Recognition: unknown
Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems
Pith reviewed 2026-05-10 00:34 UTC · model grok-4.3
The pith
A dual-timescale federated continual learning framework mitigates layer-specific forgetting and long-term drift to improve terrain adaptation in mobile autonomous fleets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a lifecycle-aware dual-timescale FCL framework, which combines training-time layer-selective rehearsal to prevent immediate forgetting and post-drift rapid knowledge recovery to counter cumulative effects, together with theoretical characterization of heterogeneous forgetting dynamics, enables effective collaborative adaptation to evolving terrains while addressing uniform protection, long-term degradation, and simulation-reality gaps in real distributed fleets.
What carries the argument
The lifecycle-aware dual-timescale FCL framework, which uses a layer-selective rehearsal strategy during local training to target forgetting-sensitive layers and a rapid knowledge recovery strategy to restore degraded models after cumulative drift.
If this is right
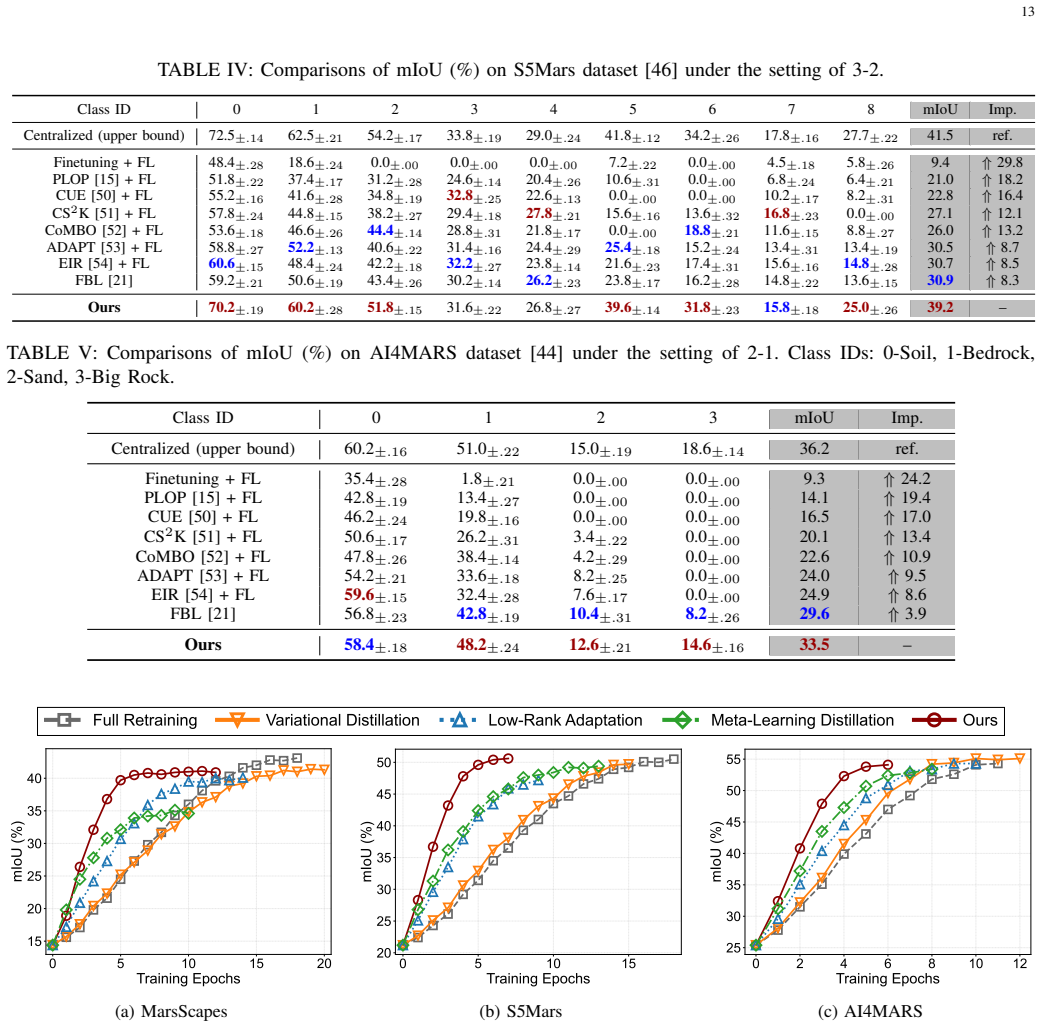
- Up to 8.3% mIoU improvement over the strongest federated baseline in segmentation tasks for evolving terrains.
