SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing
Pith reviewed 2026-05-22 01:46 UTC · model grok-4.3
The pith
SCALE achieves more precise federated unlearning by analyzing historical contributions to select sensitive layers and applying freshness-aware sparsification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a dual-level unlearning process, built on historical contribution-based layer sensitivity analysis to locate affected layers followed by adaptive sparsification at the weight sub-group level with information freshness optimization, delivers higher-precision client data removal, maintains convergence, and yields measurably better forgetting than existing approaches in mobile edge computing.
What carries the argument
Dual-level unlearning mechanism that first runs historical contribution-based layer sensitivity analysis to identify target-influenced layers, then performs adaptive sparsification at the weight sub-group level to trade off information freshness against forgetting effectiveness.
Load-bearing premise
The assumption that a historical contribution-based layer sensitivity analysis can reliably identify the layers most influenced by target clients and that adaptive sparsification at the weight sub-group level can balance information freshness with effective forgetting without introducing new biases or performance drops.
What would settle it
After running the unlearning procedure, measure whether a held-out test set from the target client still produces high model accuracy or allows data reconstruction; if accuracy does not drop relative to a non-unlearned model, the forgetting claim fails.
Figures






read the original abstract
Federated Unlearning (FU) is emerging as a powerful tool that enables the selective removal of client data to effectively address data contamination and meet strict privacy regulations in mobile edge computing (MEC) systems. Although FU has recently drawn attention in the AI community, existing approaches suffer from low unlearning precision and lack temporal information reflection, which results in suboptimal forgetting performance. To address these issues, we propose SCALE, a dual-level unlearning framework combining historical contribution analysis with information freshness-aware adaptive sparsification. Our framework first employs a historical contribution-based layer sensitivity analysis to identify layers most influenced by target clients, then performs fine-grained unlearning through adaptive sparsification at the weight sub-group level to balance information freshness with forgetting effectiveness. Through theoretical analysis, the proposed framework demonstrates the convergence properties and acceleration advantages. Our experiments and testbed results demonstrate superior unlearning effectiveness compared to state-of-the-art baselines, with significantly improved forgetting performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SCALE, a dual-level federated unlearning framework for mobile edge computing. It first applies historical contribution-based layer sensitivity analysis to identify layers most influenced by target clients, then performs adaptive sparsification at the weight sub-group level that incorporates information freshness to balance forgetting effectiveness with model utility. The paper claims to establish convergence properties and acceleration advantages via theoretical analysis, and reports superior unlearning effectiveness and forgetting performance over state-of-the-art baselines in experiments and testbed evaluations.
Significance. If the convergence analysis is rigorous and the experimental gains hold under proper controls, the work could meaningfully advance federated unlearning by adding temporal freshness awareness and fine-grained sparsification, potentially yielding more precise forgetting in MEC privacy scenarios without large accuracy penalties. The combination of contribution-driven sensitivity and freshness-aware adaptation is a plausible incremental improvement over existing FU methods.
major comments (2)
- [Abstract / Theoretical Analysis] Abstract and theoretical analysis section: The central claim that the dual-level construction (historical contribution sensitivity plus freshness-aware sparsification) yields both convergence and acceleration is load-bearing, yet the abstract supplies no equations, proof sketch, or assumption list. For non-convex deep models it is not obvious that the contribution metric ranks layers by true target-client influence or that the sparsity schedule preserves the underlying optimizer's contraction properties; a mismatch would invalidate both the convergence guarantee and the claimed forgetting improvement.
- [Experiments / Testbed Results] Experimental section: The abstract asserts superior unlearning effectiveness and significantly improved forgetting performance, but the provided text contains no tables, error bars, statistical tests, or ablation results on the free parameters (layer sensitivity threshold, freshness weighting factor). Without these, it is impossible to assess whether the gains are robust or merely post-hoc tuning artifacts.
minor comments (1)
- [Abstract] The abstract introduces 'information freshness' and 'historical contribution' without even a high-level formula or reference to their definitions; adding a brief notational preview would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, providing clarifications from the full manuscript and indicating planned revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / Theoretical Analysis] Abstract and theoretical analysis section: The central claim that the dual-level construction (historical contribution sensitivity plus freshness-aware sparsification) yields both convergence and acceleration is load-bearing, yet the abstract supplies no equations, proof sketch, or assumption list. For non-convex deep models it is not obvious that the contribution metric ranks layers by true target-client influence or that the sparsity schedule preserves the underlying optimizer's contraction properties; a mismatch would invalidate both the convergence guarantee and the claimed forgetting improvement.
