurements are self-contained
full rationale
The paper introduces TerminalWorld via an automated reverse-engineering engine applied to 80,870 terminal recordings, yielding 1,530 tasks and a 200-task Verified subset. Central results are direct empirical measurements: maximum agent pass rate of 62.5% on the Verified set and Pearson r=0.20 correlation with Terminal-Bench. These are experimental outcomes on newly collected data, not derivations, fitted parameters renamed as predictions, or results forced by self-citation chains. The phrase 'authentic and scalable by construction' describes the methodological pipeline for data collection and task extraction rather than a self-referential loop where an output is defined in terms of itself. No equations or uniqueness theorems are invoked that reduce the claims to prior inputs. The work is self-contained against external benchmarks and does not rely on load-bearing self-citations for its core claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Terminal recordings from real users contain representative developer workflows that can be reverse-engineered into evaluation tasks without major distortion.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce TERMINALWORLD, a scalable data engine that automatically reverse-engineers high-fidelity evaluation tasks from in-the-wild terminal recordings.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Syst...
work page 2024
-
[2]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F
URL http://papers.nips.cc/paper_files/paper/2024/hash/ 5a7c947568c1b1328ccc5230172e1e7c-Abstract-Conference.html. Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyu...
work page 2024
-
[3]
Accessed: 2026-05-01. OpenAI. Codex cli.https://developers.openai.com/codex/cli,
work page 2026
-
[4]
Accessed: 2026-05-01. Google. Build, debug & deploy with ai | gemini cli. https://geminicli.com/,
work page 2026
-
[5]
Accessed: 2026-05-01. Mike A Merrill, Alexander Glenn Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangy...
work page 2026
-
[6]
URLhttps://openreview.net/forum?id=a7Qa4CcHak. Yukang Feng, Jianwen Sun, Zelai Yang, Jiaxin Ai, Chuanhao Li, Zizhen Li, Fanrui Zhang, Kang He, Rui Ma, Jifan Lin, Jie Sun, Yang Xiao, Sizhuo Zhou, Wenxiao Wu, Yiming Liu, Pengfei Liu, Yu Qiao, Shenglin Zhang, and Kaipeng Zhang. Longcli-bench: A preliminary benchmark and study for long-horizon agentic program...
-
[9]
URLhttps://doi.org/10.48550/arXiv.2602.10999
doi: 10.48550/ ARXIV .2602.10999. URLhttps://doi.org/10.48550/arXiv.2602.10999. Kanishk Gandhi, Shivam Garg, Noah D Goodman, and Dimitris Papailiopoulos. Endless terminals: Scaling rl environments for terminal agents.arXiv preprint arXiv:2601.16443,
-
[10]
On data engineering for scaling llm terminal capabilities.arXiv preprint arXiv:2602.21193,
Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and Wei Ping. On data engineering for scaling llm terminal capabilities.arXiv preprint arXiv:2602.21193,
-
[11]
Siwei Wu, Yizhi Li, Yuyang Song, Wei Zhang, Yang Wang, Riza Batista-Navarro, Xian Yang, Mingjie Tang, Bryan Dai, Jian Yang, and Chenghua Lin. Large-scale terminal agentic trajectory generation from dockerized environments.CoRR, abs/2602.01244,
-
[12]
doi: 10.48550/ARXIV .2602.01244. URL https://doi.org/ 10.48550/arXiv.2602.01244. Anthropic. Introducing claude sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6 , 2026a. Accessed: 2026-05-01. 11 Anthropic. Introducing claude opus 4.7. https://www.anthropic.com/news/claude-opus-4-7 , 2026b. Accessed: 2026-05-01. OpenAI. Introducing gpt -5.5. htt...
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[13]
Accessed: 2026-05-01. Google. Gemini 3.1 pro: Best for complex tasks and bringing creative concepts to life. https://deepmind. google/models/gemini/pro/,
work page 2026
-
[14]
Xi Victoria Lin, Chenglong Wang, Luke Zettlemoyer, and Michael D
Accessed: 2026-05-01. Xi Victoria Lin, Chenglong Wang, Luke Zettlemoyer, and Michael D. Ernst. NL2Bash: A corpus and semantic parser for natural language interface to the linux operating system. In Nicoletta Calzolari, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Koiti Hasida, Hitoshi Isahara, Bente Maegaard, Joseph Mariani, Hélène Maz...
work page 2026
-
[15]
URL https: //aclanthology.org/L18-1491/
European Language Resources Association (ELRA). URL https: //aclanthology.org/L18-1491/. John Yang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Yao. Intercode: Standardizing and bench- marking interactive coding with execution feedback. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Ne...
work page 2023
-
[16]
URL http://papers.nips.cc/paper_files/paper/2023/hash/ 4b175d846fb008d540d233c188379ff9-Abstract-Datasets_and_Benchmarks.html. Earl T. Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. The oracle problem in software testing: A survey.IEEE Transactions on Software Engineering, 41(5):507–525,
work page 2023
-
[17]
doi: 10.1109/TSE. 2014.2372785. DeepSeek. Deepseek v4 preview release. https://api-docs.deepseek.com/news/news260424,
work page doi:10.1109/tse 2014
-
[18]
Accessed: 2026-05-01. Alibaba. Qwen3.6-max-preview: Smarter, sharper, still evolving. https://qwen.ai/blog?id=qwen3. 6-max-preview,
work page 2026
-
[19]
Accessed: 2026-05-01. Moonshot AI. Kimi k2.6: From code to creation, from one to many. https://www.kimi.com/ai-models/ kimi-k2-6,
work page 2026
-
[20]
Accessed: 2026-05-01. Z.ai. Glm-5.1: Towards long-horizon tasks.https://z.ai/blog/glm-5.1,
work page 2026
-
[21]
Accessed: 2026-05-01. MiniMax. Minimax m2.7: Early echoes of self-evolution. https://www.minimax.io/news/ minimax-m27-en,
work page 2026
-
[22]
Accessed: 2026-05-01. 12 A Broader Impact and Ethical Considerations In developing the TERMINALWORLDbenchmark, we adhere strictly to ethical data practices and copyright compliance, specifically addressing the challenges inherent in sourcing in-the-wild, user- generated terminal recordings. Data Sourcing and Consent.TERMINALWORLDsources data from asciinem...
work page 2026
-
[23]
1.6 (1.6 / 1.3) 128.80 1.33 0.75 / 0.73 ▷ Container startup timeouts.A small number of tasks use resource-intensive Docker images that exceed the harness startup timeout, preventing the agent from entering the environment. These two sources account for all errors observed in this experiment, with error rates ranging from 2.5% to 5.5% across models. We rep...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.