- Up to 31.7% mIoU improvement over conventional fine-tuning.
- Confirmed system-level robustness when deployed on a physical rover testbed under realistic constraints.
- Long-term degradation is inevitable in such settings without recovery mechanisms.
Where Pith is reading between the lines
- The separation of prevention and recovery phases could be tested in other distributed settings such as drone fleets adapting to seasonal changes.
- Scheduling recovery based on observed drift rates might reduce communication overhead in energy-limited missions.
- The heterogeneous forgetting analysis points toward layer-specific policies in non-federated continual learning as well.
Load-bearing premise
The layer-selective rehearsal and rapid knowledge recovery strategies, combined with the characterization of heterogeneous forgetting, are sufficient to address uniform protection, long-term drift, and simulation-reality gaps in distributed fleets.
What would settle it
A real-world rover deployment showing no mIoU gains over baselines or empirical data revealing uniform forgetting rates across layers would falsify the claim that the dual-timescale strategies and heterogeneous analysis resolve the stated challenges.
Figures






read the original abstract
Federated continual learning (FCL) allows distributed autonomous fleets to adapt collaboratively to evolving terrain types across extended mission lifecycles. However, current approaches face several key challenges: 1) they use uniform protection strategies that do not account for the varying sensitivities to forgetting on different network layers; 2) they focus primarily on preventing forgetting during training, without addressing the long-term effects of cumulative drift; and 3) they often depend on idealized simulations that fail to capture the real-world heterogeneity present in distributed fleets. In this paper, we propose a lifecycle-aware dual-timescale FCL framework that incorporates training-time (pre-forgetting) prevention and (post-forgetting) recovery. Under this framework, we design a layer-selective rehearsal strategy that mitigates immediate forgetting during local training, and a rapid knowledge recovery strategy that restores degraded models after long-term cumulative drift. We present a theoretical analysis that characterizes heterogeneous forgetting dynamics and establishes the inevitability of long-term degradation. Our experimental results show that this framework achieves up to 8.3\% mIoU improvement over the strongest federated baseline and up to 31.7\% over conventional fine-tuning. We also deploy the FCL framework on a real-world rover testbed to assess system-level robustness under realistic constraints; the testing results further confirm the effectiveness of our FCL design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a lifecycle-aware dual-timescale federated continual learning (FCL) framework for mobile autonomous systems. It incorporates a layer-selective rehearsal strategy to prevent forgetting during local training and a rapid knowledge recovery strategy to restore performance after long-term cumulative drift. A theoretical analysis characterizes heterogeneous forgetting dynamics and establishes the inevitability of degradation. Experiments report up to 8.3% mIoU improvement over the strongest federated baseline and 31.7% over conventional fine-tuning, with additional validation via deployment on a real-world rover testbed to assess system-level robustness.
Significance. If the empirical gains and theoretical results hold under rigorous validation, the work could meaningfully advance federated continual learning for distributed autonomous fleets by explicitly handling both pre- and post-forgetting phases in heterogeneous, long-lifecycle settings. The combination of a dual-timescale design, theoretical characterization of forgetting, and real-world rover deployment represents a constructive step beyond purely preventive or simulation-only approaches.
major comments (2)
- [Real-World Deployment] Real-World Deployment section: The rover testbed evaluation does not specify fleet size, mission duration, asynchrony of data arrival, or the extent of heterogeneity across agents. This leaves the post-forgetting recovery strategy unlinked to the long-term drift scenario that the theoretical analysis predicts will cause degradation, weakening support for the lifecycle-aware claim.
- [Experimental Results] Experimental Results section: The reported mIoU improvements (8.3% over federated baseline, 31.7% over fine-tuning) are presented without error bars, number of independent runs, or statistical significance tests. This makes it impossible to determine whether the gains are reliable or sensitive to the specific datasets and heterogeneity levels used.
minor comments (2)
- [Abstract] The abstract states improvements without referencing the specific datasets, number of clients, or task sequences; adding these details would improve readability even if they appear later in the paper.
