Efficient Learned Image Compression without Entropy Coding
Pith reviewed 2026-05-25 03:02 UTC · model grok-4.3
The pith
EF-LIC removes statistical and correlation redundancy in learned image compression without using entropy coding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EF-LIC generates compact representations by unconstrained vector quantization, whose index distribution approaches the maximum-entropy bound, and a context-conditioned autoregressive transform that reparameterizes latents to reduce dependency, allowing removal of both statistical and correlation redundancy without entropy coding while matching the performance of entropy-coded learned image compression.
What carries the argument
Unconstrained vector quantization paired with a context-conditioned autoregressive transform, which together eliminate the need for entropy coding by driving index distributions to maximum entropy and directly reducing latent inter-dependencies.
If this is right
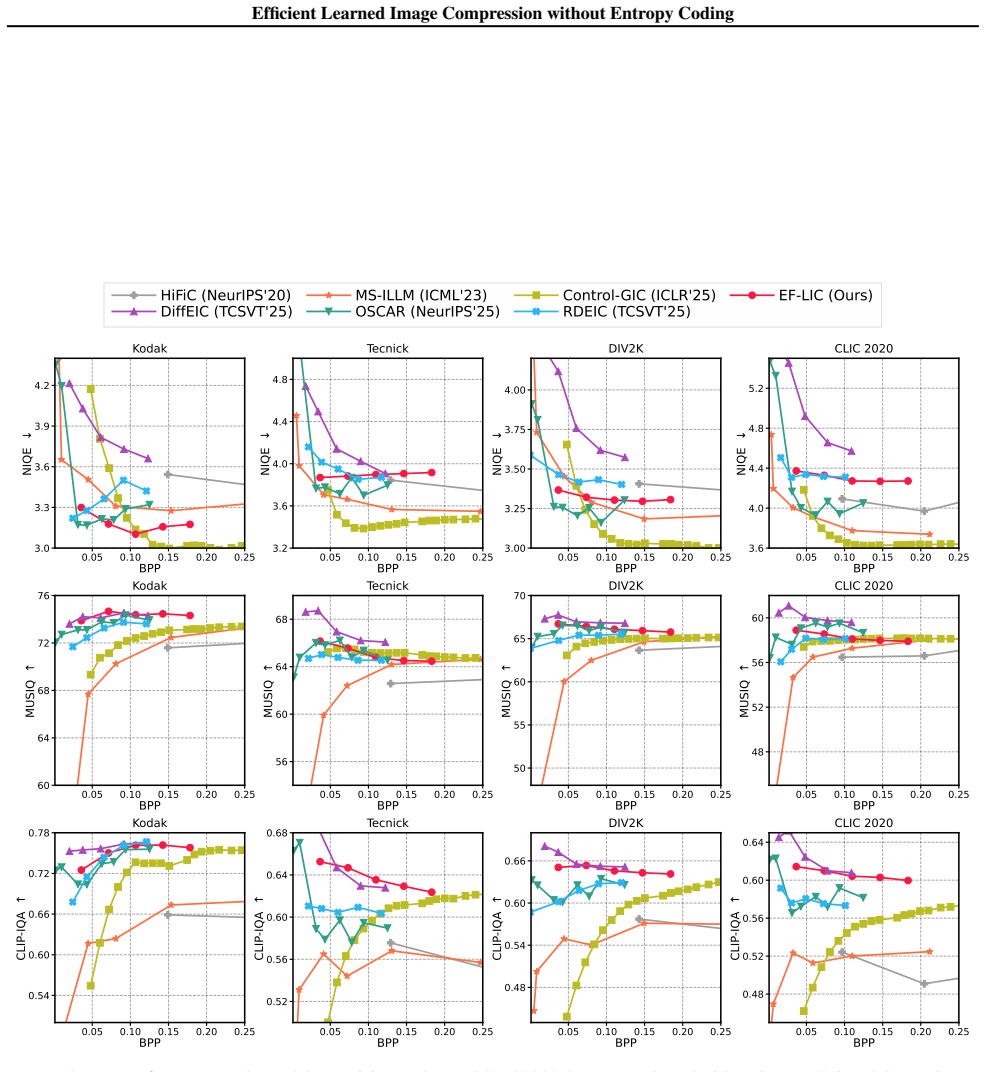
- EF-LIC achieves up to 67.86 percent bitrate reduction over MS-ILLM on the Kodak dataset under the LPIPS metric.