Authors: We appreciate the referee's emphasis on the importance of clearly conveying the theoretical foundations. The full manuscript (Section 4) provides a rigorous convergence analysis under standard assumptions including L-smoothness of the loss, bounded gradient variance, and unbiased stochastic gradients. The historical contribution metric is formally defined as the normalized cumulative gradient norm from target clients, and we prove it ranks layers by influence through a sensitivity bound. The adaptive sparsification schedule is shown to preserve the underlying optimizer's contraction mapping by bounding the additional error term introduced at each sub-group level, leading to an accelerated convergence rate compared to uniform unlearning baselines. We agree, however, that the abstract would benefit from a concise statement of key assumptions and a high-level proof outline. We will revise the abstract to incorporate this information. revision: yes
-
Referee: [Experiments / Testbed Results] Experimental section: The abstract asserts superior unlearning effectiveness and significantly improved forgetting performance, but the provided text contains no tables, error bars, statistical tests, or ablation results on the free parameters (layer sensitivity threshold, freshness weighting factor). Without these, it is impossible to assess whether the gains are robust or merely post-hoc tuning artifacts.
Authors: We acknowledge the referee's valid concern about the presentation of experimental evidence. The full manuscript includes comparative tables (Tables 1–3) reporting unlearning effectiveness and forgetting performance metrics averaged over 5 independent runs, with error bars shown in the corresponding figures. Ablation studies varying the layer sensitivity threshold and freshness weighting factor appear in Section 5.3, demonstrating that performance remains stable across a range of values. To strengthen the manuscript, we will add explicit statistical significance tests (paired t-tests with p-values) to the tables and expand the ablation discussion in the main text to further address robustness concerns. revision: yes
Circularity Check
No significant circularity; theoretical claims presented as independent of fitted inputs
full rationale
The abstract and provided context describe a dual-level framework using historical contribution-based layer sensitivity analysis followed by adaptive sparsification, with convergence and acceleration shown via theoretical analysis. No equations, self-citations, or fitted parameters are visible that reduce any prediction or uniqueness claim to the inputs by construction. The derivation chain remains self-contained against external benchmarks, as the central claims rest on modeling steps that are not shown to be tautological or statistically forced within the given text.
Axiom & Free-Parameter Ledger
free parameters (2)
- layer sensitivity threshold
- freshness weighting factor
axioms (1)
- standard math Federated learning updates converge under standard assumptions on client participation and learning rates
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
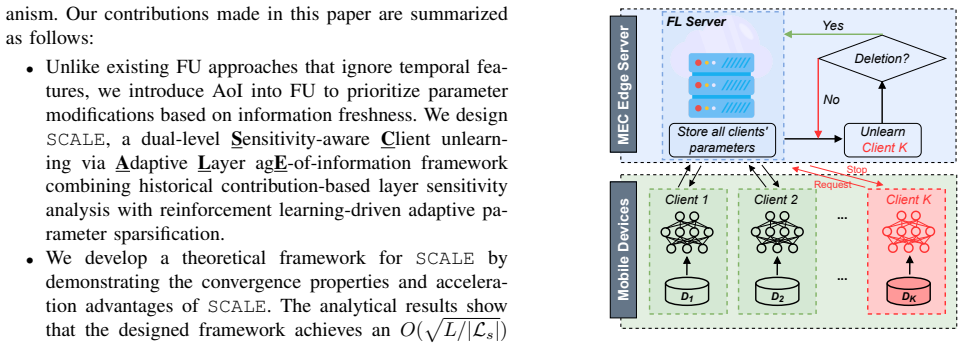
We develop a theoretical framework for SCALE by demonstrating the convergence properties and acceleration advantages of SCALE. The analytical results show that the designed framework achieves an O(√(L/|Ls|)) convergence advantage over the uniform parameter modification framework
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AoI-driven adaptive sparsification... reward R[t] = wf Rf[t] + wc Rc[t] with forgetting and freshness terms