- [Methodology] Notation for the layer-selective rehearsal parameters and recovery thresholds is introduced without a consolidated table; a summary table would aid cross-referencing between the methodology and experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Real-World Deployment] Real-World Deployment section: The rover testbed evaluation does not specify fleet size, mission duration, asynchrony of data arrival, or the extent of heterogeneity across agents. This leaves the post-forgetting recovery strategy unlinked to the long-term drift scenario that the theoretical analysis predicts will cause degradation, weakening support for the lifecycle-aware claim.
Authors: We agree that additional deployment specifics will better connect the empirical results to the theoretical analysis of long-term drift. In the revised manuscript, we will expand the Real-World Deployment section with the exact fleet size used, mission durations, observed asynchrony in data arrival, and quantified heterogeneity levels across agents. These details were recorded during the testbed experiments and will be reported to explicitly link the recovery strategy to the predicted degradation. revision: yes
-
Referee: [Experimental Results] Experimental Results section: The reported mIoU improvements (8.3% over federated baseline, 31.7% over fine-tuning) are presented without error bars, number of independent runs, or statistical significance tests. This makes it impossible to determine whether the gains are reliable or sensitive to the specific datasets and heterogeneity levels used.
Authors: We acknowledge the need for more rigorous statistical reporting. In the revised version, we will add error bars (standard deviation across runs), explicitly state the number of independent runs performed, and include statistical significance tests (e.g., paired t-tests with p-values) for the mIoU gains. This will be applied to both the federated baseline and fine-tuning comparisons to demonstrate reliability across the evaluated datasets and heterogeneity settings. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central contributions consist of an empirical framework (layer-selective rehearsal and rapid recovery strategies) evaluated via reported mIoU gains on benchmarks plus a real-world rover deployment, together with a theoretical characterization of heterogeneous forgetting. No load-bearing step reduces a claimed prediction or first-principles result to a fitted parameter, self-citation, or definitional tautology by construction. The inevitability-of-degradation result is presented as an outcome of the analysis rather than an input; experimental numbers are not described as being recovered from the same data used to tune the strategies. The derivation chain therefore remains self-contained against external benchmarks and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
Inference-Time Budget Control for LLM Search Agents
A VOI-based controller for dual inference budgets improves multi-hop QA performance by prioritizing search actions and selectively finalizing answers.
-
PRISM: Exposing and Resolving Spurious Isolation in Federated Multimodal Continual Learning
PRISM maintains per-expert gradient subspace bases preserved under FedAvg to resolve spurious isolation in federated multimodal continual learning, outperforming 16 baselines with larger gains on longer task sequences.
-
EASE: Federated Multimodal Unlearning via Entanglement-Aware Anchor Closure
EASE closes three residual anchors in federated multimodal unlearning using bilateral displacement, cosine-sine decomposition, and forget lock, achieving near-retrain performance on forget and retain data.
-
Application-Aware Twin-in-the-Loop Planning for Federated Split Learning over Wireless Edge Networks
TiLP integrates network, training, and task sub-twins into a digital twin and uses receding-horizon cross-entropy planning with actor-critic guidance to jointly optimize resource allocation in federated split learning...