- Encoding runs more than three times faster and decoding more than five times faster than entropy-coded baselines.
- Compression performance remains comparable to the entropy-coding variant of the same architecture.
- The approach supports multiple rates within a single trained model.
Where Pith is reading between the lines
- Real-time or low-power devices could adopt the method where sequential entropy coding creates unacceptable latency.
- The same redundancy-removal pattern might extend to video or point-cloud compression without requiring changes to the entropy stage.
- If the index distribution truly saturates the entropy bound, further gains would require improving the transform rather than the quantizer.
Load-bearing premise
Unconstrained vector quantization produces an index distribution that approaches the maximum-entropy bound, removing statistical redundancy without entropy coding.
What would settle it
Compute the empirical entropy of the index sequences produced by the unconstrained vector quantizer on held-out images and compare it to log2 of the codebook size; a large gap would falsify the claim that statistical redundancy is removed.
Figures













read the original abstract
Entropy coding is widely used in typical learned image compression (LIC) that converts latents into a compact bitstream. However, entropy coding is typically sequential and becomes the coding latency bottleneck. To overcome it, we present Entropy-Coding Free Learned Image Compression (EF-LIC), a multi-rate framework that generates compact representation by removing statistical and correlation redundancy with low coding latency. First, we introduce unconstrained vector quantization and prove that its index distribution approaches the maximum-entropy bound, yielding minimal statistical redundancy. Second, we propose a context-conditioned autoregressive transform that directly reparameterizes the latents to reduce inter-dependency. Theoretical analysis shows that EF-LIC can remove correlation redundancy as effectively as typical LIC with entropy coding, leading to comparable compression performance. Experiments show EF-LIC achieves up to 67.86% bitrate reduction over MS-ILLM on Kodak with LPIPS. Ablation studies further show EF-LIC matches the compression performance of its entropy-coding based variant while achieving over $3\times$ faster encoding and $5\times$ faster decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Entropy-Coding Free Learned Image Compression (EF-LIC), a multi-rate framework for learned image compression that avoids entropy coding. It introduces unconstrained vector quantization, for which it claims to prove that the index distribution approaches the maximum-entropy bound (thereby removing statistical redundancy), and a context-conditioned autoregressive transform to reparameterize latents and remove correlation redundancy. Theoretical analysis asserts that this combination matches the redundancy removal of standard entropy-coded LIC. Experiments claim up to 67.86% bitrate reduction versus MS-ILLM on Kodak under LPIPS, with >3× faster encoding and >5× faster decoding, plus ablations showing parity with an entropy-coded variant.
Significance. If the central theoretical claims hold under the stated conditions, the result would be significant for low-latency learned compression, as it removes the sequential entropy-coding bottleneck while preserving rate-distortion performance. The reported speedups and bitrate gains would be practically relevant for real-time applications. The work would also contribute a concrete demonstration that vector quantization plus autoregressive reparameterization can substitute for entropy coding if the max-entropy bound is attained.
major comments (2)
- [Theoretical Analysis] Theoretical Analysis section: the manuscript states that it proves unconstrained vector quantization yields an index distribution approaching the maximum-entropy bound, but supplies neither the derivation steps nor the explicit conditions (latent statistics, training dynamics, rate constraints) under which the bound is reached. This proof is load-bearing for the claim that statistical redundancy is removed equivalently to entropy coding.