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
B. Wu, J. Huang, Q. Duan, L. Dong, and Z. Cai, “Enhancing Vehicular Platooning With Wireless Federated Learning: A Resource-Aware Con- trol Framework,”IEEE Transactions on Networking, pp. 1–16, 2025
work page 2025
-
[2]
Forget Unlearning: Towards True Data- Deletion in Machine Learning,
R. Chourasia and N. Shah, “Forget Unlearning: Towards True Data- Deletion in Machine Learning,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 6028–6073
work page 2023
-
[3]
N. Xu, Z. Liu, X. Han, Q. Guan, H. Sun, X. Huang, and J. Ma, “An Efficient and Multi-Dimensional Privacy-Preserving Platoon Communi- cation Scheme in Vehicular Networks,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 5, pp. 6831–6847, 2025
work page 2025
-
[4]
B. Wu, Z. Ding, and J. Huang, “RELIEF: Turning Missing Modalities into Training Acceleration for Federated Learning on Heterogeneous IoT Edge,” arXiv preprint arXiv:2604.04243, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Transformer-Based Dynamic Resource Allocation for Multi-Carrier NOMA Systems,
L. Dong, J. Huang, and R. W. Heath, “Transformer-Based Dynamic Resource Allocation for Multi-Carrier NOMA Systems,”IEEE Transac- tions on Cognitive Communications and Networking, vol. 12, pp. 4926– 4941, 2026
work page 2026
-
[6]
Federated Unlearning: A Survey on Methods, Design Guidelines, and Evaluation Metrics,
N. Romandini, A. Mora, C. Mazzocca, R. Montanari, and P. Bellavista, “Federated Unlearning: A Survey on Methods, Design Guidelines, and Evaluation Metrics,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 7, pp. 11 697–11 717, 2025
work page 2025
-
[7]
FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning,
B. Wu, J. Huang, and Q. Duan, “FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning,” inInternational Conference on Wireless Artificial Intelligent Computing Systems and Applications (WASA). Springer, 2025, pp. 13–24
work page 2025
-
[8]
Z. Ding, J. Huang, Q. Duan, C. Zhang, Y . Zhao, and S. Gu, “A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V- Assisted Heterogeneous Vehicle Networks,” in2025 IEEE International Performance, Computing, and Communications Conference (IPCCC). IEEE, 2025, pp. 1–8
work page 2025
-
[9]
BFU: Bayesian Federated Unlearning With Parameter Self-Sharing,
W. Wang, Z. Tian, C. Zhang, A. Liu, and S. Yu, “BFU: Bayesian Federated Unlearning With Parameter Self-Sharing,” inProc. ACM Asia Conf. on Computer and Communications Security (AsiaCCS), 2023, pp. 567–578
work page 2023
-
[10]
Federaser: Enabling Efficient Client-Level Data Removal From Federated Learning Models,
G. Liu, X. Ma, Y . Yang, C. Wang, and J. Liu, “Federaser: Enabling Efficient Client-Level Data Removal From Federated Learning Models,” inProc. IEEE/ACM 29th Int. Symp. on Quality of Service (IWQoS). IEEE, 2021, pp. 1–10
work page 2021
-
[11]
The Right to Be Forgotten in Federated Learning: An Efficient Realization With Rapid Retraining,
Y . Liu, L. Xu, X. Yuan, C. Wang, and B. Li, “The Right to Be Forgotten in Federated Learning: An Efficient Realization With Rapid Retraining,” inProc. IEEE Conf. on Computer Communications (INFOCOM). IEEE, 2022, pp. 1749–1758
work page 2022
-
[12]
Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,
B. Wu, J. Huang, and Q. Duan, “Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,”IEEE Network, vol. 40, no. 2, pp. 184–191, 2026
work page 2026
-
[13]
Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,