Reference graph
Works this paper leans on
-
[1]
Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,
B. Wu, Z. Ding, L. Ostigaard, and J. Huang, “Reinforcement Learning- Based Energy-Aware Coverage Path Planning for Precision Agriculture,” inProceedings of the ACM Research on Adaptive and Convergent Systems (RACS), 2025, pp. 1–8
2025
-
[2]
FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning,
B. Wu, J. Huang, and Q. Duan, “FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning,” inProceedings of the Interna- tional Conference on Wireless Artificial Intelligent Computing Systems and Applications (WASA), 2025, pp. 13–24
2025
-
[3]
A Dual-Level Game-Theoretic Approach for Collaborative Learning in UA V-Assisted Heterogeneous Vehicle Networks,
Z. Ding, J. Huang, Q. Duan, C. Zhang, Y . Zhao, and S. Gu, “A Dual-Level Game-Theoretic Approach for Collaborative Learning in UA V-Assisted Heterogeneous Vehicle Networks,” inProceedings of the IEEE International Performance, Computing, and Communications Conference (IPCCC), 2025, pp. 1–8
2025
-
[4]
Mars Exploration Rovers: Spirit and Opportunity,
NASA Science, “Mars Exploration Rovers: Spirit and Opportunity,” https://science.nasa.gov/mission/ mars-exploration-rovers-spirit-and-opportunity/, 2025, accessed: 2025-12-10
2025
-
[5]
The Mars Report: Special Edition – September 2025,
——, “The Mars Report: Special Edition – September 2025,” https:// science.nasa.gov/mars/the-mars-report/2025-september-special-edition/, 2025, accessed: 2025-12-10
2025
-
[6]
Overview and Results from the Mars 2020 Perseverance Rover’s First Science Campaign on the Jezero Crater Floor,
V . Z. Sunet al., “Overview and Results from the Mars 2020 Perseverance Rover’s First Science Campaign on the Jezero Crater Floor,”Journal of Geophysical Research: Planets, vol. 128, no. 8, p. e2022JE007613, 2023
2020
-
[7]
Deep Learning for Space Guidance, Navigation, and Control,
S. V . Khoroshylov and M. O. Redka, “Deep Learning for Space Guidance, Navigation, and Control,”Space Science and Technology, vol. 27, no. 6, pp. 38–52, 2021
2021
-
[8]
“X of Information
B. Wu, J. Huang, and S. Yu, ““X of Information” Continuum: A Survey on AI-Driven Multi-Dimensional Metrics for Next-Generation Net- worked Systems,”IEEE Communications Surveys & Tutorials, vol. 28, pp. 5307–5344, 2026
2026
-
[9]
Communication-Efficient Learning of Deep Networks from Decentral- ized Data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-Efficient Learning of Deep Networks from Decentral- ized Data,” inProceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS). PMLR, 2017, pp. 1273–1282
2017
-
[10]
Federated Optimization in Heterogeneous Networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated Optimization in Heterogeneous Networks,”Proceedings of Machine Learning and Systems (MLSys), vol. 2, pp. 429–450, 2020
2020
-
[11]
Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,
B. Wu, J. Huang, and Q. Duan, “Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization,”IEEE Network, vol. 40, no. 2, pp. 184–191, 2026
2026
-
[12]
B. Wu, Z. Ding, and J. Huang, “RELIEF: Turning Missing Modalities into Training Acceleration for Federated Learning on Heterogeneous IoT Edge,” arXiv preprint arXiv:2604.04243, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
A Comprehensive Survey of Continual Learning: Theory, Method and Application,
L. Wang, X. Zhang, H. Su, and J. Zhu, “A Comprehensive Survey of Continual Learning: Theory, Method and Application,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5362–5383, 2024
2024
-
[14]
iCaRL: Incremental Classifier and Representation Learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “iCaRL: Incremental Classifier and Representation Learning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2017, pp. 2001–2010
2017
-
[15]
PLOP: Learning Without Forgetting for Continual Semantic Segmentation,
A. Douillard, Y . Chen, A. Dapogny, and M. Cord, “PLOP: Learning Without Forgetting for Continual Semantic Segmentation,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021, pp. 4040–4050
2021
-
[16]
Unleashing the Power of Continual Learning on Non-Centralized Devices: A Survey,
Y . Li, H. Wang, W. Xu, T. Xiao, H. Liu, M. Tu, Y . Wang, X. Yang, R. Zhang, and S. Yu, “Unleashing the Power of Continual Learning on Non-Centralized Devices: A Survey,”IEEE Communications Surveys and Tutorials, 2025
2025
-
[17]
Forgetting, Ignorance or Myopia: Revisiting Key Challenges in Online Continual Learning,
X. Wang, C. Geng, W. Wan, S.-Y . Li, and S. Chen, “Forgetting, Ignorance or Myopia: Revisiting Key Challenges in Online Continual Learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 58 341–58 375, 2024
2024
-
[18]
Federated Con- tinual Learning via Knowledge Fusion: A Survey,
X. Yang, H. Yu, X. Gao, H. Wang, J. Zhang, and T. Li, “Federated Con- tinual Learning via Knowledge Fusion: A Survey,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 8, pp. 3832–3850, 2024
2024
-
[19]
Incremental Meta-Learning via Episodic Replay Distillation for Few-Shot Image Recognition,
K. Wang, X. Liu, A. D. Bagdanov, L. Herranz, S. Jui, and J. van de Weijer, “Incremental Meta-Learning via Episodic Replay Distillation for Few-Shot Image Recognition,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022, pp. 3729–3739
2022
-
[20]
Does Continual Learning Equally Forget All Parameters?