- [Experiments] Experiments section (Kodak results): the 67.86% bitrate reduction over MS-ILLM under LPIPS is reported without accompanying error bars, multiple random seeds, or explicit controls for baseline hyperparameter matching; this undermines confidence that the gain survives standard statistical checks and is not an artifact of post-hoc selection.
minor comments (1)
- [Abstract] The abstract invokes both a 'proof' and a 'theoretical analysis' equating the two redundancy-removal mechanisms; these should be cross-referenced to specific numbered equations or lemmas in the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical Analysis section: the manuscript states that it proves unconstrained vector quantization yields an index distribution approaching the maximum-entropy bound, but supplies neither the derivation steps nor the explicit conditions (latent statistics, training dynamics, rate constraints) under which the bound is reached. This proof is load-bearing for the claim that statistical redundancy is removed equivalently to entropy coding.
Authors: We acknowledge that the Theoretical Analysis section presented the result at a high level without full derivation steps or explicit conditions. In the revision we will expand this section to include the complete mathematical derivation, specifying the assumptions on latent statistics (e.g., i.i.d. Gaussian-like marginals after normalization), training dynamics (unconstrained VQ with uniform initialization and rate-regularized loss), and rate constraints under which the index distribution provably converges to the maximum-entropy bound. This will make explicit how statistical redundancy removal matches that of entropy coding. revision: yes
-
Referee: [Experiments] Experiments section (Kodak results): the 67.86% bitrate reduction over MS-ILLM under LPIPS is reported without accompanying error bars, multiple random seeds, or explicit controls for baseline hyperparameter matching; this undermines confidence that the gain survives standard statistical checks and is not an artifact of post-hoc selection.
Authors: We agree that reporting variability across random seeds and explicit baseline controls would increase confidence in the results. We will rerun the Kodak experiments with at least five random seeds, include error bars (mean ± std) for the reported bitrate reductions, and add a supplementary table listing the exact hyperparameter settings used for MS-ILLM (taken from its public implementation) to document fair matching. These additions will be incorporated in the revised Experiments section. revision: yes
Circularity Check
No significant circularity; theoretical claims presented as independent
full rationale
The abstract asserts a proof that unconstrained VQ index distribution approaches the maximum-entropy bound and that the context-conditioned autoregressive transform removes correlation redundancy equivalently to entropy-coded LIC. No equations, self-citations, or reductions to fitted inputs are visible in the provided text that would make any prediction equivalent to its inputs by construction. The derivation chain is therefore treated as self-contained theoretical analysis supported by external experiments, consistent with a non-circular finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Unconstrained vector quantization produces an index distribution that approaches the maximum-entropy bound.
- domain assumption The context-conditioned autoregressive transform removes inter-dependency at least as effectively as entropy coding.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 3.1 (Maximum-Entropy Probabilistic Shaping). For a codec employing an unconstrained VQ with K codewords and target rate R=logK, any distortion-optimal quantizer Q∗ must satisfy … ΔH=0
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.5 (R–D upper bound for EF-LIC) … DRD_X(R/(1−ε)) ≤ DCM_X(R)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Agustsson, E. and Timofte, R. NTIRE 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pp. 126– 135,
work page 2017
- [2]
-
[3]
Duda, J. Asymmetric numeral systems: Entropy cod- ing combining speed of Huffman coding with com- pression rate of arithmetic coding.arXiv preprint arXiv:1311.2540,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
doi: 10.1109/ LSP.2012.2227726. Muckley, M. J., El-Nouby, A., Ullrich, K., J´egou, H., and Verbeek, J. Improving statistical fidelity for neural im- age compression with implicit local likelihood models. InProceedings of International Conference on Machine Learning (ICML), pp. 25426–25443. PMLR,
-
[6]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K. and Zisserman, A. Very deep convolu- tional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Accessed: 2025- 06-05. Wallace, G. The jpeg still picture compression standard. IEEE Transactions on Consumer Electronics, 38(1):xviii– xxxiv,
work page 2025
-
[8]
Wang, Z., Simoncelli, E. P., and Bovik, A. C. Multiscale structural similarity for image quality assessment. InThe thirty-seventh Asilomar Conference on Signals, Systems & Computers, 2003, volume 2, pp. 1398–1402. IEEE,
work page 2003
-
[9]
• Section B describes the model implementation and bitstream packing methods
12 Efficient Learned Image Compression without Entropy Coding Appendix In the appendix, we provide the following: • Section A provides proofs of Theorems 3.1, 3.3 and 3.5. • Section B describes the model implementation and bitstream packing methods. • Section C presents additional experimental details, in- cluding the exact settings of competing methods a...