B. Wu, Z. Ding, L. Ostigaard, and J. Huang, “Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,” in2025 ACM Research on Adaptive and Convergent Systems (RACS). ACM, 2025, pp. 1–8
work page 2025
-
[14]
AoI-aware Resource Management for Smart Health via Deep Reinforcement Learning,
B. Wu, Z. Cai, W. Wu, and X. Yin, “AoI-aware Resource Management for Smart Health via Deep Reinforcement Learning,”IEEE Access, 2023
work page 2023
-
[15]
AoI-Aware Federated Unlearning for Streaming Data With Online Client Selection and Pricing,
Y . Cui, N. Ding, and M. H. Cheung, “AoI-Aware Federated Unlearning for Streaming Data With Online Client Selection and Pricing,” in IEEE INFOCOM 2025–IEEE Conference on Computer Communica- tions. IEEE, 2025, pp. 1–10
work page 2025
-
[16]
C.-C. Xing, Z. Ding, and J. Huang, “A Stochastic Geometry- Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Harvesting,”SIGAPP Appl. Comput. Rev., vol. 25, no. 4, p. 18–34, Jan
-
[17]
Available: https://doi.org/10.1145/3787594.3787596
[Online]. Available: https://doi.org/10.1145/3787594.3787596
-
[18]
Hybrid Edge Intelligence for Real- Time Intrusion Detection in Advanced Traffic Management Systems,
R. R. Depa, Y . Zhang, and D. Xu, “Hybrid Edge Intelligence for Real- Time Intrusion Detection in Advanced Traffic Management Systems,” in2025 IEEE Security and Privacy Workshops (SPW). IEEE, 2025, pp. 352–354
work page 2025
-
[19]
Z. Ding, J. Huang, and J. Qi, “Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,” in2026 International Conference on Computing, Networking and Communications (ICNC), 2026, pp. 769– 774
work page 2026
-
[20]
Federated Unlearning With Fast Recovery,
C. Zhou, C. Pan, M. Li, and P. Wang, “Federated Unlearning With Fast Recovery,”IEEE Transactions on Mobile Computing, pp. 1–18, 2025
work page 2025
-
[21]
Exploring Federated Unlearning: Review, Comparison, and Insights,
Y . Zhao, J. Yang, Y . Tao, L. Wang, X. Li, D. Niyato, and H. Vin- cent Poor, “Exploring Federated Unlearning: Review, Comparison, and Insights,”IEEE Network, pp. 1–1, 2025
work page 2025
-
[22]
X. Sheng, W. Bao, and L. Ge, “Robust Federated Unlearning,” in Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM), 2024, pp. 2034–2044
work page 2024
-
[23]
Certified Unlearning for Federated Recommendation,
T. T. Huynh, T. B. Nguyen, T. T. Nguyen, P. L. Nguyen, H. Yin, Q. V . H. Nguyen, and T. T. Nguyen, “Certified Unlearning for Federated Recommendation,”ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–29, 2025
work page 2025
-
[24]
FU-PA: Federated Unlearning via Parameters Adjustment,
W. Zeng, S. Chen, X. Li, and S. Chen, “FU-PA: Federated Unlearning via Parameters Adjustment,”IEEE Transactions on Emerging Topics in Computational Intelligence, pp. 1–12, 2025
work page 2025
-
[25]
Speed Up Federated Unlearning With Temporary Local Models,
M. Ameen, P. Wang, W. Su, X. Wei, and Q. Zhang, “Speed Up Federated Unlearning With Temporary Local Models,”IEEE Transactions on Sustainable Computing, pp. 1–16, 2025
work page 2025
-
[26]
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine Unlearning,” in2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021, pp. 141–159
work page 2021
-
[27]
Federated Unlearning via Class- Discriminative Pruning,
J. Wang, S. Guo, X. Xie, and H. Qi, “Federated Unlearning via Class- Discriminative Pruning,” inProceedings of the ACM Web Conference 2022, 2022, pp. 622–632
work page 2022
-
[28]
Proof of Unlearning: Definitions and Instantiation,
J. Weng, S. Yao, Y . Du, J. Huang, J. Weng, and C. Wang, “Proof of Unlearning: Definitions and Instantiation,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 3309–3323, 2024