H. Zhao, T. Zhou, G. Long, J. Jiang, and C. Zhang, “Does Continual Learning Equally Forget All Parameters?” inProceedings of the Inter- national Conference on Machine Learning (ICML). PMLR, 2023, pp. 42 280–42 303
2023
-
[21]
Federated Incremental Semantic Segmentation,
J. Dong, D. Zhang, Y . Cong, W. Cong, H. Ding, and D. Dai, “Federated Incremental Semantic Segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023, pp. 3934–3943
2023
-
[22]
Variational Data-Free Knowledge Distillation for Continual Learning,
X. Li, S. Wang, J. Sun, and Z. Xu, “Variational Data-Free Knowledge Distillation for Continual Learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 12 618–12 634, 2023
2023
-
[23]
Learn More, But Bother Less: Parameter Ef- ficient Continual Learning,
F. Qiao and M. Mahdavi, “Learn More, But Bother Less: Parameter Ef- ficient Continual Learning,”Advances in Neural Information Processing Systems (NeurIPS), vol. 37, pp. 97 476–97 498, 2024
2024
-
[24]
CL-LoRA: Continual Low-Rank Adaptation for Rehearsal-Free Class-Incremental Learning,
J. He, Z. Duan, and F. Zhu, “CL-LoRA: Continual Low-Rank Adaptation for Rehearsal-Free Class-Incremental Learning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2025, pp. 30 534–30 544
2025
-
[25]
Online-LoRA: Task-Free Online Continual Learning via Low Rank Adaptation,
X. Wei, G. Li, and R. Marculescu, “Online-LoRA: Task-Free Online Continual Learning via Low Rank Adaptation,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2025, pp. 6634–6645
2025
-
[26]
Nested Learn- ing: The Illusion of Deep Learning Architectures,
A. Behrouz, M. Razaviyayn, P. Zhong, and V . Mirrokni, “Nested Learn- ing: The Illusion of Deep Learning Architectures,” inProceedings of the Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[27]
EVCL: Elastic Variational Continual Learning with Weight Consolidation,
H. Batra and R. Clark, “EVCL: Elastic Variational Continual Learning with Weight Consolidation,”arXiv preprint arXiv:2406.15972 (arXiv), 2024
-
[28]
Enhancing Vehic- ular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework,
B. Wu, J. Huang, Q. Duan, L. Dong, and Z. Cai, “Enhancing Vehic- ular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework,”IEEE/ACM Transactions on Networking, 2025
2025
-
[29]
Enhancing Federated Learning in Connected and Autonomous Vehicles Through Cost Optimization and Advanced Model Selection,
X. Cai, P. Zhao, S. Liu, Y . Fu, C. Li, and F. R. Yu, “Enhancing Federated Learning in Connected and Autonomous Vehicles Through Cost Optimization and Advanced Model Selection,”IEEE Transactions on Intelligent Transportation Systems, 2025
2025
-
[30]
A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,
J. Huang, B. Wu, Q. Duan, L. Dong, and S. Yu, “A Fast UA V Tra- jectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating,”IEEE Transactions on Mobile Computing, vol. 24, no. 8, pp. 6870–6885, 2025
2025
-
[31]
Securing Smart Agriculture with Communication-Efficient Federated Unlearning,
U. Pudasaini, Z. Ding, and J. Huang, “Securing Smart Agriculture with Communication-Efficient Federated Unlearning,” inProceedings of the IEEE International Conference on High Performance Switching and Routing (HPSR), 2026, pp. 1–8
2026
-
[32]
Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics,
Z. Fang, S. Hu, J. Wang, Y . Deng, X. Chen, and Y . Fang, “Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics,”IEEE Transactions on Networking, pp. 1–17, 2025
2025
-
[33]
R- ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,
Z. Fang, J. Wang, Y . Ma, Y . Tao, Y . Deng, X. Chen, and Y . Fang, “R- ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications,”IEEE Journal on Selected Areas in Communications, 2025
2025
-
[34]
Task-Oriented Communications for Visual Navigation with Edge-Aerial Collaboration in Low Altitude Economy,