work page 2000
-
[10]
We implement RVQ following (Kumar et al., 2023), as il- lustrated in Figure 5b. To support multiple bitrates, we use a set of independent RVQ modules, where each RVQ uses a different number of codebooks m. In the main text, we set m∈ {1,2,3,4,5} to cover a sufficiently wide bitrate range. At inference time, in addition to the input image, the model takes ...
work page 2023
-
[11]
For transmission, we prepend a header containing H, W , and q, where H×W is the input image resolution and q is the rate-selection param- eter. The header takes 28 bits for H and W and 4 bits for q, which is negligible compared to the overall bitrate. Given a fixed model, the mapping from H×W to the index grid h×w is deterministic, and the number of codeb...
work page 2025
-
[12]
measures the average bitrate dif- ference between two methods over a specified quality range. We compute BD-rate as the area between the two R–D curves after interpolating them with a monotonic piecewise cubic Hermite interpolating polynomial (PCHIP). A nega- tive BD-rate indicates that the proposed method achieves the same quality at a lower bitrate than...
work page 2022
-
[13]
Table 5.Comparison of BD-rate on the Kodak, Tecnick, DIV2K, and CLIC 2020 datasets evaluated under DISTS. Best results are inbold. Second-best are underlined . Method BD-rate (DISTS) Kodak Tecnick DIV2K CLIC2020 HiFiC 90.08% 99.67% 100.76% 124.45% Control-GIC 34.18% 67.12% 62.09% 110.76% MS-ILLM 0.00% 0.00% 0.00% 0.00% DiffEIC -33.79% 23.68% 15.78% 59.91%...
work page 2020
-
[14]
100.18 200.03 6820.28 1065.81 8.03% OneDC (Xue et al., 2025a) 100.50 235.03 7142.91 1406.42 0.00% EF-LIC (Ours)17.62 13.72 279.61 35.74 -3.33% Table 7.Comparison of GPU runtimes (ms) and memory (GB) for image encoding and decoding across different resolutions. Enc./Dec. denote encoding/decoding times. Mem. denotes memory usage. Best results are inbold. Se...
work page 1920
-
[15]
We compare against the stronger entropy coding implementations in DCVC-RT (Jia et al., 2025)
because it has been widely adopted in most LIC (Ball´e et al., 2018; Minnen et al., 2018; He et al., 2022a; Feng et al., 2025; Li et al., 2025b). We compare against the stronger entropy coding implementations in DCVC-RT (Jia et al., 2025). The results are also included in Table
work page 2018
-
[16]
in the main paper, we provide R–D curves measured by PSNR, MS-SSIM (Wang et al., 2003), FID (Heusel et al., 2017), KID (Bi´nkowski et al., 2018), NIQE (Mittal et al., 2013), MUSIQ (Ke et al., 2021), and CLIP-IQA (Wang et al.,
work page 2003
-
[17]
can produce visually realistic images, but their content can differ sub- stantially from the original images, which leads to a large FID in our evaluation. Since our goal is image compression rather than image generation, preserving fidelity to the orig- inal content is essential, and we therefore primarily report LPIPS and DISTS in the main paper. Follow...
work page 2025
-
[18]
and KID (Bi´nkowski et al., 2018). This protocol crops images into 256×256 non-overlapping patches to significantly aug- ment the sample size, thereby ensuring a more accurate and robust calculation of both metrics. While this approach 19 Efficient Learned Image Compression without Entropy Coding 0.1690 / 0.1782 0.1229 / 0.1782 0.1825 / 0.1426 0.1311 / 0....
work page 2018
-
[19]
Although the qualitative results of different models on high-resolution images appear similar, we include them to demonstrate that EF-LIC also functions correctly on high-resolution inputs. 20 Efficient Learned Image Compression without Entropy Coding 0.05 0.10 0.15 0.20 0.25 BPP 21.0 22.5 24.0 25.5 27.0PSNR Kodak 0.05 0.10 0.15 0.20 0.25 BPP 22 24 26 28 ...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.