work page 2024
-
[29]
Langevin Unlearning: A New Perspective of Noisy Gradient Descent for Machine Unlearning,
E. Chien, H. Wang, Z. Chen, and P. Li, “Langevin Unlearning: A New Perspective of Noisy Gradient Descent for Machine Unlearning,” Advances in Neural Information Processing Systems (NeurIPS), vol. 37, pp. 79 666–79 703, 2024
work page 2024
-
[30]
J. Huang, B. Wu, Q. Duan, L. Dong, and S. Yu, “A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,”IEEE Transactions on Mobile Computing, pp. 1–16, 2025
work page 2025
-
[31]
Unified Gradient-Based Machine Unlearning With Remain Geometry Enhancement,
Z. Huang, X. Cheng, J. Zheng, H. Wang, Z. He, T. Li, and X. Huang, “Unified Gradient-Based Machine Unlearning With Remain Geometry Enhancement,”Advances in Neural Information Processing Systems (NeurIPS), vol. 37, pp. 26 377–26 414, 2024
work page 2024
-
[32]
GDR-GMA: Machine Unlearning via Direction-Rectified and Magnitude-Adjusted Gradients,
S. Lin, X. Zhang, W. Susilo, X. Chen, and J. Liu, “GDR-GMA: Machine Unlearning via Direction-Rectified and Magnitude-Adjusted Gradients,” inProceedings of the 32nd ACM International Conference on Multimedia (ACM MM), 2024, pp. 9087–9095
work page 2024
-
[33]
Federated Unlearning With Gradient Descent and Conflict Mitigation,
Z. Pan, Z. Wang, C. Li, K. Zheng, B. Wang, X. Tang, and J. Zhao, “Federated Unlearning With Gradient Descent and Conflict Mitigation,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol. 39, no. 19, 2025, pp. 19 804–19 812
work page 2025
-
[34]
PRISM: Exposing and Resolving Spurious Isolation in Federated Multimodal Continual Learning
B. Wu, Z. Ding, and J. Huang, “PRISM: Exposing and Resolving Spurious Isolation in Federated Multimodal Continual Learning,” arXiv preprint arXiv:2605.01061, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
B. Wang, Y . Zi, Y . Sun, Y . Zhao, and B. Qin, “Balancing Forget Quality and Model Utility: A Reverse KL-Divergence Knowledge Distillation Approach for Better Unlearning in LLMs,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers...
work page 2025
-
[36]
H. Kim, S. Lee, and S. S. Woo, “Layer Attack Unlearning: Fast and Accurate Machine Unlearning via Layer Level Attack and Knowledge Distillation,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol. 38, no. 19, 2024, pp. 21 241–21 248
work page 2024
-
[37]
Update Selective Pa- rameters: Federated Machine Unlearning Based on Model Explanation,
H. Xu, T. Zhu, L. Zhang, W. Zhou, and P. S. Yu, “Update Selective Pa- rameters: Federated Machine Unlearning Based on Model Explanation,” IEEE Transactions on Big Data, vol. 11, no. 2, pp. 524–539, 2025
work page 2025
-
[38]
Sky of Unlearning (SoUL): Rewiring Federated Machine Unlearning via Selective Pruning,
M. M. U. Zaman, X. Sun, and J. Yao, “Sky of Unlearning (SoUL): Rewiring Federated Machine Unlearning via Selective Pruning,”arXiv preprint arXiv:2504.01705 (arXiv), 2025
-
[39]
Towards Safe Machine Unlearning: A Paradigm That Mitigates Performance Degradation,
S. Ye, J. Lu, and G. Zhang, “Towards Safe Machine Unlearning: A Paradigm That Mitigates Performance Degradation,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 4635–4652
work page 2025
-
[40]
Machine Unlearning Through Fine-Grained Model Parameters Perturbation,
Z. Zuo, Z. Tang, K. Li, and A. Datta, “Machine Unlearning Through Fine-Grained Model Parameters Perturbation,”IEEE Transactions on Knowledge and Data Engineering, vol. 37, no. 4, pp. 1975–1988, 2025
work page 1975
-
[41]
A Review of Continual Learning in Edge AI,