Z. Fang, Z. Liu, J. Wang, S. Hu, Y . Guo, Y . Deng, and Y . Fang, “Task-Oriented Communications for Visual Navigation with Edge-Aerial Collaboration in Low Altitude Economy,” inProceedings of the IEEE Global Communications Conference (GLOBECOM), 2026
2026
-
[35]
AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning,
B. Wu, Z. Cai, W. Wu, and X. Yin, “AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning,”IEEE Access, 2023
2023
-
[36]
A Stochastic Geometry-Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Har- vesting,
C.-C. Xing, Z. Ding, and J. Huang, “A Stochastic Geometry-Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Har- vesting,”ACM SIGAPP Applied Computing Review, vol. 25, no. 4, pp. 18–34, 2026
2026
-
[37]
A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum- Based Nano-Communication Technique,
D. Pan, B.-N. Wu, Y .-L. Sun, and Y .-P. Xu, “A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum- Based Nano-Communication Technique,”Sustainable Computing: In- formatics and Systems, vol. 37, p. 100827, 2023. 19
2023
-
[38]
Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning,
B. Wu and W. Wu, “Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning,”Mathematical Problems in Engineering, vol. 2023, no. 1, p. 6350647, 2023
2023
-
[39]
Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,
Z. Ding, J. Huang, and J. Qi, “Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing,” inProceedings of the International Confer- ence on Computing, Networking and Communications (ICNC), 2026
2026
-
[40]
Federated Continual Learning With Bounded Forgetting via Diffusion-Based Generative Replay in Edge Computing,
Z. He, Y . Wang, and Z. Cai, “Federated Continual Learning With Bounded Forgetting via Diffusion-Based Generative Replay in Edge Computing,”IEEE Transactions on Mobile Computing, pp. 1–17, 2025
2025
-
[41]
SPOC: Deep learning-based terrain classification for Mars rover missions,
B. Rothrock, R. Kennedy, C. Cunningham, J. Papon, M. Heverly, and M. Ono, “SPOC: Deep learning-based terrain classification for Mars rover missions,” inAIAA SPACE Forum, 2016, pp. 1–12
2016
-
[42]
MAARS: Machine learning- based analytics for automated rover systems,
M. Ono, B. Rothrock, K. Otsu, S. Higa, Y . Iwashita, A. Didier, T. Islam, C. Laporte, V . Sun, K. Stacket al., “MAARS: Machine learning- based analytics for automated rover systems,” inProc. IEEE Aerospace Conference, 2020, pp. 1–17
2020
-
[43]
MLNav: Learning to safely navigate on Mars,
S. Daftry, N. Abcouwer, T. Del Sesto, S. Venkatraman, J. Song, L. Igel, A. Byon, U. Rosolia, Y . Yue, and M. Ono, “MLNav: Learning to safely navigate on Mars,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 5461–5468, 2022
2022
-
[44]
AI4MARS: A Dataset for Terrain-Aware Autonomous Driving on Mars,
R. M. Swan, D. Atha, H. A. Leopold, M. Gildner, S. Oij, C. Chiu, and M. Ono, “AI4MARS: A Dataset for Terrain-Aware Autonomous Driving on Mars,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2021
2021
-
[45]
A Hybrid Attention Semantic Segmentation Network for Unstructured Terrain on Mars,
H. Liu, M. Yao, X. Xiao, and H. Cui, “A Hybrid Attention Semantic Segmentation Network for Unstructured Terrain on Mars,”Acta Astro- nautica, vol. 204, pp. 492–499, 2023
2023
-
[46]
S5Mars: Semi- Supervised Learning for Mars Semantic Segmentation,
J. Zhang, L. Lin, Z. Fan, W. Wang, and J. Liu, “S5Mars: Semi- Supervised Learning for Mars Semantic Segmentation,”IEEE Trans- actions on Geoscience and Remote Sensing, vol. 62, pp. 1–15, 2024
2024
-
[47]
A Review of Continual Learning in Edge AI,
B. Wu, Z. Ding, and J. Huang, “A Review of Continual Learning in Edge AI,”IEEE Transactions on Network Science and Engineering, vol. 13, pp. 6571–6588, 2026
2026
-
[48]