B. Wu, Z. Ding, and J. Huang, “A Review of Continual Learning in Edge AI,”IEEE Transactions on Network Science and Engineering, vol. 13, pp. 6571–6588, 2026
work page 2026
-
[42]
H. Zhang, B. Wu, X. Yang, X. Yuan, X. Liu, and X. Yi, “Dynamic Graph Unlearning: A General and Efficient Post-Processing Method via Gradient Transformation,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 931–944
work page 2025
-
[43]
Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems
B. Wu and J. Huang, “Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems,” arXiv preprint arXiv:2604.20745, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
EASE: Federated Multimodal Unlearning via Entanglement-Aware Anchor Closure
Z. Ding, B. Wu, and J. Huang, “EASE: Federated Multimodal Un- learning via Entanglement-Aware Anchor Closure,” arXiv preprint arXiv:2605.00733, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Incentivized Federated Learning and Unlearning,
N. Ding, Z. Sun, E. Wei, and R. Berry, “Incentivized Federated Learning and Unlearning,”IEEE Transactions on Mobile Computing, pp. 1–17, 2025
work page 2025
-
[46]
Application-Aware Twin-in-the-Loop Planning for Federated Split Learning over Wireless Edge Networks
Z. Ding, B. Wu, J. Huang, and S. Mao, “Application-Aware Twin-in- the-Loop Planning for Federated Split Learning over Wireless Edge Networks,” arXiv preprint arXiv:2604.26105, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
B. Wu, J. Huang, and S. Yu, ““X of Information” Continuum: A Survey on AI-Driven Multi-Dimensional Metrics for Next-Generation Net- worked Systems,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 5307–5344, 2026
work page 2026
-
[48]
Securing Smart Agriculture with Communication-Efficient Federated Unlearning,
U. Pudasaini, Z. Ding, and J. Huang, “Securing Smart Agriculture with Communication-Efficient Federated Unlearning,” in2026 IEEE International Conference on High Performance Switching and Routing (HPSR). IEEE, 2026, pp. 1–8
work page 2026
-
[49]
Pearson’s correlation coefficient,
P. Sedgwick, “Pearson’s correlation coefficient,”Bmj, vol. 345, 2012
work page 2012
-
[50]
R ´enyi Divergence and Kullback-Leibler Divergence,
T. van Erven and P. Harremos, “R ´enyi Divergence and Kullback-Leibler Divergence,”IEEE Transactions on Information Theory, vol. 60, no. 7, pp. 3797–3820, 2014
work page 2014
-
[51]
Learn to Forget: Machine Unlearning via Neuron Masking,
Z. Ma, Y . Liu, X. Liu, J. Liu, J. Ma, and K. Ren, “Learn to Forget: Machine Unlearning via Neuron Masking,”IEEE Transactions on De- pendable and Secure Computing, vol. 20, no. 4, pp. 3194–3207, 2023
work page 2023
-
[52]
FedEraser: Enabling Efficient Client-Level Data Removal from Federated Learning Models,
G. Liu, X. Ma, Y . Yang, C. Wang, and J. Liu, “FedEraser: Enabling Efficient Client-Level Data Removal from Federated Learning Models,” in2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), 2021, pp. 1–10
work page 2021
-
[53]
Federated unlearning: How to effi- ciently erase a client in fl? arXiv preprint arXiv:2207.05521,
A. Halimi, S. Kadhe, A. Rawat, and N. Baracaldo, “Federated Unlearning: How to Efficiently Erase a Client in FL?” 2023. [Online]. Available: https://arxiv.org/abs/2207.05521
-
[54]
Z. Zhong, W. Bao, J. Wang, S. Zhang, J. Zhou, L. Lyu, and W. Y . B. Lim, “Unlearning Through Knowledge Overwriting: Reversible Feder- ated Unlearning via Selective Sparse Adapter,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025, pp. 30 661–30 670
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.