Dark Experience for General Continual Learning: A Strong, Simple Baseline,
P. Buzzega, M. Boschini, A. Porrello, D. Abati, and S. Calderara, “Dark Experience for General Continual Learning: A Strong, Simple Baseline,”Advances in Neural Information Processing Systems, vol. 33, pp. 15 920–15 930, 2020
2020
-
[49]
Shared Spatial Memory Through Predictive Coding,
Z. Fang, Y . Guo, J. Wang, Y . Zhang, H. An, Y . Wang, and Y . Fang, “Shared Spatial Memory Through Predictive Coding,” arXiv preprint arXiv:2511.04235, 2025
-
[50]
Towards Continual Universal Segmen- tation,
Z. Lin, Z. Wang, and X. Wang, “Towards Continual Universal Segmen- tation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2025, pp. 29 417–29 427
2025
-
[51]
CS 2K: Class-Specific and Class-Shared Knowledge Guidance for Incremental Semantic Segmen- tation,
W. Cong, Y . Cong, Y . Liu, and G. Sun, “CS 2K: Class-Specific and Class-Shared Knowledge Guidance for Incremental Semantic Segmen- tation,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2024, pp. 244–261
2024
-
[52]
CoMBO: Conflict Mitigation via Branched Optimization for Class Incremental Segmentation,
K. Fang, A. Zhang, G. Gao, J. Jiao, C. H. Liu, and Y . Wei, “CoMBO: Conflict Mitigation via Branched Optimization for Class Incremental Segmentation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2025, pp. 25 667– 25 676
2025
-
[53]
ADAPT: Attentive Self-Distillation and Dual-Decoder Prediction Fusion for Continual Panoptic Segmentation,
Z. Yang, S. Dong, R. Li, N. Song, and G. Lin, “ADAPT: Attentive Self-Distillation and Dual-Decoder Prediction Fusion for Continual Panoptic Segmentation,” inProceedings of The Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[54]
Beyond Background Shift: Rethinking Instance Replay in Continual Semantic Segmentation,
H. Yin, T. Feng, F. Lyu, F. Shang, H. Liu, W. Feng, and L. Wan, “Beyond Background Shift: Rethinking Instance Replay in Continual Semantic Segmentation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2025, pp. 9839–9848
2025
-
[55]
Task Confusion and Catastrophic Forgetting in Class-Incremental Learning: A Mathematical Framework for Discriminative and Generative Modelings,
M. Khademi Nori and I.-M. Kim, “Task Confusion and Catastrophic Forgetting in Class-Incremental Learning: A Mathematical Framework for Discriminative and Generative Modelings,”Advances in Neural Information Processing Systems, vol. 37, pp. 47 678–47 707, 2024
2024
-
[56]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks,
C. Finn, P. Abbeel, and S. Levine, “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks,” inProceedings of the International Conference on Machine Learning (ICML). PMLR, 2017, pp. 1126– 1135
2017
-
[57]
Relay communications strategies for Mars exploration through 2020,
C. D. Edwards, B. W. Arnold, R. P. DePaula, G. J. Kazz, C. H. Lee, and G. K. Noreen, “Relay communications strategies for Mars exploration through 2020,”Acta Astronautica, vol. 59, no. 1–5, pp. 310–318, 2006
2020
-
[58]
Shalev-Shwartz and S
S. Shalev-Shwartz and S. Ben-David,Understanding Machine Learning: From Theory to Algorithms. Cambridge, UK: Cambridge University Press, 2014
2014
-
[59]
Encoder- Decoder with Atrous Separable Convolution for Semantic Image Seg- mentation,
L.-C. Chen, Y . Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder- Decoder with Atrous Separable Convolution for Semantic Image Seg- mentation,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2018, pp. 801–818
2018
-
[60]
Deep Residual Learning for Image Recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016, pp. 770–778
2016
-
[61]
ImageNet Large Scale Visual Recognition Challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “ImageNet Large Scale Visual Recognition Challenge,”International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.